A tendência NoSQL tem quase 10 anos e você pode tirar conclusões e generalizações com segurança. Faremos isso e falaremos sobre o desenvolvimento do NoSQL.
Lembre-se de como o NoSQL nasceu. Vamos ver o que é bom e o que é ruim, e o que resistiu ao teste do tempo. Vamos analisar os recursos que já estão no SQL e que agora aparecem no NoSQL DBMS. Destacamos os valores exclusivos do NoSQL e observamos um pouco à frente o que acontecerá amanhã no mercado.
Konstantin Osipov (
@kostja ), desenvolvedor e arquiteto do Tarantool DBMS, que falou sobre as tendências do NewSQL em seu relatório no RIT ++ 2017, nos ajudará com isso, porque o arquiteto deve entender o que está acontecendo no mundo dos bancos de dados para que pelo menos reinventar a roda.
Sobre o palestrante : Agora Konstantin Osipov está trabalhando no Tarantool, mas já participou anteriormente do desenvolvimento do MySQL, e quando Konstantin começou a trabalhar em um novo banco de dados, ficou muito confuso sobre o porquê de isso ser feito, por que o próximo banco de dados era necessário. Em particular, a atitude em relação ao NoSQL foi muito cética quanto ao "under-SQL".
No entanto, o desenvolvimento continua, alguns dos princípios originais desaparecem e, ao mesmo tempo, os bancos de dados NoSQL assumem os recursos do SQL clássico. Com base nos resultados desses vários anos de rápida transformação, é bem possível obter resultados intermediários e permitir-se fazer várias previsões para o futuro.
Planejar
Princípios NoSQL
Muitas pessoas estão tentando se ater ao termo NoSQL agora, mas ele foi amplamente adotado em 2009 quando a hashtag
#nosql apareceu. O desenvolvedor do Last.FM inventou essa tag para o mitap dos bancos de dados distribuídos.
Depois disso, a tag começou a ganhar popularidade no Twitter, e o NoSQL se tornou um tanque de drenagem ou funil de frustração, como eu chamo - frustração que se acumulou ao longo de muitos anos trabalhando com bancos de dados tradicionais.
O NoSQL é uma saída para a frustração, uma marca que todos os que não possuem recursos SQL suficientes se apropriaram.
Essa frustração precisa ser de alguma forma estruturada e determinada que muitas vezes as pessoas não gostam nos DBMSs tradicionais. Podemos distinguir três grandes blocos de tarefas para a solução da qual o NoSQL foi criado:
- escala horizontal;
- novos modelos de dados;
- novos modelos de consistência.
Vamos ver o que são esses blocos. Tome, por exemplo, bancos de dados de valor-chave. A idéia principal do modelo de dados de valor-chave é que o banco de dados seja simples, mas escalável. Um grande número de problemas recai sobre os ombros do desenvolvedor, mas ele tem uma garantia estrita de que seu banco de dados será
infinitamente escalável . Mas escalabilidade infinita não é mágica. Garantias de escalabilidade são alcançadas devido à
semântica extremamente simples de operações suportadas: em um banco de dados de valores-chave, qualquer operação afeta estritamente um nó de cluster.
Inicialmente, era muito difícil para a comunidade separar modelos de dados de modelos em escala. Se você observar o mesmo Cassandra, nas versões anteriores, seu modelo de dados era chamado de Wide Column Store - um banco de dados de colunas largas. Se houver um índice no valor-chave do DBMS, por chave, no armazenamento da coluna ampla, dois índices sempre serão criados automaticamente: por chave e por Família de colunas.
Além disso, o índice por chave é compartilhável, e o índice por Família de colunas é local para um nó de dados específico. Devido a isso, alcançamos o dimensionamento horizontal, mas, ao mesmo tempo, tivemos a oportunidade de realizar consultas locais na família de colunas. Os veteranos lembram que um recurso semelhante foi implementado no Oracle, mantendo o modelo relacional, e foi chamado de tabela unida. Esse recurso tornou possível especificar o local físico das duas tabelas no formulário unido. Amplo armazenamento de colunas no Cassandra - implementa uma tabela unida com distribuição automática em todo o cluster.
A mesclagem do modelo de dados e do modelo em escala é exatamente o problema que foi resolvido usando o modelo relacional. Bem-vindo aos anos 70.
Além dos novos modelos de dados, o NoSQL implementou novos modelos de consistência. Sim, sim, novamente este famoso
teorema da PAC . Falar sobre o teorema da PAC me diverte o tempo todo - quem precisa? Como não há esturjão da segunda atualização, não há outras respostas para a pergunta sobre a consistência dos dados, exceto uma:
o banco de dados deve garantir essa consistência . Portanto, novos modelos de consistência também são, na minha opinião, uma tendência de morte.
