
A Netflix está obcecada com a disponibilidade do serviço. Já o revimos em nosso blog mais de uma vez e informamos como conseguimos atingir nossos objetivos. Usamos disjuntores, limites de simultaneidade, teste de caos e muito mais. Hoje, apresentamos outra abordagem inovadora que aumenta significativamente a estabilidade do aplicativo sob cargas extremas e evita falhas de serviço em cascata - limites adaptáveis para conexões paralelas. Não é necessário mais esforço para determinar os limites das conexões paralelas, permitindo que o sistema mantenha um tempo de resposta curto. Como parte deste anúncio, também estamos publicando em domínio público uma biblioteca Java simples com recursos de integração para servlets, programas de controle e gRPC.
Vamos começar com o básico
O limite de conexões paralelas é o número máximo de solicitações que o sistema pode processar em um determinado momento. Normalmente, esse valor depende de um recurso limitado, como o poder de processamento do processador central. Geralmente, o limite de conexões paralelas de um sistema é calculado de acordo com a lei de Little, que soa assim: para um sistema estável, o número máximo de conexões paralelas é igual ao produto do tempo médio gasto no processamento da solicitação e da intensidade média das solicitações recebidas (L = λW). Quaisquer solicitações que excedam o limite de conexão paralela não podem ser processadas imediatamente pelo sistema, portanto, serão enfileiradas ou rejeitadas. O enfileiramento é uma função importante que permite o uso completo do sistema nos casos em que as solicitações são recebidas de maneira desigual e requerem uma quantidade de tempo diferente para serem processadas.
Se não houver limite para a fila, poderá ocorrer uma falha no sistema, por exemplo, se por um longo período a intensidade das solicitações for superior à velocidade do processamento. À medida que a fila cresce, o atraso também aumenta, o que leva a exceder o tempo limite para solicitações. Isso continua até que a memória livre se esgote, após o que o sistema trava. Se você não acompanhar o tempo de atraso crescente, ele começará a afetar negativamente os serviços de chamada e a falhas em cascata do sistema.

O uso de limites de conexão paralela é uma prática padrão, mas a dificuldade reside em determiná-los para grandes sistemas dinâmicos distribuídos, onde parâmetros como tempo de atraso e o possível número de conexões paralelas estão constantemente mudando. A essência da nossa solução é a capacidade de determinar dinamicamente o limite de conexões paralelas. Esse limite pode ser representado como o número de solicitações recebidas (executadas em paralelo e na fila) que o sistema pode processar até que seu desempenho comece a diminuir (e o tempo de atraso aumente).
Solução
Anteriormente, os funcionários da Netflix determinavam limites de conexão simultânea manual por meio de testes e perfis de desempenho demorados. O número resultante estava correto por um período específico, mas logo a topologia do sistema começou a mudar devido a falhas parciais, redimensionamento automático ou introdução de código adicional que afetava o tempo de atraso. Como resultado, o limite está desatualizado. Sabíamos que éramos capazes de mais, que não bastava mais simplesmente determinar estaticamente os limites de conexão. Precisávamos de uma maneira de determinar automaticamente os limites inerentes ao próprio sistema. Ao mesmo tempo, queríamos este método:
- não exigiu trabalho manual;
- não exigia coordenação central;
- poderia determinar o limite sem qualquer informação sobre a topologia de hardware ou sistema;
- Adaptado a mudanças na topologia do sistema;
- foi simples em termos de implementação e os cálculos necessários.
Para resolver esse problema, recorremos ao algoritmo comprovado de rastreamento de congestionamento TCP. Este algoritmo determina o número de pacotes de dados que podem ser transmitidos em paralelo (isto é, o tamanho da janela de estouro) sem aumentar o tempo de atraso ou exceder o tempo de espera. Esses algoritmos usam vários indicadores para determinar o limite de pacotes transmitidos simultaneamente e redimensionar a janela de estouro de acordo.

A cor azul na imagem mostra o limite desconhecido para conexões paralelas ao sistema. Primeiro, o cliente envia um pequeno número de solicitações simultâneas e, em seguida, começa a verificar periodicamente o sistema para ver se consegue lidar com mais solicitações, aumentando a janela de estouro até que isso cause um aumento no atraso. Quando o atraso ainda aumenta, o remetente decide que atingiu o limite e reduz novamente o tamanho da janela de estouro. Esse teste contínuo do limite é refletido no gráfico que você vê acima.
Nosso algoritmo baseia-se no algoritmo de rastreamento de congestionamento TCP, que considera a relação entre o tempo de atraso mínimo (o melhor cenário possível em que a fila não é usada) e o tempo de atraso, medido periodicamente à medida que as solicitações são executadas. Essa proporção permite determinar que uma fila foi formada que provoca um aumento no atraso. Essa proporção nos fornece o gradiente ou magnitude da mudança no tempo de atraso:
gradiente = (RTTnoload / RTTactual) . Se o valor for igual a um, entendemos que não há fila e o limite pode ser aumentado. Um valor menor que um indica que a fila está cheia e o limite precisa ser reduzido. A cada nova medição do tempo de atraso, o limite é ajustado com base na taxa acima e, com ele, o tamanho da fila permitido muda de acordo com esta fórmula simples:
_ = _ × + _
Para várias iterações, o algoritmo calcula um limite que permite não apenas manter o tempo de atraso em um nível baixo, mas também formar a fila necessária de solicitações em caso de surtos de atividade. O tamanho da fila válido pode ser configurado. É usado para determinar a rapidez com que o limite de simultaneidade pode aumentar. Como tamanho padrão, escolhemos a raiz quadrada do valor limite atual. Essa escolha se deve à propriedade útil da raiz quadrada: em valores pequenos, será grande o suficiente em comparação com o limite para garantir um crescimento rápido, mas em valores grandes, pelo contrário, seu valor relativo será menor, o que aumentará a estabilidade do sistema.
