
Anotação
O processamento de dados em tempo real exatamente uma vez ( exatamente uma vez ) é uma tarefa extremamente não trivial e requer uma abordagem séria e ponderada em toda a cadeia de cálculos. Alguns até acreditam que essa tarefa é impossível . Na realidade, quero ter uma abordagem que forneça processamento tolerante a falhas sem demora e o uso de vários armazenamentos de dados, o que apresenta novos requisitos ainda mais rigorosos para o sistema: simultâneo exatamente uma vez e a heterogeneidade da camada persistente. Até o momento, esse requisito não suporta nenhum dos sistemas existentes.
A abordagem proposta revelará consistentemente os ingredientes secretos e os conceitos necessários que tornam relativamente fácil implementar o processamento simultâneo heterogêneo exatamente uma vez literalmente a partir de dois componentes.
1. Introdução
O desenvolvedor de sistemas distribuídos passa por várias etapas:
Etapa 1: Algoritmos . Aqui está o estudo de algoritmos básicos, estruturas de dados, abordagens de programação como OOP, etc. O código é exclusivamente de thread único. A fase inicial de ingresso na profissão. No entanto, é bastante complicado e pode durar anos.
Etapa 2: Multithreading . Em seguida, surgem questões sobre como extrair a máxima eficiência do ferro, há multithreading, assincronia, corrida, depuração, strace, noites sem dormir ... Muitos ficam presos nesse estágio e até começam a sentir uma emoção inexplicável em algum momento. Mas apenas alguns conseguem entender a arquitetura da memória virtual e dos modelos de memória, algoritmos sem bloqueio / sem espera e vários modelos assíncronos. E quase ninguém nunca - verificação de código multithread.
Etapa 3: Distribuição . Aqui está acontecendo um lixo que nem um conto de fadas nem uma caneta descrevem.
Parece que algo complicado. Fazemos a transformação: muitos threads -> muitos processos -> muitos servidores. Mas cada passo da transformação traz mudanças qualitativas, e todas elas caem no sistema, esmagando-o e transformando-o em pó.
E o objetivo aqui é alterar o domínio de tratamento de erros e a disponibilidade de memória compartilhada. Se antes havia sempre um pedaço de memória disponível em cada encadeamento e, se desejado, em todos os processos, agora não existe esse pedaço e não pode existir. Cada um por si, independente e orgulhoso.
Se anteriormente, uma falha no fluxo enterrava o fluxo e o processo ao mesmo tempo, e isso era bom, porque não levou a falhas parciais, agora falhas parciais se tornam a norma e toda vez antes de cada ação que você pensa: “e se?”. Isso é tão irritante e perturbador para a escrita, de fato, as próprias ações que o código por causa disso cresce não às vezes, mas por ordens de magnitude. Tudo se transforma no macarrão de manipulação de erros, troca de estado e preservação de contexto, restauração devido a falhas de um componente, outro componente, inacessibilidade de alguns serviços, etc. etc. Depois de estragar o monitoramento de todas essas coisas, você pode ter uma ótima noite de sono no seu laptop favorito.
Se é uma questão de multithreading: peguei o mutex e fui destruir a memória compartilhada por prazer. Beleza!
Como resultado, temos que os padrões chave e testados em batalha foram retirados, e os novos, para substituí-los, por algum motivo não foram entregues, e aconteceu como uma piada sobre como a fada acenou com sua varinha e a torre caiu do tanque.
No entanto, os sistemas distribuídos têm um conjunto de práticas e algoritmos comprovados. No entanto, todo programador que se preze considera seu dever rejeitar conquistas conhecidas e aproveitar seu próprio bem, apesar da experiência adquirida, um número considerável de artigos científicos e pesquisas acadêmicas. Afinal, se você pode usar algoritmos e multithreading, como pode entrar em confusão com a distribuição? Não pode haver duas opiniões aqui!
Como resultado, os sistemas estão com bugs, os dados divergem e se deterioram, os serviços ficam periodicamente indisponíveis para gravação ou até mesmo completamente indisponíveis, porque de repente um nó travou, a rede caiu, o Java consumiu muita memória e o GC sem graça, e existem muitos outros motivos que podem atrasar seu término. às autoridades.
Contudo, mesmo com abordagens conhecidas e comprovadas, a vida não se torna mais fácil, porque primitivas confiáveis distribuídas são pesadas, com sérios requisitos para a lógica do código executável. Portanto, os cantos são cortados sempre que possível. E, como costuma acontecer, com cantos cortados às pressas, a simplicidade e a escalabilidade relativa aparecem, mas a confiabilidade, a disponibilidade e a consistência de um sistema distribuído desaparecem.
