Tudo com o fim das férias! ... Alguns dirão que esse parabéns é mais ou menos. Mas, certamente, muitos em breve tirarão férias, então tire um pouco mais. Bem, não estamos perdendo força e, neste dia quente, compartilhamos a experiência de nossos parceiros. Será sobre a otimização do trabalho com o banco de dados. Mais detalhes sob o corte!
 Dou a palavra ao autor.
Dou a palavra ao autor.Sejam bem-vindos, leitores da Habr! Nós somos a equipe
WaveAccess , neste artigo compartilharemos com você a experiência de usar o serviço de banco de dados (DB) do Azure Cosmos DB em um projeto comercial. Nós lhe diremos por que o banco de dados se destina e as nuances que tivemos que enfrentar durante o desenvolvimento.
O que é o Azure Cosmos DB
O Azure Cosmos DB é um serviço de banco de dados comercial distribuído globalmente com um paradigma de vários modelos, fornecido como uma solução PaaS. Ela é a próxima geração do Azure DocumentDB.
O banco de dados foi desenvolvido em 2017 pela Microsoft com a participação de Leslie Lamport, Ph.D. em Ciência da Computação (vencedor do Prêmio Turing 2013 por contribuição fundamental à teoria dos sistemas distribuídos, desenvolvedor LaTex, criador da especificação TLA +).
As principais características do Azure Cosmos DB são:
- Banco de dados não relacional;
- Os documentos nele são armazenados como JSON;
- Escala horizontal com uma escolha de regiões geográficas;
- Paradigma de dados multi-modelo: valor-chave, documento, gráfico, família de colunas;
- Baixa latência para 99% das solicitações: menos de 10 ms para operações de leitura e menos de 15 ms para operações de gravação (indexadas);
- Projetado para alto rendimento;
- Garante disponibilidade, consistência dos dados, latência no nível do SLA de 99,999%;
- Largura de banda configurável
- Replicação automática (mestre-escravo);
- Indexação automática de dados;
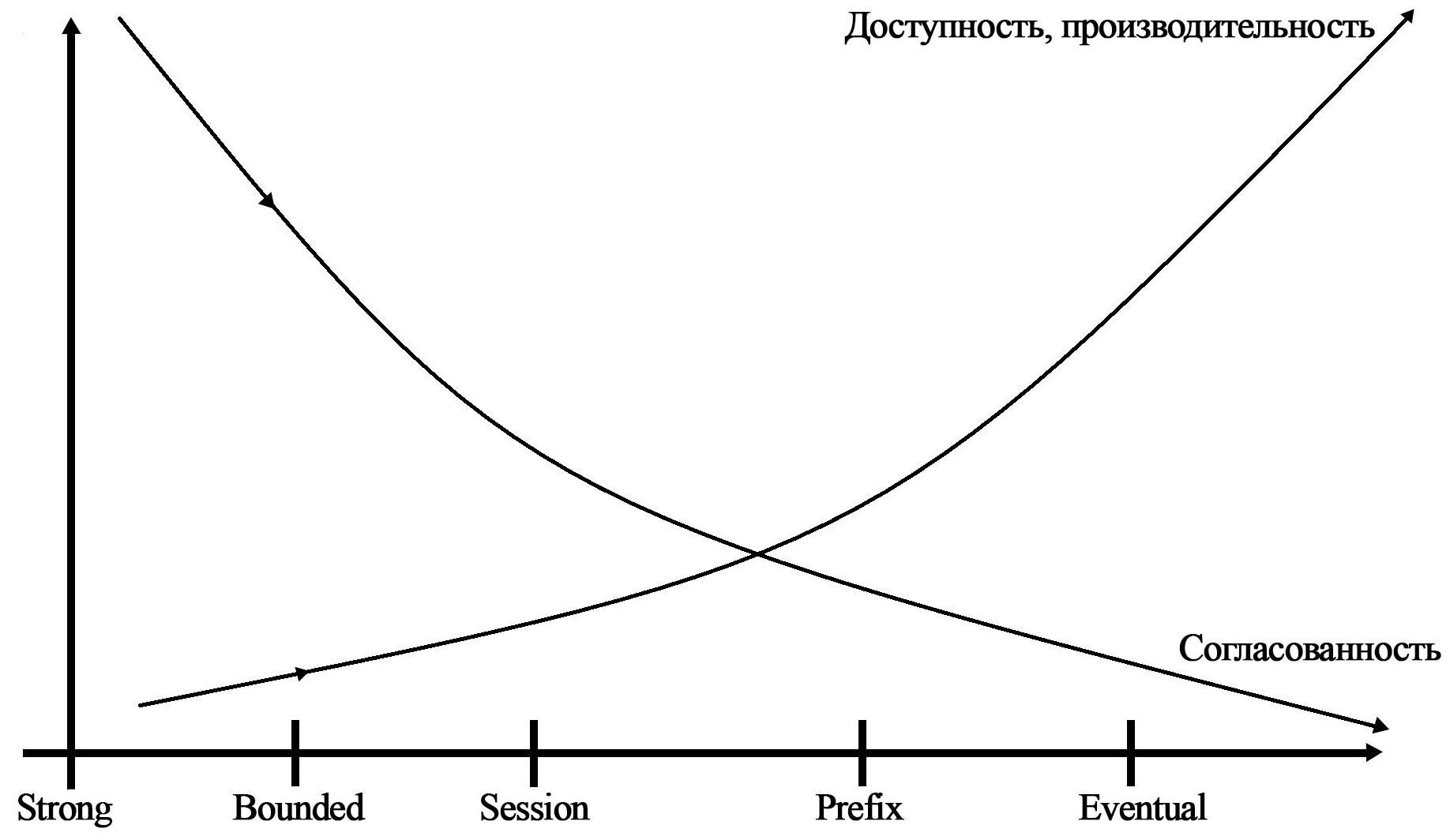
