A primeira parte, “Avaliação do Cavium ThunderX2: o sonho de um servidor Arm se tornou realidade” está
aquiConfiguração e metodologia de teste
Para a revisão do ThunderX2, todos os nossos testes foram realizados no kernel do Ubuntu Server 17.10, Linux 4.13 de 64 bits. Geralmente usamos a versão LTS, mas como o Cavium vem com essa versão específica do Ubuntu, não corremos o risco de alterar o sistema operacional. A distribuição Ubuntu inclui o compilador GCC 7.2.

Você notará que a quantidade de DRAM varia em nossas configurações de servidor. O motivo é simples: a Intel possui 6 canais de memória e o ThunderX2 da Cavium possui 8 canais de memória.
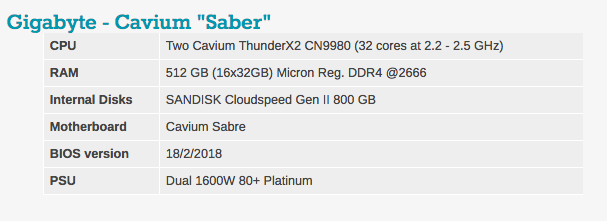
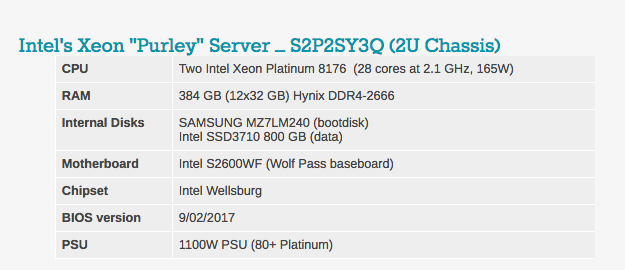
As configurações típicas do BIOS podem ser vistas abaixo. Vale ressaltar que o hyperthreading e a tecnologia de virtualização da Intel estão incluídas.
Outras notasAmbos os servidores são alimentados de acordo com o padrão europeu - 230 V (máximo de 16 amperes). A temperatura do ar interior é controlada e mantida a 23 ° C pelos nossos instrumentos Airwell CRAC.
Consumo de energia
Vale ressaltar que o sistema Gigabyte “Saber” consumia 500 watts se estivesse apenas executando o Linux (ou seja, estava praticamente ocioso). No entanto, sob carga, o sistema consome cerca de 800 W, o que, em princípio, atendeu às nossas expectativas, pois temos dois chips TDP de 180 W no interior. Como é geralmente o caso dos sistemas de teste iniciais, não podemos fazer comparações precisas de potência.
De fato, Cavium afirma que os sistemas atuais da HP, Gigabyte e outros serão muito mais eficientes. O sistema de teste do Sabre usado teve vários problemas com o gerenciamento de energia: controle incorreto do firmware do ventilador, erro de BMC e unidade de fonte de alimentação com muita energia (1600 W).
Subsistema de memória: Largura de banda
O uso do benchmark Stream de largura de banda Stream de John McCalpin nos processadores mais recentes está se tornando cada vez mais difícil de medir todo o potencial da largura de banda do sistema à medida que o número de canais principais e de memória aumenta. Como você pode ver nos resultados abaixo, estimar o rendimento não é fácil. O resultado depende muito das configurações selecionadas.

Teoricamente, o ThunderX2 tem 33% mais largura de banda que o Intel Xeon, uma vez que o SoC possui 8 canais de memória em comparação com seis canais da Intel. Esses números de alta taxa de transferência são alcançados somente sob condições muito específicas e requerem algum ajuste para evitar o uso de memória remota. Em particular, devemos garantir que os fluxos não sejam transportados de um soquete para outro.
Para iniciantes, tentamos obter os melhores resultados nas duas arquiteturas. No caso da Intel, o compilador ICC sempre produziu melhores resultados com algumas otimizações de baixo nível nos loops de fluxo. No caso do Cavium, seguimos as instruções do Cavium. Grosso modo, a imagem resultante é uma idéia de qual largura de banda esses processadores podem atingir em seus picos. Para ser honesto com a Intel, com as configurações ideais (AVX-512), você pode atingir 200 GB / s.
No entanto, é óbvio que o sistema ThunderX2 pode fornecer 15 a 28% mais largura de banda aos núcleos do processador. O resultado é 235 GB / s, ou cerca de 120 GB / s por slot. Este, por sua vez, é cerca de 3 vezes maior que o ThunderX original.
