
No verão passado, terminou a
competição no site kaggle, dedicada à classificação de imagens de satélite das florestas amazônicas. Nossa equipe ficou em 7º lugar entre mais de 900 participantes. Apesar de a competição ter terminado há muito tempo, quase todos os métodos de nossa solução ainda são aplicáveis, e não apenas para competições, mas também para o treinamento de redes neurais à venda. Para detalhes em cat.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
Descrição da tarefa
A Planet preparou um conjunto de imagens de satélite em dois formatos:
- TIF - 16 bits RGB + N, onde N - Próximo ao infravermelho
- JPG - RGB de 8 bits, derivados do TIF e fornecidos para reduzir o limite de entrada na tarefa e para simplificar a visualização. Na competição anterior do Kaggle, era necessário trabalhar com imagens multiespectrais. não visual, isto é, infravermelho, bem como canais com comprimento de onda maior, melhorou bastante a qualidade da previsão, tanto na rede quanto nos métodos não supervisionados.
Geograficamente, foram coletados dados do território da bacia amazônica e dos territórios dos países do Brasil, Peru, Uruguai, Colômbia, Venezuela, Guiana, Bolívia e Equador, nos quais foram selecionadas áreas de superfície interessantes, cujas fotos foram oferecidas aos participantes.
Depois de criar jpg a partir de tif, todas as cenas foram cortadas em pequenos pedaços de tamanho 256x256. E de acordo com o jpg recebido pelos funcionários da Planet nos escritórios de Berlim e San Francisco, bem como através da plataforma Crowd Flower, a marcação foi realizada.
Os participantes foram incumbidos de prever, para cada bloco de 256x256, uma das marcas meteorológicas mutuamente exclusivas:
Nublado, Parcialmente nublado, Nublado, Nublado
E também 0 ou mais intempéries: Agricultura, Primário, Extração Seletiva, Habitação, Água, Estradas, Cultivo de Mudança, Florescência, Mineração Convencional
Um total de 4 condições climáticas e 13 condições não climáticas, clima mutuamente exclusivo, mas sem clima, mas se a imagem estiver nublada, não haverá outras tags.

A precisão do modelo foi estimada pela métrica F2:
Pontuação=(1+ beta2) fracpr( beta2p+r)
p= fractptp+fp
r= fractptp+fn
beta=2
Além disso, todos os rótulos tinham o mesmo peso e o primeiro F2 foi calculado para cada foto e, em seguida, houve uma média geral. Geralmente eles fazem isso de maneira um pouco diferente, ou seja, uma determinada métrica é calculada para cada classe e, em seguida, calculada a média. A lógica é que a última opção é mais interpretável, pois permite responder à pergunta de como o modelo se comporta em cada classe específica. Nesse caso, os organizadores foram de acordo com a primeira opção, que, aparentemente, está relacionada às especificidades de seus negócios.
Existem 40 mil amostras no trem. No teste de 40k. Devido ao tamanho pequeno do conjunto de dados, mas ao tamanho grande das imagens, podemos dizer que este é "MNIST em esteróides"
Digressão líricaComo você pode ver na descrição, a tarefa é bastante compreensível e a solução não é do tipo foguete: você só precisa arquivar a grade. E, levando em conta as especificidades da maca, você também pode empilhar vários modelos por cima. No entanto, para obter uma medalha de ouro, você não precisa apenas treinar, de alguma forma, vários modelos. É imperativo ter muitos modelos básicos diversos, cada um dos quais mostra um resultado notável. E já em cima desses modelos, você pode acabar empilhando e outros hacks.
| membro | net | 1crop | Tta | diff,% |
|---|
| alno | densenet121 | 0,9278 | 0,9294 | 0,1736 |
| nizhib | densenet169 | 0,9243 | 0,9277 | 0,3733 |
| romul | vgg16 | 0,9266 | 0,9267 | 0,0186 |
| ternaus | densenet121 | 0,9232 | 0,9241 | 0,0921 |
| albu | densenet121 | 0,9294 | 0,9312 | 0,1933 |
| kostia | resnet50 | 0,9262 | 0,9271 | 0,0907 |
| n01z3 | resnext50 | 0,9281 | 0,9298 | 0,1896 |
A tabela mostra os modelos de pontuação F2 de todos os participantes para uma cultura e TTA. Como você pode ver, a diferença é pequena para uso real, mas é importante para o modo de competição.