NoSQL hoje
A tese que quero expressar antes de tudo é que todo o movimento NoSQL sobreviveu:
- escala horizontal;
novos modelos de dados documentam e modelam modelos de dados;novos modelos de consistência.
Das teses sobre novos modelos de dados, quase um ano e meio sobreviveu e a tese sobre modelos de consistência morreu completamente.
Capuz da morte
Por que alguns modelos de consistência não sobreviveram?
●
Consistência eventual: inflação a termoQuem usa um banco de dados que possui um relógio vetorial funcional e a lógica comercial do aplicativo é voltada para isso? ninguém. Quem usa bancos de dados que possuem CRDT (tipos de dados replicados sem conflito)? Quem está usando o Riak? ninguém. O que as pessoas usam? Mais frequentemente, PostgreSQL, menos frequentemente outras bases, por exemplo, MongoDB.
●
MongoDB: atômico é substituído por isolado, transações são adicionadas em 3.xxEste banco de dados possui replicação assíncrona. É uma coisa muito fácil de entender, embora, de fato,
existam 4 tipos de replicação assíncrona . A replicação dos dados da transação pode ocorrer após uma transação ser confirmada localmente; antes que a transação seja confirmada localmente.
Ou seja, o ponto de consolidação no banco de dados principal também pode ser correlacionado com o ponto de consolidação na réplica de maneiras diferentes.
Uma entrada para o log local já foi feita, mas ainda não foi levada para a réplica. Suponha que você queira esperar que ela pelo menos voe para uma réplica. Voou para longe - não significa que voou. Chegou - isso não significa que foi gravado no diário local na réplica.
Inicialmente, o MongoDB tinha um modo: a solicitação chega no servidor, o banco de dados respondeu OK - ainda nem chegou ao disco nem ao diário de bordo - não foi a lugar nenhum. Devido a isso, tudo funciona muito rapidamente, mas eles começaram a criticar o MongoDB por isso e, por padrão, nas versões posteriores 3+, afinal, ele começou a gravar a transação no log e somente depois enviar uma confirmação ao cliente.
Ou seja, mesmo a replicação assíncrona é um abismo dos modelos semânticos. Portanto, os
modelos de consistência são muito complicados para um amplo círculo de desenvolvedores entender, e as transações e a replicação síncrona estão substituindo a variedade de modelos exóticos .
No contexto da morte do modelo de consistência, ainda existe uma tendência interessante no desenvolvimento de consistências realmente mais rigorosas. Existem transações no Redis, embora eu não as chamasse de transações, mas à custa do que é uma transação real, há controvérsia sem ela.
Vamos dar uma olhada no histórico de transações no NoSQL. Inicialmente, o MongoDB implementou a atomicidade em nível de documento. Em seguida, foi adicionado um modo de execução isolado para permitir que os desenvolvedores, se realmente desejarem, atualizem vários documentos de maneira atômica.
●
Transações RedisNo início do NoSQL, o desenvolvedor foi oferecido para colocar todo o caso de negócios em um único documento de cesta. Um fluxo inteiro aparece chamado design orientado a domínio, o que eleva essa perversão à classificação do padrão de design. De fato, se tudo estiver armazenado em um documento, a atomicidade será alcançada simplesmente: você fez uma transação, um processo de negócios e uma alteração atômica em um documento.
Mas acontece que isso não funciona. Os dados precisam ser normalizados para evitar redundância de armazenamento. Eles precisam ser normalizados para consultas analíticas. No final, o modelo de dados está evoluindo - e o documento que ontem pode salvar todas as informações necessárias para um cenário de negócios hoje precisa ser expandido e complementado.
Os problemas de atomicidade demonstram? quão estreitamente os modelos de dados estão relacionados aos modelos de consistência - o advento das transações e da replicação síncrona torna desnecessária a maioria dos modelos no NoSQL.
Modelos de dados
Agora vamos falar sobre a próxima história - a história com modelos de dados.
Grupos de modelos de dados inventados após o SQL:
- Valor-chave
- Documentário
- Loja de colunas largas;
- Servidor de estrutura de dados (para Redis);
- Bases de dados de gráficos.
Legal! Temos tantos modelos de dados! E quão bem eles escalam?
Esta é uma tese, principalmente relacionada à chamada hiperconvergência, quando todos os projetos modernos usam servidores de servidor único baratos e as empresas param de comprar máquinas verticalmente escalonáveis.
A hiperconvergência entrou em nossas vidas tão completamente que hoje, mesmo dentro de máquinas com escala vertical, se houver, já existe software horizontalmente escalável - veja como o PureStorage funciona ou, se você se lembra, à noite, a Nutanix. Obviamente, eles vendem armários para pessoas, mas esses armários são dispostos no interior como racks comuns em um provedor de hospedagem.
