A replicação de fluxo, que apareceu em 2010, tornou-se um dos principais recursos do PostgreSQL e, atualmente, quase nenhuma instalação é concluída sem o uso da replicação de fluxo. É confiável, fácil de configurar, sem exigir recursos. No entanto, por todas as suas qualidades positivas, durante sua operação, vários problemas e situações desagradáveis podem surgir.
Alexey Lesovsky (
@lesovsky ) do Highload ++ 2017 contou como
diagnosticar vários tipos de problemas usando ferramentas internas e de terceiros
e como corrigi-los . Sob os cortes, a decodificação deste relatório, baseada em um princípio espiral: primeiro, listamos todas as ferramentas de diagnóstico possíveis, depois listamos problemas comuns e diagnosticamos, depois vemos quais medidas de emergência podem ser tomadas e, finalmente, como lidar radicalmente com o problema.
Sobre o palestrante : Alexei Lesovsky, administrador de banco de dados da Data Egret. Um dos tópicos favoritos de Alexey no PostgreSQL é transmitir replicação e trabalhar com estatísticas; portanto, o relatório no Highload ++ 2017 foi dedicado a como encontrar problemas usando estatísticas e quais métodos usar para resolvê-los.
Planejar
- Um pouco de teoria ou como a replicação funciona no PostgreSQL
- Ferramentas de solução de problemas ou o que o PostgreSQL e a comunidade possuem
- Resolução de casos:
- problemas: seus sintomas e diagnóstico
- decisões
- medidas a serem tomadas para que esses problemas não surjam.
Por que tudo isso? Este artigo ajudará você a entender melhor a replicação de streaming, aprender a encontrar e corrigir problemas rapidamente, a fim de reduzir o tempo de reação a incidentes desagradáveis.
Pouco de teoria
O PostgreSQL possui uma entidade como o Write-Ahead Log (XLOG), um log de transações.
Quase todas as alterações que ocorrem com dados e metadados dentro do banco de dados são registradas neste log. Se ocorrer um acidente repentino, o PostgreSQL inicia, lê o log de transações e restaura as alterações registradas nos dados. Isso garante confiabilidade - uma das propriedades mais importantes de qualquer DBMS e PostgreSQL também.
O log de transações pode ser preenchido de duas maneiras:
- Por padrão, quando os back-end fazem algumas alterações no banco de dados (INSERT, UPDATE, DELETE etc.), todas as alterações são registradas no log de transações de forma síncrona :
- O cliente enviou um comando COMMIT para confirmar os dados.
- Os dados são registrados no log de transações.
- Depois que a fixação ocorre, o controle é dado ao back-end e ele pode continuar recebendo comandos do cliente.
- A segunda opção é a gravação assíncrona no log de transações, quando um processo de gravador WAL dedicado separado grava as alterações no log de transações com um determinado intervalo de tempo. Por esse motivo, é alcançado um aumento no desempenho de back-end, pois não há necessidade de esperar até que o comando COMMIT seja concluído.
Mais importante, a replicação de streaming é baseada nesse log de transações. Temos vários membros de replicação de streaming:
- mestre onde todas as mudanças ocorrem;
- várias réplicas que aceitam o log de transações do mestre e reproduzem todas essas alterações nos dados locais. Isso é replicação de streaming.
Vale lembrar que todos esses logs de transações são armazenados no diretório pg_xlog em $ DATADIR - o diretório com os principais arquivos de dados DBMS. Na 10ª versão do PostgreSQL, esse diretório foi renomeado para pg_wal /, porque não é incomum o pg_xlog / ocupar muito espaço, e desenvolvedores ou administradores, sem saber, confundi-lo com logs, excluir alegremente e tudo fica ruim.
O PostgreSQL possui vários serviços em segundo plano envolvidos na replicação de streaming. Vamos examiná-los do ponto de vista do sistema operacional.
- Do lado do mestre - processo WAL Sender. Este é um processo que envia logs de transações para réplicas, cada réplica terá seu próprio WAL Sender.
- A réplica, por sua vez, executa o processo WAL Receiver, que recebe os logs de transações pela conexão de rede do remetente WAL e os passa para o processo de inicialização.
- O processo de inicialização lê os logs e reproduz no diretório de dados todas as alterações registradas no log de transações.
