A primeira e a
segunda parte, "Avaliação Cavium ThunderX2: o sonho do servidor de arm se tornou realidade".
Desempenho Java
O SPECjbb 2015 é um benchmark do Java Business Benchmark usado para avaliar o desempenho de servidores executando aplicativos Java típicos. Ele usa os mais recentes recursos Java 7 e XML, alterando a segurança.

Observe que atualizamos a versão do SPECjbb 1.0 para a versão 1.01.

Testamos o SPECjbb com quatro grupos de injetores de transações e back-end. O motivo pelo qual usamos o teste da Multi JVM é que ele está mais próximo das condições reais: várias máquinas virtuais em um servidor são uma prática comum, especialmente em servidores com mais de 100 threads. A versão do Java é OpenJDK 1.8.0_161.
Sempre que publicamos os resultados do SPECjbb, recebemos comentários de que nosso desempenho é muito baixo. Portanto, decidimos gastar um pouco mais de tempo e prestar atenção a várias configurações.
- Configurações do kernel, como horários do agendador de tarefas, limpando o cache da página
- Desativando recursos de economia de energia, configurando manualmente o comportamento do estado c.
- Configurando os ventiladores para a velocidade máxima (gastamos muita energia em favor de alguns pontos de desempenho extras)
- Desativando funções RAS (por exemplo, limpeza de memória)
- Inúmeras configurações para vários parâmetros Java ... Não é realista, porque cada vez que você executa o aplicativo em máquinas diferentes (o que geralmente acontece na nuvem), especialistas caros devem definir as configurações de uma máquina específica, o que, além disso, pode fazer com que o aplicativo pare em outras máquinas
- Defina configurações NUMA muito específicas de SKU e mapeamentos de CPU. A migração entre dois SKUs diferentes no mesmo cluster pode levar a sérios problemas de desempenho.
Em um ambiente de produção, a configuração deve ser simples e, de preferência, não muito específica para a máquina. Para esse fim, aplicamos dois tipos de configurações. O primeiro é uma configuração muito simples para medir o desempenho imediatamente e colocar tudo em um servidor com 128 GB de RAM:
"-server -Xmx24G -Xms24G -Xmn16G"Para a segunda configuração, em busca do melhor indicador de taxa de transferência, tocamos com "-XX: + AlwaysPreTouch", "-XX: -UseBiasLocking" e "specjbb.forkjoin.workers". "+ AlwaysPretouch" antes de iniciar redefine todas as páginas da memória, o que reduz o impacto do desempenho em novas páginas. "-UseBiallyLockin" desativa o bloqueio aumentado, que é ativado por padrão. O bloqueio tendencioso dá prioridade a um encadeamento que já carregou dados conflitantes no cache. O verso do bloqueio parcial é processos adicionais (Rebias) bastante complexos que podem reduzir o desempenho no caso de uma estratégia escolhida incorretamente.
O gráfico abaixo mostra o desempenho máximo do nosso benchmark MultiJVM SPECJbb.

O ThunderX2 alcança desempenho de 80 a 85% do Xeon 8176. Esse número é suficiente para superar o Xeon 6148. Curiosamente, os sistemas Intel e Cavium alcançam seus melhores resultados de diferentes maneiras. No caso do Dual ThunderX2, usamos:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingEnquanto o sistema Intel obteve o melhor desempenho, deixando um bloqueio de deslocamento (padrão). Percebemos que o sistema Intel - provavelmente devido ao número relativamente "ímpar" de encadeamentos - possui uma carga média do processador ligeiramente mais baixa (alguns por cento) e um cache L3 maior, o que torna o bloqueio parcial uma boa estratégia para essa arquitetura.
Por fim, temos o Critical-jOPS, que mede a taxa de transferência por limites de tempo de resposta.