Ou seja, o dimensionamento horizontal é uma tendência que pressiona a todos, incluindo os inventores de novos modelos de dados. Então, quais modelos de dados são bons para dimensionamento horizontal e quais são ruins?
É bom ou ruim para o dimensionamento horizontal? A resposta, de fato, é bastante controversa, retornaremos a ela mais tarde.
Redis
Quando a Redis adicionou o cluster Redis, descobriu-se que nem todas as operações do modelo de dados são dimensionadas normalmente horizontalmente.

Esta é uma citação da documentação em que eles escrevem que algo funciona para eles em um shard específico e algo realmente funciona como em um cluster real.
O problema fundamental dessa abordagem é o mesmo do MySQL, que pegamos e apertamos as mãos. Ou seja, o desenvolvedor possui dois modelos de dados:
- Em um deles, ele pensa dentro da estrutura da álgebra relacional.
- Então, quando ele pensa em sharding independente, ele pensa no modelo de dados da álgebra shard-relacional.
Um bom modelo de dados deve ser universal . O que é belo na álgebra relacional - o resultado de uma projeção é uma relação, o resultado de qualquer operador é uma relação. E assim que começamos a compartilhar manualmente o MySQL no cluster, perdemos isso.
No entanto, o Redis adiciona um cluster Redis porque
todos desejam escalar horizontalmente .
Bancos de dados gráficos
Os bancos de dados de gráficos são um bom exemplo que ajuda a
separar os conceitos de escala horizontal de computação e armazenamento . As informações sempre podem ser divididas por qualquer número de nós. Mas se o banco de dados é projetado por natureza para processar os dados que armazena e esses cálculos não são redimensionados horizontalmente, surge o problema de um armazenamento horizontal eficaz que permite que os cálculos funcionem.
Vejamos o problema dos DBMSs do gráfico de escala - os DBMSs do SQL enfrentam barreiras de escala muito semelhantes.
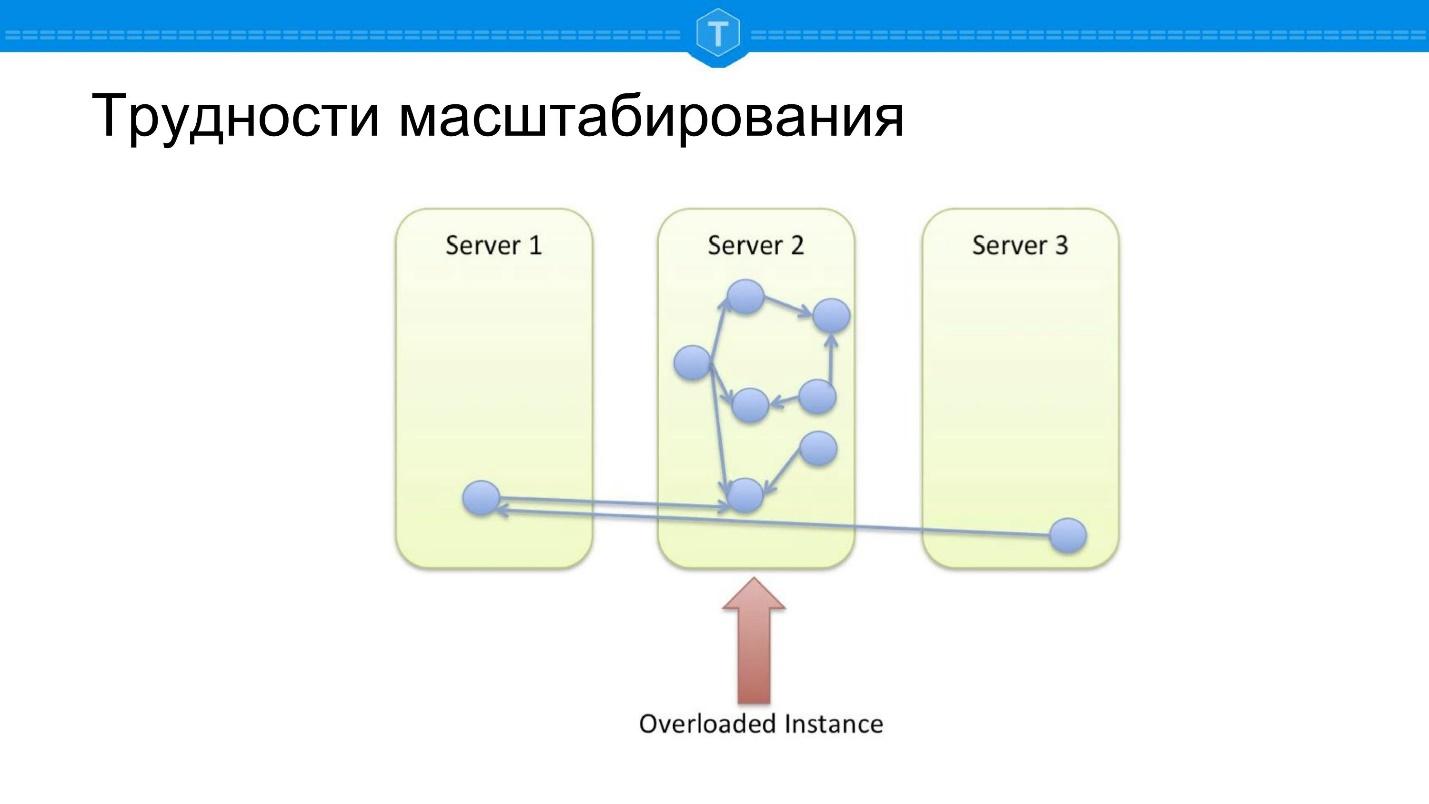
Pegue o banco de dados local no qual o gráfico está armazenado. Cedo ou tarde, um nó é preenchido e começamos a usar outros nós. Assim que usamos mais de um nó, o nó central fica sobrecarregado, pois a localidade das solicitações é perdida. Algumas consultas no gráfico são forçadas a percorrer vários nós físicos, ou seja, atrasos na rede são exibidos.