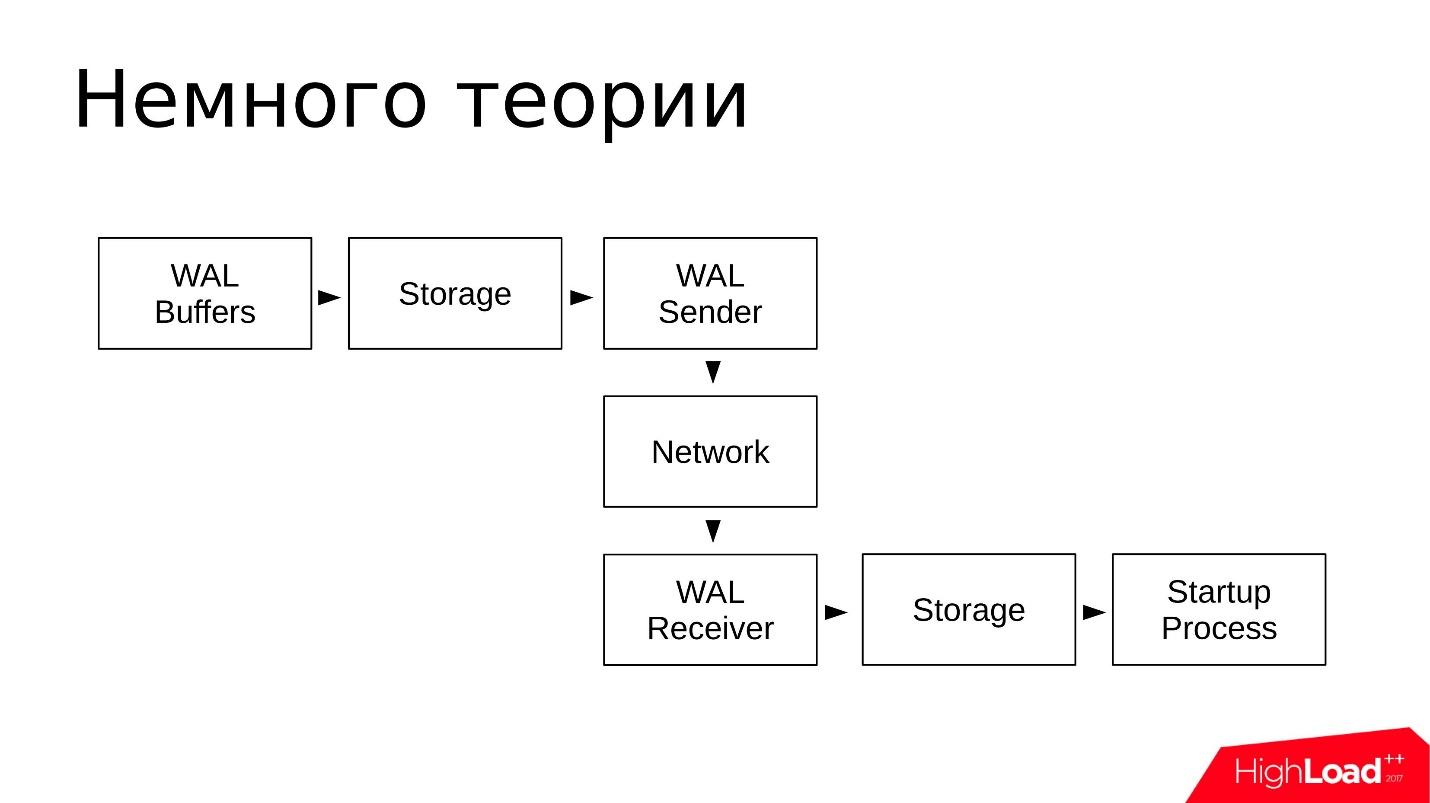
Esquematicamente, é algo parecido com isto:
- As alterações são gravadas nos buffers WAL, que serão gravados no log de transações;
- Os logs estão armazenados no diretório pg_wal /;
- O WAL Sender lê o log de transações do repositório e os transmite pela rede;
- O receptor WAL recebe e armazena em seu armazenamento - no local pg_wal /;
- O processo de inicialização lê tudo o que é aceito e reproduzido.
O esquema é simples. A replicação de fluxo funciona de maneira bastante confiável e foi excelentemente explorada por muitos anos.
Ferramentas de solução de problemas
Vamos ver quais ferramentas e utilitários a comunidade e o PostgreSQL oferecem para investigar os problemas encontrados na replicação de streaming.
Ferramentas de terceiros
Vamos começar com ferramentas de terceiros. Esses utilitários têm um
plano bastante
universal ; podem ser usados não apenas para investigar incidentes relacionados à replicação de streaming. Geralmente, são
utilitários de qualquer administrador do sistema .