Subsistema de memória: atraso
Embora as medições de largura de banda se apliquem apenas a uma pequena parte do mercado de servidores, quase todos os aplicativos são altamente dependentes da latência do subsistema de memória. Nas tentativas de medir a latência do cache e da memória, usamos o LMBench. Os dados que queremos ver como resultado são "Atraso em carregamento aleatório, passo = 16 bytes". Observe que expressamos a latência L3 e o atraso de tempo da DRAM em nanossegundos, pois não temos valores exatos do relógio do cache L3.
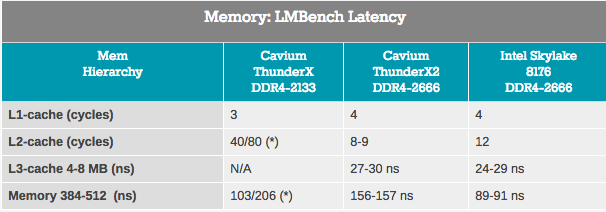
O cache ThunderX2 L2 é acessado com latência muito baixa e, ao usar um único fluxo, o cache L3 parece um concorrente do cache L3 integrado da Intel. No entanto, quando chegamos à DRAM, a Intel mostrou uma latência significativamente menor.
Subsistema de memória: TinyMemBench
Para entender melhor as arquiteturas respectivas, foi utilizado o teste de código aberto TinyMemBench. O código-fonte foi compilado usando o GCC 7.2 e o nível de otimização foi definido como -O3. A estratégia de teste está bem descrita no manual de benchmark:
O tempo médio é medido para acessos aleatórios à memória em buffers de vários tamanhos. Quanto maior o buffer, maior a contribuição relativa de falhas de cache TLB, acessos L1 / L2 e DRAM. Todos os números representam o tempo extra que precisa ser adicionado à latência do cache L1 (4 ciclos).
Testamos com uma e duas leituras aleatórias (sem páginas enormes), porque queríamos ver como o sistema de memória lidava com várias solicitações de leitura.
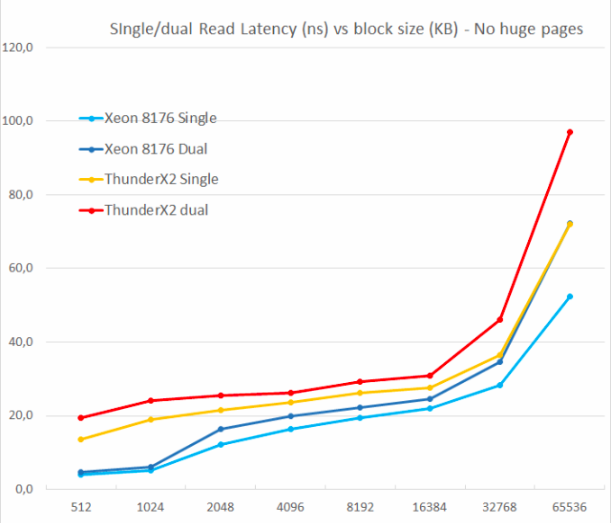
Uma das principais desvantagens do ThunderX original foi a incapacidade de suportar várias falhas pendentes. A simultaneidade no nível de memória é um recurso importante para qualquer núcleo moderno de processador de alto desempenho: com sua ajuda, evita falhas de cache que podem causar "fome" de back-end. Portanto, um cache sem bloqueio é um recurso essencial para núcleos grandes.
O ThunderX2 não sofre com esse problema, graças ao seu cache sem bloqueio. Assim como o núcleo Skylake no Xeon 8176, a segunda leitura aumenta a latência total em apenas 15 a 30%, não em 100%. De acordo com o TinyMemBench, o núcleo do Skylake possui uma latência significativamente melhor. O ponto de referência de 512 KB é fácil de explicar: o núcleo do Skylake ainda está sendo recuperado do seu L2 rápido e o núcleo do ThunderX2 deve acessar o L3. Mas os números de 1 e 2 MB mostram que os pré-buscadores da Intel oferecem uma vantagem séria, pois a latência é a média do cache L2 e L3. As taxas de latência são semelhantes no intervalo de 8 a 16 MB, mas assim que ultrapassamos L3 (64 MB), o Skylake da Intel oferece uma memória de menor latência.