Suponha que fizemos algo diferente - eles pegaram e quebraram tudo com uma boa função de fragmentação. Calculamos um certo hash, espalhando aleatoriamente todos os dados em nosso cluster de maneira bastante aleatória - e temos outro problema.

Se no esquema anterior pelo menos algumas consultas funcionaram bem, então
100% das consultas são estúpidas aqui , porque a maioria das consultas ao banco de dados está conectada à
passagem de gráfico. Qualquer desvio do nó deve ir para algum lugar e, na maioria das vezes, para calcular a solicitação, você precisa ir para outro nó.

A idéia surge em um fragmento aproximadamente, conforme mostrado no diagrama acima: encontre clusters e coloque-os em seus nós: subconjuntos firmemente conectados são colocados juntos, subconjuntos fracamente conectados são espaçados.
Essa é uma opção ideal, mas a
opção ideal existe apenas na teoria . Os dados ao vivo não se prestam ao particionamento estático. Para implementar essa abordagem, precisamos detectar automaticamente os clusters em um conjunto de mudanças dinâmicas, mover constantemente os nós, dependendo dos títulos emergentes e desaparecidos.
Portanto, o Neo4j agora é escalado como bancos de dados SQL clássicos. Eles trabalham no sharding há algum tempo, tentando resolver os problemas descritos.
A tese que apresento é que o
dimensionamento horizontal exerce
pressão sobre todos , e todos os modelos de dados serão forçados, mais cedo ou mais tarde, a implementá-lo. Mas alguns modelos permanecerão conosco, enquanto outros não.
Assim, por exemplo, se considerarmos os bancos de dados de valor-chave e documento em forma pura, minha afirmação é que eles não serão. Se você olhar para os bancos de dados gráficos, eles já ocupam um segmento significativo, mas estão sob a pressão da escala horizontal.
Os bancos de dados gráficos desaparecerão? É mais provável que
colunas, como documentos, sejam incluídas em todos os produtos . Essa tendência é chamada de bancos de dados de vários modelos e, posteriormente, no relatório, darei um exemplo de como isso pode funcionar na prática. Mas, por enquanto, como outra ilustração da tendência dos bancos de dados com vários modelos, vejamos o JSON.
Json
Abaixo está um exemplo de como uma tendência que está se tornando abrangente funciona.
Eu mantenho que qualquer banco de dados que seja capaz de suportar JSON de qualquer forma suportará JSON.
Talvez alguns bancos de dados para computação matricial não suportem JSON. Mas provavelmente lá será útil. E todo o resto será definitivamente.
| MySQL
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4j
|
Armazenamento JSON
| Sim
| Sim
| Sim
| Sim
| Sim
| Sim
|
Operações de campo JSON
| Sim
| Sim
| Sim
| Sim
| Não
| Não
|
Consulta Json
| Sim
| Sim
| Não
| Sim
| Sim
| Não
|
Índice secundário JSON
| Sim
| Sim
| Não
| Sim
| Não
| Não
|
Esta tabela permite que você veja visualmente o que está acontecendo com modelos de dados. Os bancos de dados relacionais em seu suporte ao JSON estão à frente dos bancos não relacionais do mesmo Cassandra. Não possui chaves secundárias para campos JSON. E até os bancos de dados gráficos também estão começando a incluir JSON, porque
todos precisam de JSON .
