
Oi Habr!
Meu nome é Alexey Solodky, sou desenvolvedor de PHP no Badoo. E hoje vou compartilhar uma versão em texto da minha palestra para o primeiro Meetup do Badoo PHP. Um vídeo deste e de outros relatórios da mitap pode ser encontrado
aqui .
Qualquer sistema que consiste em pelo menos dois componentes (e se você possui PHP e um banco de dados, esses são dois componentes), enfrenta classes inteiras de riscos na interação entre esses componentes.
O departamento de plataforma em que trabalho integra novos serviços internos ao nosso aplicativo. E resolvendo esses problemas, acumulamos experiência, que eu quero compartilhar.
Nosso back-end é um monólito PHP interagindo com muitos serviços (atualmente existem cerca de 50 deles). Os serviços raramente interagem entre si. Mas os problemas que falo no artigo também são relevantes para a arquitetura de microsserviços. De fato, nesse caso, os serviços interagem muito ativamente entre si e, quanto mais interação você tiver, mais problemas terá.
Considere o que fazer quando o serviço falhar ou diminuir, como organizar a coleção de métricas e o que fazer quando todas as opções acima não salvarem você.
Falha no serviço
Mais cedo ou mais tarde, o servidor no qual seu serviço está instalado cairá. Isso acontecerá com certeza e você não poderá se defender - apenas reduza a probabilidade. Você pode se decepcionar com hardware, rede, código, implantação malsucedida - qualquer coisa. E quanto mais servidores você tiver, mais frequentemente isso acontecerá.
Como fazer seus serviços sobreviverem em um mundo em que os servidores travam constantemente? Uma abordagem geral para resolver essa classe de problemas é a redundância.
A redundância é usada em todos os lugares, em diferentes níveis: do ferro aos data centers inteiros. Por exemplo, RAID1 para proteger contra falhas no disco rígido ou uma fonte de alimentação de backup para o servidor em caso de falha do primeiro. Além disso, esse esquema é amplamente aplicado aos bancos de dados. Por exemplo, você pode usar master-slave para isso.
Vamos considerar problemas típicos de redundância usando o esquema mais simples como exemplo:
O aplicativo se comunica exclusivamente com o mestre, enquanto em segundo plano, de forma assíncrona, os dados são transferidos para o escravo. Quando o mestre travar, mudaremos para o escravo e continuaremos trabalhando.
Depois de restaurar o mestre, apenas criamos um novo escravo, e o antigo se transforma em um mestre.
O esquema é simples, mas mesmo com muitas nuances características de qualquer esquema redundante.
Carregar
Digamos que um servidor do exemplo acima possa suportar cerca de 100k RPS. Agora, a carga é de 60k RPS e tudo funciona como um relógio.
Porém, com o tempo, a carga no aplicativo e, portanto, a carga no mestre aumentam. Você pode equilibrar movendo parte da leitura para um escravo.
Parece muito bom. Mantém a carga, o servidor não está mais ocioso. Mas isso é uma péssima ideia. É importante lembrar por que você criou o escravo inicialmente - para mudar para ele em caso de problemas com o principal. Se você começou a carregar os dois servidores, quando o seu mestre travar - e mais cedo ou mais tarde ele travará - você terá que alternar o tráfego principal do mestre para o servidor de backup, e ele já estará carregado. Essa sobrecarga tornará seu sistema terrivelmente lento ou o desativará completamente.
Dados
O principal problema ao adicionar tolerância a falhas em um serviço é o estado local. Se o seu serviço for sem estado, ou seja, não armazena dados mutáveis, a sua escala não apresenta um problema. Nós apenas levantamos quantas instâncias precisamos e equilibramos as solicitações entre elas.
No caso em que o serviço é estável, não podemos mais fazer isso. Você precisa pensar em como armazenar os mesmos dados em todas as instâncias do nosso serviço para que eles permaneçam consistentes.
Para resolver esse problema, uma das duas abordagens é usada: replicação síncrona ou assíncrona. No caso geral, recomendo que você use a opção assíncrona, pois geralmente é mais simples e rápido escrever e, de acordo com as circunstâncias, verifique se você precisa mudar para síncrono.
Uma nuance importante a considerar ao trabalhar com replicação assíncrona é a
consistência eventual . Isso significa que, em um determinado momento no tempo em diferentes escravos, os dados podem ficar para trás do mestre em intervalos de tempo imprevisíveis e diferentes.