- top do pacote procps. Como um substituto para o top, você pode usar quaisquer utilitários, como top, htop e similares. Eles oferecem funcionalidade semelhante.
Com a ajuda do topo, analisamos: utilização de processadores (CPU), carga média (carga média) e uso de memória e espaço de troca.
- iostat de sysstat e iotop. Esses utilitários mostram a utilização de dispositivos de disco e qual E / S é criada pelos processos no sistema operacional.
Com a ajuda do iostat, procuramos: utilização do armazenamento, quantos lops no momento, qual taxa de transferência nos dispositivos, quais atrasos no processamento de solicitações de E / S (latência). Essas informações bastante detalhadas são obtidas do sistema de arquivos procfs e fornecidas ao usuário de forma visual.
- O nicstat é um análogo do iostat, apenas para interfaces de rede. Neste utilitário, você pode assistir a utilização de interfaces.
Usando o nicstat, observamos: da mesma forma, utilização da interface, alguns erros que ocorrem nas interfaces, a taxa de transferência também é um utilitário muito útil.
- O pgCenter é um utilitário para trabalhar apenas com o PostgreSQL. Ele mostra as estatísticas do PostgreSQL em uma interface de ponta, e você também pode ver estatísticas relacionadas à replicação de streaming.
Com a ajuda do pgCenter, olhamos: estatísticas sobre replicação. Você pode observar o atraso na replicação, de alguma forma avaliá-lo e prever trabalhos futuros.
- perf é um utilitário para uma investigação mais profunda das causas de "golpes subterrâneos", quando em operação existem problemas estranhos no nível de código do PostgreSQL.
Com a ajuda do perf, procuramos: batidas subterrâneas. Para que o perf funcione totalmente com o PostgreSQL, este último deve ser compilado com caracteres de depuração, para que você possa ver a pilha de funções nos processos e quais funções levam mais tempo na CPU.
Todos esses utilitários são necessários para
testar hipóteses que surgem ao solucionar problemas - verifique onde e o que diminui, onde e o que você precisa corrigir. Esses utilitários ajudam a garantir que estamos no caminho certo.
Ferramentas Incorporadas
O que o próprio PostgreSQL oferece?
Visualizações do sistema
Em geral, existem muitas ferramentas para trabalhar com o PostgreSQL. Cada empresa fornecedora que fornece suporte ao PostgreSQL oferece suas próprias ferramentas. Mas, como regra, essas ferramentas são baseadas em estatísticas internas do PostgreSQL. Nesse sentido, o PostgreSQL fornece visualizações de sistema nas quais você pode fazer várias seleções e obter as informações necessárias. Ou seja, usando um cliente comum, geralmente psql, podemos fazer consultas e ver o que acontece nas estatísticas.
Existem algumas visualizações do sistema. Para trabalhar com a replicação de streaming e investigar problemas, precisamos apenas de: pg_stat_replication, pg_stat_wal_receiver, pg_stat_databases, pg_stat_databases_conflicts e auxiliar pg_stat_activity e pg_stat_archiver.
Existem alguns deles, mas esse conjunto é suficiente para verificar se há algum problema.
Funções auxiliares
Usando funções auxiliares, você pode obter dados das representações estatísticas do sistema e transformá-los em uma forma mais conveniente para si mesmo. As funções auxiliares também são apenas algumas peças.
- pg_current_wal_lsn () (o antigo análogo de pg_current_xlog_location ()) é a função mais necessária que permite ver a posição atual no log de transações. Um log de transações é uma sequência contínua de dados. Usando esta função, você pode ver o último ponto, obter a posição em que o log de transações parou agora.
- pg_last_wal_receive_lsn (), pg_last_xlog_receive_location () é uma função semelhante ao anterior, apenas para réplicas. A réplica recebe o log de transações e você pode ver a última posição do log de transações recebidas;
- pg_wal_lsn_diff (), pg_xlog_location_diff () é outra função útil. Nós damos a ela duas posições no log de transações, e ela mostra a diferença - a distância entre esses dois pontos em bytes. Essa função é sempre útil para determinar o atraso entre o mestre e as réplicas em bytes.
Uma lista completa de funções pode ser obtida com o meta-comando psql: \ df * (wal | xlog | lsn | location) *.
Você pode digitá-lo no psql e ver todas as funções que wal, xlog, Isn, location contêm. Haverá cerca de 20 a 30 funções, e elas também fornecem várias informações no log de transações. Eu recomendo que você se familiarize.
