Cada um de nós faz uma tarefa. Todo mundo escreve o código padrão. Porque Não é melhor automatizar esse processo e trabalhar apenas em tarefas interessantes? Leia este artigo se desejar que o computador faça esse trabalho para você.
 Este artigo é baseado na transcrição de um relatório de Zack Sweers, desenvolvedor de aplicativos móveis do Uber, que falou na conferência MBLT DEV em 2017.
Este artigo é baseado na transcrição de um relatório de Zack Sweers, desenvolvedor de aplicativos móveis do Uber, que falou na conferência MBLT DEV em 2017.
O Uber tem cerca de 300 desenvolvedores de aplicativos móveis. Eu trabalho em uma equipe chamada "plataforma móvel". O trabalho da minha equipe é simplificar e melhorar o processo de desenvolvimento de aplicativos móveis, tanto quanto possível. Trabalhamos principalmente em estruturas internas, bibliotecas, arquiteturas etc. Devido à grande equipe, temos que fazer projetos em larga escala que nossos engenheiros precisarão no futuro. Pode ser amanhã, ou talvez no próximo mês ou até um ano.
Geração de código para automação
Gostaria de demonstrar o valor do processo de geração de código, bem como considerar alguns exemplos práticos. O processo em si é algo como isto:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
Este é um exemplo do uso do Kotlin Poet. O Kotlin Poet é uma biblioteca com uma boa API que gera código Kotlin. Então, o que vemos aqui?
- FileSpec.builder cria um arquivo chamado " Apresentação ".
- .addComment () - adiciona um comentário ao código gerado.
- .addAnnotation () - Adiciona uma anotação do tipo Autor .
- .addMember () - adiciona uma variável " name " com um parâmetro, no nosso caso é " Zac Sweers ". % S - tipo de parâmetro.
- .useSiteTarget () - Instala o SiteTarget.
- .build () - completa a descrição do código que será gerado.
Após a geração do código, é obtido o seguinte:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
O resultado da geração de código é um arquivo com o nome, comentário, anotação e nome do autor. Surge imediatamente a pergunta: "Por que preciso gerar esse código se posso fazê-lo em algumas etapas simples?" Sim, você está certo, mas e se eu precisar de milhares desses arquivos com diferentes opções de configuração? O que acontece se começarmos a alterar os valores nesse código? E se tivermos muitas apresentações? E se tivermos muitas conferências?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
Como resultado, chegaremos à conclusão de que é simplesmente impossível manter esse número de arquivos manualmente - é necessário automatizar. Portanto, a primeira vantagem da geração de código é livrar-se do trabalho de rotina.
Geração de código sem erros
A segunda vantagem importante da automação é a operação sem erros. Todas as pessoas cometem erros. Isso acontece especialmente quando fazemos a mesma coisa. Os computadores, pelo contrário, fazem esse trabalho perfeitamente.
Considere um exemplo simples. Existe uma classe Person:
class Person(val firstName: String, val lastName: String)
Suponha que desejemos adicionar serialização a ele no JSON. Faremos isso usando a biblioteca
Moshi , pois é bastante simples e excelente para demonstração. Crie um PersonJsonAdapter e herde do JsonAdapter com um parâmetro do tipo Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
Em seguida, implementamos o método fromJson. Ele fornece um leitor para ler informações que finalmente serão retornadas para Person. Em seguida, preenchemos os campos com o nome e o sobrenome e obtemos o novo valor de Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
A seguir, examinamos os dados no formato JSON, verificamos e inserimos nos campos necessários:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
Isso vai funcionar? Sim, mas há uma nuance: os objetos que lemos devem estar contidos no JSON. Para filtrar dados em excesso que podem vir do servidor, adicione outra linha de código:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
Neste ponto, contornamos com êxito a área do código de rotina. Neste exemplo, apenas dois campos de valor. No entanto, esse código possui várias seções diferentes nas quais você pode travar repentinamente. De repente, cometemos um erro no código?
Considere outro exemplo:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
Se você tiver pelo menos um problema a cada 10 modelos, isso significa que você definitivamente terá dificuldades nessa área. E este é o caso em que a geração de código pode realmente ajudá-lo. Se houver muitas classes, você não poderá trabalhar sem automação, porque todas as pessoas permitem erros de digitação. Com a ajuda da geração de código, todas as tarefas serão executadas automaticamente e sem erros.