Assim, você não pode ler dados todas as vezes em um servidor aleatório, porque respostas diferentes podem chegar às mesmas solicitações do usuário. Para contornar esse problema,
é usado o mecanismo de
sessões fixas , o que garante que todas as solicitações de um usuário vão para uma instância.
As vantagens de uma abordagem síncrona são que os dados estão sempre em um estado consistente e o risco de perda de dados é menor (porque é considerado gravado somente depois de todos os servidores). No entanto, você deve pagar por isso com a velocidade de gravação e a complexidade do próprio sistema (por exemplo, vários algoritmos de quorum para proteção contra o
cérebro dividido ).
Conclusões
- Reserve. Se os dados em si e a disponibilidade de um serviço específico forem importantes, verifique se o serviço sobreviverá à queda de uma máquina específica.
- Ao calcular a carga, considere a queda de alguns servidores. Se o cluster tiver quatro servidores, verifique se, quando um cai, os três restantes puxam a carga.
- Escolha o tipo de replicação, dependendo das tarefas.
- Não coloque todos os seus ovos em uma cesta. Verifique se você está distante o suficiente dos servidores. Dependendo da criticidade da disponibilidade do serviço, seus servidores podem estar em diferentes racks em um data center ou em diferentes data centers em diferentes países. Tudo depende de quanto desastre global você deseja e está pronto para sobreviver.
Serviço de silêncio
Em algum momento, seu serviço pode começar a funcionar muito lentamente. Esse problema pode ocorrer por vários motivos: carga excessiva, atrasos na rede, problemas de hardware ou erros de código. Parece um problema não tão terrível, mas na verdade é mais insidioso do que parece.
Imagine: um usuário solicita uma página. Acessamos simultânea e sequencialmente os quatro demônios para desenhá-lo. Eles respondem rapidamente, tudo funciona bem.
Suponha que este caso seja tratado usando nginx com um número fixo de trabalhadores do PHP FPM (com dez, por exemplo). Se cada solicitação for processada por aproximadamente 20 ms, com a ajuda de cálculos simples, pode-se entender que nosso sistema é capaz de processar cerca de quinhentas solicitações por segundo.
O que acontece quando um desses quatro serviços começa a ficar embotado e o processamento de solicitações para ele aumenta de 20 ms para um tempo limite de 1000 ms? É importante lembrar que, quando trabalhamos com a rede, o atraso pode ser infinitamente grande. Portanto, você sempre deve definir um tempo limite (nesse caso, é igual a um segundo).
Acontece que o back-end é forçado a aguardar o tempo limite expirar e receber e processar o erro do daemon. Isso significa que o usuário recebe a página em um segundo em vez de dez milissegundos. Lento, mas não fatal.
Mas qual é o verdadeiro problema aqui? O fato é que, quando temos todas as solicitações processadas por segundo, a taxa de transferência cai tragicamente para dez solicitações por segundo. E o décimo primeiro usuário não poderá mais obter uma resposta, mesmo que ele tenha solicitado uma página que não esteja de modo algum associada a um serviço sem graça. Só porque todos os dez funcionários estão aguardando um tempo limite e não podem processar novas solicitações.