Utilitário Pg_waldump
Antes da versão 10.0, era chamado pg_xlogdump. O utilitário pg_waldump é necessário quando queremos examinar os segmentos do log de transações, descobrir quais registros de recursos chegaram lá e o que o PostgreSQL escreveu lá, ou seja, para um estudo mais detalhado.
Na versão 10.0, todas as visualizações, funções e utilitários do sistema que incluíam a palavra xlog foram renomeadas. Todas as ocorrências das palavras xlog e location foram substituídas pelas palavras wal e lsn, respectivamente. O mesmo foi feito com o diretório pg_xlog, que se tornou o diretório pg_wal.
O utilitário pg_waldump simplesmente decodifica o conteúdo dos segmentos XLOG em um formato legível por humanos. Você pode ver quais registros de recursos se enquadram nos logs de segmentos durante o trabalho do PostgreSQL, quais índices e arquivos de heap foram alterados, quais informações foram direcionadas para o modo de espera. Assim, muitas informações podem ser visualizadas usando pg_waldump.
Mas há um aviso de isenção de responsabilidade escrito na documentação oficial : pg_waldump pode mostrar dados ligeiramente incorretos quando o PostgreSQL está em execução (pode gerar resultados incorretos quando o servidor está em execução - o que isso significa)
Você pode usar o comando:
pg_waldump -f - /wal_10 \ $(psql -qAtX - "select pg_walfile_name(pg_current_wal_lsn())")
Este é um análogo do comando tail -f apenas para logs de transações. Este comando mostra a cauda do log de transações que está acontecendo no momento. Você pode executar este comando, ele encontrará o último segmento com a entrada mais recente do log de transações, se conectará a ele e começará a exibir o conteúdo do log de transações. Uma equipe um pouco complicada, mas, no entanto, funciona. Costumo usá-lo.
Casos de solução de problemas
Aqui, examinamos os problemas mais comuns que surgem na prática dos consultores, quais podem ser os sintomas e como diagnosticá-los:
As defasagens de replicação são o problema mais comum . Mais recentemente, tivemos correspondência com o cliente:
- Quebramos a replicação mestre-escravo entre os dois servidores.
- Detecção de atraso 2 horas, iniciado pg_dump.
- entendi. Qual é o nosso atraso permitido?
- 16 horas em max_standby_streaming_delay.
- O que acontecerá quando esse atraso for excedido? Sirene uivante?
- Não, as transações serão vencidas e o rolo WAL será retomado.
Temos problemas com atrasos na replicação o tempo todo, e quase toda semana nós os resolvemos.
O aumento do diretório pg_wal / em que os segmentos do log de transações estão armazenados é um problema que ocorre com menos frequência. Porém, neste caso, é necessário tomar medidas imediatas para que o problema não se transforme em uma situação de emergência quando as réplicas caírem.
Consultas longas executadas na réplica levam a
conflitos durante a recuperação . Essa é uma situação em que iniciamos algum tipo de carregamento na réplica, você pode executar consultas de leitura nas réplicas e, nesse momento, essas consultas interferem na reprodução do log de transações. Existe um conflito, e o PostgreSQL precisa decidir se deve aguardar a conclusão da consulta ou concluí-la e continuar reproduzindo o log de transações. Este é um conflito de replicação ou de recuperação.
Processo de recuperação: 100% de uso da CPU - O processo de recuperação de um log de transações em réplicas leva 100% do tempo do processador. Essa também é uma situação rara, mas é bastante desagradável, porque leva a um aumento no atraso na replicação e geralmente é difícil de investigar.
Atrasos na replicação
As defasagens de replicação ocorrem quando a mesma solicitação, executada no mestre e na réplica, retorna dados diferentes. Isso significa que os dados são inconsistentes entre o mestre e as réplicas, e há algum atraso. A réplica precisa reproduzir parte dos logs de transações para acompanhar o assistente. O principal sintoma se parece exatamente com isso: há uma consulta e eles retornam resultados diferentes.
Como procurar por esses problemas?- Há uma visão básica no assistente e nas réplicas - pg_stat_replication . Ele mostra informações sobre todo o WAL Sender, ou seja, sobre processos que enviam logs de transações. Cada réplica terá uma linha separada que mostra estatísticas para essa réplica específica.
- A função auxiliar pg_wal_lsn_diff () permite comparar posições diferentes no log de transações e calcular o mesmo atraso. Com sua ajuda, podemos obter números específicos e determinar onde temos um grande atraso, onde é pequeno e já de alguma forma respondemos ao problema.