Existem outros benefícios para a geração de código. Por exemplo, fornece informações sobre o código ou informa se algo der errado. A geração de código será útil durante a fase de teste. Se você usar o código gerado, poderá ver como o código de trabalho realmente ficará. Você pode até executar a geração de código durante os testes para simplificar seu trabalho.
Conclusão: vale a pena considerar a geração de código como uma possível solução para se livrar dos erros.
Agora vamos ver as ferramentas de software que ajudam na geração de código.
As ferramentas
- As bibliotecas JavaPoet e KotlinPoet para Java e Kotlin, respectivamente. Esses são os padrões de geração de código.
- Padronização. Um exemplo popular de modelagem para Java é o Apache Velocity e para o guidão do iOS.
- SPI - Service Processor Interface. Ele é incorporado ao Java e permite criar e aplicar uma interface e, em seguida, declará-la em um JAR. Quando o programa é executado, você pode obter todas as implementações prontas da interface.
- O Compile Testing é uma biblioteca do Google que ajuda no teste de compilação. Em termos de geração de código, isso significa: "Aqui está o que eu esperava, mas aqui está o que eu finalmente recebi". A compilação começará na memória e, em seguida, o sistema informará se esse processo foi concluído ou que erros ocorreram. Se a compilação tiver sido concluída, você será solicitado a comparar o resultado com as suas expectativas. A comparação é baseada no código compilado; portanto, não se preocupe com coisas como formatação de código ou qualquer outra coisa.
Ferramentas de criação de código
Existem duas ferramentas principais para criar código:
- Processamento de anotações - você pode escrever anotações no código e solicitar ao programa informações adicionais sobre elas. O compilador fornecerá informações mesmo antes de terminar de trabalhar com o código-fonte.
- Gradle é um sistema de montagem de aplicativos com muitos ganchos (interceptação de gancho de chamadas de função) em seu ciclo de vida de montagem de código. É amplamente utilizado no desenvolvimento do Android. Também permite aplicar a geração de código ao código-fonte, independente da fonte atual.
Agora considere alguns exemplos.
Faca de manteiga
Butter Knife é uma biblioteca desenvolvida por Jake Wharton. Ele é uma figura bem conhecida na comunidade de desenvolvedores. A biblioteca é muito popular entre os desenvolvedores do Android porque ajuda a evitar a grande quantidade de trabalho rotineiro que quase todo mundo enfrenta.
Normalmente, inicializamos a visualização desta maneira:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
Com o Butterknife, ficará assim:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
E podemos adicionar facilmente qualquer número de visualizações, enquanto o método onCreate não aumentará o código padrão:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Em vez de fazer manualmente essa ligação a cada vez, basta adicionar anotações do @BindView a esses campos, bem como identificadores (IDs) aos quais estão atribuídos.
O legal do Butter Knife é que ele analisará o código e gerará todas as seções semelhantes a você. Também possui excelente escalabilidade para novos dados. Portanto, se novos dados aparecerem, não há necessidade de aplicar o onCreate novamente ou rastrear algo manualmente. Essa biblioteca também é ótima para excluir dados.
Então, como é esse sistema por dentro? A visualização é pesquisada pelo reconhecimento de código e esse processo é executado no estágio de processamento da anotação.
Nós temos este campo:
@BindView(R.id.title) TextView title;
A julgar por esses dados, eles são usados em uma certa FooActivity:
Ela tem seu próprio significado (R.id.title), que atua como alvo. Observe que, durante o processamento dos dados, esse objeto se torna um valor constante dentro do sistema:
Isso é normal. É a isso que o Butter Knife deve ter acesso de qualquer maneira. Há um componente TextView como um tipo. O próprio campo é chamado title. Se, por exemplo, criamos uma classe de contêiner com esses dados, obtemos algo parecido com isto:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
Portanto, todos esses dados podem ser facilmente obtidos durante o processamento. Também é muito semelhante ao que o Butter Knife faz dentro do sistema.
Como resultado, esta classe é gerada aqui:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
Aqui vemos que todos esses dados são reunidos. Como resultado, temos a classe de destino ViewBinding da biblioteca java Underscore. Por dentro, esse sistema é organizado de tal maneira que toda vez que você cria uma instância da classe, ele executa imediatamente toda essa ligação com as informações (código) que você gerou. E tudo isso é gerado estaticamente anteriormente durante o processamento de anotações, o que significa que é tecnicamente correto.
