“Pesquisando no mercado de vagas para analistas” era a tarefa muito real de um analista líder muito real de uma empresa grande ou pequena. O analisador distribuiu dezenas de descrições de tarefas com hh manualmente, espalhando-as de acordo com as habilidades solicitadas e aumentando o contador na coluna da planilha correspondente.
Vi nessa tarefa um bom campo para automação e decidi tentar lidar com isso com menos sangue, fácil e simples.
Eu estava interessado nas seguintes questões levantadas neste estudo:
- salário médio para analistas de negócios e sistemas,
- as habilidades e qualidades pessoais mais exigidas nessa posição,
- dependências (se houver) entre certas habilidades e o nível de salário.
Spoiler: fácil e simples não funcionou.
Preparação de dados
Se queremos coletar muitos dados sobre vagas, é lógico que ele não seja limitado. No entanto, para pureza do experimento simplicidade, começamos com este recurso.
Colecção
Para coletar dados, usaremos a procura de emprego por meio da API hh.
Pesquisarei usando a consulta de texto simples "analista de sistemas", "analista de negócios" e "proprietário do produto", porque as atividades e áreas de responsabilidade nessas posições, em regra, se sobrepõem.
Para fazer isso, crie uma solicitação no formato https://api.hh.ru/vacancies?text="systems+analyst" e analise o JSON recebido.
Para obter as vagas mais relevantes na amostra, pesquisaremos apenas nos cabeçalhos da vaga, adicionando o parâmetro search_field=name à consulta.
Aqui você pode ver quais campos de vaga são retornados para esta solicitação. Eu escolhi o seguinte:
- cargo
- a cidade
- data de publicação
- salário - limites superior e inferior
- moeda na qual o salário é indicado
- bruto - T / F
- a companhia
- responsabilidades
- requisitos para o candidato
Além disso, quero analisar melhor as habilidades indicadas na seção Habilidades Principais, mas esta seção está disponível apenas na descrição completa do trabalho. Portanto, também manterei links para as vagas encontradas, a fim de obter posteriormente uma lista de habilidades para cada uma delas.
Ver código # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
Na função hh.getjobs() , a entrada aceita o vetor de consultas de pesquisa de seu interesse e refinamento, estamos interessados apenas em vagas com o salário especificado ou todas seguidas (por padrão, adotamos a segunda opção). Um quadro dafa vazio é criado e, em seguida, é jsonlite função fromJSON() do pacote fromJSON() , que pega a URL de entrada e retorna uma lista estruturada. Em seguida, nos nós desta lista, obtemos os dados nos quais estamos interessados e preenchemos os campos correspondentes do quadro de dados.
Por padrão, os dados são fornecidos página por página, com 20 elementos em cada página. Para um máximo de 2.000 vagas de emprego. Todos os dados que recebemos são registrados em df .
Life hack 1: não é fato que, a nosso pedido, haverá 2.000 vagas e, a partir de algum momento, receberemos páginas em branco. Nesse caso, R xinga e pula fora do loop. Portanto, envolvemos cuidadosamente o conteúdo do loop interno em try() .
Life hack 2: também faz sentido adicionar a saída do status atual da coleta de dados ao console no loop interno, porque esse não é um negócio rápido. Eu fiz isso:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
Após o preenchimento dos dados, as colunas são renomeadas para facilitar o trabalho com elas e o quadro de dados resultante é retornado.
Vou armazenar essa e outras funções auxiliares em um arquivo functions.R separado functions.R para não confundir o script principal, que até agora se parece com isso:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
Agora, obteremos experience e key_skills partir da descrição completa do trabalho .
hh.getxp o quadro de dados para a função hh.getxp , hh.getxp os links salvos das vagas e, a partir da descrição completa, obtemos o valor da experiência de trabalho necessária. O valor resultante é armazenado em uma nova coluna.