- A função pg_last_xact_replay_timestamp () funciona apenas na réplica e permite ver o horário em que a última transação perdida foi executada. Existe uma função now () bem conhecida que mostra a hora atual, subtraímos a hora que nos é mostrada pela função pg_last_xact_replay_timestamp () da função now () e obtemos o intervalo de tempo.
Na 10ª versão do pg_stat_replication, surgiram campos adicionais que mostram o intervalo de tempo já existente no assistente; portanto, esse método já está desatualizado, mas, no entanto, pode ser usado.
Há uma pequena armadilha. Se não houver transações no assistente por um longo período de tempo e ele não gerar logs de transações, a última função mostrará um atraso crescente. De fato, o sistema está simplesmente ocioso, não há atividade, mas no monitoramento podemos ver que o atraso está crescendo. Vale a pena lembrar dessa armadilha.
A vista é a seguinte.

Ele contém informações sobre cada remetente WAL e vários campos que são importantes para nós. Isso é principalmente
client_addr - o endereço de rede da réplica conectada (geralmente um endereço IP) e um conjunto de campos
lsn (em versões mais antigas é chamado de localização), falarei um pouco mais sobre eles.
Na 10ª versão, os campos de
lag apareceram - este é um atraso expresso no tempo, ou seja, um formato mais legível para humanos. O atraso pode ser expresso em bytes ou no tempo - você pode escolher o que mais gosta.
Como regra, eu uso essa solicitação.

Esta não é a consulta mais complexa que pg_stat_replication imprime em um formato mais conveniente e compreensível. Aqui eu uso as seguintes funções:
- pg_wal_lsn_diff () para ler as diferenças. Mas entre o que eu acho que diffs são? Temos vários campos - sent_lsn, write_lsn, flush_lsn, replay_lsn. Ao calcular a diferença entre o campo atual e o anterior, podemos entender com precisão onde ficamos, onde exatamente ocorre o atraso.
- pg_current_wal_lsn () , que mostra a posição atual do log de transações. Aqui, examinamos a distância entre a posição atual no log e a enviada - quantos logs de transações foram gerados, mas não enviados.
- sent_lsn , write_lsn - é quanto é enviado para a réplica, mas não gravado. Ou seja, agora está localizado em algum lugar da rede ou foi recebido por uma réplica, mas ainda não foi gravado dos buffers de rede no armazenamento em disco.
- write_lsn, flush_lsn - está gravado, mas não foi emitido pelo comando fsync - como se estivesse gravado, mas pode estar localizado em algum lugar na RAM, no cache da página do sistema operacional. Assim que fazemos o fsync, os dados são sincronizados com o disco, chegam ao armazenamento persistente e tudo parece confiável.
- replay_lsn, flush_lsn - dados despejados, fsync executado, mas não replicado.
- current_wal_lsn e replay_lsn é um tipo de atraso total que inclui todas as posições anteriores.
Alguns exemplos

A réplica 10.6.6.8 está destacada acima. Ela tem um
atraso pendente , gerou alguns logs de transações, mas eles ainda não foram enviados e estão no mestre. Provavelmente, há algum tipo de problema com o desempenho da rede. Vamos verificar isso usando o utilitário nicstat.
Lançaremos o nicstat, veremos a utilização da interface, se houver algum problema ou erro. Para que possamos testar esta hipótese.

O
atraso de gravação está marcado acima. De fato, esse atraso é bastante raro, quase não vejo que seja grande. O problema pode estar nos discos e usamos o utilitário iostat ou iotop - examinamos a utilização dos armazenamentos de disco, que a E / S é criada pelos processos e depois descobrimos o porquê.
 Liberar e reproduzir atrasos
Liberar e reproduzir atrasos - geralmente o atraso ocorre quando o dispositivo de disco na réplica não tem tempo para simplesmente perder todas as alterações que chegam do mestre.
Também com os utilitários iostat e iotop, examinamos o que acontece com a utilização do disco e por que os freios.
E o último
total_lag é uma métrica útil para sistemas de monitoramento. Se nosso limite total_lag for excedido, uma caixa de seleção será exibida no monitoramento e começaremos a investigar o que está acontecendo lá.
Teste de hipótese
Agora você precisa descobrir como investigar mais um problema específico. Eu já disse que, se houver um atraso na rede, precisamos verificar se está tudo em ordem com a rede.
Agora, quase todos os hosters fornecem 1 Gb / s ou até 10 Gb / s, portanto, uma
largura de banda entupida é o cenário mais improvável . Como regra, você precisa observar os erros. O nicstat contém informações sobre erros nas interfaces. Você pode descobrir que há problemas com os drivers, com a própria placa de rede ou com os cabos.
