Ou como eu acabei na equipe vencedora da competição adversária do Machines Can See 2018.
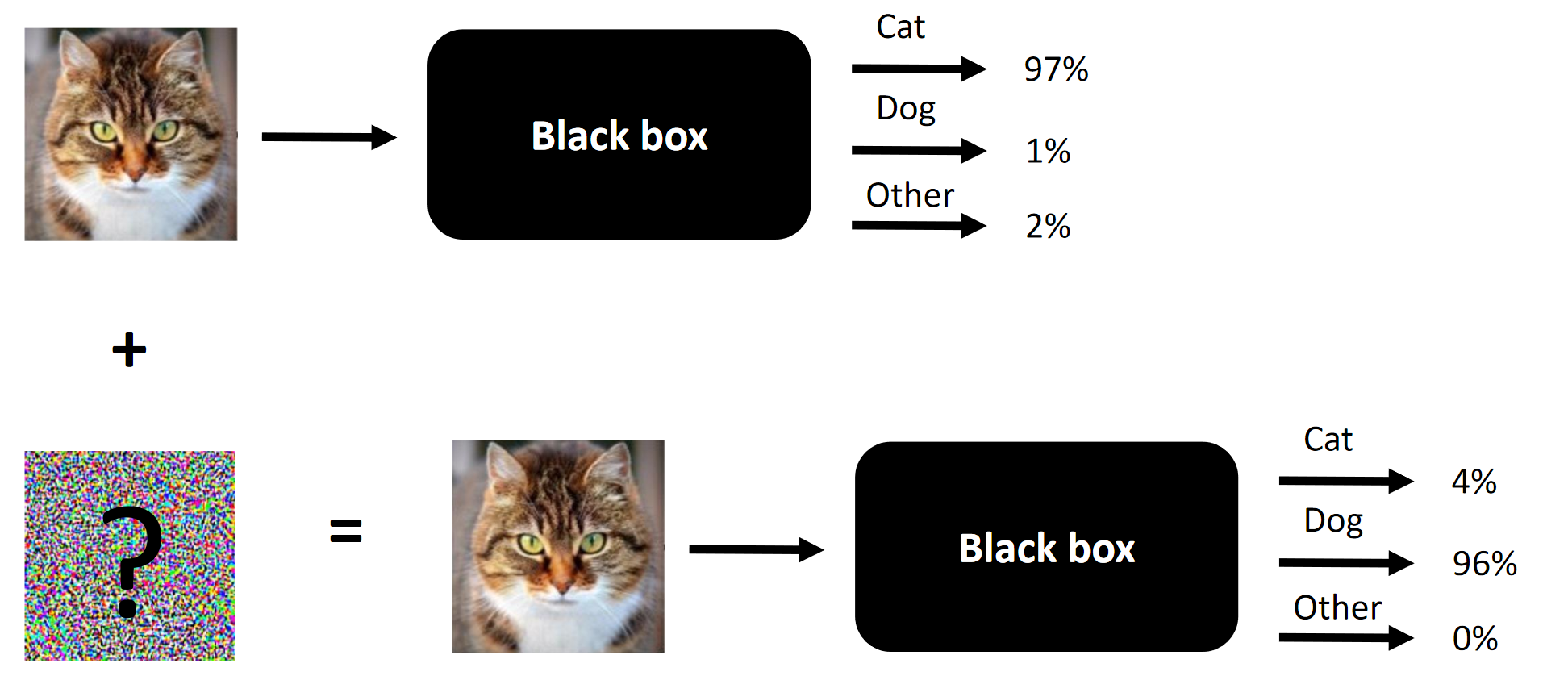 A essência de qualquer ataque competitivo é um exemplo.
A essência de qualquer ataque competitivo é um exemplo.Aconteceu que participei da competição Machines Can See 2018. Entrei para a competição que estava um pouco atrasado (cerca de uma semana antes do final), mas finalmente acabei em uma equipe de 4 pessoas, onde a contribuição de nós três (incluindo eu) era necessário para a vitória (remova um componente - e seríamos estranhos).
O objetivo da competição é mudar a face das pessoas para que a rede neural convolucional, apresentada como uma caixa preta pelos organizadores, não consiga distinguir a face da fonte da face do alvo. O número de alterações permitidas foi limitado pelo
SSIM .
Artigo original publicado
aqui .