Ver código hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
A descrição da nova função auxiliar é enviada para functions.R , e o script principal agora a acessa:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
No fragmento acima, também formamos um novo quadro de dados all.skills formulário "job id - skill":
Ver código hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
Pré-processamento
Vamos ver quantos dados conseguimos coletar:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
Quase um milhão e meio de empregos! Parece bom. E, aparentemente, várias vagas entraram nos resultados da pesquisa duas vezes - para solicitações diferentes. Portanto, a primeira etapa é deixar apenas entradas exclusivas: jobdf <- jobdf[unique(jobdf$id),] .
Para comparar os salários dos analistas do mercado de trabalho, preciso
1) verifique se todos os dados disponíveis sobre salários são apresentados em uma moeda única,
2) selecione em um quadro de dados separado as vagas para as quais o salário é indicado.
Consideramos cada uma das subtarefas em mais detalhes. Anteriormente, você pode descobrir o que, em princípio, as moedas são encontradas em nossos dados usando a table(jobdf$Currency) . No meu caso, além de rublos, dólares, euros, hryvnias, tenge cazaque e até somas uzbeques apareceram.
Para converter valores de salário em rublo, você precisa descobrir a taxa de câmbio atual. Descobriremos pelo Banco Central :
Ver código quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
Para garantir que os cursos sejam processados corretamente em R, você precisa garantir que a parte decimal seja separada por um ponto. Além disso, você deve prestar atenção à coluna Nominal: em algum lugar é 1, em algum lugar 10 ou 100. Isso significa que uma libra esterlina custa ~ 85 rublos e, digamos, por cem drams armênios você pode comprar ~ 13 rublos. Para facilitar o processamento, reduzi os valores para um valor nominal de 1 em relação ao rublo.
Agora você pode traduzir. Nosso script faz isso usando a função convert.currency() . A taxa de câmbio atual é extraída da tabela de quotations , onde salvamos os dados do XML fornecidos pelo Banco Central. Além disso, a função de entrada aceita a moeda de destino para conversão (por padrão, RUR) e uma tabela com vagas, os valores dos garfos salariais nos quais é necessário levar a uma moeda única. A função retorna uma tabela com dígitos salariais atualizados (já sem a coluna Moeda, como desnecessário).
Eu tive que mexer com rublos bielorrussos: depois de receber dados muito estranhos em várias abordagens, realizei uma pequena pesquisa e descobri que desde 2016 uma nova moeda foi usada na Bielorrússia, que difere não apenas na taxa de câmbio, mas também na abreviação (agora não BYR, mas BYN) . Nos diretórios hh, a abreviação BYR ainda é usada, sobre a qual o XML do Banco Central não sabe nada. Portanto, na função convert.currency() I não da maneira mais elegante Primeiro, substituo a abreviação pela atual e só então vou diretamente para a conversão.
É assim:
Ver código convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
Você também pode levar em consideração que alguns dados sobre salários são apresentados em valores brutos, ou seja, o empregado receberá um pouco menos por mão. Para calcular o salário líquido para residentes da Federação Russa, 13% devem ser deduzidos desses valores (30% é deduzido para não residentes).
Ver código gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
Obviamente, não farei isso, porque nesse caso vale a pena considerar impostos em diferentes países, e não apenas na Rússia, ou adicionar um filtro por país na consulta de pesquisa inicial.
O último passo antes da análise é dividir as vagas encontradas em três categorias: junho, médio e sênior e escrever as posições recebidas em uma nova coluna. Os cargos seniores incluirão aqueles em nome dos quais a palavra "seniores" e seus sinônimos estejam presentes. Da mesma forma, encontraremos as posições iniciais para as palavras-chave "junior" e sinônimos e, entre os meios, incluiremos todos aqueles entre:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
Adicione o bloco de preparação de dados ao script principal.
Adicionado # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
Análise
Como mencionado acima, vou analisar os seguintes aspectos dos dados obtidos:
- salário médio BA / SA,
- as habilidades e qualidades pessoais mais exigidas nessa posição,
- dependências (se houver) entre certas habilidades e o nível de salário.