Idealmente, gostaria de não pensar que nosso sistema seja distribuído e multithread, ou seja, trabalhe na 1ª etapa (algoritmos), sem pensar na 2ª (multithreading + assincronia) e na 3ª (distribuição). Essa maneira de isolar abstrações aumentaria significativamente a simplicidade, a confiabilidade e a velocidade da escrita de código. Infelizmente, no momento isso só é possível em sonhos.
No entanto, abstrações individuais permitem um isolamento relativo. Um dos exemplos típicos é o uso de corotinas , em que, em vez de código assíncrono, nos tornamos síncronos, ou seja, passamos da 2ª para a 1ª etapa, o que nos permite simplificar significativamente a escrita e a manutenção do código.
O artigo revela sucessivamente o uso de algoritmos sem bloqueio para criar um sistema em tempo real escalável distribuído consistente e confiável, ou seja, como as conquistas sem bloqueio do segundo estágio ajudam na implementação do terceiro, reduzindo a tarefa a algoritmos single-threaded do primeiro estágio.
Declaração do problema
Esta tarefa ilustra apenas algumas abordagens importantes e é apresentada como um exemplo para a introdução de problemas no contexto. Pode ser facilmente generalizado para casos mais complexos, o que será feito no futuro.
Tarefa: processamento de dados de streaming em tempo real .
Existem dois fluxos de números. O manipulador lê os dados desses fluxos de entrada e seleciona os últimos números por um determinado período. A média desses números é nesse intervalo de tempo, ou seja, em uma janela de dados deslizante por um determinado tempo. O valor médio obtido deve ser gravado na fila de saída para processamento subseqüente. Além disso, se o número de números na janela exceder um determinado limite, aumente em um o contador no banco de dados transacional externo.
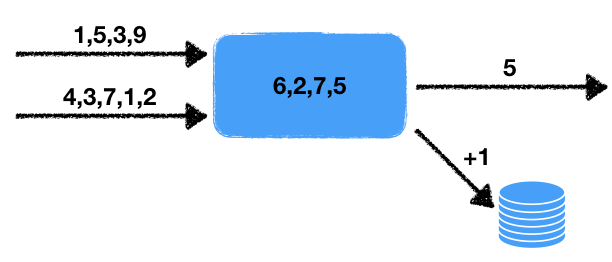
Observamos alguns recursos desse problema.
- Não determinismo . Existem duas fontes de comportamento não determinístico: é uma leitura de dois fluxos, bem como uma janela de tempo. É claro que a leitura pode ser realizada de diferentes maneiras, e o resultado final dependerá de qual sequência os dados serão extraídos. A janela de tempo também altera o resultado do início ao início, conforme a quantidade de dados na janela dependerá da velocidade do trabalho.
- O estado do manipulador . Há um estado do manipulador na forma de um conjunto de números na janela, do qual dependem os resultados atuais e subsequentes do trabalho. I.e. nós temos um manipulador stateful.
- Interação com armazenamento externo . É necessário atualizar o valor do contador no banco de dados externo. O ponto crucial é que o tipo de armazenamento externo é diferente do armazenamento do estado do processador e dos threads.
Tudo isso, como será mostrado abaixo, afeta seriamente as ferramentas utilizadas e os possíveis métodos de implementação.
Resta adicionar um pequeno toque à tarefa, que transfere a tarefa imediatamente de uma área além da complexidade para um impossível: é necessária uma garantia simultânea exatamente uma vez .
Exatamente uma vez
Exatamente uma vez é muitas vezes interpretado de maneira muito ampla, o que emascula o próprio termo e deixa de atender aos requisitos originais da tarefa. Se estamos falando de um sistema que roda localmente em um computador - tudo é simples: aguarde mais, jogue mais longe. Mas, neste caso, estamos falando de um sistema distribuído no qual:
- O número de manipuladores pode ser grande: cada manipulador trabalha com seus próprios dados. Além disso, os resultados podem ser adicionados a vários locais, por exemplo, um banco de dados externo, possivelmente até embaralhado.
- Cada manipulador pode parar subitamente o processamento. Um sistema tolerante a falhas implica em operação contínua, mesmo no caso de falha de partes individuais do sistema.
Portanto, devemos estar preparados para o fato de que o manipulador pode cair e outro manipulador deve pegar o trabalho já realizado e continuar o processamento.