Nota A tradução desajeitada da terminologia ou sua ausência é ditada pela falta de terminologia estabelecida no idioma russo. Você pode sugerir suas opções nos comentários. A essência da competição é mudar a face na entrada para que a caixa preta não consiga distinguir entre duas faces (pelo menos do ponto de vista da distância L2 / Euclidiana)
A essência da competição é mudar a face na entrada para que a caixa preta não consiga distinguir entre duas faces (pelo menos do ponto de vista da distância L2 / Euclidiana)O que funciona em ataques competitivos e o que funcionou no nosso caso:
- Método de sinal de gradiente rápido (FGSM). A adição de heurísticas tornou LITTLE melhor;
- Método do valor de gradiente rápido (FGVM). O acréscimo de heurísticas tornou-o MUITO MELHOR;
- Evolução diferencial genética (ótimo artigo sobre esse método) + ataques pixel por pixel;
- Conjuntos de modelos (solução de ponta ... 6 ResNet “empilhado”);
- Desvio inteligente de combinações de imagens de destino;
- Essencialmente, parada precoce durante um ataque da FGVM;
O que não funcionou no nosso caso:
- Adicionando um “momento de inércia” à FGVM (embora tenha funcionado para a equipe com classificação inferior, é possível que conjuntos + heurísticas funcionem melhor do que adicionar um momento?);
- Ataque C&W (essencialmente um ataque de ponta a ponta direcionado aos logs do modelo de caixa branca) - funciona para a caixa branca (BY), não funciona para a caixa preta (CN);
- Uma abordagem baseada no Siamese LinkNet de ponta a ponta (arquitetura semelhante à UNet, mas baseada na ResNet). Também trabalhou apenas para BY;
O que não tentamos (não teve tempo, não teve esforço suficiente ou era muito preguiçoso):
- Teste de aumento interpretativo para a aprendizagem dos alunos (eu precisaria recontar os descritores também - é fácil, mas uma idéia tão simples não veio imediatamente);
- Aumento durante o ataque - por exemplo, "espelhe" a imagem da esquerda para a direita;
Sobre a competição em geral:
- O conjunto de dados era "muito pequeno" (1000 combinações 5 + 5);
- O conjunto de dados de treinamento da rede do aluno era relativamente grande (mais de 1 milhão de imagens);
- O CE foi apresentado como um conjunto de modelos pré-compilados no Caffe (naturalmente, em nossos ambientes, eles emitiram bugs pela primeira vez). Isso também introduziu alguma complexidade, pois o QW não aceitava imagens com lotes;
- A competição possuía uma excelente linha de base (solução básica), sem a qual, na minha opinião, poucos se envolveriam diretamente;
Recursos:
1. Visão geral da competição Machines Can See 2018 e como eu participei
Concorrência e Abordagens
Honestamente, fui atraído por uma nova área interessante, a GTX 1080Ti Founders 'Edition em prêmios e uma concorrência relativamente baixa (o que não seria possível comparar com 4000 pessoas em qualquer competição no Kaggle contra o ODS inteiro com 20 GPUs por equipe).
Como mencionado acima, o objetivo da competição era enganar o modelo de CE, de modo que este último não pudesse distinguir entre duas pessoas diferentes (no sentido da distância da norma L2 / Euclidiana). Bem, como era uma caixa preta, tivemos que destilar as redes de Alunos nos dados fornecidos e esperar que os gradientes do QW e BYW fossem semelhantes o suficiente para realizar o ataque.
Se você ler resenhas de artigos (por exemplo,
aqui e
ali , embora esses artigos não digam realmente o que funciona na prática) e compilar o que as principais equipes alcançaram, você poderá descrever brevemente essas práticas recomendadas:
- Os ataques mais simples na implementação envolvem BY ou conhecimento da estrutura interna da rede neural convolucional (ou simplesmente arquitetura) na qual o ataque é realizado;
- Alguém no bate-papo sugeriu rastrear o tempo de inferência no CE e tentar adivinhar sua arquitetura;
- Tendo acesso a uma quantidade suficiente de dados, você pode emular o QW com QW bem treinado
- Presumivelmente, os métodos mais avançados são:
- Ataque C&W de ponta a ponta (não funcionou neste caso);
- Extensões inteligentes de FGSM (ou seja, momento de inércia + conjuntos complicados);
Honestamente, ainda estávamos confusos pelo fato de que duas abordagens de ponta a ponta completamente diferentes, implementadas independentemente por duas pessoas diferentes da equipe, estupidamente não funcionavam para a CH. Em essência, isso pode significar que em nossa interpretação da declaração do problema em algum lugar houve um vazamento de dados que não percebemos (ou que as mãos estavam tortas). Em muitas tarefas modernas de visão computacional, as soluções completas (por exemplo, transferência de estilo, divisor de águas profundo, geração de imagens, limpeza de ruídos e artefatos etc.) são muito melhores do que tudo o que era antes ou nem funcionam. Meh.