Vamos voltar ao nosso pipeline de software:
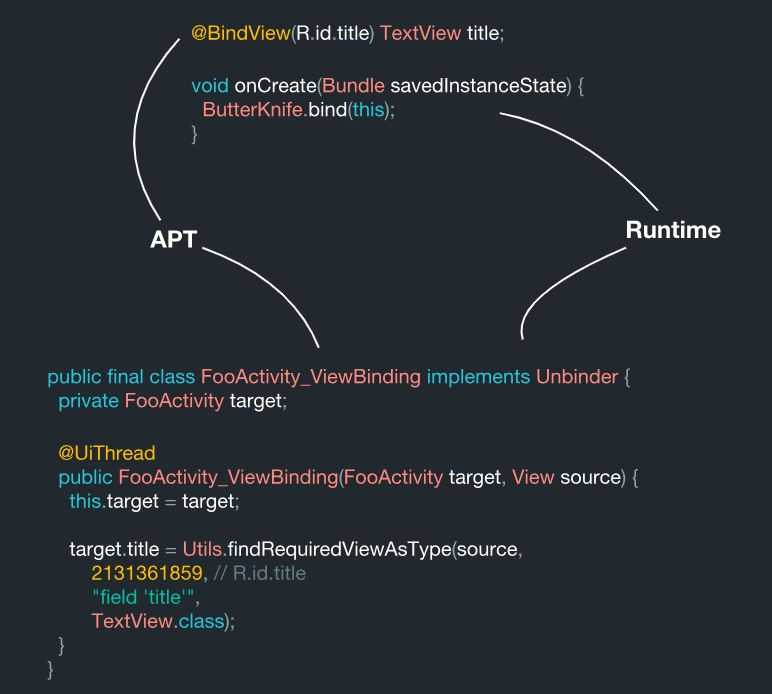
Durante o processamento da anotação, o sistema lê essas anotações e gera a classe ViewBinding. E então, durante o método bind, realizamos uma pesquisa idêntica para a mesma classe de uma maneira simples: pegamos seu nome e anexamos o ViewBinding no final. Por si só, uma seção com um ViewBinding durante o processamento é substituída na área especificada usando JavaPoet.
Rxbindings
RxBindings sozinho não é responsável pela geração de código. Ele não manipula anotações e não é um plug-in Gradle. Esta é uma biblioteca comum. Ele fornece fábricas estáticas com base no princípio de programação reativa para a API do Android. Isso significa que, por exemplo, se você configurouOnClickListener, será exibido um método click que retornará um fluxo de eventos (Observáveis). Ele atua como uma ponte (padrão de design).
Mas, na verdade, há geração de código no RxBinding:
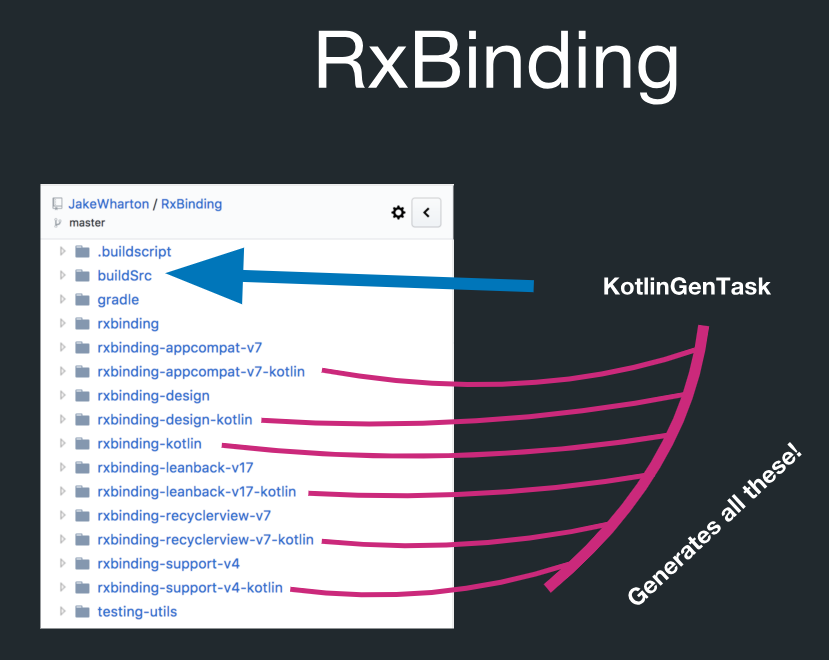
Nesse diretório chamado buildSrc, há uma tarefa Gradle chamada KotlinGenTask. Isso significa que tudo isso é realmente criado pela geração de código. O RxBinding possui implementações em Java. Ela também possui artefatos Kotlin que contêm funções de extensão para todos os tipos de destino. E tudo isso está estritamente sujeito às regras. Por exemplo, você pode gerar todas as funções de extensão Kotlin e não precisa controlá-las individualmente.