Interação da equipeAlexander Buslaev
albuNo momento da participação na competição, ele liderou toda a direção da ml no Geoscan. Mas, desde então, ele organizou várias competições, tornou-se o pai de todos os ODS na segmentação semântica e partiu para Minsk, remando no Mapbox, sobre o qual o
artigo foi
publicado.Alexey Noskov
alnoLutador universal de ml. Trabalhou no Evil Marciano. Agora rolou para o Yandex.
Konstantin Lopukhin
kostialopuhinTrabalhou e continua a trabalhar na Scrapinghub. Desde então, Kostya conseguiu mais algumas medalhas e, sem 5 minutos, Kaggle Grandmaster
Arthur Primo
n01z3No momento da participação nessa competição, eu trabalhava na Avito. Mas por volta do ano novo,
a startup Lead Data Scientist
da Dbrain passou para a blockchain. Espero que em breve encantemos a comunidade com nossas competições com estivadores e marcações de lâmpadas.
Evgeny Nizhibitsky
@nizhibCientista de Dados Líder na Rambler & Co. A partir dessa competição, Eugene descobriu a capacidade secreta de encontrar rostos em competições de imagens. O que o ajudou a arrastar algumas competições na plataforma Topcoder. Eu
falei sobre um deles.
Ruslan
Baykulov romulEnvolvido no rastreamento de eventos esportivos em Constanta.
Vladimir Iglovikov
ternausVocê poderia ser lembrado por um
artigo cheio de ação sobre assédio da inteligência britânica. Ele trabalhou na TrueAccord, mas depois ingressou na juventude Lyft. Onde o Computer Vision funciona para carros autônomos? Continua a arrastar competições e recentemente recebeu o Kaggle Grandmaster.
Nossa associação e formato de participação podem ser chamados de típicos. A decisão de nos unir deveu-se ao fato de todos termos resultados próximos na tabela de classificação. E cada um de nós viu nosso próprio pipeline independente, que era uma solução completamente autônoma do começo ao fim. Além disso, após a fusão, vários participantes estavam envolvidos no empilhamento.