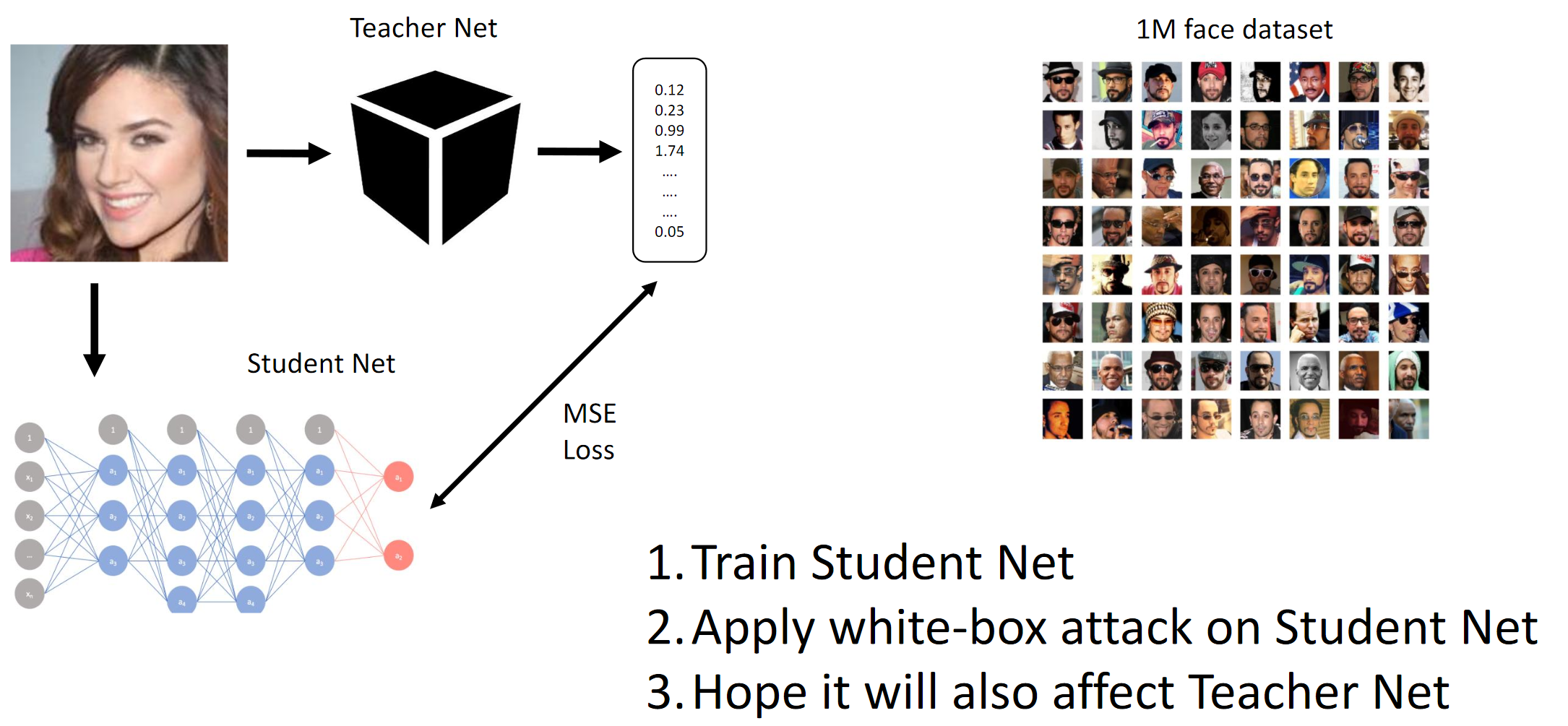 1. Treine a rede do aluno. 2. Aplique o ataque BY na Student Net. 3. Os ataques da Hope Teacher Net também se espalharamComo o método gradiente funciona
1. Treine a rede do aluno. 2. Aplique o ataque BY na Student Net. 3. Os ataques da Hope Teacher Net também se espalharamComo o método gradiente funciona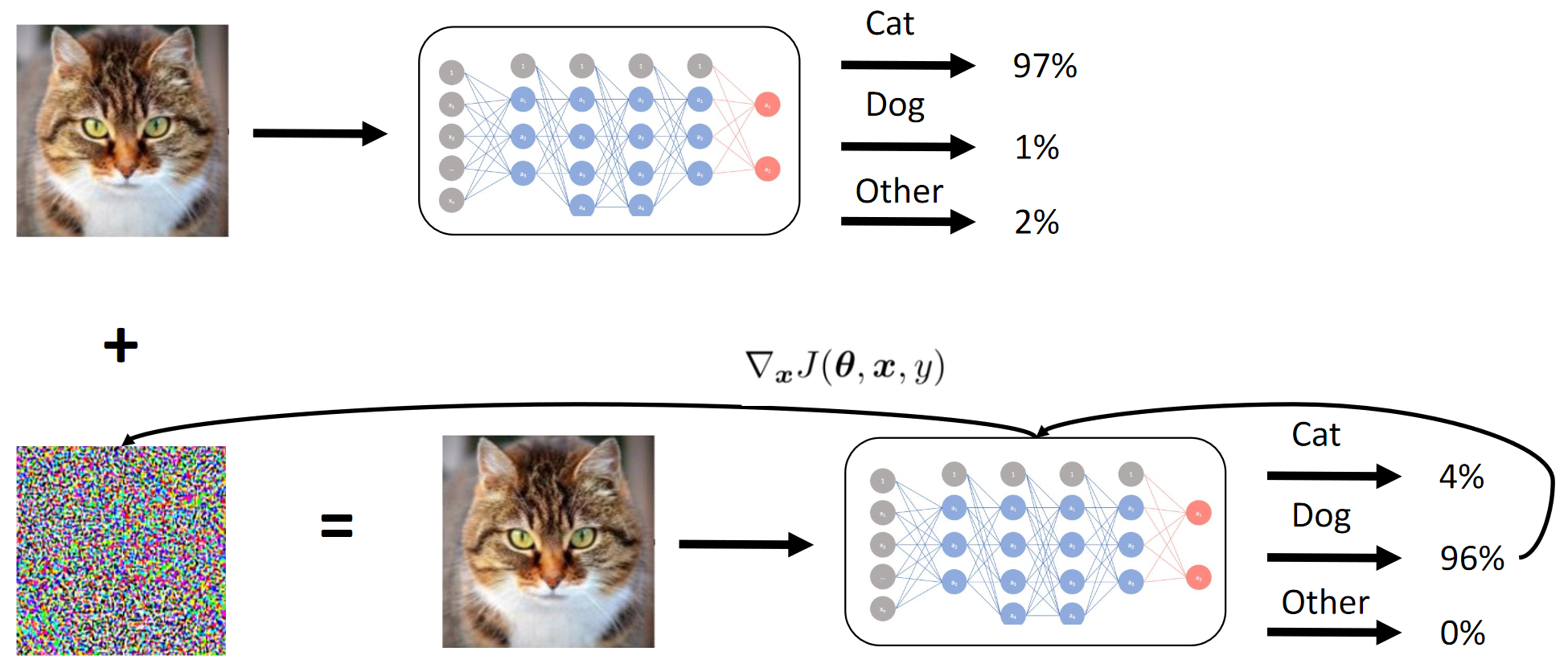
Conseguimos essencialmente por destilação que o BY está emulando o BY. Em seguida, os gradientes das imagens de entrada em relação à saída do modelo são considerados. O segredo, como sempre, está na heurística.
Métrica de destino
A métrica alvo foi a norma L2 média (distância euclidiana) entre todas as 25 combinações de imagens de origem e de destino (5 * 5 = 25).
Devido às limitações da plataforma (CodaLab), era provável que as pontuações privadas (e a fusão de equipes) fossem calculadas manualmente, o que seria uma história.

A equipe
Entrei para a equipe depois de treinar grades de Alunos, melhor do que todos os outros na tabela de classificação (tanto quanto eu sei), e depois de uma pequena discussão com
Atmyre (ela ajudou com o QW corretamente compilado, pois ela mesma enfrentava o mesmo). Depois, compartilhamos nossas pontuações locais sem compartilhar abordagens e códigos e, na verdade, 2-3 dias antes da linha de chegada, aconteceu o seguinte:
- Meus modelos contínuos fracassaram (sim, também neste caso);
- Eu tinha os melhores modelos de alunos;
- Eles (equipes) apresentaram as melhores variações heurísticas para a FGVM (seu código foi baseado na linha de base);
- Acabei de experimentar modelos com gradientes e atingi uma velocidade local em torno de 1,1 - inicialmente não queria usar uma linha de base de minhas preferências pessoais (me desafiei);
- Eles não tinham poder de computação suficiente naquele momento;
- No final, tentamos a sorte e juntamos forças - investi meu poder computacional / redes neurais convolucionais / conjunto de testes de ablação. A equipe colocou em sua base de código, que eles aperfeiçoaram por algumas semanas;
Mais uma vez, gostaria de agradecer a ela pelos conselhos inestimáveis e pelas habilidades organizacionais.