- Níveis personalizáveis de consistência dos dados. 5 níveis diferentes (Forte, Estabilidade limitada, Sessão, Prefixo consistente, Eventual);
No gráfico, você pode ver a dependência de vários níveis de consistência na disponibilidade, desempenho e consistência dos dados.
- Para uma transição conveniente para o Cosmos DB de seu banco de dados, existem muitas APIs para acessar dados: SQL, JavaScript, Gremlin, MongoDB, Cassandra, Blob do Azure;
- Firewall personalizável;
- Tamanho do banco de dados personalizado.
A tarefa que resolvemos
Milhares de sensores localizados em todo o mundo transmitem informações (a seguir notificações) a cada poucos segundos N. Essas notificações devem ser armazenadas no banco de dados e, em seguida, procurá-las e exibi-las na interface do usuário do operador do sistema.
Exigências do cliente:
- Usando uma pilha de tecnologias da Microsoft, incluindo a nuvem do Azure;
- Taxa de transferência de 100 solicitações por segundo;
- As notificações não têm uma estrutura clara e podem se expandir ainda mais;
- Para notificações críticas, a velocidade de processamento é importante;
- Alta resiliência do sistema.
Com base nos requisitos do cliente, fomos idealmente abordados por um banco de dados comercial confiável, não relacional, distribuído globalmente.

Se olharmos para bancos de dados semelhantes ao Cosmos DB, podemos lembrar o Amazon DynamoDB, Google Cloud Spanner. Mas o Amazon DynamoDB não é distribuído globalmente, e o Google Cloud Spanner possui menos níveis de consistência e tipos de modelos de dados (apenas tabulares, relacionais).
Por esses motivos, optamos pelo Azure Cosmos DB. Para interagir com o banco de dados,
usamos o SDK do Azure Cosmos DB para .NET , pois o back-end foi escrito em .NET.
As nuances que encontramos
1. Gerenciamento de banco de dadosPara começar a usar o banco de dados, primeiro você precisa escolher uma ferramenta para gerenciá-lo. Usamos o Azure Cosmos DB Data Explorer no portal do Azure e no
DocumentDbExplorer . Há também um utilitário do Azure Storage Explorer.