Como é realmente isso?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Aqui está um método RxBinding completamente clássico. Objetos observáveis são retornados aqui. O método é chamado de cliques. O trabalho com eventos de clique ocorre "sob o capô". Nós omitimos os fragmentos de código extras para manter a legibilidade do exemplo. No Kotlin, fica assim:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Esta função de extensão retorna objetos observáveis. Na estrutura interna do programa, ele chama diretamente a interface Java usual para nós. No Kotlin, você deve alterar isso para Tipo de unidade:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Ou seja, em Java, fica assim:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
E também é o código Kotlin:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Temos uma classe RxView que contém esse método. Podemos substituir as partes correspondentes dos dados no atributo target, no atributo name pelo nome do método e no tipo que estamos expandindo, bem como no tipo do valor de retorno. Toda essa informação será suficiente para começar a escrever estes métodos:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
Agora podemos substituir diretamente esses fragmentos no código Kotlin gerado dentro do programa. Aqui está o resultado:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Geração de serviço
Estamos trabalhando no Service Gen da Uber. Se você trabalha em uma empresa e lida com características gerais e uma interface de software comum para o back-end e o cliente, independentemente de estar desenvolvendo aplicativos Android, iOS ou Web, não faz sentido criar modelos e serviços manualmente para o trabalho em equipe.
Usamos a biblioteca
AutoValue do Google para modelos de objetos. Ele processa anotações, analisa dados e gera um código hash de duas linhas, o método equals () e outras implementações. Ela também é responsável pelo suporte a extensões.
Temos um objeto do tipo Rider:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Temos linhas com ID, nome, sobrenome e endereço. Para trabalhar com a rede, usamos as bibliotecas Retrofit e OkHttp e JSON como formato de dados. Também usamos RxJava para programação reativa. É assim que nosso serviço de API gerado se parece:
interface UberService { @GET("/rider") Rider getRider() }
Podemos escrever tudo isso manualmente, se assim o desejarmos. E por um longo período de tempo, nós fizemos. Mas leva muito tempo. No final, custa muito em termos de tempo e dinheiro.
O que e como o Uber faz hoje
A última tarefa da minha equipe é criar um editor de texto do zero. Decidimos não escrever mais manualmente o código que posteriormente atinge a rede, por isso usamos o
Thrift . É algo como uma linguagem de programação e um protocolo ao mesmo tempo. O Uber usa o Thrift como idioma para especificações técnicas.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
No Thrift, definimos contratos de API entre o back-end e o cliente e, em seguida, simplesmente geramos o código apropriado. Usamos a biblioteca
Thrifty para analisar dados e o JavaPoet para geração de código. No final, geramos implementações usando o AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Nós fazemos todo o trabalho em JSON. Existe uma extensão chamada
AutoValue Moshi , que pode ser adicionada às classes AutoValue usando o método estático jsonAdapter:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
A Thrift também ajuda no desenvolvimento de serviços:
service UberService { Rider getRider() }
Também precisamos adicionar alguns metadados aqui para nos informar qual resultado final queremos alcançar:
service UberService { Rider getRider() (path="/rider") }
Após a geração do código, receberemos nosso serviço:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
Mas este é apenas um dos resultados possíveis. Um modelo. Como sabemos por experiência, ninguém jamais usou apenas um modelo. Temos muitos modelos que geram código para nossos serviços:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
No momento, temos cerca de 5-6 aplicativos. E eles têm muitos serviços. E todo mundo passa pelo mesmo pipeline de software. Escrever tudo isso à mão seria uma loucura.