Surge imediatamente a pergunta: o que significa exatamente uma vez se o manipulador não determinístico funcionar? Afinal, toda vez que reiniciarmos, receberemos, de um modo geral, diferentes estados resultantes. A resposta aqui é simples: com exatamente uma vez, existe uma execução do sistema em que cada valor de entrada é processado exatamente uma vez, fornecendo o resultado de saída correspondente. Além disso, essa execução não precisa estar fisicamente no mesmo nó. Mas o resultado deve ser como se tudo fosse processado em um único nó lógico sem falhas .
Concorrente exatamente uma vez
Para agravar os requisitos, introduzimos um novo conceito: simultâneo exatamente uma vez . A diferença fundamental do simples exatamente uma vez é a ausência de pausas durante o processamento, como se tudo fosse processado no mesmo nó sem quedas e sem pausas . Em nossa tarefa, exigiremos exatamente simultâneo exatamente uma vez , para simplificar a apresentação, para não considerar uma comparação com sistemas existentes que não estão disponíveis atualmente.
As conseqüências de ter esse requisito serão discutidas abaixo.
Transacional
Para que o leitor seja ainda mais profundamente imbuído da complexidade que surgiu, vejamos vários cenários ruins que devem ser considerados ao desenvolver esse sistema. Também tentaremos usar uma abordagem geral que nos permita resolver o problema acima, levando em consideração nossos requisitos.
A primeira coisa que vem à mente é a necessidade de registrar o estado do manipulador e os fluxos de entrada e saída. O estado dos fluxos de saída é descrito por uma fila simples de números e o estado dos fluxos de entrada pela posição neles. Em essência, um fluxo é uma fila infinita e uma posição na fila define um local exclusivamente.

A implementação ingênua a seguir de um manipulador surge usando algum tipo de armazém de dados. Nesta fase, as propriedades específicas do repositório não serão importantes para nós. Usaremos a linguagem Pseco para ilustrar a ideia (Pseco: = pseudo código):
handle(input_queues, output_queues, state): # input_indexes = storage.get_input_indexes() # while true: # items, new_input_indexes = input_queues.get_from(input_indexes) # state.queue.push(items) # duration state.queue.trim_time_window(duration) avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary # (A) output_queues[0].push(avg) if need_update_counter: # (B) db.increment_counter() # (C) storage.save_state(state) # (D) storage.save_queue_indexes(new_input_indexes) # (E) input_indexes = new_input_indexes
Aqui está um algoritmo simples de thread único que lê dados dos fluxos de entrada e grava os valores desejados de acordo com a tarefa descrita acima.
Vamos ver o que acontece no caso de um nó cair em pontos arbitrários no tempo, bem como depois de retomar o trabalho. É claro que, no caso de uma queda nos pontos (A) e (E) tudo ficará bem: ou os dados ainda não foram gravados em nenhum lugar e simplesmente restauramos o estado e continuamos no outro nó, ou todos os dados necessários já foram gravados e continuamos a próxima etapa.
No entanto, no caso de uma queda em todos os outros pontos, problemas inesperados nos aguardam. Se ocorrer uma queda no ponto (B) , quando o manipulador for reiniciado, restauraremos o estado e registraremos novamente o valor médio aproximadamente no mesmo intervalo de números. No caso de uma queda no ponto (C) além da duplicata média, uma duplicata ocorrerá no incremento do valor. E no caso de uma queda em (D) obteremos um estado inconsistente do manipulador: o estado corresponde a um novo momento no tempo e leremos os valores dos fluxos de entrada antigos.

Ao mesmo tempo, nada mudará fundamentalmente ao reorganizar as operações de gravação: a inconsistência e as duplicatas permanecerão assim. Assim, chegamos à conclusão de que todas as ações para alterar o estado do manipulador no repositório, na fila de saída e no banco de dados devem ser executadas de maneira transacional, ou seja, tudo é atômico ao mesmo tempo.
Consequentemente, é necessário desenvolver um mecanismo para que diferentes armazenamentos possam mudar transacionalmente seu estado, e não dentro de cada um independentemente, mas transacionalmente entre todos os armazenamentos simultaneamente. Obviamente, você pode colocar nosso armazenamento em um banco de dados externo; no entanto, a tarefa assumiu que o mecanismo de banco de dados e o mecanismo da estrutura de processamento de dados de streaming são separados e funcionam independentemente um do outro. Aqui eu quero considerar o caso mais difícil, porque casos simples não são interessantes a considerar.