Composição da equipe:
github.com/atmyre - com base nas ações, foi o capitão da equipe inicialmente. Adicionado um ataque de evolução diferencial genética na submissão final;
github.com/mortido - a melhor implementação de ataques da FGVM com excelentes heurísticas + modelos treinados 2 usando o código de linha de base;
github.com/snakers4 - além de quaisquer testes para reduzir o número de opções na busca de uma solução, eu treinei 3 modelos de alunos com as melhores métricas + forneci poder de computação + auxiliei na fase de envio e apresentação final dos resultados;
github.com/stalkermustang;Como resultado, todos aprendemos muito um com o outro e estou feliz por termos tentado a sorte nesta competição. A ausência de pelo menos uma contribuição em três levaria à derrota.
2. Estudante de Destilação CNN
Consegui obter a melhor velocidade ao treinar os modelos de alunos, pois usei meu próprio código em vez do código de linha de base.
Pontos principais / o que funcionou:- Seleção de um regime de treinamento para cada arquitetura individualmente;
- Primeiro treinamento com decaimento de Adam + LR;
- Monitoramento cuidadoso da capacidade de sob e sobreajuste e modelo;
- Ajuste manual dos modos de treinamento. Não confie completamente nos esquemas automáticos: eles podem funcionar, mas se você definir bem as configurações, o tempo de treinamento poderá ser reduzido em 2-3 vezes. Isso é especialmente importante em modelos pesados como o DenseNet;
- Arquiteturas pesadas tiveram melhor desempenho do que arquiteturas leves, sem contar o VGG;
- Treinar com perda de L2 em vez de MSE também funciona, mas um pouco pior;
O que não funcionou:- Arquiteturas baseadas em criação (não é adequado devido à alta amostragem para baixo e maior resolução de entrada). Embora a equipe em terceiro lugar tenha conseguido, de alguma forma, usar o Inception-v1 e imagens completas (~ 250x250);
- Arquiteturas baseadas em VGG (sobreajuste);
- Arquiteturas leves (SqueezeNet / MobileNet - underfitting);
- Aumento de imagens (sem modificar os descritores - embora a equipe de alguma forma o tenha retirado do terceiro lugar);
- Trabalhe com imagens em tamanho real;
- Também no final das redes neurais fornecidas pelos organizadores da competição havia uma camada de lote-norma. Isso não ajudou meus colegas, e eu usei meu código, pois não entendi muito bem por que essa camada estava lá;
- Usando mapas de saliência com ataques baseados em pixels. Suponho que isso seja mais aplicável a imagens em tamanho real (basta comparar 112x112x search_space e 299x299x search_space);
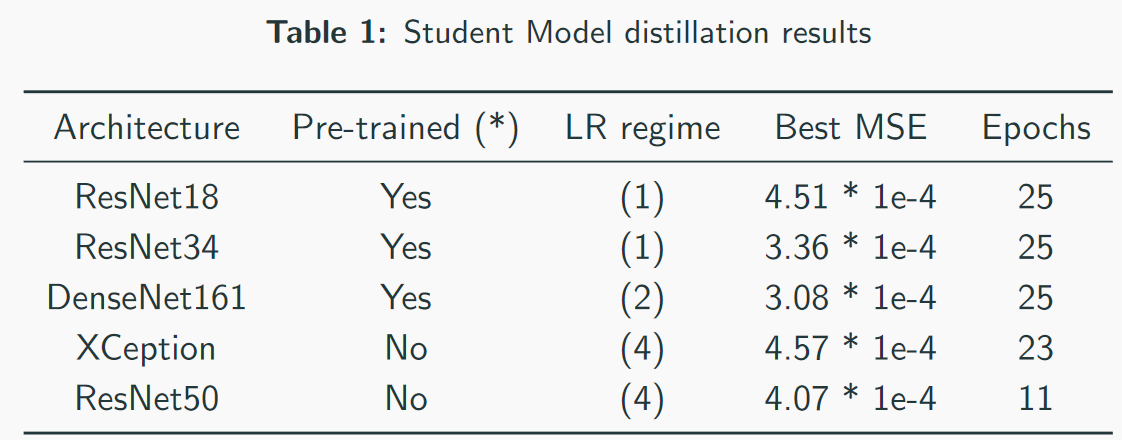 Nossos melhores modelos - observe que a melhor velocidade é 3 * 1e-4. A julgar pela complexidade dos modelos, pode-se imaginar que QW é ResNet34. Nos meus testes, o ResNet50 + teve um desempenho pior que o ResNet34.