Com o uso ativo de um grande número de encadeamentos, é possível obter significativamente mais Critical-jOPS aumentando a distribuição de RAM na JVM. Surpreendentemente, o sistema Dual ThunderX2 - com seu maior número de fluxos e menor velocidade de clock - mostra o melhor tempo, fornecendo alta largura de banda, mantendo um tempo de resposta de 99% até um determinado limite.
Aumentar o tamanho do heap ajuda a Intel a diminuir um pouco a diferença (até x2), mas às custas da largura de banda (de -20% a -25%). Parece que o chip Intel precisa de mais personalização que o ARM. Para explorar isso ainda mais, optamos por Transparant Huge Pages (THP).
Desempenho Java: páginas grandes
Geralmente para a CPU, alguém raramente reproduz outra no fator 3, mas decidimos investigar o assunto mais profundamente. O candidato mais óbvio foi o Huge Pages, ou como todos, exceto a comunidade Linux, chamam de "Large Pages".
Cada processador moderno armazena em cache os mapeamentos de memória física e virtual em seus TLBs. O tamanho da página "normal" é de 4 KB, portanto, com 1536 elementos, o núcleo do Skylake pode armazenar em cache cerca de 6 MB por núcleo. Nos últimos 15 anos, a capacidade de DRAM aumentou de alguns GB para centenas de GB e, portanto, as perdas de TLB se tornaram uma preocupação. Uma falta de TLB é bastante cara - você precisa de alguns acessos à memória para ler algumas tabelas e finalmente encontrar um endereço físico.
Todos os processadores modernos suportam páginas grandes. No x86-64 (Intel e AMD), uma opção popular é 2 MB, uma página de 1 GB também está disponível. Enquanto isso, uma página grande no ThunderX2 é de pelo menos 0,5 GB. O uso de páginas grandes reduz o número de falhas no TLB (embora o número de entradas nos TLBs seja geralmente muito menor para páginas grandes), reduz o número de acessos à memória necessários na falta de um TLB.
No entanto, era hora de o Linux suportar esse recurso de maneira conveniente. A fragmentação da memória, configurações conflitantes e difíceis de configurar, incompatibilidades e nomes especialmente muito confusos causaram muitos problemas. De fato, muitos fornecedores de software ainda aconselham os administradores de servidor a desativar páginas grandes.
Para esse fim, vamos ver o que acontece se ativarmos as Páginas enormes transparentes e salvarmos as melhores configurações discutidas anteriormente.
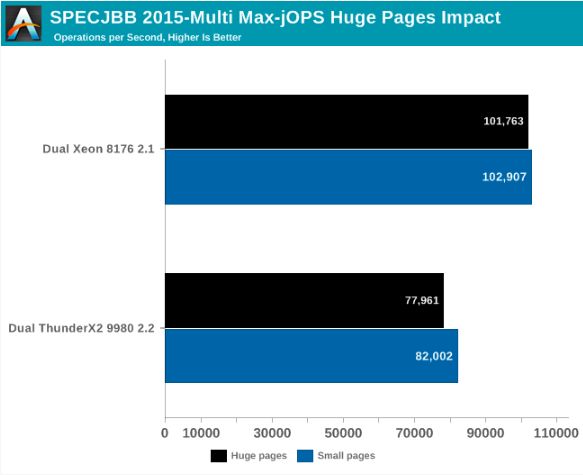
No geral, para Max-jOPs, o impacto no desempenho não é espetacular; isso é realmente uma pequena regressão. O Xeon perde cerca de 1% de sua largura de banda, o ThunderX2 - cerca de 5%.
Vamos para a métrica Critical-jOPS, onde a taxa de transferência é medida como o 99º percentil do limite de tempo de resposta.

Enorme diferença! Em vez de derrota, a Intel vai além do ThunderX2. No entanto, deve-se dizer que o desempenho com páginas de 4 KB é aparentemente uma fraqueza séria na arquitetura Intel.
Comparação do Apache Spark 2.x
Por último, mas não menos importante, nosso arsenal tem o teste Apache Spark. O Apache Spark é uma criação do processamento de Big Data. Acelerar as aplicações de Big Data continua sendo um projeto prioritário no laboratório da universidade em que trabalho (Sizing Servers Lab University of West-Flanders), por isso preparamos uma referência que usa muitos recursos do Spark e se baseia no uso no mundo real.