Portanto, os bancos de dados com vários modelos e, em particular, o JSON como um tipo de dados encontrado em quase todos os produtos, é o que permanecerá sério e por muito tempo no NoSQL.
Mas se todos os bancos de dados suportam JSON, por que você precisa dos bancos de dados NoSQL?Só resta uma história - escala horizontal. Queremos escalar horizontalmente, e é por isso que usamos algo diferente do MySQL ou PostgreSQL.

Esta é a palestra de Thomas Ulin, vice-presidente de engenharia do MySQL da Oracle, que fala sobre o futuro do MySQL. O mesmo acontece na comunidade do Postgres e em outros produtos relacionais. A pressão do dimensionamento horizontal afeta 100% dos produtos devido à transição para hiperconvergência e computação em nuvem.
Thomas diz que a visão deles é um produto com alta disponibilidade e escalabilidade prontas para uso. Estamos falando de alta disponibilidade, principalmente do InnoDB Cluster, que é replicação de grupo + InnoDB. Esse banco de dados nunca morre, mesmo que seja atingido por um martelo.
Em seguida, Thomas escreve "
recursos de escala integrados " - "integramos todos esses recursos". O ponto é que, através de x releases (acho que x = 2, 3), eles receberão o MySQL Cluster em sua forma pura, que suportará SQL no cluster, armazenamento JSON no cluster.
Atualmente, o
MySQL possui um protocolo X muito semelhante ao MongoDB e foi projetado para funcionar com JSON.
SQL no NoSQL
Agora vamos ver o movimento do outro lado. Para declarar a morte, você precisa observar não apenas como o SQL adota os princípios do NoSQL, mas também vice-versa.
| Mongodb
| Couchbase
| Cassandra
| Redis
|
Esquema de dados
| Sim *
| Não
| Sim
| Não
|
NULLs / valores ausentes
| Sim *
| Sim
| Sim
| Não
|
Junções
| Sim
| Sim
| Não
| Não
|
Chaves secundárias
| Sim *
| Sim
| Sim mas ...
| Não
|
GRUPO POR
| Sim *
| Sim
| Não
| Não
|
JDBC / ODBC
| Não
| Sim
| Não
| Não
|
Aqui, de fato, também há idéias interessantes. Peguei, na minha opinião, os líderes. Concordo que nem tudo está aqui, por exemplo, o Elastic também é um líder do NoSQL. Mas o Elastic ainda é principalmente uma solução para a pesquisa de texto completo, portanto não a incluí na tabela.
Bancos de dados de séries temporais como uma tendência que não toco. Existe uma tese entre as séries temporais de movimentos de que esse é um nicho separado, semelhante aos bancos de dados de gráficos, mas se você se aprofundar, o Postgres fica oculto.
Couchbase
Na minha opinião, o Couchbase tem a mais ampla gama de possibilidades do mundo SQL. Todo mundo sabe que o
Couchbase é o Memcached . Dormando (
Alan Kasindorf ), um dos desenvolvedores do Memcached, tinha uma visão de produto completamente diferente, que não envolvia escala horizontal. Portanto, o Memcache bifurcou para ser dimensionado horizontalmente. Tudo correu bem e começou a fazer negócios em torno dele, depois se fundiu com o CouchDB e assim por diante.
O Couchbase inicialmente diz a si mesmo que eles são um
banco de dados sem esquema . Memcache é originalmente um valor-chave muito simples. Agora vamos ver como essa auto-identificação muda com o tempo.
Por exemplo, o Couchbase possui chaves secundárias, e as
chaves secundárias são, na verdade, o início do esquema . Se você diz que possui alguns campos pelos quais você cria o índice, já está falando sobre o esquema dos documentos de dados que você armazena.
Além disso, como o Couchbase gradualmente corta toda a história sobre o Memcache da documentação de hoje, eles também cortam a história sobre eventual consistência amanhã, embora hoje ainda existam muitas histórias sobre a falta de consistência de leitura - as chaves secundárias acabam sendo consistentes.
Mas o problema é que o Couchbase possui JDBC / ODBC. , Tableau ClickView — , CQL SQL.
— SQL., .

, - , , , - — , SQL.
, IS MISSING — , IS NULL?
JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
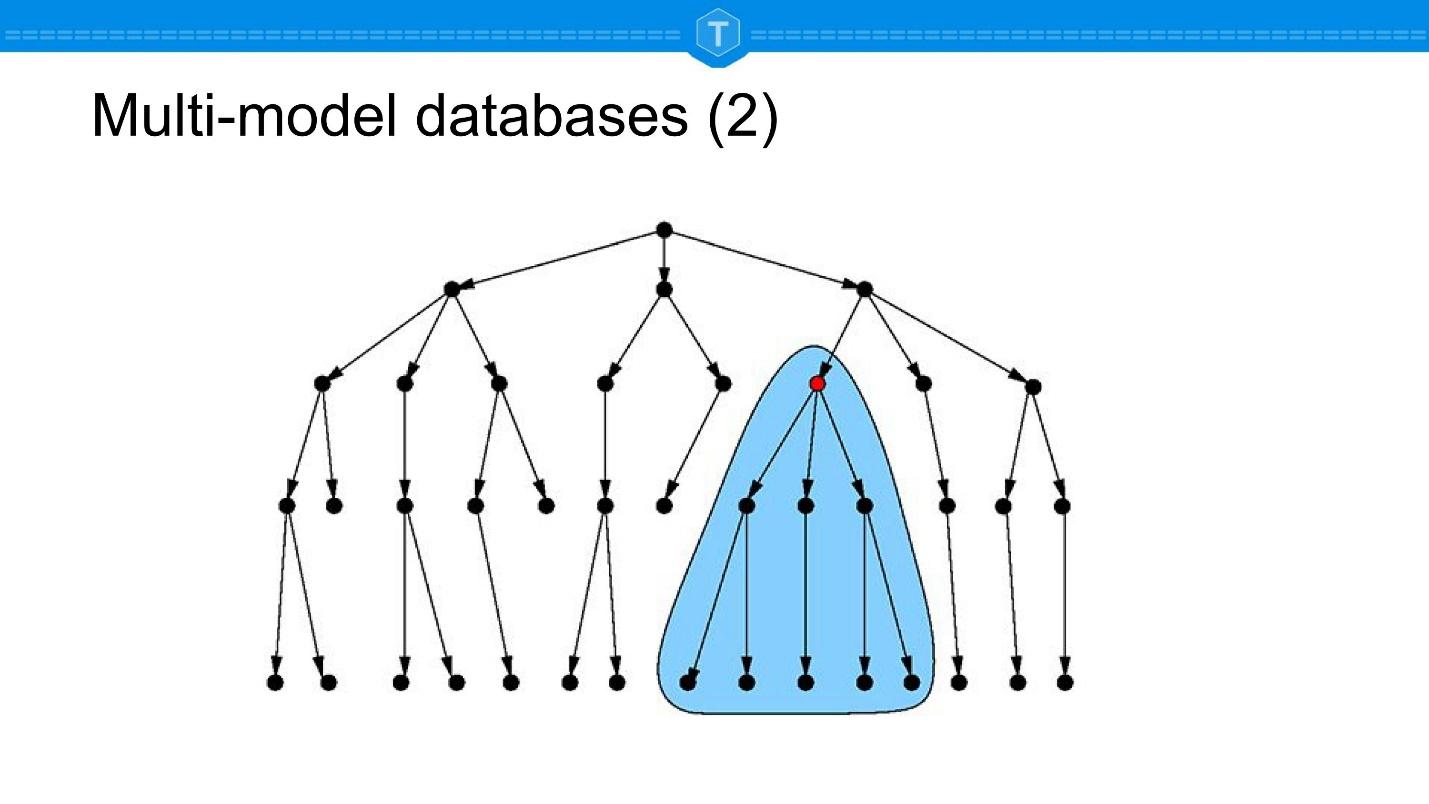
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
Isso não é inteiramente sobre o NoSQL, mas essa é uma tendência que me parece muito importante - esse é o
armazenamento otimizado para gravação - que, na minha opinião, permanecerá conosco seriamente e por muito tempo.
Nem o SQL nem o NoSQL têm instruções que são gravadas apenas por natureza. Mesmo ausente, que está no MongoDB, em vários casos, também lê dados. A inserção também é uma operação de leitura, porque se um ID já estiver definido no documento, será necessário verificar se esse ID não existe.
Você diz - se houver índices, devemos ler. Mas
mesmo se houver índices, a leitura nem sempre é necessária . A idéia é essa - você não quer ler de forma alguma, não precisa fazer isso, não se importa com o resultado da leitura. Você deseja adicionar dados ao banco de dados, se ele ainda não existir. Se eles existirem, digamos que você substitua a versão antiga por uma nova ou execute algum tipo de comando de mesclagem. Ou seja, você deve inventar uma
nova semântica para não ler.
Na minha opinião, nem um único banco de dados fornece isso agora, mas a atratividade dos algoritmos otimizados para gravação é tão grande que eu realmente quero essa possibilidade. Como graças ao armazenamento otimizado para gravação, o desempenho da gravação em árvores LSM (RocksDB, LevelDB e outras)
sem leitura é 2 ordens de magnitude maior que o desempenho com gravação . Em vez de 10 mil solicitações por segundo, pode haver um milhão em um nó.