A primeira coisa que fizemos foi compartilhar dobras. Garantimos que a distribuição de classes em cada dobra fosse a mesma que em todo o conjunto de dados. Para isso, a classe mais rara foi escolhida pela primeira vez, estratificada por ela, porque as fotos restantes foram estratificadas pela segunda classe mais popular, e assim por diante até que não houvesse mais imagens.
Histograma das classes de dobra:
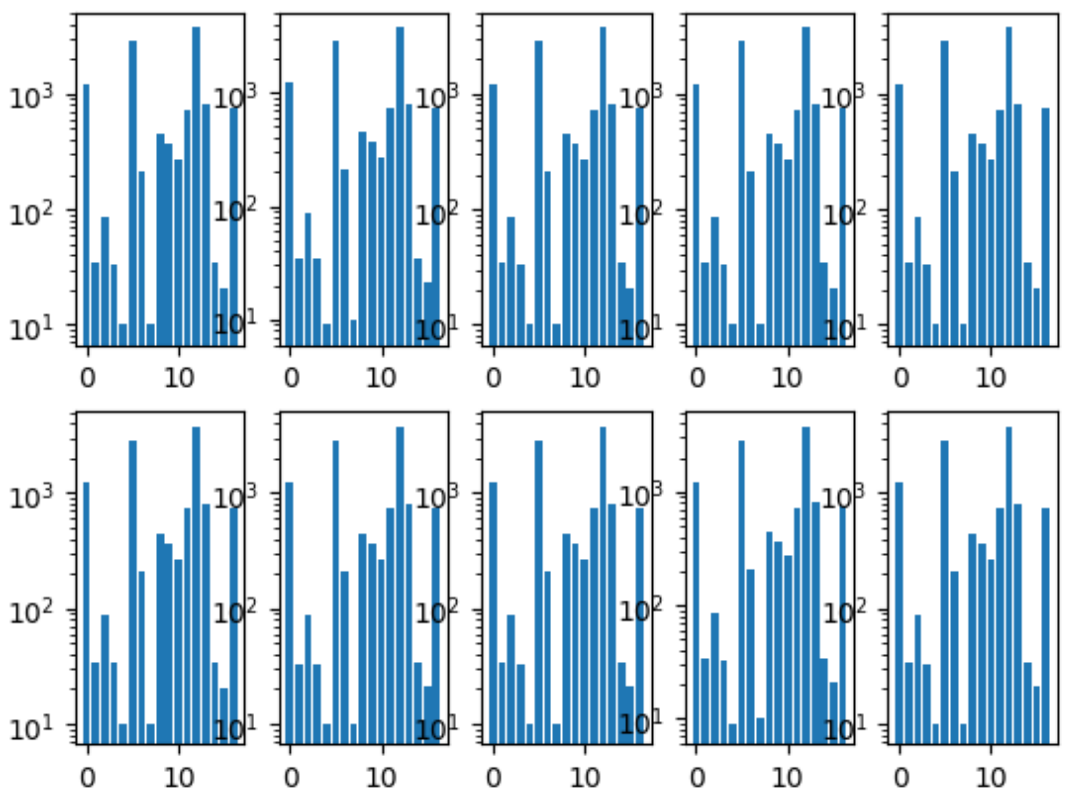
Também tínhamos um repositório comum, onde cada membro da equipe tinha sua própria pasta, dentro da qual ele organizou o código como queria.
E também concordamos com o formato das previsões, porque esse era o único ponto de interação para combinar nossos modelos.
Treinamento em redes neuraisComo cada um de nós tinha um canal independente, éramos uma amostra da grade do processo ideal de aprendizado paralelizado pelas pessoas.
Abordagem geral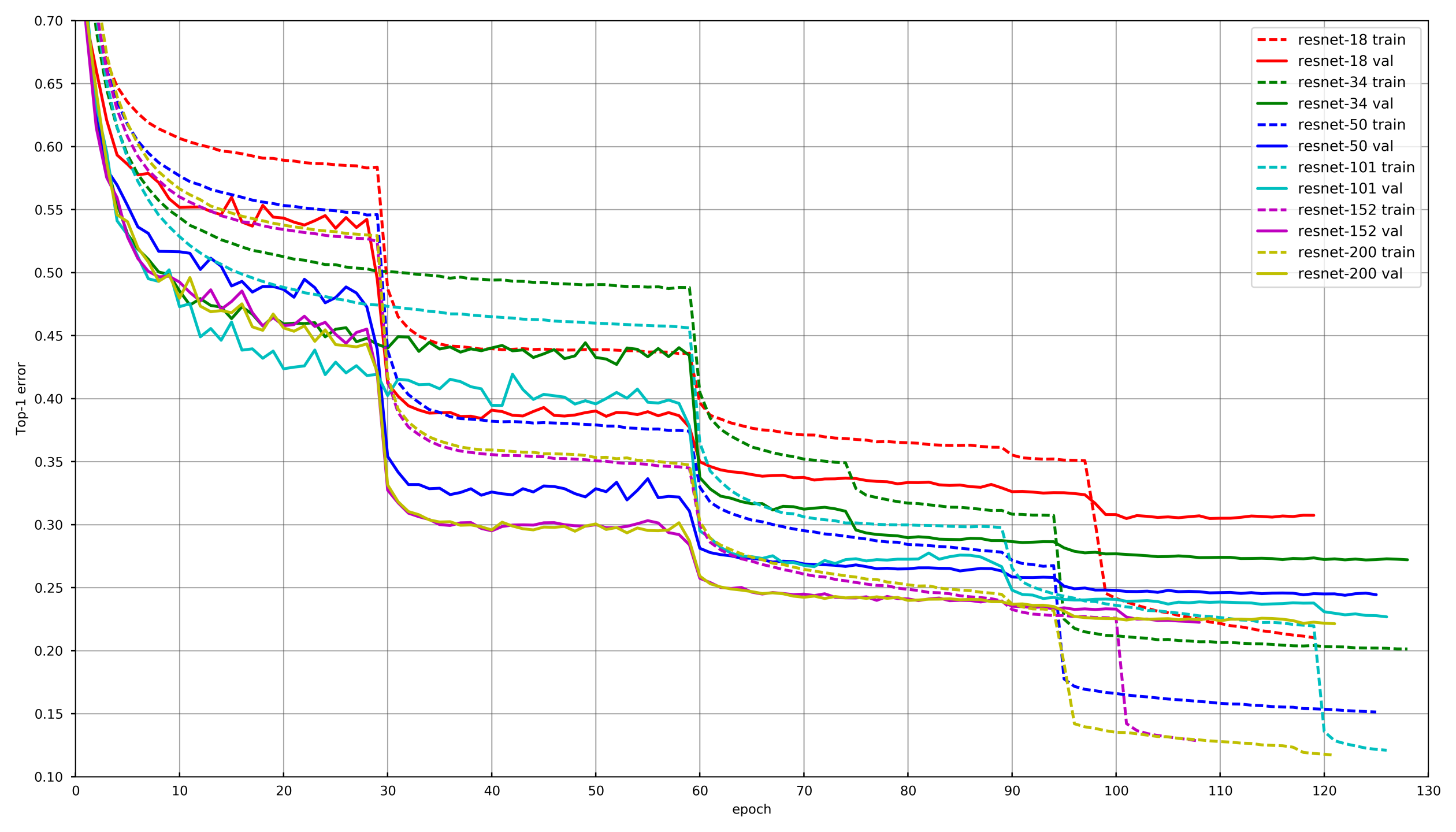
Imagem de
github.com/tornadomeet/ResNetUm processo de aprendizado típico é apresentado no cronograma de treinamento das redes neurais da Resnet na imagenet. Eles começam com pesos inicializados aleatoriamente com SGD (lr 0,1 Nesterov Momentum 0,0001 WD 0,9) e depois de 30 apagamentos, diminua a taxa de aprendizado em 10 vezes.
Conceitualmente, cada um de nós usou a mesma abordagem, no entanto, para não envelhecer enquanto aprendia cada rede, a diminuição da LR ocorria se a validação não reduzisse a perda por 3-5 eras seguidas. Ou, alguns participantes simplesmente reduziram o número de eras em cada dano de RL e diminuíram de acordo com o cronograma.