Renda média BA / SA
Como se viu, as empresas relutam em indicar um limite salarial superior ou inferior.
No nosso jobdf quadro de dados jobdf esses valores estão nas colunas Para e De, respectivamente. Quero encontrar as médias e escrevê-las em uma nova coluna Salário.
Nos casos em que o salário é indicado na íntegra, isso pode ser feito facilmente usando a função mean() , filtrando todos os outros registros em que os dados no plugue estão ausentes, no todo ou em parte. Mas, neste caso, menos de 10% permaneceria em nossa amostra original, que já é pequena. Portanto, calculo o coeficiente Podgoniana , que mostra o quanto os valores de Para e De diferem, em média, nas vagas em que o garfo completo é indicado e, com sua ajuda, preencho os dados ausentes nos casos em que apenas um valor está ausente.
Ver código select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
Essa é uma filtragem de dados "flexível", definida na função select.paid() com o parâmetro suggest = TRUE . Como alternativa, podemos especificar suggest = FALSE ao chamar a função e simplesmente cortar todas as linhas em que os dados do salário estão pelo menos parcialmente ausentes. No entanto, usando a filtragem suave e um coeficiente mágico, consegui salvar quase um quarto dos dados originais da amostra.
Passamos para a parte visual:

Neste gráfico, você pode avaliar visualmente a densidade de distribuição dos salários BA / SA em duas capitais e regiões. Mas e se especificarmos a solicitação e compararmos quanto os homens médios e altos nas capitais recebem?
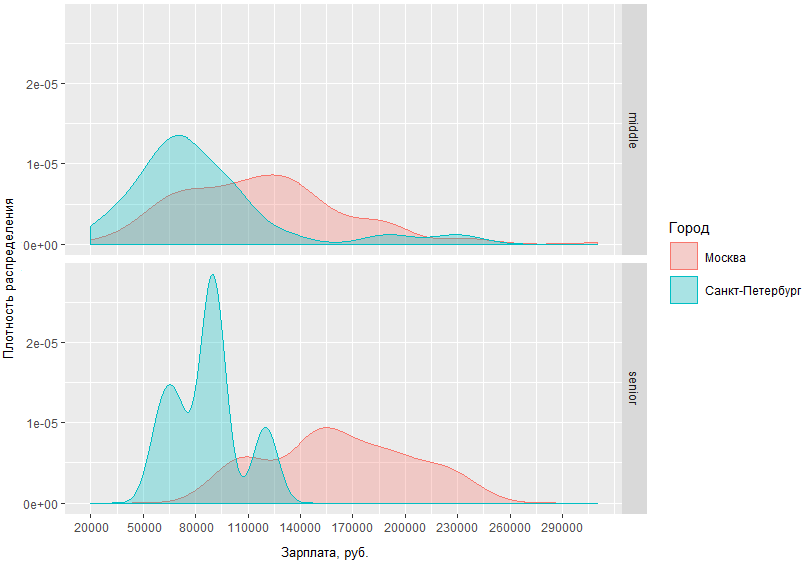
A partir do gráfico obtido, fica claro que a diferença nas situações salariais entre homens médios e altos em Moscou e São Petersburgo não é muito diferente. Assim, em São Petersburgo, os medianos são geralmente recebidos na região de 70 tr, enquanto em Moscou o pico de densidade é de aproximadamente 120 tr, e a diferença de renda dos especialistas de nível sênior em Moscou e São Petersburgo difere em média de 60 mil.
Também podemos observar, por exemplo, os salários de analistas em Moscou por posição:

Pode-se concluir que a) hoje em Moscou há uma demanda muito maior por analistas iniciantes eb) ao mesmo tempo, o limite salarial superior para esses especialistas é muito mais limitado do que o de intermediários e seniores.