Capacidade de resposta competitiva
Considere a execução competitiva exatamente uma vez com mais detalhes. No caso de um sistema tolerante a falhas, exigimos a continuação do trabalho a partir de algum ponto. É claro que este ponto será algum ponto no passado, porque Para manter o desempenho, é impossível armazenar todos os momentos de mudanças de estado no presente e no futuro: o último resultado das operações ou um grupo de valores para aumentar o rendimento é salvo. Esse comportamento imediatamente nos leva ao fato de que, após a restauração do estado do processador, ocorrerá algum atraso nos resultados, aumentará com o aumento do tamanho do grupo de valores e do tamanho do estado.
Além desse atraso, também existem atrasos no sistema associados ao carregamento do estado em outro nó. Além disso, a detecção de um nó problemático também leva algum tempo, e muitas vezes muito. Isso se deve, em primeiro lugar, ao fato de que, se definirmos um tempo de detecção curto, possíveis falsos positivos frequentes serão possíveis, o que levará a todos os tipos de efeitos especiais desagradáveis.
Além disso, com o aumento do número de processadores paralelos, repentinamente acontece que nem todos eles funcionam igualmente bem, mesmo na ausência de falhas. Às vezes ocorrem embotamentos, o que também leva a atrasos no processamento. A razão para tais embotamentos pode ser variada:
- Software : pausas no GC, fragmentação da memória, pausas no alocador, interrupção do kernel e agendamento de tarefas, problemas com drivers de dispositivo, causando lentidão.
- Hardware : alta carga de disco ou de rede, limitação da CPU devido a problemas de refrigeração, sobrecarga, etc., lentidão no disco devido a problemas técnicos.
E isso não é de forma alguma uma lista exaustiva de problemas que podem retardar os manipuladores.
Por conseguinte, abrandar é um dado com o qual se tem que viver. Às vezes, esse não é um problema sério e, às vezes, é extremamente importante manter uma alta velocidade de processamento, apesar de falhas ou lentidões.
Imediatamente surge a idéia de duplicação de sistemas: vamos rodar para um e o mesmo fluxo de dados, não um, mas dois processadores ao mesmo tempo, ou até três. O problema aqui é que, nesse caso, duplicatas e comportamento inconsistente do sistema podem ocorrer facilmente. Normalmente, as estruturas não são projetadas para esse comportamento e sugerem que o número de manipuladores em um determinado momento não exceda um. Os sistemas que permitem a duplicação descrita da execução são chamados simultâneos exatamente uma vez .
Essa arquitetura permite resolver vários problemas ao mesmo tempo:
- Comportamento à prova de falhas: se um dos nós cai, o outro simplesmente continua a funcionar como se nada tivesse acontecido. Não há necessidade de coordenação adicional, pois o segundo manipulador é executado independentemente do estado do primeiro.
- Remoção de embotamento: quem primeiro forneceu o resultado é bom para ele. O outro só terá que pegar um novo estado e continuar a partir deste momento.
Essa abordagem, em particular, permite concluir um cálculo longo difícil e difícil por um tempo mais previsível, porque a probabilidade de que ambos sejam estúpidos e caiam significativamente menos.
Avaliação de probabilidade
Vamos tentar avaliar os benefícios da duplicação de desempenho. Suponha que algo aconteça em média todos os dias com o manipulador: ou o GC está embotado, ou o nó está mentindo ou os contêineres se tornaram cancerígenos. Suponha também que preparemos pacotes de dados em 10 segundos.
Então a probabilidade de que algo aconteça durante a criação do pacote é 10 / (24 · 3600) ≃ 1e-4 .
Se você executar dois manipuladores em paralelo, a probabilidade de ambas as moscas serem ≃ 1e-8 . Portanto, este evento virá em 23 anos! Sim, os sistemas não vivem tanto, o que significa que isso nunca acontecerá!
Além disso, se o tempo de preparação da embalagem for ainda mais curto e / ou os embotamentos ocorrerem com menos frequência, esse número só aumentará.
Assim, concluímos que a abordagem em consideração aumenta significativamente a confiabilidade de todo o sistema. Resta apenas resolver uma pequena questão como esta: onde ler sobre como criar um sistema concorrente exatamente uma vez . E a resposta é simples: você tem que ler aqui.
Meia transação
Para uma discussão mais aprofundada, precisamos do conceito de meia transação . A maneira mais fácil de explicar isso com um exemplo.