AumentoEscolher os aumentos certos é muito importante ao treinar redes neurais. Aumentos devem refletir a variabilidade da natureza dos dados. Convencionalmente, os aumentos podem ser divididos em dois tipos: aqueles que introduzem viés nos dados e aqueles que não. Por viés, pode-se entender várias estatísticas de baixo nível, como histogramas de cores ou tamanho das características. Nesse sentido, digamos, os aumentos e escalas do HSV introduzem um deslocamento, mas uma colheita aleatória não.
Nos primeiros estágios do treinamento da rede, você pode ir longe demais com aprimoramentos e usar um conjunto muito difícil. No entanto, no final do treinamento, você deve desativar os aprimoramentos ou deixar apenas aqueles que não apresentam viés. Isso permite que a rede neural se ajuste demais um pouco sob o trem e mostre um resultado um pouco melhor na validação.
Congelamento de camadasNa grande maioria das tarefas, não faz sentido treinar uma rede neural do zero, é muito mais eficiente mexer com redes pré-treinadas, digamos com a Imagenet. No entanto, você pode ir além e não apenas alterar a camada totalmente conectada sob a camada com o número desejado de classes, mas primeiro treiná-la com o congelamento de todas as convoluções. Se você não congelar as convoluções e treinar imediatamente toda a rede com pesos inicializados aleatoriamente de uma camada totalmente conectada, os pesos das convoluções serão corrompidos e o desempenho final da rede neural será menor. Nesta tarefa, isso foi especialmente notável devido ao pequeno tamanho da amostra de treinamento. Em outras competições com uma grande quantidade de dados, como o desconto no CD, não foi possível congelar toda a rede neural, mas grupos de convoluções a partir do final. Dessa maneira, o treinamento poderia ser bastante acelerado, pois os gradientes não eram considerados para as camadas congeladas.