O teste é descrito no diagrama acima. Começamos com 300 GB de dados compactados coletados do CommonCrawl. Esses arquivos compactados são um grande número de arquivos da web. Descompactamos os dados rapidamente para evitar uma longa espera, principalmente relacionada ao dispositivo de armazenamento. Em seguida, extraímos os dados de texto significativos dos arquivos usando a biblioteca Java BoilerPipe. Usando a Stanford CoreNLP Natural Language Processing Tool, extraímos entidades (“palavras que significam alguma coisa”) do texto e calculamos quais URLs têm maior ocorrência desses objetos. O algoritmo Alternating Lessest Square é usado para recomendar quais URLs são mais interessantes para um assunto específico.
Para alcançar uma melhor escala, lançamos 4 artistas. O pesquisador Esley Havenert reconfigurou o teste Spark para que ele pudesse executar no Apache Spark 2.1.1.
Aqui estão os resultados:

(*) O EPYC e o Xeon E5 V4 são mais antigos, funcionam no Kernel 4.8 e no Java 1.8.0_131 um pouco mais antigo do que no 1.8.0_161. Embora esperemos que os resultados sejam muito semelhantes no kernel 4.13 e no Java 1.8.0_161, já que não vimos muita diferença no Skylake Xeon entre essas duas configurações.
O processamento de dados é muito paralelo e carrega muito intensamente o processador, mas para as fases de "embaralhamento" requer muita interação com a memória. O tempo gasto na comunicação com o dispositivo de armazenamento é insignificante. A fase do ALS não é escalável em vários threads, mas é inferior a 4% do tempo total de teste.
O ThunderX2 fornece 87% do desempenho do EPYC 7601 duas vezes mais caro. Como esse indicador se adapta bem ao número de núcleos, podemos estimar que o Xeon 6148 terá cerca de 4,8. Assim, enquanto o ThunderX2 não pode realmente ameaçar o Xeon Platinum 8176, ele oferece a mesma coisa que o Gold 6148 e seu irmão por muito menos dinheiro.
E o que no final
Para resumir tudo, nossos testes SPECInt mostram que os núcleos ThunderX2 ainda têm algumas falhas. Nossa primeira impressão negativa é que o código de ramificação intensivo - especialmente em combinação com as falhas habituais de cache L3 (alto atraso de DRAM) - funciona bem devagar. Assim, haverá casos especiais em que o ThunderX2 não é a melhor escolha.
No entanto, além de alguns nichos de mercado, temos certeza de que o ThunderX2 se tornará um sólido desempenho. Por exemplo, as medições de desempenho realizadas por nossos colegas da Universidade de Bristol confirmam nossa suposição de que cargas de trabalho intensas de HPC, como OpenFoam (CFD) e NAMD.run, funcionam bem no ThunderX2