Investigamos
problemas de armazenamento usando o iostat e o iotop. O iostat é necessário para visualizar a imagem geral do armazenamento em disco: reciclagem de dispositivos, largura de banda, latência. iotop - para pesquisas mais precisas, quando precisamos identificar qual processo está carregando o subsistema de disco. Se esse é algum tipo de processo de terceiros, ele pode ser simplesmente detectado, concluído e talvez o problema desapareça.
Primeiro, analisamos
os atrasos na
recuperação e os conflitos de replicação por meio de top ou pg_stat_activity: quais processos estão em execução, quais solicitações estão em execução, seu tempo de execução e quanto tempo estão em execução. Se houver algumas consultas longas, veremos por que elas funcionam por um longo tempo, filmamos, entendemos e
otimizamos - examinaremos as próprias consultas.
Se houver uma
grande quantidade de logs de transações gerados pelo assistente, podemos detectar isso por
pg_stat_activity . Talvez alguns processos de backup sejam iniciados lá, algum tipo de vácuo tenha sido iniciado (pg_stat_progress_vacuum) ou o ponto de verificação esteja sendo executado. Ou seja, se muitos logs de transações forem gerados e a réplica simplesmente não tiver tempo para processá-la, em algum momento ela poderá cair e isso será um problema para nós.
E, é claro,
pg_wal_lsn_diff () para determinar o atraso e determinar onde o temos especificamente - na rede, em discos ou em processadores.
Opções de solução
Problemas de rede / armazenamentoTudo é bem simples aqui, mas do ponto de vista da configuração, isso geralmente não é resolvido. Você pode apertar algumas porcas, mas em geral existem 2 opções:
- Verificar carga de trabalho
Verifique quais pedidos estão em execução. Talvez seja iniciado algum tipo de migração que gere muitos logs de transações, ou possa ser transferência, exclusão ou inserção de dados.
Qualquer processo que gera logs de transação pode levar a um atraso na transação . Todos os dados no assistente são gerados o mais rápido possível, fizemos uma alteração nos dados, enviamos para a réplica e a réplica pode lidar ou falhar - isso não diz respeito ao assistente. Um atraso pode aparecer aqui e você precisa fazer algo com ele.
A opção mais estúpida - talvez tenhamos encontrado desempenho de ferro e você só precise alterá-lo. Pode ser discos antigos ou SSDs de baixa qualidade ou um plug-in no desempenho de um controlador RAID. Aqui não estamos mais explorando a base em si, mas verificando o desempenho de nossas glândulas.
Atrasos na recuperaçãoSe houver algum tipo de conflito de replicação devido a solicitações longas, resultando em um aumento no atraso na reprodução, a
primeira coisa que fazemos é
disparar solicitações longas que são executadas na réplica, porque atrasam a reprodução dos logs de transações.
Se consultas longas estiverem relacionadas à não otimização da própria consulta SQL (nós descobrimos isso usando EXPLAIN ANALYZE), basta abordar essa consulta de maneira diferente e reescrevê-la. Ou existe uma opção para configurar uma
réplica separada para relatórios de consultas . Se fizermos relatórios que funcionem por um longo período, eles precisam ser enviados para uma réplica separada.
Ainda há a opção de
apenas esperar . Se tivermos algum tipo de atraso no nível de alguns kilobytes ou mesmo dezenas de megabytes, mas achamos que isso é aceitável, esperamos apenas que a solicitação seja concluída e o atraso se resolva. Isso também é uma opção, e muitas vezes acontece que é aceitável.
WAL de alto volumeSe gerarmos um grande volume de log de transações, precisamos reduzir esse
volume por unidade de tempo , para fazer com que a réplica mastigue menos logs de transações.
Isso geralmente é feito
através da configuração . Solução parcial na configuração do parâmetro full_page_writes = off. Essa opção ativa / desativa a gravação de imagens completas das páginas alteradas no log de transações. Isso significa que, quando tivemos a operação de serviço de escrever um ponto de verificação (CHECKPOINT), na próxima vez que alterarmos algum bloco de dados na área de buffers compartilhados, a imagem completa desta página irá para o log de transações, e não apenas a alteração em si. Com todas as alterações subsequentes na mesma página, apenas as alterações serão registradas no log de transações. E assim por diante até o próximo ponto de verificação.