Nossos melhores modelos - observe que a melhor velocidade é 3 * 1e-4. A julgar pela complexidade dos modelos, pode-se imaginar que QW é ResNet34. Nos meus testes, o ResNet50 + teve um desempenho pior que o ResNet34.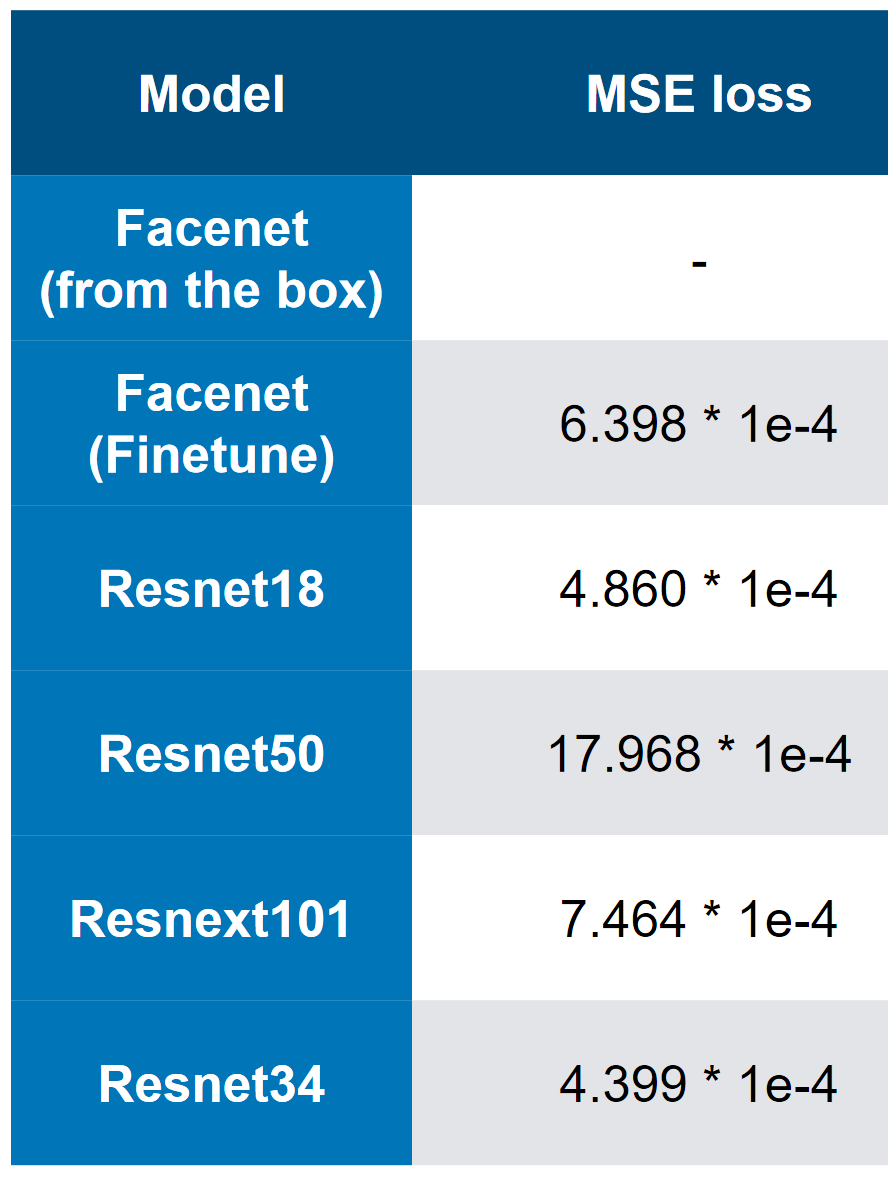 MSE perda em primeiro lugar
MSE perda em primeiro lugar3. A velocidade final e a análise de "ablação"
Coletamos nossa velocidade assim:
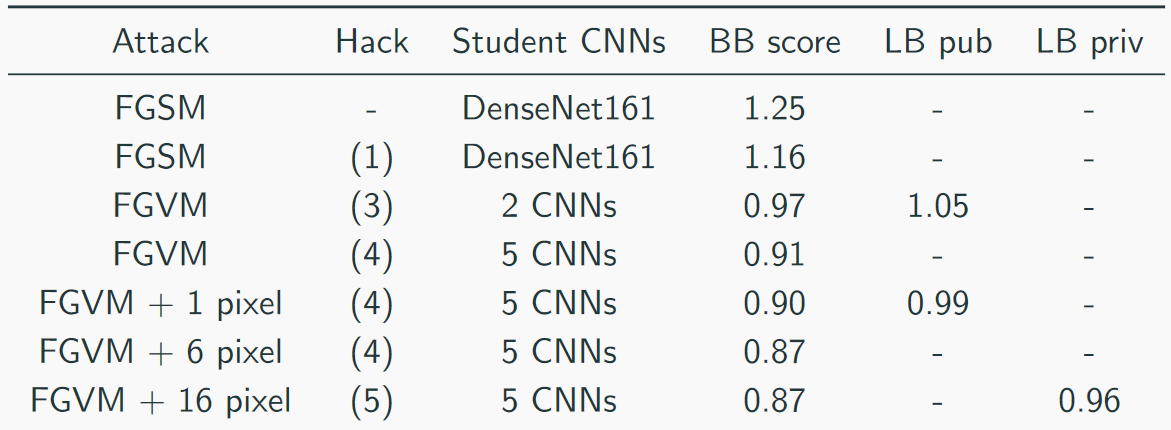
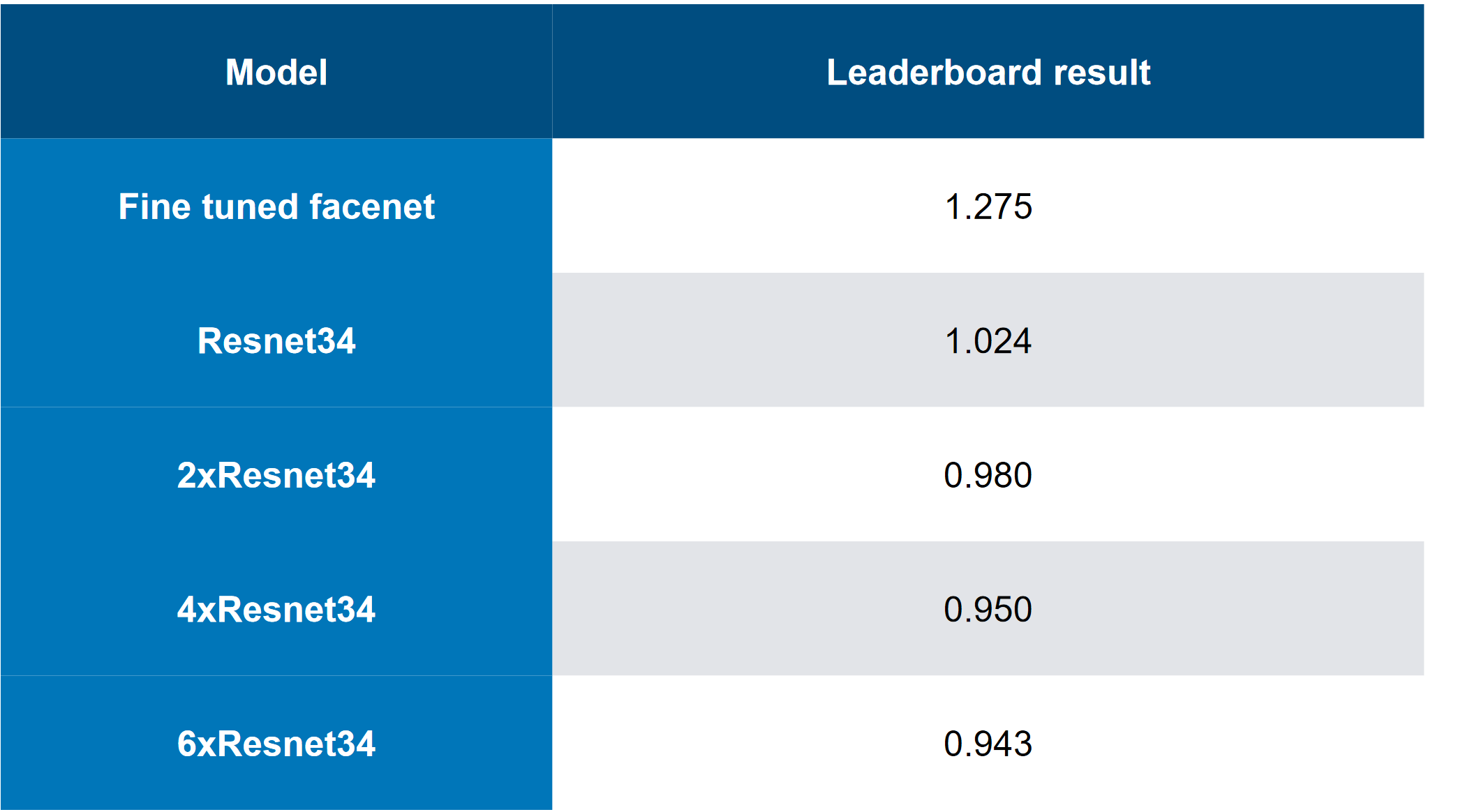
A solução principal era assim (sim, havia piadas sobre o fato de apenas empilhar o abate, você pode adivinhar que o CH é um abate):
Outras abordagens úteis de outras equipes:
- Parâmetro adaptativo epsilon;
- Aumento de Dados
- Momento de inércia;
- O momento de Nesterov ;
- Imagens de espelho;