Outra observação: o sn médio de especialistas em Moscou de nível médio e alto tem uma área de interseção bastante grande. Isso pode indicar que o mercado possui uma fronteira bastante desfocada entre essas duas etapas.
Código completo para gráficos abaixo do corte.
Ver # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
Análise das principais habilidades
Passamos ao objetivo principal do estudo - identificar as habilidades mais procuradas para BA / SA. Para fazer isso, analisaremos os dados explicitamente indicados no campo especial da vaga - habilidades-chave.
Habilidades mais populares
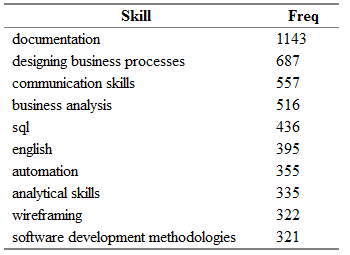
Anteriormente, recebemos um quadro de dados separado all.skills , onde gravamos os pares "job id - skill". É fácil encontrar as habilidades mais comuns com a função table() :
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
Você obtém algo como o seguinte:

Aqui Freq é o número de vagas no campo "key_skills", cuja habilidade correspondente na coluna Skill é indicada.
“Mas isso não é tudo!” (C) É bastante óbvio que as mesmas habilidades podem ser facilmente encontradas em diferentes vagas em termos sinônimos.
Compilei um pequeno dicionário de sinônimos para os nomes das habilidades e as dividi em categorias.
O dicionário é um arquivo csv com colunas de categoria - um dos seguintes: Atividades, Ferramentas, Conhecimento, Padrões e Pessoal; skill - o nome principal da habilidade, que usarei em vez de todos os sinônimos encontrados; syn1, syn2, ... syn13 - variações realmente possíveis para cada habilidade. Algumas linhas podem conter colunas vazias de sinônimos.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
Primeiro, importe o dicionário e depois redistribua as habilidades novamente com base nas equivalências existentes:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
Abaixo do corte, você pode ver o preenchimento da função categorize.skills() .
essas entranhas! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
Eu adiciono a coluna categoria e habilidade ao quadro de dados de habilidades original. grupo - para a categoria e o nome generalizado da habilidade, respectivamente. Depois, percorro o dicionário importado e componho um padrão para a função grep() de cada linha de sinônimos. Adicionando cada valor de coluna não vazio à linha, separo-os com um traço para obter uma condição "ou". Portanto, para todas as habilidades da tabela de origem que incluem o uml|activity diagram|use case diagram|ucd|class diagram , escreverei o valor "uml" na coluna skill.group. E assim será com todos! .. habilidade do quadro de dados original.
Ao solicitar novamente o topo das habilidades mais populares, você pode ver que o alinhamento de forças mudou um pouco:
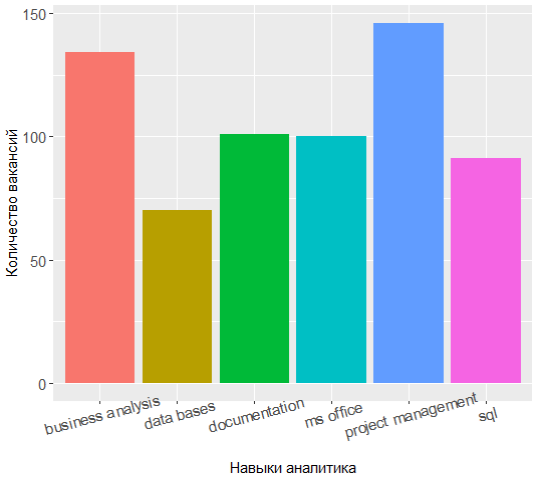
Os três líderes agora têm gerenciamento de projetos, análise e documentação de negócios, e o conhecimento da UML mudou dos sete principais.
É muito interessante examinar as categorias e descobrir quais habilidades são mais procuradas em cada uma delas.