Na serialização em JSON, o “adaptador” não precisa ser registrado no Moshi e, se você usa o JSON, não precisa se registrar no JSON. Também é duvidoso sugerir que os funcionários realizem a desserialização reescrevendo o código por meio de um gráfico de DI.
Mas trabalhamos com Java, para que possamos usar o padrão Factory, que geramos através da biblioteca
Fractory . Podemos gerar isso porque conhecemos esses tipos antes da compilação. Fractory gera um adaptador como este:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
O código gerado não parece muito bom. Se machuca os olhos, pode ser reescrito manualmente.
Aqui você pode ver os tipos mencionados anteriormente com os nomes dos serviços. O sistema determinará automaticamente quais adaptadores serão selecionados e chamados. Mas aqui estamos diante de outro problema. Temos 6000 desses adaptadores. Mesmo se você as dividir entre si no mesmo modelo, o modelo “Come” ou “Conduz” se enquadra no modelo “Condutor” ou estará em sua aplicação. O código será estendido. Após um certo ponto, ele não pode nem caber em um arquivo .dex. Portanto, você precisa separar os adaptadores de alguma forma:

Por fim, analisaremos o código antecipadamente e criaremos um subprojeto de trabalho para ele, como em Gradle:

Na estrutura interna, essas dependências se tornam dependências Gradle. Os elementos que usam o aplicativo Rider agora dependem dele. Com isso, eles formarão os modelos de que precisam. Como resultado, nossa tarefa será resolvida e tudo isso será regulado pelo sistema de montagem de código dentro do programa.
Mas aqui estamos diante de outro problema: agora temos um número n de modelos de fábrica. Todos eles são compilados em vários objetos:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
No processo de processamento de anotações, não será possível ler apenas anotações em dependências externas e gerar geração de código adicional apenas nelas.
Solução: temos algum suporte na biblioteca Fractory, o que nos ajuda de uma maneira complicada. Está contido no processo de ligação de dados. Introduzimos metadados usando o parâmetro classpath no arquivo Java para seu armazenamento adicional:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
Agora, toda vez que você precisar usá-los no aplicativo, entramos no filtro do diretório classpath com esses arquivos e os extraímos a partir daí no formato JSON para descobrir quais dependências estão disponíveis.
Como tudo se encaixa
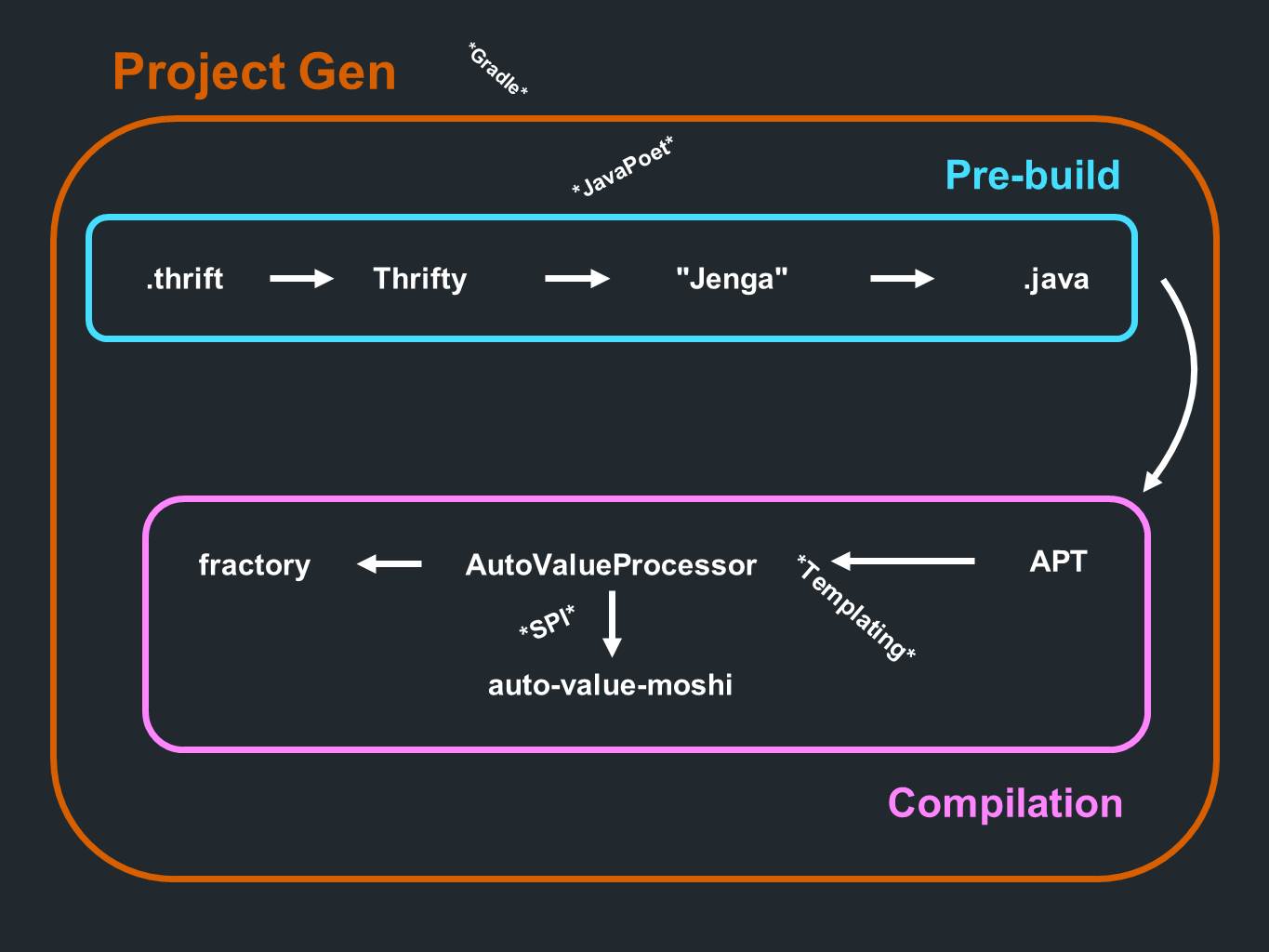