- "Hackear" os dados um pouco - havia apenas 1000 imagens únicas e 5000 combinações de imagens => foi possível gerar mais dados (não 5 alvos, mas 10, porque as imagens foram repetidas);
Heurísticas úteis para FGVM:
- Geração de ruído pela regra: Noise = eps * clamp (grad / grad.std (), -2, 2);
- Um conjunto de várias CNNs ponderando seus gradientes;
- Salve as alterações somente se elas reduzirem a perda média;
- Use combinações de destinos para uma segmentação mais consistente
- Use apenas gradientes mais altos que a média + padrão (para FGSM);
Sammari curto:
- Em primeiro lugar, houve uma decisão mais "desajeitada"
- Tivemos a solução mais "diversificada";
- Em terceiro lugar, a solução mais "elegante";
Soluções de ponta a ponta
Mesmo se eles falharem, valem a pena tentar novamente no futuro em novas tarefas. Veja os detalhes no repositório, mas na verdade tentamos o seguinte:
- Ataque de C&W;
- LinkNet siamês;
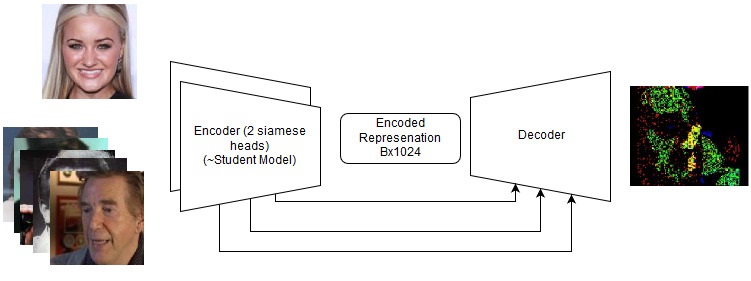 Modelo de ponta a ponta
Modelo de ponta a ponta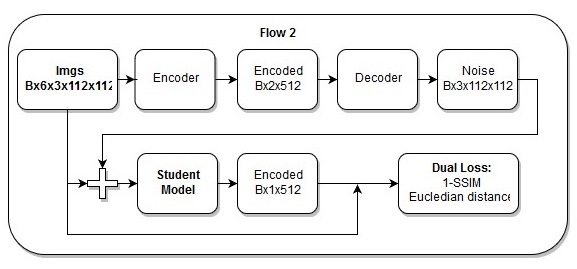 A sequência de ações no modelo de ponta a ponta
A sequência de ações no modelo de ponta a pontaEu também acho que minha
perda é linda.
5. Referências e materiais adicionais de leitura
- Página da competição ;
- Nosso repositório ;
- Uma série de artigos sobre o VAE é um tópico semelhante;
- Recursos SSIM
- Wiki
- Implementação de PyTorch "com backpropable"
- Recursos para evolução diferencial
- Apresentações
- 2 artigos mais úteis:
- 2 artigos de revisão "no topo":