Considere transferir fundos de uma conta bancária para outra. A abordagem tradicional usando transações na linguagem Pseco pode ser descrita da seguinte maneira:
transfer(from, to, amount): tx = db.begin_transaction() amount_from = tx.get(from) if amount_from < amount: return error.insufficient_funds tx.set(from, amount_from - amount) tx.set(to, tx.get(to) + amount) tx.commit() return ok
No entanto, e se essas transações não estiverem disponíveis para nós? Usando bloqueios, isso pode ser feito da seguinte maneira:
transfer(from, to, amount): # lock_from = db.lock(from) lock_to = db.lock(to) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) db.set(to, db.get(to) + amount) return ok
Essa abordagem pode levar a impasses, pois os bloqueios podem ser feitos em diferentes seqüências em paralelo. Para corrigir esse comportamento, basta introduzir uma função que simultaneamente leva vários bloqueios em uma sequência determinística (por exemplo, classifica por chaves), que elimina completamente possíveis bloqueios.
No entanto, a implementação pode ser um pouco simplificada:
transfer(from, to, amount): lock_from = db.lock(from) amount_from = db.get(from) if amount_from < amount: return error.insufficient_funds db.set(from, amount_from - amount) lock_from.release() # , # .. db.set(db.get...) lock_to = db.lock(to) db.set(to, db.get(to) + amount) return ok
Essa abordagem também torna o estado final consistente, preservando os invariantes pelo tipo de prevenção de gastos excessivos de fundos. A principal diferença da abordagem anterior é que, em tal implementação, temos um certo período de tempo em que as contas estão em um estado inconsistente. Nomeadamente, tal operação implica que o estado total dos fundos nas contas não muda. Nesse caso, há um intervalo de tempo entre lock_from.release() e db.lock(to) , durante o qual o banco de dados pode fornecer um valor inconsistente: o valor total pode diferir do valor correto para baixo.
De fato, dividimos uma transação para transferir dinheiro em duas meias transações:
- A primeira meia transação faz um cheque e deduz da conta o valor necessário.
- A segunda meia transação grava o valor sacado em outra conta.
É claro que dividir uma transação em transações menores, de um modo geral, viola o comportamento transacional. E o exemplo acima não é excepção. No entanto, se todas as meias transações na cadeia forem completamente cumpridas, o resultado será consistente com todos os invariantes preservados. É exatamente isso que é uma propriedade importante de uma cadeia de meia transação.
Perdendo temporariamente alguma consistência, adquirimos outro recurso útil: a independência das operações e, como resultado, melhor escalabilidade. A independência se manifesta no fato de que uma meia transação a cada vez trabalha com apenas uma linha, lendo, verificando e alterando seus dados, sem se comunicar com outros dados. Assim, você pode embaralhar um banco de dados cujas transações funcionam com apenas um shard. Além disso, essa abordagem pode ser usada no caso de repositórios heterogêneos, ou seja, meias transações podem começar em um tipo de armazenamento e terminar em outro. São essas propriedades úteis que serão usadas no futuro.
Surge uma pergunta legítima: como implementar o meio transe em sistemas distribuídos e não o rake? Para resolver esse problema, é necessário considerar a abordagem sem bloqueio.
Sem bloqueio
Como você sabe, as abordagens sem bloqueio às vezes melhoram o desempenho de sistemas multithread, especialmente no caso de acesso competitivo ao recurso. No entanto, é completamente óbvio que essa abordagem pode ser usada em sistemas distribuídos. Vamos nos aprofundar e considerar o que é livre de bloqueios e por que essa propriedade será útil na solução de nosso problema.
Alguns desenvolvedores às vezes não entendem o que é livre de bloqueio. O olhar tacanho sugere que isso é algo relacionado às instruções do processador atômico. É importante entender aqui que livre de bloqueio significa o uso de "átomos", o oposto não é verdadeiro, ou seja, nem todos os "atômicos" oferecem um comportamento livre de bloqueio.
Uma propriedade importante do algoritmo sem bloqueio é que pelo menos um encadeamento avança no sistema. Mas, por alguma razão, muitos atribuem essa propriedade como uma definição (é uma definição tão contundente que pode ser encontrada, por exemplo, na Wikipedia ). Aqui é necessário adicionar uma nuance importante: o progresso é feito mesmo no caso de embotamento de um ou mais threads. Esse é um ponto muito crítico que geralmente é esquecido e tem sérias implicações para um sistema distribuído.
Por que a ausência de uma condição de progresso de pelo menos um thread nega o conceito de um algoritmo sem bloqueio? O fato é que, neste caso, o spinlock usual também estará livre de bloqueios. De fato, quem assumiu o controle fará progressos. Existe um tópico com progress = = free-lock?