Recozimento cíclicoEsse processo se parece com isso. Após a conclusão do processo básico de treinamento da rede neural, os melhores pesos são obtidos e o processo de treinamento é repetido. Mas começa com uma taxa de aprendizado mais baixa e ocorre em um curto período de tempo, digamos 3-5 eras. Isso permite que a rede neural diminua para um mínimo local mais baixo e mostre um melhor desempenho. Esta campanha estável melhora o resultado em um número bastante amplo de concursos.
Mais detalhadamente sobre duas recepções
aquiAumentos do tempo de testeComo se trata de uma competição e não temos uma restrição formal ao tempo de inferência, você pode usar aprimoramentos durante o teste. Parece que a imagem está distorcida da mesma maneira que aconteceu durante o treinamento. Digamos, ele é refletido verticalmente, horizontalmente, girado por um ângulo etc. Cada aumento fornece uma nova imagem a partir da qual obtemos previsões. Em seguida, as previsões de tais distorções de uma imagem são calculadas como média (em regra por meios geométricos). Também dá lucro. Em outras competições, também experimentei aumentos aleatórios. Digamos, você pode aplicar não um de cada vez, mas simplesmente reduzir a amplitude para curvas aleatórias, contrastes e aumento de cores pela metade, fixar a semente e fazer várias imagens distorcidas aleatoriamente. Isso também deu um aumento.
Conjunto de instantâneos (TTA de pontos de verificação múltiplos)A idéia de recozimento pode ser desenvolvida ainda mais. Em cada estágio do recozimento, a rede neural voa para mínimos locais ligeiramente diferentes. E isso significa que esses são modelos essencialmente ligeiramente diferentes que podem ser calculados em média. Assim, durante as previsões do teste, você pode fazer os três melhores pontos de verificação e calcular a média de suas previsões. Eu também tentei pegar não os três melhores, mas os três mais diversos dos 10 melhores - era pior. Bem, para a produção, esse truque não é aplicável e tentei calcular o peso dos modelos. Isso deu um aumento muito insignificante, mas constante.
 Abordagens de cada membro da equipe
Abordagens de cada membro da equipeAssim, em um grau ou outro, cada membro de nossa equipe usou uma combinação diferente das técnicas acima.
| nick | Congelar conv,
época | Optimizer | Estratégia | Agosto | Tta |
|---|
| albu | 3 | SGD | Decadência LR de 15 épocas,
Círculo 13 épocas | D4,
Escala,
Deslocamento
Distorção
Contraste
Desfocar | D4 |
|---|
| alno | 3 | SGD | Lr decadência | D4,
Escala,
Deslocamento
Distorção
Contraste
Desfocar
Cisalhamento
Multiplicador de canal | D4 |
|---|
| n01z3 | 2 | SGD | Drop LR, paciente 10 | D4,
Escala,
Distorção
Contraste
Desfocar | D4, 3 pontos de verificação |
|---|
| ternaus | - | Adam | LR cíclico (1e-3: 1e-6) | D4,
Escala,
Adição de canal
Contraste | D4,
colheita aleatória |
|---|
| nizhib | - | Adam | StepLR, 60 épocas, 20 por decaimento | D4,
RandomSizedCrop | D4,
4 cantos,
centro
escala |
|---|
| kostia | 1 | Adam | | D4,
Escala,
Distorção
Contraste
Desfocar | D4 |
|---|
| romul | - | SGD | base_lr: 0,01 - 0,02
lr = base_lr * (0,33 ** (época / 30))
Época: 50 | D4, Escala | D4, recorte central,
Culturas de canto |
|---|
Empilhamento e hacksNós treinamos cada modelo com cada conjunto de parâmetros em 10 dobras. E então, nas previsões fora da dobra (OOF), treinamos modelos de segundo nível: Árvores Extra, Regressão Linear, Rede Neural e simplesmente modelos de média.