É por isso que o banco de dados de séries temporais agora está ganhando porque não possui essa lacuna semântica. O fluxo de dados que chega neles é claramente definido como uma série temporal e é gravado de maneira muito rápida e compacta no banco de dados, em particular. porque você não precisa verificar a exclusividade. Essa é uma ordem de magnitude mais rápida, simplesmente porque nos bancos de dados tradicionais não existe uma operação semântica que seria apenas de gravação.
Eu acho que vai aparecer.

Para onde tudo isso vai a seguir? Se você olhar muito longe, a inovação não para no NoSQL e no NewSQL. Nossa compreensão da informação está em constante evolução.
Uma das tendências mais importantes do futuro, na minha opinião, é que excluiremos cada vez menos informações.
Para isso, nasce toda uma série de produtos, chamados bancos de dados temporais.
Após NewSQL: banco de dados temporal
Abaixo estão as capturas de tela do Microsoft SQL Server. Este é um banco de dados que permite que você faça perguntas até certo ponto: existe o SELECT para o estado atual, mas ainda é possível fazer o SELECT para alguma data no passado.

Isso gera uma série de novos aplicativos de banco de dados. Primeiro, você pode rastrear o histórico de um objeto. Em segundo lugar, você pode calcular automaticamente grupos, relatórios por período. Você não precisa criar tabelas separadas para isso - você tem uma representação natural em uma tabela: uma entidade - uma tabela.
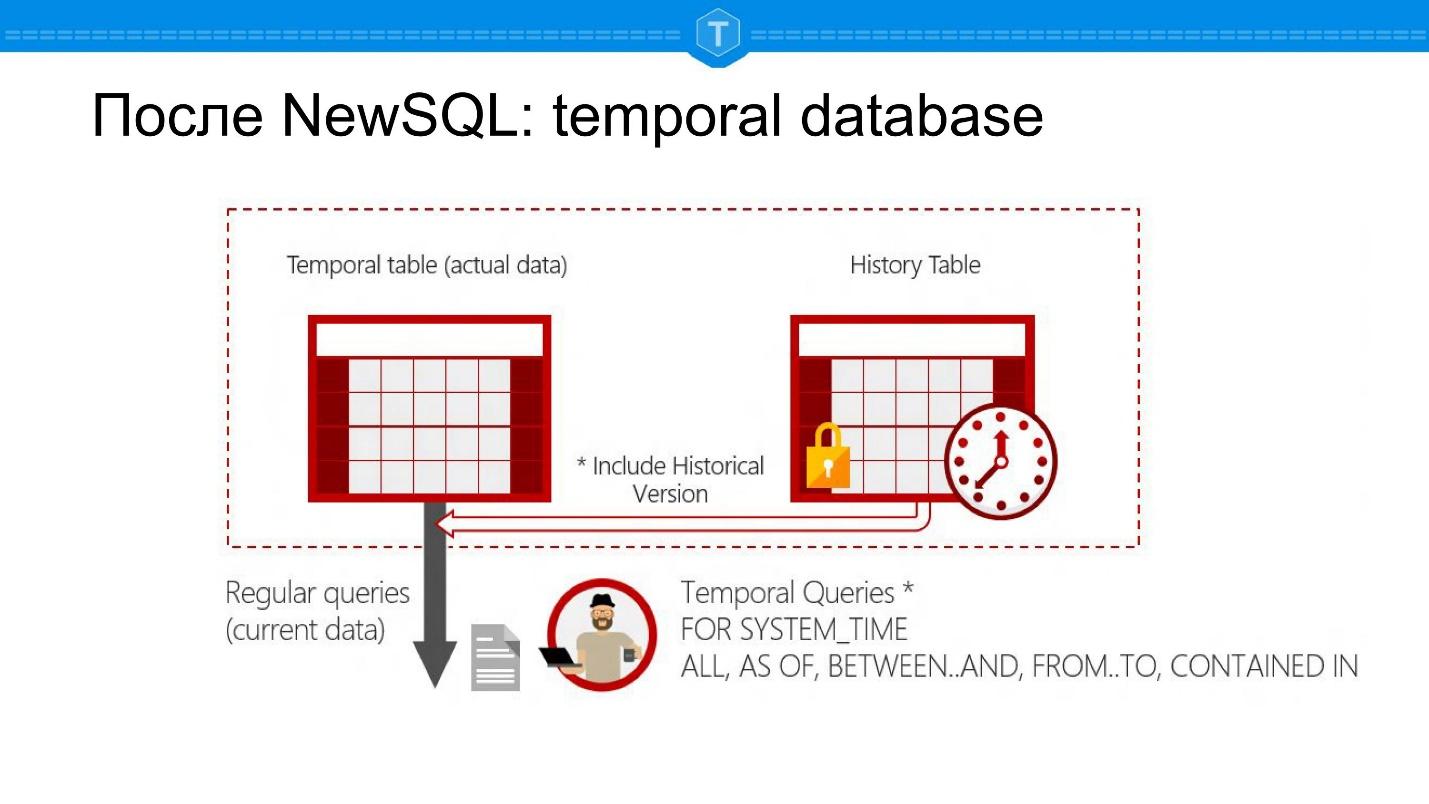
Do ponto de vista da estrutura interna, essa é realmente a tabela principal e a tabela com o histórico. Cada linha é associada a duas vezes conhecidas pelo sistema. Estas não são apenas duas colunas que você adicionou, mas dados que o sistema suporta automaticamente:
- a hora em que o registro foi adicionado ao banco de dados,
- hora do evento.