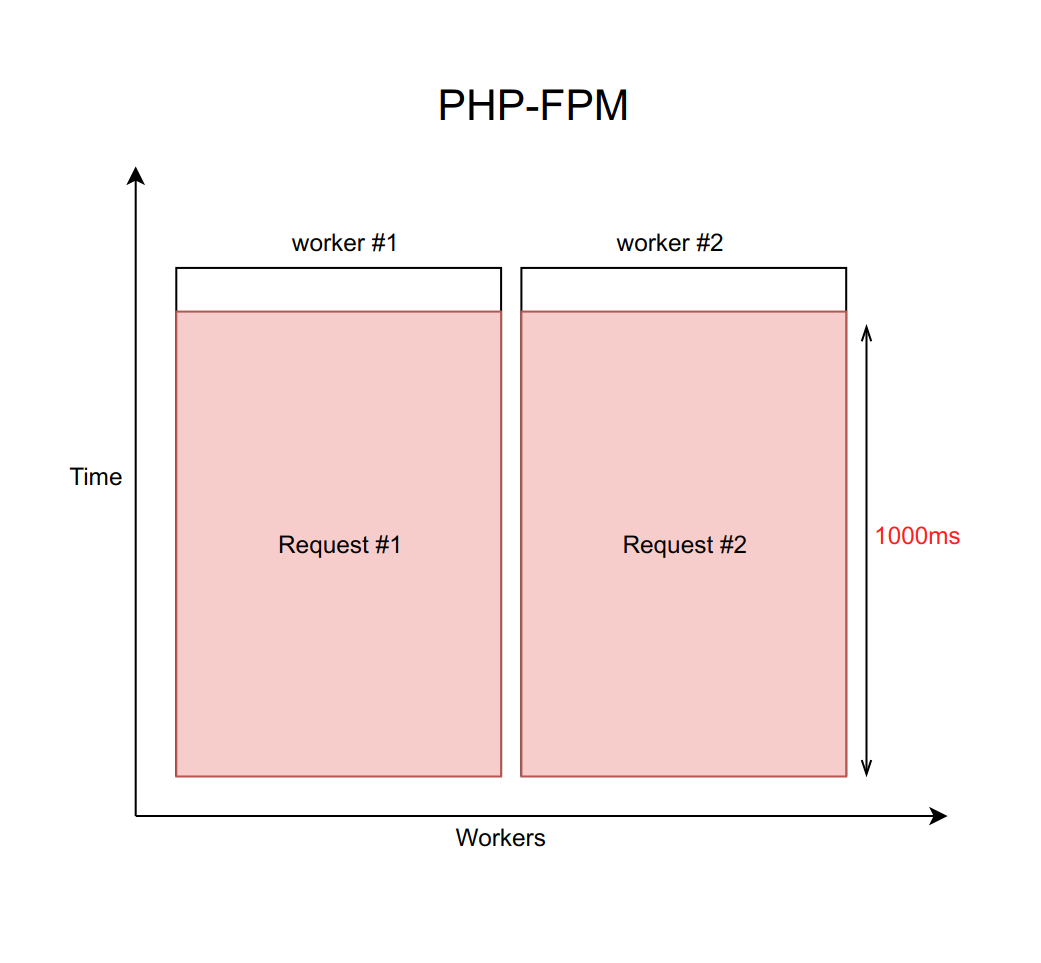
É importante entender que esse problema não pode ser resolvido aumentando o número de trabalhadores. Afinal, cada trabalhador exige uma certa quantidade de RAM para o seu trabalho, mesmo que ele não execute um trabalho real, mas simplesmente trava na expectativa de um tempo limite. Portanto, se você não limitar o número de trabalhadores de acordo com os recursos do seu servidor, aumentar cada vez mais novos trabalhadores colocará o servidor inteiro. Este caso é um exemplo de falha em cascata, quando a queda de qualquer serviço, mesmo que não seja crítica para o usuário, causa uma falha em todo o sistema.
Solução
Existe um padrão chamado
disjuntor . Sua tarefa é bastante simples: ele deve, em algum momento, reduzir um serviço monótono. Para isso, um proxy é colocado entre o serviço e os trabalhadores. Pode ser um código PHP com armazenamento ou um daemon no host local. É importante observar que, se você tiver várias instâncias (seu serviço é replicado), esse proxy deverá rastrear separadamente cada uma delas.
Escrevemos nossa implementação desse padrão. Mas não porque gostamos de escrever código, mas porque quando resolvemos esse problema há muitos anos, não havia soluções prontas.
Agora, descreverei em termos gerais sobre nossa implementação e como isso ajuda a evitar esse problema. E mais sobre ela e suas diferenças em relação a outras soluções podem ser ouvidas
em um relatório de Mikhail Kurmaev na Highload Siberia no final de junho. A transcrição de seu relatório também estará neste blog.
Parece algo como isto:
Existe um serviço Sphinx abstrato, que é enfrentado por um disjuntor. O disjuntor armazena o número de conexões ativas para um daemon específico. Assim que esse valor atinge o limite, que definimos como uma porcentagem dos trabalhadores disponíveis do FPM na máquina, acreditamos que o serviço começou a ficar mais lento. Ao atingir o primeiro limite, enviamos uma notificação para a pessoa responsável pelo serviço. Tal situação é um sinal de que os limites precisam ser revistos ou um indicador de problemas de embotamento.