Temos uma
economia . Os dados de lá vão para a
Thrifty e passam pela análise. Eles passam por um programa de geração de código que chamamos de
Jenga . Produz arquivos no formato Java. Tudo isso acontece mesmo antes da fase preliminar de processamento ou antes da compilação. E durante o processo de compilação, as anotações são processadas. É
a vez
do AutoValue gerar uma implementação. Também chama o
AutoValue Moshi para fornecer suporte a JSON.
Fractory também
está envolvido . Tudo acontece durante o processo de compilação. O processo é precedido por um componente para criar o próprio projeto, que gera principalmente subprojetos
Gradle .
Agora que você vê a imagem completa, começa a perceber as ferramentas mencionadas anteriormente. Por exemplo, existe o Gradle, criando modelos, AutoValue, JavaPoet para geração de código. Todas as ferramentas são úteis não só por si próprias, mas também em combinação.Contras da geração de código
É necessário contar sobre armadilhas. O menos óbvio é inchar o código e perder o controle dele. Por exemplo, o Dagger ocupa aproximadamente 10% de todo o código no aplicativo. Os modelos ocupam uma parcela significativamente maior - cerca de 25%.Na Uber, tentamos resolver o problema jogando fora o código desnecessário. Temos que realizar algumas análises estatísticas do código e entender quais áreas estão realmente envolvidas no trabalho. Quando descobrimos, podemos fazer algumas transformações e ver o que acontece.Esperamos reduzir o número de modelos gerados em cerca de 40%. Isso ajudará a acelerar a instalação e a operação de aplicativos, além de economizar dinheiro.Como a geração de código afeta os cronogramas de desenvolvimento do projeto
A geração de código, é claro, acelera o desenvolvimento, mas o tempo depende das ferramentas que a equipe usa. Por exemplo, se você estiver trabalhando em Gradle, provavelmente estará fazendo isso em um ritmo medido. O fato é que Gradle gera modelos uma vez por dia, e não quando o desenvolvedor deseja.Saiba mais sobre desenvolvimento no Uber e em outras empresas importantes.
Em 28 de setembro, a 5ª Conferência Internacional de Desenvolvedores Móveis MBLT DEV começa em Moscou . 800 participantes, palestrantes, questionários e quebra-cabeças para quem estiver interessado no desenvolvimento do Android e iOS. Os organizadores da conferência são e-Legion e RAEC. Você pode se tornar um participante ou parceiro do MBLT DEV 2018 no site da conferência .
Denunciar vídeo