Desempenho de thread único: SPEC CPU2006
Começando com a medição do desempenho real da computação, começamos com o pacote SPEC CPU2006. Os leitores informados indicarão que o SPEC CPU2006 foi preterido quando o SPEC CPU2017 apareceu. Mas, devido ao tempo limitado de teste e ao fato de não termos conseguido testar novamente o ThunderX, decidimos seguir o CPU2006.
Como o SPEC é quase tão bom como um benchmark de compilador que o hardware, acreditamos que será apropriado formular nossa filosofia de teste. Você precisa avaliar os indicadores reais e não inflar os resultados do teste. Portanto, é importante criar, na medida do possível, condições "como no mundo real" com as seguintes configurações (críticas construtivas sobre esse assunto são bem-vindas):
- Gcc de 64 bits: o compilador mais usado no Linux, um bom compilador que não tenta "interromper" os testes (libquantum ...)
- -Ofast: otimização do compilador que muitos desenvolvedores podem usar
- -fno-strict-aliasing: necessário para compilar alguns subtestes
- execução base: cada subteste é compilado da mesma maneira
Primeiro, você precisa medir o desempenho em aplicativos nos quais, por algum motivo, ocorre um atraso devido a um "ambiente hostil multithread". Segundo, você precisa entender como a arquitetura ThunderX LLC funciona com um único thread em comparação com a arquitetura Skylake da Intel. Observe que, nesse modelo Skylake específico, você pode fazer um overclock da frequência em 3,8 GHz. O chip funcionará a uma frequência de 2,8 GHz em quase todas as situações (28 threads estão ativos) e suportará 3,4 GHz com 14 threads ativos.
Em geral, a Cavium posiciona o ThunderX2 CN9980 (US $ 1795) como "melhor que 6148" (US $ 3072), um processador operando a 2,6 GHz (20 threads) e atingindo 3,3 GHz sem problemas (até 16 threads ativos) ) Por outro lado, o Intel-SKU terá uma vantagem significativa de 30% na velocidade do relógio em muitas situações (3,3 GHz versus 2,5 GHz).
A Cavium decidiu compensar o déficit de frequência pelo número de núcleos, oferecendo 32 núcleos - 60% a mais que o Xeon 6148 (20 núcleos). Vale ressaltar que um número maior de núcleos levará a uma diminuição no retorno em muitas aplicações (por exemplo, Amdahl). Portanto, se a Cavium quiser abalar a posição dominante da Intel com o ThunderX2, cada núcleo deve ao menos oferecer desempenho competitivo no mundo real. Ou nesse caso, o ThunderX2 deve fornecer pelo menos 66% (2,5 versus 3,8) de desempenho Skylake de thread único.
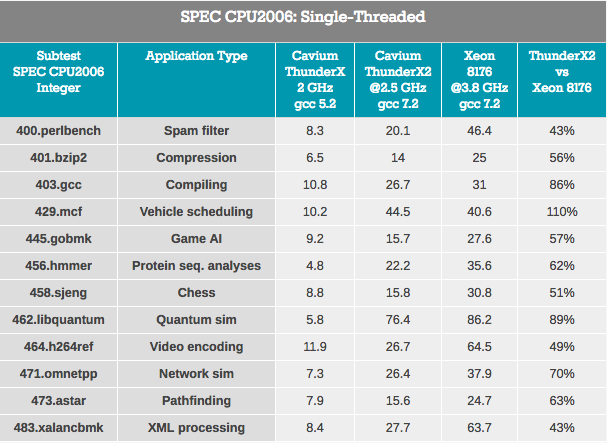
Os resultados são imprecisos porque o ThunderX2 funciona com o código ARMv8 (AArch64) e o Xeon usa o código x86-64.
Testes de rastreamento de ponteiro - o processamento XML (também grandes buffers OoO) e a localização de caminhos que normalmente dependem de um cache L3 grande para reduzir o impacto da latência de acesso são os piores para o ThunderX2. Pode-se assumir que uma latência mais alta do sistema DRAM prejudica o desempenho.
Cargas de trabalho nas quais a influência da previsão de ramificação é maior (pelo menos em x86-64: uma porcentagem maior de escolha da ramificação errada) - gobmk, sjeng, hmmer - não são as melhores cargas no ThunderX2.