Após o ponto de verificação, registramos a imagem completa da página e isso afeta o volume do log de transações gravado. Se houver muitos pontos de verificação por unidade de tempo, digamos que 4 pontos de verificação sejam feitos por hora e haverá muitas imagens de página inteira, isso será um problema. Você pode desativar a gravação de imagens completas e isso afetará o volume do WAL. Mas, novamente, esta é uma meia medida.
Nota: A recomendação para desativar full_page_writes deve ser considerada com cuidado, pois o autor esqueceu de esclarecer durante o relatório que a desativação de um parâmetro pode, em algumas circunstâncias, ocorrer em situações de emergência (danos ao sistema de arquivos ou ao seu log, gravação parcial em blocos etc.) arquivos de banco de dados potencialmente corrompidos. Portanto, tenha cuidado, desabilitar o parâmetro pode aumentar o risco de corrupção de dados em situações de emergência.Outra metade da medida é
aumentar o intervalo entre os pontos de verificação . Por padrão, o ponto de verificação é feito a cada 5 minutos, e isso é bastante comum. Como regra, esse intervalo é aumentado para 30 a 60 minutos - esse é um período aceitável para o qual todas as páginas sujas conseguem se sincronizar com o disco.
Mas a solução principal é, obviamente,
examinar nossa carga de trabalho - que tipo de operações pesadas estão acontecendo lá, associadas à alteração dos dados e, talvez, tentar fazer essas alterações em lotes.
Suponha que tenhamos uma tabela, queremos excluir vários milhões de registros dela. A melhor opção é não excluir esses milhões de uma só vez com uma solicitação, mas dividi-los em pacotes de 100 a 200 mil, para que, primeiro, sejam gerados pequenos volumes de WAL, em segundo lugar, o vácuo tenha tempo para passar pelos dados excluídos e, portanto, o atraso não foi tão grande e crítico.
Inchaço pg_wal /
Agora, vamos falar sobre como você pode descobrir que o diretório pg_wal / está inchado.
Em teoria, o PostgreSQL sempre o mantém em um estado ideal para si mesmo no nível de certos arquivos de configuração e, como regra, não deve crescer acima de certos limites.
Existe um parâmetro max_wal_size, que determina o valor máximo. Além disso, existe o parâmetro wal_keep_segments - um número adicional de segmentos que o mestre armazena para a réplica, se a réplica estiver subitamente indisponível por um longo período de tempo.
Tendo calculado a soma de max_wal_size e wal_keep_segments, podemos estimar aproximadamente quanto espaço o diretório pg_wal / ocupará. Se crescer rapidamente e ocupar muito mais espaço do que o valor calculado, isso significa que há algum problema e você precisa fazer algo a respeito.
Como detectar tais problemas?
No sistema operacional Linux, existe o
comando du -csh . Podemos simplesmente monitorar o valor e monitorar quantos logs de transações temos lá; mantenha um rótulo calculado, quanto ele deve e quanto ele realmente recebe e, de alguma forma, responde a mudanças nos números.
Outro lugar que examinamos são as
visualizações pg_replication_slots e
pg_stat_archiver . Os motivos mais comuns pelos quais o pg_wal / ocupa muito espaço são slots de replicação esquecidos ou arquivamento interrompido. Outras razões também têm um lugar para estar, mas na minha prática eram muito raras.
E, é claro, sempre há erros nos logs do PostgreSQL associados ao comando archive. Infelizmente, não haverá outros motivos relacionados ao pg_wal / overflow. Podemos pegar apenas erros de arquivamento lá.
Opções para problemas:
CRUD pesado -
operações pesadas de atualização de dados - INSERT, DELETE, UPDATE pesado, associado à alteração de vários milhões de linhas. Se o PostgreSQL precisar fazer essa operação, é claro que uma grande quantidade de log de transações será gerada. Ele será armazenado em pg_wal /, e isso aumentará o espaço ocupado. Ou seja, como já disse anteriormente, é uma boa prática simplesmente dividi-los em pacotes e atualizar não toda a matriz, mas 100, 200, 300 mil cada.
Um slot de replicação esquecido ou não usado é outro problema comum. As pessoas costumam usar replicação lógica para algumas de suas tarefas: configuram barramentos que enviam dados para Kafka, enviam dados para um aplicativo de terceiros que decodifica a replicação lógica para outro formato e os processa de alguma forma.
A replicação lógica normalmente funciona através de slots . Ocorre que configuramos um slot de replicação, reproduzido com o aplicativo, percebemos que esse aplicativo não nos convém, desativamos o aplicativo, o excluímos
e os slots de replicação continuam ativos .