Limites adaptativos em ação
Os limites adaptativos no lado do servidor rejeitam solicitações excessivas e mantêm uma baixa latência, o que permite que a instância do sistema se proteja e os serviços dos quais depende. Anteriormente, quando não era possível rejeitar solicitações excessivas, qualquer aumento constante no número de solicitações por segundo ou tempo de atraso levava a um aumento ainda maior nesse período e, finalmente, à queda de todo o sistema. Hoje, os serviços podem se livrar de cargas de trabalho desnecessárias e manter baixa latência enquanto trabalham com outras ferramentas de estabilização, como dimensionamento automático.
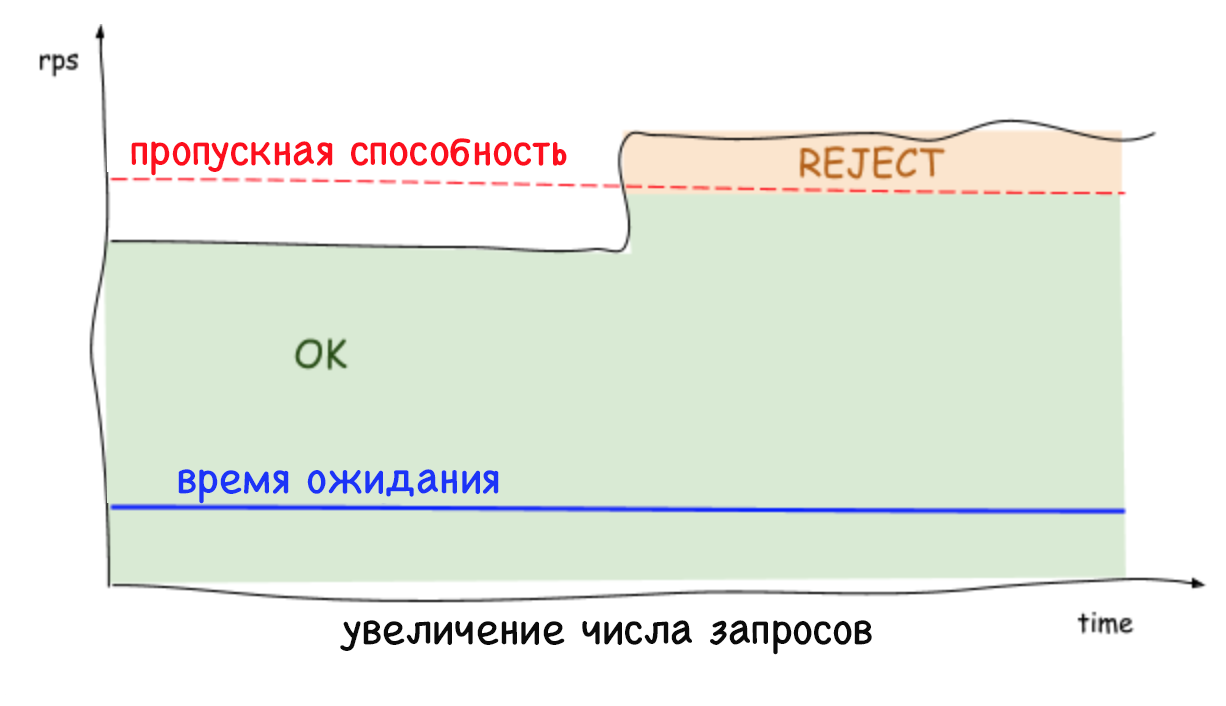
É importante lembrar que os limites são definidos no nível do servidor (e sem nenhuma coordenação), que o tráfego para cada servidor pode diminuir e aumentar bastante. Portanto, não é de surpreender que o limite detectado e o número de conexões simultâneas possam ser diferentes, dependendo do servidor. Isto é especialmente verdade em um ambiente em nuvem de múltiplos clientes. Como resultado, pode ocorrer uma situação quando um servidor está sobrecarregado, embora o restante esteja livre. Ao mesmo tempo, ao equilibrar a carga no lado do cliente, apenas uma solicitação repetida alcançará o servidor com recursos livres em quase 100% dos casos. E isso não é tudo: não há mais motivos para se preocupar com o fato de solicitações repetidas provocarem um ataque DDOS, pois os serviços conseguem rejeitar rapidamente (em menos de um milissegundo) o tráfego com impacto mínimo no desempenho.
Conclusão
O uso de limites adaptativos para conexões paralelas elimina a necessidade de determinar manualmente como e em quais casos nossos serviços devem rejeitar o tráfego. Além disso, também aumenta a confiabilidade geral e a disponibilidade de todo o nosso ecossistema de microsserviços.
Temos o prazer de compartilhar com você nossos métodos de implementação e a integração geral desta solução, que você pode encontrar na biblioteca pública em
github.com/Netflix/concurrency-limits . Esperamos que nosso código ajude os usuários a proteger seus serviços contra falhas e problemas em cascata com latência crescente, além de aumentar sua disponibilidade.