Obviamente, sem bloqueios significa sem bloqueios, enquanto spinlock por seu nome indica que esse é um bloqueio real. É por isso que é importante adicionar uma condição ao progresso, mesmo no caso de embotamentos. Afinal, esses atrasos podem durar indefinidamente, porque a definição não diz nada sobre a linha do tempo superior. E, nesse caso, esses atrasos serão equivalentes em certo sentido ao desligamento dos fluxos. Nesse caso, algoritmos sem bloqueio produzirão progresso nesse caso.
Mas quem disse que as abordagens sem bloqueio se aplicam exclusivamente a sistemas multiencadeados? Substituindo threads no mesmo processo no mesmo nó por processos em nós diferentes, e a memória compartilhada dos threads por armazenamento distribuído compartilhado, obtemos um algoritmo distribuído sem bloqueio.
Uma queda de nó nesse sistema é equivalente a um atraso na execução de um encadeamento por algum tempo, porque é hora de restaurar o trabalho. Ao mesmo tempo, a abordagem sem bloqueio permite que outros participantes no sistema distribuído continuem trabalhando. Além disso, algoritmos especiais livres de bloqueio podem ser executados em paralelo, detectando uma mudança competitiva e eliminando duplicatas.
A abordagem Exatamente uma vez implica a presença de um armazenamento distribuído consistente. Geralmente, esses armazenamentos representam uma enorme tabela de valor-chave persistente. Operações possíveis: set , get , del . No entanto, é necessária uma operação mais complicada para a abordagem sem bloqueio: CAS ou compare-and-swap. Vamos considerar em mais detalhes essa operação, as possibilidades de seu uso, bem como os resultados que ela fornece.
Cas
O CAS ou compare-and-swap é a primitiva principal e importante da sincronização para algoritmos sem bloqueio e sem espera. Sua essência pode ser ilustrada pelo seguinte Pseco:
CAS(var, expected, new): # , atomic, atomic: if var.get() != expected: return false var.set(new) return true
Às vezes, para otimização, eles retornam não true ou false , mas o valor anterior, porque muitas vezes essas operações são executadas em loop e, para obter o valor expected , você deve primeiro lê-lo:
CAS_optimized(var, expected, new): # , atomic, atomic: current = var.get() if current == expected: var.set(new) return current # CAS CAS_optimized CAS(var, expected, new): return var.CAS_optimized(expected, new) == expected
Essa abordagem pode salvar uma leitura. Como parte de nossa análise, usaremos uma forma simples de CAS , porque se desejado, essa otimização pode ser feita de forma independente.
No caso de sistemas distribuídos, cada alteração é versionada. I.e. primeiro, lemos o valor da loja, obtendo a versão atual dos dados. E então tentamos escrever, esperando que a versão dos dados não tenha mudado. Nesse caso, a versão é incrementada toda vez que os dados são atualizados:
CAS_versioned(var, expected_version, new): atomic: if var.get_version() != expected_version: return false var.set(new, expected_version + 1) return true
Essa abordagem permite controlar com mais precisão a atualização de valores, evitando o problema ABA . Em particular, o controle de versão é suportado pelo Etcd e pelo Zookeeper.
Observe a propriedade importante que o uso das operações CAS_versioned fornece. O fato é que essa operação pode ser repetida sem prejuízo da lógica superior. Na programação multithread, essa propriedade não possui valor especial, porque lá, se a operação falhar, sabemos com certeza que ela não se aplicou. No caso de sistemas distribuídos, essa invariante é violada, porque a solicitação pode chegar ao destinatário, mas a resposta bem-sucedida não está mais lá. Portanto, é importante poder reenviar solicitações sem medo de quebrar invariantes da lógica de alto nível.
É essa propriedade que a operação CAS_versioned . De fato, essa operação pode ser repetida infinitamente até que a resposta real do destinatário seja retornada. O que, por sua vez, gera toda uma classe de erros relacionados à interação da rede.