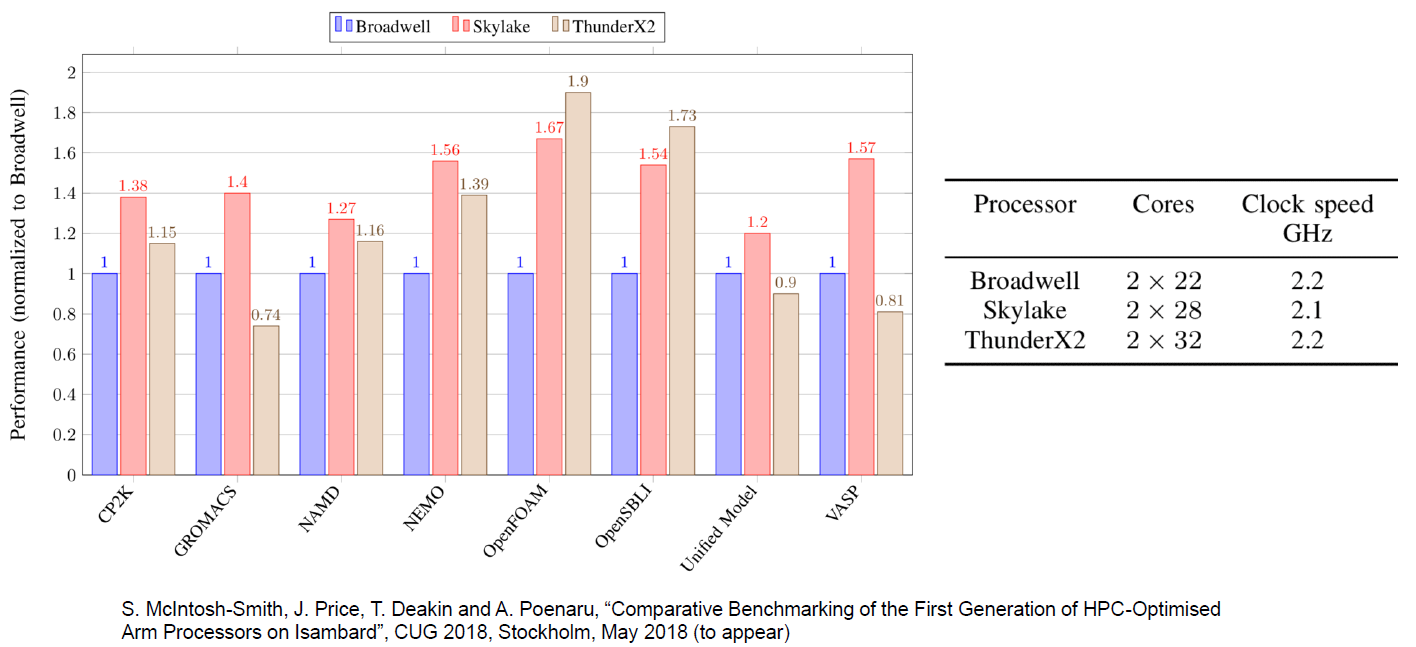
Com base nos resultados dos testes iniciais do software para servidor que conseguimos, podemos ser agradavelmente surpreendidos. O desempenho do ThunderX2 por um dólar no Java Server (SPECJbb) e no processamento de big data - agora - de longe o melhor do mercado de servidores. Temos que testar novamente o processador AMD EPYC e a versão dourada da geração atual (Skylake) Xeon, mas, ao mesmo tempo, 80-90% do desempenho do processador 8176 por um quarto de seu custo será muito difícil de superar.
Como um benefício adicional ao Cavium e ao ThunderX2, deve-se mencionar que o ecossistema Arm Linux já está maduro em 2018; kernels Linux especializados e outras ferramentas não são mais necessários. Você simplesmente instala o servidor Ubuntu, Red Hat ou Suse e pode automatizar a implantação e instalação do software a partir de repositórios padrão. Esta é uma melhoria significativa em relação ao que experimentamos quando o ThunderX foi lançado. Em 2016, uma instalação simples a partir de repositórios regulares do Ubuntu poderia causar problemas.
Então, no geral, o ThunderX2 é um rival muito poderoso. Isso pode ser ainda mais perigoso para o EPYC AMD do que para o Skylake Xeon, da Intel, porque o Cavium e a AMD estão competindo pelo mesmo grupo de clientes, dada a possibilidade de abandonar a Intel. Isso se deve ao fato de os clientes que investiram em software corporativo caro (Oracle, SAP) serem menos sensíveis ao custo no lado do hardware e, portanto, são muito menos propensos a mudar para uma nova plataforma de hardware. E essas pessoas investiram na Intel nos últimos 5 anos, pois essa era a única opção.
Por sua vez, isso significa que aqueles que são mais flexíveis e sensíveis ao preço, como provedores de hospedagem e nuvem, agora poderão escolher um servidor Arm alternativo com uma excelente relação desempenho / dólar. E com a HP, Cray, Pengiun, Gigabyte, Foxconn e Inventec oferecendo sistemas baseados em ThunderX2, não faltam fornecedores de qualidade.
Em resumo, o ThunderX2 é o primeiro SoC a competir com a Intel e a AMD no mercado de servidores de CPU. E isso é uma surpresa agradável: finalmente, uma solução para os servidores Arm apareceu!
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?