Se a situação piorar e o número de trabalhadores inibidores atingir o segundo valor limite - em nossa produção, é de cerca de 10% -, reduzimos completamente esse host. Mais precisamente, o serviço realmente continua a funcionar, mas paramos de enviar solicitações para ele. O navegador do Circuit os rejeita e imediatamente dá um erro aos trabalhadores, como se o serviço estivesse mentindo.
Periodicamente, pulamos automaticamente uma solicitação de um trabalhador para ver se o serviço ganhou vida. Se ele responder adequadamente, nós o incluiremos novamente no trabalho.
Tudo isso é feito para reduzir a situação ao esquema de replicação anterior. Em vez de esperar um segundo antes de perceber que o host está indisponível, imediatamente obtemos um erro e vamos para o host de backup.
Implementações
Felizmente, o Open Source não fica parado e hoje você pode usar uma solução pronta para usar no Github.
Existem duas abordagens principais para implementar o disjuntor: uma biblioteca em nível de código e um daemon independente que solicita proxies por meio de si mesmo.
A opção com a biblioteca é mais adequada se você tiver um monólito principal em PHP, que interage com vários serviços, e os serviços quase não se comunicam. Aqui estão algumas implementações disponíveis:
Se você tiver muitos serviços em idiomas diferentes e todos interagirem, a opção no nível do código deverá ser duplicada em todos esses idiomas. Isso é inconveniente no suporte e, finalmente, leva a diferenças nas implementações.
Colocar um daemon nesse caso é muito mais fácil. Nesse caso, você não precisa editar especialmente o código. O demônio está tentando tornar a interação transparente. No entanto, essa opção é
muito mais complicada em termos de arquitetura .
Aqui estão algumas opções (a funcionalidade é mais rica lá, mas também há um disjuntor):
Conclusões
- Não confie na rede.
- Todas as solicitações de rede devem ter um tempo limite, porque a rede pode demorar infinitamente.
- Use um disjuntor se desejar evitar falhas de aplicativos em cascata devido ao fato de um pequeno serviço ficar mais lento.
Monitoramento e telemetria
O que isso dá
- Previsibilidade. É importante prever qual é a carga e o que será em um mês para aumentar atempadamente o número de instâncias de serviço. Isso é especialmente verdadeiro se você estiver lidando com uma infraestrutura de ferro, pois a encomenda de novos servidores leva tempo.
- Investigação de incidentes. Mais cedo ou mais tarde, algo vai dar errado de qualquer maneira, e você terá que investigá-lo. E é importante ter dados suficientes para entender o problema e ser capaz de evitar essas situações no futuro.
- Prevenção de acidentes. Idealmente, você deve entender quais padrões levam a falhas. É importante acompanhar esses padrões e notificar a equipe sobre eles em tempo hábil.
O que medir
Métricas de integraçãoComo estamos falando da interação entre serviços, monitoramos tudo o que é possível em relação à comunicação do serviço com o aplicativo. Por exemplo:
- número de solicitações;
- tempo de processamento da solicitação (incluindo percentis);
- número de erros lógicos;
- número de erros do sistema.
É importante distinguir erros lógicos dos erros do sistema. Se o serviço cair, é uma situação regular: simplesmente mudamos para o segundo. Mas não é tão assustador. Se você iniciar algum tipo de erro lógico, por exemplo, dados estranhos entram no serviço ou os deixam, então isso já precisa ser investigado. Provavelmente, o erro está relacionado a um erro no código. Ela própria não vai passar.
Métricas internasPor padrão, o serviço é uma caixa preta que faz seu trabalho de maneira incompreensível. Ainda é desejável entender e coletar o máximo de dados que o serviço pode fornecer. Se o serviço for um banco de dados especializado que armazena alguns dados da lógica de negócios, acompanhe exatamente quantos dados, qual o tipo e outras métricas de conteúdo. Se você tiver interação assíncrona, também é importante monitorar as filas pelas quais o serviço se comunica: velocidade de chegada e partida, horário em diferentes estágios (se você tiver vários pontos intermediários), número de eventos na fila.
Vamos ver quais métricas podem ser coletadas usando o memcached como exemplo:
- taxa de acerto / erro;
- tempo de resposta para várias operações;
- RPS de várias operações;
- discriminação dos mesmos dados em chaves diferentes;
- chaves com carregamento superior;
- todas as métricas internas fornecidas pelo comando stats.