Exemplo
Vejamos como, com base em CAS_versioned e meia transação do CAS_versioned , transferir de uma conta para outra, que pertence, por exemplo, a diferentes cópias do Etcd. Aqui, suponho que a função CAS_versioned já CAS_versioned implementada de acordo com a API fornecida.
withdraw(from, amount): # CAS- while true: # version_from, amount_from = from.get_versioned() if amount_from < amount: return error.insufficient_funds if from.CAS_versioned(version_from, amount_from - amount): break return ok deposit(to, amount): # CAS- while true: version_to, amount_to = to.get_versioned() if to.CAS_versioned(version_to, amount_to + amount): break return ok transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
Aqui dividimos nossa operação em meias transações e realizamos cada meia transação através da operação CAS_versioned . Essa abordagem permite trabalhar independentemente com cada conta, permitindo o uso de armazenamento heterogêneo que não está conectado entre si. O único problema que nos espera aqui é a perda de dinheiro no caso de uma queda no processo atual no intervalo entre meias transações.
Fila
Para seguir em frente, você precisa implementar uma fila de eventos. A idéia é que, para que os manipuladores se comuniquem, é necessário ter uma fila de mensagens ordenada na qual os dados não sejam perdidos ou duplicados. Consequentemente, toda interação na cadeia de manipuladores será construída sobre esse primitivo. É também uma ferramenta útil para analisar e auditar fluxos de dados de entrada e saída. Além disso, mutações do estado dos manipuladores também podem ser feitas através da fila.
A fila consistirá em um par de operações:
- Adicione uma mensagem ao final da fila.
- Recebendo uma mensagem da fila no índice especificado.
Nesse contexto, não considero remover mensagens da fila por vários motivos:
- Vários processadores podem ler da mesma fila. Remover a sincronização será uma tarefa não trivial, embora não seja impossível.
- É útil manter uma fila por um intervalo relativamente longo (dia ou semana) para depuração e auditoria. É difícil superestimar a utilidade dessa propriedade.
- Você pode excluir itens antigos de acordo com a programação ou definindo TTL nos itens da fila. É importante garantir que os processadores consigam processar os dados antes que a vassoura chegue e limpe tudo. Se o tempo de processamento for da ordem de segundos e o TTL da ordem dos dias, nada disso deverá acontecer.
Para armazenar os elementos e implementar efetivamente a adição, precisamos:
- O valor com o índice atual. Este índice aponta para o final da fila para adicionar itens.
- , .
lock-free
: . :
- CAS .
- .
, , .
- lock-free . , , . Lock-free? Não! , 2 : . lock-free, — ! , , , . . , .. , .
- . , . .
, lock-free .
Lock-free
, , : , .. , :
push(queue, value): # index = queue.get_current_index() while true: # , # var = queue.at(index) # = 0 , .. # , if var.CAS_versioned(0, value): # , queue.update_index(index + 1) break # , . index = max(queue.get_current_index(), index + 1) update_index(queue, index): while true: # cur_index, version = queue.get_current_index_versioned() # , # , . if cur_index >= index: # - , # break if queue.current_index_var().CAS_versioned(version, index): # , break # - . # , ,
. , ( — , , ). lock-free . ?
, push , ! , , .
. : . , - , - . , , .. . . ? , .. , , .
, , . .. . , , . , .
, . , . , , . , .
, , , .
. .
, :
- , .. stateless.
- , — .
, , concurrent exactly-once .
:
handle(input, output): index = 0 while true: value = input.get(index) output.push(value) index += 1
. :
handle(input, output, state): # index = state.get() while true: value = input.get(index) output.push(value) index += 1 # state.set(index)
exactly-once . , , , .
exactly-once , , . .., , , , , — :
# get_next_index(queue): index = queue.get_index() # while queue.has(index): # queue.push index = max(index + 1, queue.get_index()) return index # . # true push_at(queue, value, index): var = queue.at(index) if var.CAS_versioned(0, value): # queue.update_index(index + 1) return true return false handle(input, output, state): # # {PREPARING, 0} fsm_state = state.get() while true: switch fsm_state: case {PREPARING, input_index}: # : , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) if output.push_at(value, output_index): # , input_index += 1 # , push_at false, # fsm_state = {PREPARING, input_index} state.set(fsm_state)
push_at ? , . , , , . , . . - , lock-free .
, :
- : .
- , : .
: concurrent exactly-once .
? :
- , ,
push_at false. . - , . , , .
concurrent exactly-once ? , , . , . .
:
# , , # .. true, # true. # false push_at_idempotent(queue, value, index): return queue.push_at(value, index) or queue.get(index) == value handle(input, output, state): version, fsm_state = state.get_versioned() while true: switch fsm_state: case {PREPARING, input_index}: # , , # output_index = output.get_next_index() fsm_state = {WRITING, input_index, output_index} case {WRITING, input_index, output_index}: value = input.get(input_index) # , # if output.push_at_idempotent(value, output_index): input_index += 1 fsm_state = {PREPARING, input_index} # if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

, . , .
kernel panic, , .. . . : , . , .