São tempos diferentes, não importa o quão divertido seja.
Suponha que Ivan Ivanovich tenha morrido em 17 de novembro e esse registro tenha sido inserido no banco de dados em 20 de novembro - ambos os horários são armazenados nesses bancos de dados.
Na minha opinião, esta é também uma das tendências fundamentais. Por que eu penso assim? Se retornarmos às chaves secundárias e à consistência Eventual, armazenar absolutamente tudo permitirá que você resolva esse problema com elegância.
Se nunca precisarmos excluir nada do banco de dados, nosso banco de dados será sempre consistente - uma história interessante!
Links úteis
Perguntas frequentes- Existe algum desenvolvimento na criação de um novo banco de dados que não se aplique ao MySQL, PostgreSQL, MongoDB, etc.?
De uma maneira boa, a pergunta é: haverá novos bancos de dados, startups? Eu acho que eles aparecerão cada vez menos. A tempestade diminuiu e agora veremos mais cedo a partida do que a chegada, o CockroachDB foi um dos últimos a chegar.
Vamos direto ao ponto. Meu professor da universidade disse que o DBMS é uma área eternamente verde. Portanto, sempre veremos algum tipo de movimento. Mas acho que, no futuro próximo, produtos fundamentalmente diferentes não aparecerão, haverá convergência, não um boom.
- Não é uma pergunta, mas uma adição: o SQL geralmente tenta fazer índices de cobertura para que o resultado da consulta SQL não se refira ao nível de armazenamento, mas seja imediatamente obtido a partir do índice. O próprio índice é realmente um caso especial do gráfico. Então, talvez a tendência seja que todo o banco de dados flua gradualmente para um índice de gráfico acentuado?
Esta é uma história maravilhosa que todos os representantes dos bancos de dados gráficos adoram contar aos seus clientes - ela não funciona! Porque existem várias maneiras de atualizar índices e muitas opções de indexação, mas nem todo mundo tem um gráfico! Vamos nos acalmar - assim como nem tudo é relacional, nem todo mundo é um gráfico.
- Na sua opinião, para onde o Elastic e similares vão? Estou falando do fato de que ele está começando a resolver problemas muito estranhos - ele está tentando fingir séries temporais e uma base analítica para trabalhar com logs. Parece que ninguém o usa para pesquisa de texto.
O Elastic não precisa se mover em nenhum lugar porque o Elastic é ótimo. Ele resolve um problema específico de negócios - é uma pesquisa eficaz e tudo relacionado a esse ecossistema.
Eu acho que tudo deriva principalmente do fato de o Elastic estar tentando ser tudo. Mas aqui a questão é da tarefa, a tarefa Elastic é muito semelhante às tarefas da série temporal, portanto, é justificada. O Elastic é bom para pesquisar em grandes matrizes dos mesmos logs, etc.
Há um caso mais restrito - é apenas uma pesquisa de texto completo, mas você não faz muito disso. É preciso fazer mais para diferenciar dos concorrentes em primeiro lugar. Portanto, tudo isso está acontecendo.
Mas não acho que o Elastic faça transações bancárias amanhã. Tudo vai ao ponto que o Couchbase, por exemplo, será - se não transações bancárias, mas algo tão rápido.
Notícias
Muito em breve, em 21 de junho, a Conferência Tarantool ocorrerá em Moscou - ou brevemente T + Conf - uma conferência não apenas sobre o próprio Tarantool, mas sobre o uso da computação em memória em geral .
- Konstantin Osipov planeja fazer um relatório no qual ele examinará a arquitetura do Vinyl, suas capacidades e, o mais importante, os mecanismos de ajuste e monitoramento de desempenho específicos para esse mecanismo da maneira mais consistente e detalhada possível.
- Vladimir Perepelitsa, em um formato de tutorial, quer mostrar que o Tarantool é um banco de dados com grande potencial para uso como servidor de aplicativos.
- Vladislav Zaitsev de abordar esse tópico do seu lado - do lado da Internet das coisas e dizer , em particular, por que o sistema de controle da Internet das coisas.