Como fazer
Se você tem uma empresa pequena, um projeto pequeno e poucos servidores, é uma boa solução conectar algum tipo de SaaS para coletar e visualizar - é mais fácil e mais barato. Nesse caso, geralmente o SaaS possui uma funcionalidade abrangente e não precisa se preocupar com muitas coisas. Exemplos de tais serviços:
Como alternativa, você sempre pode instalar o Zabbix, Grafana ou qualquer outra solução auto-hospedada em sua própria máquina.
Conclusões
- Colete todas as métricas que puder. Os dados não são supérfluos. Quando você tiver que investigar alguma coisa, agradecerá sua premissa.
- Não se esqueça da interação assíncrona. Se você possui linhas que alcançam gradualmente, é importante entender a rapidez com que atingem, o que acontece com seus eventos no cruzamento entre os serviços.
- Se você escrever seu serviço, ensine-o a fornecer estatísticas sobre o trabalho. Parte dos dados pode ser medida na camada de integração quando nos comunicamos com este serviço. O restante do serviço deve poder fornecer estatísticas de acordo com o comando condicional. Por exemplo, em todos os nossos serviços on Go, essa funcionalidade é padrão.
- Personalize gatilhos. Os gráficos são bons, mas apenas enquanto você os olha. É importante que você tenha um sistema personalizado que informará se algo der errado.
Memento mori
E agora um pouco sobre coisas tristes. Você pode ter a sensação de que o exposto acima é uma panacéia e agora nada cairá. Mas, mesmo que você aplique tudo o que foi descrito acima, algo cairá. É importante considerar isso.
As razões para a queda são muitas. Por exemplo, você pode escolher um esquema de replicação insuficientemente paranóico. Um meteorito caiu no seu data center e depois no segundo. Ou você acabou de implantar o código com um erro complicado que apareceu inesperadamente.
Por exemplo, no Badoo, há uma página "Pessoas próximas". Lá, os usuários pesquisam outras pessoas próximas para conversar com eles.

Agora, para renderizar a página, o back-end faz chamadas síncronas para cerca de sete serviços. Para maior clareza, reduza esse número para dois. Um serviço é responsável por renderizar o bloco central com fotos. O segundo é para o bloco de publicidade no canto inferior esquerdo. Quem quiser se tornar mais visível pode chegar lá. Se temos um serviço que exibe esse anúncio, o bloco simplesmente desaparece.

A maioria dos usuários nem sabe desse fato: nossa equipe responde rapidamente e logo o bloco reaparece.
Mas nem todas as funcionalidades que podemos remover silenciosamente. Se perdermos o serviço responsável pela parte central da página, isso não funcionará para ocultar. Portanto, é importante informar ao usuário em seu idioma o que está acontecendo.

Também é desejável que a falha de um serviço não leve a uma falha em cascata. Para cada serviço, é necessário escrever um código que lide com a queda, caso contrário, o aplicativo poderá falhar como um todo.
Mas isso não é tudo. Às vezes, algo cai, sem o qual você não pode viver de forma alguma. Por exemplo, um banco de dados central ou serviço de sessão. É importante resolvê-lo corretamente e mostrar ao usuário algo adequado, de alguma forma entretê-lo, para dizer que tudo está sob controle. Ao mesmo tempo, é importante que tudo esteja realmente sob controle e os monitores sejam notificados do problema.
Morrer tão certo
- Prepare-se para o outono. Não há bala de prata; portanto, sempre coloque canudos caso o serviço caia completamente, mesmo se você usar redundância.
- Evite falhas em cascata quando problemas com um dos serviços matam o aplicativo inteiro.
- Desative a funcionalidade não crítica do usuário. Isso é normal. Muitos serviços são usados apenas para necessidades internas e não afetam a funcionalidade fornecida. Por exemplo, um serviço de estatísticas. Não importa para o usuário se as estatísticas são coletadas de você ou não. É importante para ele que o site funcione.
Sumário
Para integrar de forma confiável o novo serviço ao sistema, escrevemos uma API de wrapper especial em torno dele no Badoo, que executa as seguintes tarefas:
- balanceamento de carga;
- timeouts;
- failover lógico;
- disjuntor;
- monitoramento e telemetria;
- lógica de autorização;
- serialização e desserialização de dados.
É melhor garantir que todos esses itens também sejam abordados na sua camada de integração. Especialmente se você estiver usando um cliente API de código-fonte pronto. É importante lembrar que a camada de integração é uma fonte de maior risco de falha em cascata do seu aplicativo.
Obrigado pela atenção!
Literatura