, , .
: .
: , , , , :
# : # - input_queues - # - output_queues - # - state - # - handler - : state, inputs -> state, outputs handle(input_queues, output_queues, state, handler): # version, fsm_state = state.get_versioned() while true: switch fsm_state: # input_indexes case {HANDLING, user_state, input_indexes}: # inputs = [queue.get(index) for queue, index in zip(input_queues, input_indexes)] # , next_indexes = next(inputs, input_indexes) # # user_state, outputs = handler(user_state, inputs) # , # fsm_state = {PREPARING, user_state, next_indexes, outputs, 0} case {PREPARING, user_state, input_indexes, outputs, output_pos}: # , # output_index = output_queues[output_pos].get_next_index() # fsm_state = { WRITING, user_state, input_indexes, outputs, output_pos, output_index } case { WRITING, user_state, input_indexes, outputs, output_pos, output_index }: value = outputs[output_pos] # if output_queues[output_pos].push_at_idempotent( value, output_index ): # , output_pos += 1 # , PREPARING. # # fsm_state = if output_pos == len(outputs): # , # {HANDLING, user_state, input_indexes} else: # # , # {PREPARING, user_state, input_indexes, outputs, output_pos} if state.CAS_versioned(version, fsm_state): version += 1 else: # , version, fsm_state = state.get_versioned()
:

: HANDLING . , .., , . , . , PREPARING WRITING , . , HANDLING .
, , , . , . , .
. . .

:
my_handler(state, inputs): # state.queue.push(inputs) # duration state.queue.trim_time_window(duration) # avg = state.queue.avg() need_update_counter = state.queue.size() > size_boundary return state, [ avg, if need_update_counter: true else: # none none ]
, , concurrent exactly-once handle .
:
handle_db(input_queue, db): while true: # tx = db.begin_transaction() # . # , # index = tx.get_current_index() # tx.write_current_index(index + 1) # value = intput_queue.get(index) if value: # tx.increment_counter() tx.commit() # , , #
. Porque , , , , concurrent exactly-once . .
— . , , .
, , . , , .
. , . Porque , . . .
— . , , . , - , , . , .. , , .
. , , . , , .
. , . : , . , .
, , :
- , . .
- . , .
- . , . , , . .. . : .
, , -, , -, .
, . :
transfer(from, to, amount): # if withdraw(from, amount) is ok: # , # deposit(to, amount)
withdraw , , deposit : ? deposit - (, , ), . , , , , ? , , - , .
, , , . , , , . , . , , . Porque , , . , : , — .
, .
: , , , , . , - :
, , .
, , .. , , . , .
: lock-free , . , .. , .
CAS . , :
# , handle(input, output, state): # ... while true: switch fsm_state: case {HANDLING, ...}: # fsm_state = {PREPARING, ...} case {PREPARING, input_index}: # ... output_index = ...get_next_index() fsm_state = {WRITING, output_index, ...} case {WRITING, output_index, ...}: # , output_index
, . . :
- PREPARING . , .
- WRITING . . , PREPARING .
, . , , — . :
- . , , .. , .
- , .. . , .
, lock-free , , .
, . , Stale Read , . — CAS: . :
- Distributed single register — (, etcd Zookeeper):
- Linearizability
- Sequential consistency
- Transactional — (, MySQL, PostgreSQL ..):
- Serializability
- Snapshot Isolation
- Repeatable Read
- Read Committed
- Distributed Transactional — NewSQL :
- Strict Consistency
: ? , , . , , CAS . , , Read My Writes .
exactly-once . , .. , , , . , , , , .. , .
lock-free .
:
- : .
- : .
- : : exactly-once .
- Concurrent : .
- Real-time : .
- Lock-free : , .
- Deadlock free : , .
- Race condition free : .
- Hot-hot : .
- Hard stop : .
- No failover : .
- No downtime : .
- : , .
- : .
- : .
- : .
, . Mas isso é outra história.

:
- Concurrent exactly-once.
- Semi-transactions .
- Lock-free two-phase commit, .
- .
- lock-free .
- .
Literatura
[1] Wikipedia: O Problema da ABA.
[2] Blog: você não pode ter entrega exata uma vez.
[3] Habr: alcançabilidade do limite inferior no tempo de execução do commit de transações distribuídas à prova de falhas.
[4] Habr: assincronia 3: modelo subjetivo.
[5] Wikipedia: sincronização sem bloqueio.