 2. Configurando coleções de banco de dados
2. Configurando coleções de banco de dadosNo Cosmos DB, cada banco de dados consiste em coleções e documentos.
Recursos de coleção personalizáveis a serem observados:
- Tamanho da coleção: fixo ou ilimitado;
- Largura de banda em unidades de solicitações por segundo RU / s (de 400 RU / s);

- Política de indexação (incluindo ou excluindo documentos e caminhos para e do índice, configurando vários tipos de índice, configurando modos de atualização de índice).
Exemplo típico de índice
{ "id": "datas", "indexingPolicy": { "indexingMode": "consistent", "automatic": true, "includedPaths": [ { "path": "/*", "indexes": [ { "kind": "Range", "dataType": "Number", "precision": -1 }, { "kind": "Hash", "dataType": "String" }, { "kind": "Spatial", "dataType": "Point" } ] } ], "excludedPaths": [] } }
Para que a pesquisa de substring funcione, para os campos de string, você precisa usar o índice Hash ("kind": "Hash").
3. Transações de banco de dadosAs transações são implementadas no banco de dados no nível dos procedimentos armazenados (a execução de um procedimento armazenado é uma operação atômica). Procedimentos armazenados JavaScript
var helloWorldStoredProc = { id: "helloWorld", body: function () { var context = getContext(); var response = context.getResponse(); response.setBody("Hello, World"); } }
4. Canal de mudança de banco de dadosO Feed de alterações ouve alterações na coleção. Quando ocorrem alterações nos documentos de coleta, o banco de dados lança um evento sobre alterações para todos os assinantes deste canal.
Usamos o Feed de alterações para rastrear as alterações da coleção. Ao criar um canal, você deve primeiro criar uma coleção
AUX auxiliar que coordene o processamento do canal de mudança para várias funções de trabalho.
5. Restrições de banco de dados:- Falta de operações em massa (procedimentos armazenados usados para exclusão em massa , atualização de documentos);
- Falta de atualização parcial do documento;
- Nenhuma operação SKIP (complexidade da implementação de paginação). Para implementar a paginação em solicitações de notificações, usamos os parâmetros RequestContinuation (link para o último elemento como resultado da emissão) e MaxItemCount (o número de elementos retornados do banco de dados). Por padrão, os resultados são retornados em lotes (não mais que 100 itens e não mais que 1 MB em cada pacote). O número de itens retornados pode ser aumentado para 1000 usando o parâmetro MaxItemCount.
6. Processando 429º erro no banco de dadosQuando a largura de banda da coleção atinge o máximo, o banco de dados começa a gerar um erro "429 Too Many Request". Para processá-lo, você pode usar a configuração
RetryOptions no SDK, em que MaxRetryAttemptsOnThrottledRequests é o número de tentativas para concluir a solicitação e MaxRetryWaitTimeInSeconds é o tempo total das tentativas de conexão.
7. Previsão do custo de uso do banco de dadosPara prever o custo do uso do banco de dados, usamos a
calculadora online RU / s. No plano básico, uma unidade de solicitação para um elemento de 1 KB corresponde a um simples comando GET por um link para si ou para o identificador desse elemento.
Conclusões
O Azure Cosmos DB é fácil de usar, fácil e flexível de configurar através do portal do Azure. As muitas APIs de acesso a dados facilitam a migração para o Cosmos DB. Não há necessidade de contratar um administrador de banco de dados para manter o banco de dados. Garantias financeiras do SLA, a escala horizontal global torna esse banco de dados muito atraente no mercado. É adequado para uso em aplicativos corporativos e globais que exigem alta tolerância a falhas e largura de banda. Nós do WaveAccess continuamos a usar o Cosmos DB em nossos projetos.
Sobre o autor
A equipe do
WaveAccess cria
software tecnicamente sofisticado, altamente carregado e tolerante a falhas para empresas em todo o mundo.
Alexander Azarov , vice-presidente sênior de desenvolvimento de software da WaveAccess, comenta:
À primeira vista, tarefas difíceis podem ser resolvidas por métodos relativamente simples. É importante não apenas aprender novas ferramentas, mas também aperfeiçoar o conhecimento de tecnologias familiares.
Blog da empresa