O PostgreSQL para cada slot de replicação salva segmentos do log de transações, caso um aplicativo ou réplica remota se conecte a esse slot novamente e, em seguida, o assistente pode enviar esses logs de transação.
Mas o tempo passa, ninguém se conecta ao slot, os logs de transações são acumulados e, em algum momento, ocupam 90% do espaço. Precisamos descobrir o que é, por que tanto espaço é ocupado. Como regra, esse slot esquecido e não utilizado precisa ser removido e o problema será resolvido. Mas mais sobre isso mais tarde.
Outra opção pode ser um
arquivo morto_command . Quando temos algum tipo de repositório de log de transações externo que mantemos para tarefas de recuperação de desastre, geralmente um comando de arquivamento é configurado, menos frequentemente o pg_receivexlog é configurado. O comando registrado no archive_command geralmente é um comando separado ou algum script que pega segmentos do log de transações de pg_wal / e o copia para o armazenamento do archive.
Ocorre que realizamos algum tipo de atualização de pacotes do sistema, por exemplo, no rsync, a versão foi alterada, os sinalizadores foram atualizados ou alterados, ou em algum outro comando usado no comando archive, o formato também foi alterado - e o script ou o próprio programa especificado em archive_command breaks. Consequentemente, os arquivos deixam de ser copiados.
Se o comando archive funcionou com uma saída diferente de 0, uma mensagem sobre isso será gravada no log e o segmento permanecerá no diretório pg_wal /.
Até descobrirmos que nossa equipe de arquivamento está quebrada, os segmentos se acumularão e o local também terminará em algum momento.
Conjunto de medidas de emergência (100% de espaço usado):1.
CRUD , — pg_terminate_backend().
- , , , .. , pg_wal/, .
2.
root — reserved space ratio (ext filesystems).
ext ext 5%. , , 5% — . , , 1% , tune2fs -m 1. PostgreSQL , . 100% .
3.
(LVM, ZFS,...).
LVM ZFS, LVM ZFS, , , . , .
4. —
, , HE pg_wal/ .
, , , . ! PostgreSQL , . , , , .
, pg_xlog/ pg_wal/ — log , , , , - — !
, 100% CPU, .
workload . , ? , - , -. : , tablespace, tablespace.
. , , , , , , .
— .checkpoints_segments/max_wal_size, wal_keep_segments . , , — 10-20 wal_keep_segments, max_wal_size. , . PostgreSQL pg_wal/ .
pg_replication_slots — . ,
, — . , , . .
WAL, ,
pg_stat_archiver , . ,
, , , .
checkpoint . , , . , PostgreSQL .
, checkpoint .
, , — . - , . , .
— PostgreSQL :
- User was holding shared bufer pin for too long.
- User query might have needed to see row versions that must be removed.
- User was holding a relation lock for too long.
- User was or might have been using table space that must be dropped.
- User transaction caused bufer deadlock with recovery.
- User was connected to a database that must be dropped.
2 — , , . : , , . ( 30 ),
PostgreSQL — .
. , , . - , timeout . — ALTER, , .
. , tablespace , tablespace. , , - — .
?
pg_stat_databases, pg_stat_databases_conflicts . , . , .
,
. , . , . , , , .
?
, — :
- max_standby_streaming_delay ( ). , . .
- hot_stadby_feedback ( /). , vacuum - , . bloat . , , , hot_stadby_feedback .
- DBA — . , . , , , - , .
- , , , , DBA — , , . max_standby_streaming_delay . , . , , , . — , .
Recovery process: 100% CPU usage
, , ,
100% . , , 100%. , pg_stat_replication, , replay, , .
:
- top — — 100% CPU usage recovery process;
- pg_stat_replication — , , .
, . , :
- perf top/record/report ( debug—);
- GDB;
- pg_waldump.
, , . workload,
. , , PostgreSQL shared buffers ( ). .
Solução
,
. - workload, - , - : « , - ».
pgsql-hackers ,
pgsql-bugs , , . , .
—
- , , .
. , , , .
. , , , , , — .
,
, — . , , , .
, ,
— , , .
Links úteis
, Highload++ Siberia , 25 26 . , , .
- MySQL ClickHouse.
- , Oracle.
- Nikolay Golov lhe dirá como implementar transações se o dinheiro estiver em um serviço, serviços em outro e cada serviço tiver sua própria base isolada.
- Yuri Nasretdinov explicará em detalhes por que a VK precisa do ClickHouse, a quantidade de dados armazenados e muito mais.