Por exemplo, para a categoria Conhecimento, a situação é a seguinte:
Ver código tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

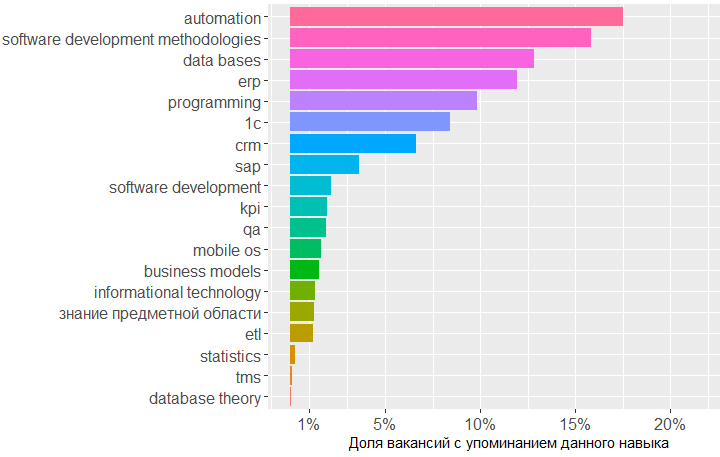
O gráfico mostra que a maior demanda é por conhecimento no campo de bancos de dados, metodologias de desenvolvimento de software e 1C. Em seguida, vêm os conhecimentos na área de CRM, sistemas ERP e noções básicas de programação.
No que diz respeito aos padrões, o conhecimento de SQL e UML é realmente muito procurado, a notação ARIS vem à tona, mas os GOSTs ocupam apenas o sexto lugar.
Aqui está o código ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

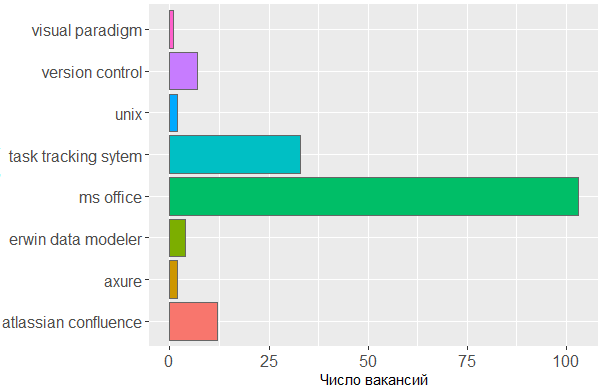
Quanto às ferramentas utilizadas, mais uma vez vemos a confirmação de que a cabeça é a principal ferramenta do analista. Não se pode prescindir da linha MS Office e dos sistemas de rastreamento de tarefas, mas o restante é de pouca preocupação para o editor no qual o analista cria seus próprios esquemas ou esboços de modelos de interface.
Aqui está o código ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
O impacto das habilidades na renda
, , . , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
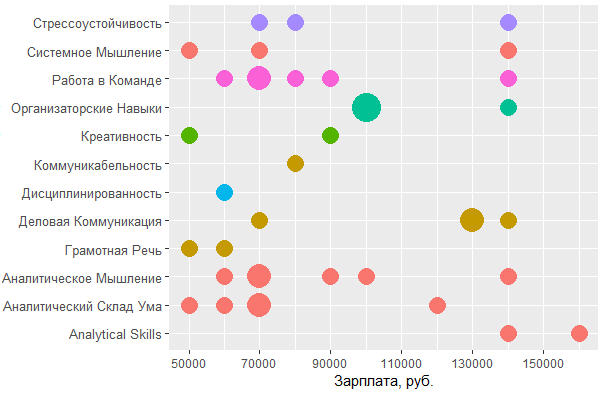
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
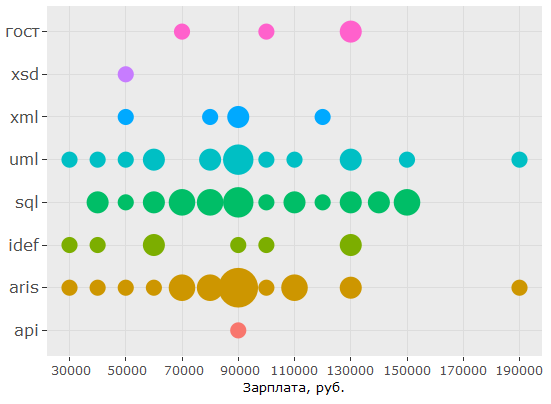
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
, , BA , - .