Também é importante notar que as instruções perlbench, gobmk, hmmer e h264ref são conhecidas por se beneficiarem do cache L2 maior do Skylake (512 KB). Mostramos apenas algumas peças do quebra-cabeça, mas juntas elas podem ajudar a montar a imagem.
No lado positivo, o ThunderX2 funcionou bem para o gcc, que funciona principalmente dentro do cache L1 e L2 (contando com baixa latência L2), e o impacto do desempenho do preditor de ramificação é mínimo. Em geral, o melhor teste para o TunderX2 é o mcf (distribuição de veículos no transporte público), que, como você sabe, ignora quase completamente o cache de dados L1, contando com o cache L2, e esse é o ponto forte do ThunderX2. Mcf também está exigindo largura de banda de memória. Libquantum é um teste que tem a maior necessidade de largura de banda de memória. O fato de o Skylake oferecer largura de banda de thread único bastante medíocre também é provavelmente o motivo pelo qual o ThunderX2 teve um desempenho tão bom no libquantum e no mcf.
SPEC CPU2006 Cont: desempenho baseado em núcleo com SMT
Indo além do desempenho de thread único, o desempenho multi-thread em um único núcleo também deve ser considerado. A arquitetura do processador Vulcan foi originalmente projetada para usar o SMT4 para manter seus núcleos carregados e aumentar a taxa de transferência geral, e falaremos sobre isso agora.
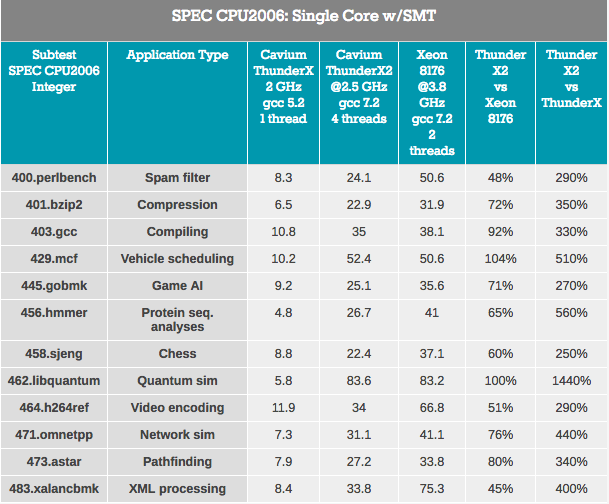
Primeiro de tudo, o núcleo ThunderX2 "sofreu" muitas melhorias significativas em relação ao primeiro núcleo ThunderX. Mesmo com a libquantum em mente, esse teste pode ser executado três vezes mais rápido no kernel ThunderX mais antigo, após algumas melhorias e otimizações no compilador. Bem, o novo ThunderX2 não é nada menos que 3,7 vezes mais rápido que seu irmão mais velho. Essa superioridade do IPC elimina quaisquer vantagens do ThunderX anterior.
Ao analisar o impacto do SMT, em média, vemos que o SMT de quatro vias melhora o desempenho do ThunderX2 em 32%. Isso varia de 8% para codificação de vídeo a 74% para Pathfinding. Enquanto isso, a Intel está ganhando 18% de seu SMT bidirecional, de 4% para 37% nos mesmos cenários.
No geral, o aumento de desempenho do ThunderX2 é de 32%, o que é muito bom. Mas aqui surge a pergunta óbvia: como é diferente de outras arquiteturas SMT4? Por exemplo, o IBM POWER8, que também suporta SMT4, mostra um aumento de 76% no mesmo cenário.
No entanto, isso não é exatamente uma comparação do similar com o similar, já que o chip IBM possui um back-end muito mais amplo: ele pode processar 10 instruções, enquanto o núcleo do ThunderX2 é limitado a 6 instruções por ciclo. O núcleo do POWER8 é mais guloso: o processador pode acomodar apenas 10 desses núcleos "ultra-largos" em um orçamento de energia de 190 W a 22 nm. Provavelmente, um aumento adicional no desempenho do uso do SMT4 exigirá núcleos ainda maiores e, por sua vez, afetará seriamente o número de núcleos disponíveis no ThunderX2. No entanto, é interessante observar esse aumento de 32% no futuro.
Na próxima (3) parte:
- Desempenho Java
- Desempenho Java: páginas enormes
- Comparação do Apache Spark 2.x
- Sumário
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?