E já na OOF, as previsões dos modelos de segundo nível pegaram peso na mistura. Você pode ler mais sobre empilhamento
aqui e
aqui .
Na produção real, curiosamente, essa abordagem também ocorre. Por exemplo, quando há dados multimodais (figuras, texto, categorias etc.) e você deseja combinar as previsões dos modelos. Você pode simplesmente calcular a média das probabilidades, mas o treinamento de um modelo de segundo nível fornece o melhor resultado.
Otimização de Baes F2Além disso, as previsões finais se ajustaram um pouco usando a otimização bayesiana. Suponha que tenhamos probabilidades ideais e, em seguida, F2 com o melhor tapete de expectativas (ou seja, do tipo ideal) seja obtido pela seguinte fórmula:
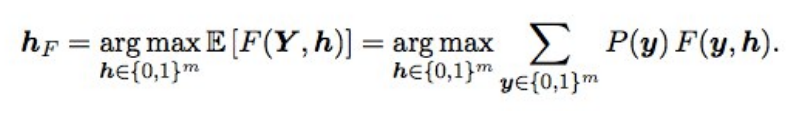
O que isso significa? Precisamos classificar todas as combinações (ou seja, para cada rótulo 0 e 1), calcular a probabilidade de cada combinação e multiplicar por F2 - obtemos o F2 esperado. Para qual combinação é melhor e fornecerá o F2 ideal. As probabilidades foram consideradas simplesmente uma multiplicação das probabilidades de rótulos individuais (se o rótulo for 0, pegamos 1 - p) e, para não classificar 2 em 17 opções, apenas rótulos com probabilidade de 0,05 a 0,5 foram escalonados - havia 3-7 deles seguidos, portanto, as opções um pouco (a submissão foi feita em alguns minutos). Em teoria, seria legal obter a probabilidade de uma combinação de rótulos, não apenas multiplicando probabilidades individuais (porque os rótulos não são independentes), mas não funcionou.
o que deu? quando os modelos se tornaram bons, a seleção de limites após o conjunto parou de funcionar, e isso deu um aumento pequeno, mas estável, na validação e em público / privado.
PosfácioComo resultado, treinamos 48 modelos diferentes, cada um com 10 dobras, ou seja, 480 modelos do primeiro nível. Tal igreja humana da grade me permitiu experimentar diferentes técnicas ao treinar redes neurais convolucionais profundas, que ainda uso no trabalho e nas competições.
Foi possível treinar menos modelos e obter o mesmo ou melhor resultado? Sim, bastante. Nossos compatriotas do 3º lugar, Stanislav
stasg7 Semenov e Roman
ZFTurbo Soloviev, custam um número menor de modelos de primeiro nível e compensam mais de 250 modelos de segundo nível. Sobre a solução, você pode
ver a análise e
ler a postagem.
O primeiro lugar foi para o misterioso melhor ajuste. Em geral, esse cara é muito legal, e agora ele se tornou o top1 do Keggle, tendo participado de muitas competições de fotos. Ele permaneceu anônimo por um longo tempo, até que a Nvidia quebrou a capa ao
entrevistá- lo. No qual ele admitiu que 200 subordinados se reportariam a ele ... Há também um
post sobre a decisão.
Outro interessante: amplamente conhecido em círculos estreitos,
Jeremy Howard , pai
fastai terminou 22m. E se você pensou que ele acabou de enviar algumas submissões para o fã dele, não adivinhou. Ele participou da equipe e enviou 111 encomendas.
Além disso, os estudantes de pós-graduação de Stanford que estavam fazendo o lendário curso CS231n na época e que tinham permissão para usar essa tarefa como projeto de curso terminaram toda a equipe no meio da tabela de classificação.
Como bônus,
falei no Mail.ru com o material deste post e aqui está outra
apresentação de Vladimir Iglovikov de uma reunião no Vale.