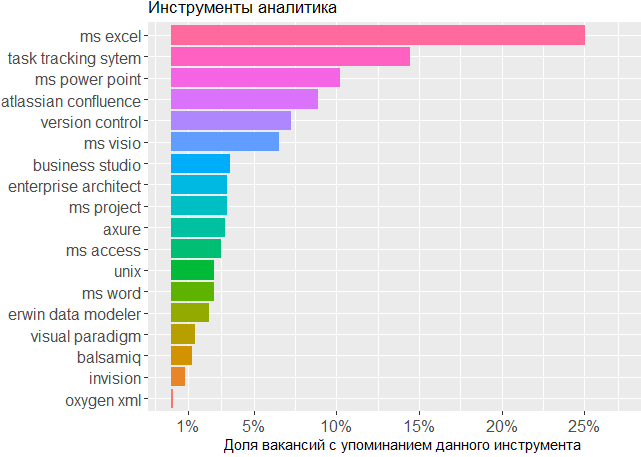
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
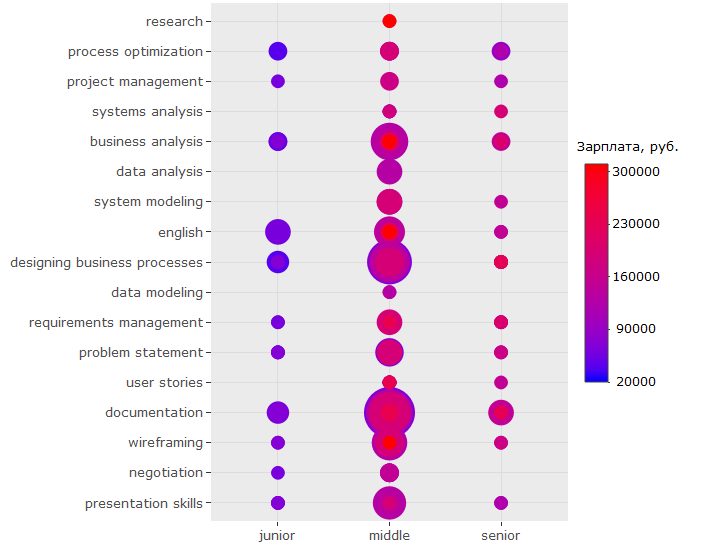
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
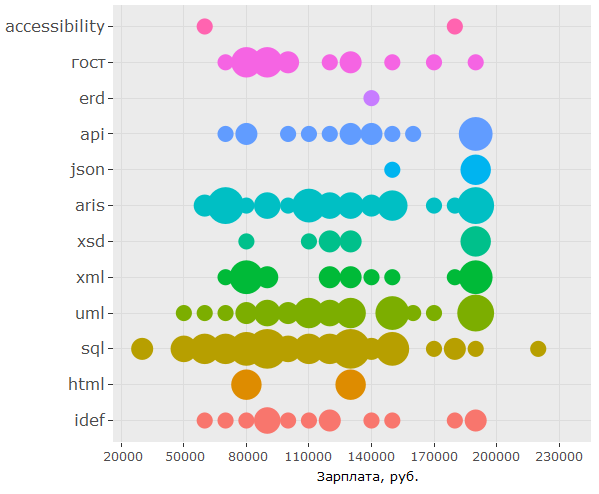
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
