Olá Habr! Continuamos nossa série experimental de artigos, observando que você pode influenciar em tempo real o processo de criação de um jogo na UWP. Hoje, falaremos sobre a pergunta "Onde armazenar dados?", Que surge constantemente nas fileiras dos desenvolvedores. Junte-se a nós e compartilhe seus pensamentos nos comentários!
 Dou a palavra ao autor, Alexei Plotnikov .
Dou a palavra ao autor, Alexei Plotnikov .Em um artigo anterior, eu levantei a questão da sincronização conveniente dos dados do usuário entre os dispositivos e, em primeiro lugar, resolvi o problema com sua identificação; no entanto, essa é a menor fração do que resta a ser feito para alcançar os objetivos.
Uma questão muito mais complexa é a maneira e, mais importante, a localização dos dados do usuário e, através dos esforços da Microsoft, ao fazer uma pergunta, a primeira coisa que vem à mente é o
Microsoft Azure . A plataforma de nuvem do Azure inclui uma gama tão ampla de serviços que parece que não há tarefas que não possam ser resolvidas com sua ajuda. Seja verdade ou não, não posso julgar, mas minha tarefa está definitivamente dentro do poder desta plataforma. No entanto, as primeiras coisas primeiro.
Começamos pequenos - o que é uma nuvem? Pela primeira vez, ouvi falar sobre a nuvem em 2012 e, em seguida, a frase "computação em nuvem" era mais usada. A idéia inicial de tais cálculos era distribuir o trabalho de computação entre diferentes dispositivos que são remotos um do outro. Particularmente impressionante falou sobre o futuro, no qual até as tarefas mais difíceis serão processadas em alguns momentos, devido ao fato de que os cálculos serão distribuídos entre todos os computadores do mundo.
Na prática, tudo se resumia a data centers espalhados pelo mundo e fornecendo seu poder de computação aos consumidores, e o conceito inicial era apenas a distribuição entre as máquinas dentro do data center e entre os próprios data centers (geralmente na mesma região).
Com base no exposto, podemos assumir que, quando você ouve a palavra "nuvem", pode percebê-la como uma "hospedagem" mais familiar, com a única diferença de que o poder da nuvem pode ser expandido sem nenhum esforço adicional de sua parte.
A segunda pergunta que você pode ter é por que o Azure? “Como este é um artigo no blog da Microsoft, o autor falará apenas sobre os produtos deles” - você diz e estará errado. Os motivos para usar o Azure são muito mais comuns - como é um produto da Microsoft, ele tem o mais alto grau de integração possível com seus outros produtos, com a ajuda da qual meu aplicativo está sendo desenvolvido.
No entanto, observo que a empresa faz todos os esforços para tornar o uso do Azure atraente para desenvolvedores para Android ou iOS. Bem, o último problema mencionado, mas não menos importante, é o custo do uso da nuvem. Como sou titular de uma assinatura do BizSpark, recebi um empréstimo mensal por uma bolsa com juros mais do que cobrindo minhas necessidades de nuvem, embora as condições fornecidas gratuitamente também possam cobrir a maioria das necessidades de um desenvolvedor privado.
Agora vamos para a seleção direta de um mecanismo de sincronização e armazenamento de dados. Não vou ser astuto, como uma pessoa autodidata, muitas vezes tenho que lidar com tecnologias que não tenho idéia antes de conhecer a UWP, resolvi problemas semelhantes usando bancos de dados SQL.
No entanto, o UWP não possui meios para trabalhar com DBMSs SQL clássicos, mas o SQLite é oferecido como uma alternativa e, após iniciar seu estudo, descobri que esse banco de dados é interno, adequado para armazenamento e uso conveniente de dados locais, mas é completamente inadequado para a localização de dados. no armazenamento remoto. Já no processo de redação deste artigo, quando a tecnologia necessária foi selecionada, me deparei com uma das soluções do Azure no campo do desenvolvimento de aplicativos móveis, que permite sincronizar dados da tabela SQLite entre dispositivos, mas depois de pensar com cuidado, permaneci na escolha inicial.
A propósito, fazer a escolha inicial não foi difícil, pois a Microsoft educadamente levou uma lista de tecnologias que o desenvolvedor da UWP provavelmente teria que enfrentar. Nas versões mais recentes do Visual Studio, ao criar um novo projeto UWP, você verá uma página com recomendações para começar, onde um dos links diz "Adicionando um serviço recomendado". Ao clicar neste link, a guia "Conectar o serviço" é aberta e já vemos a opção "Armazenamento em nuvem com o serviço de armazenamento do Azure".
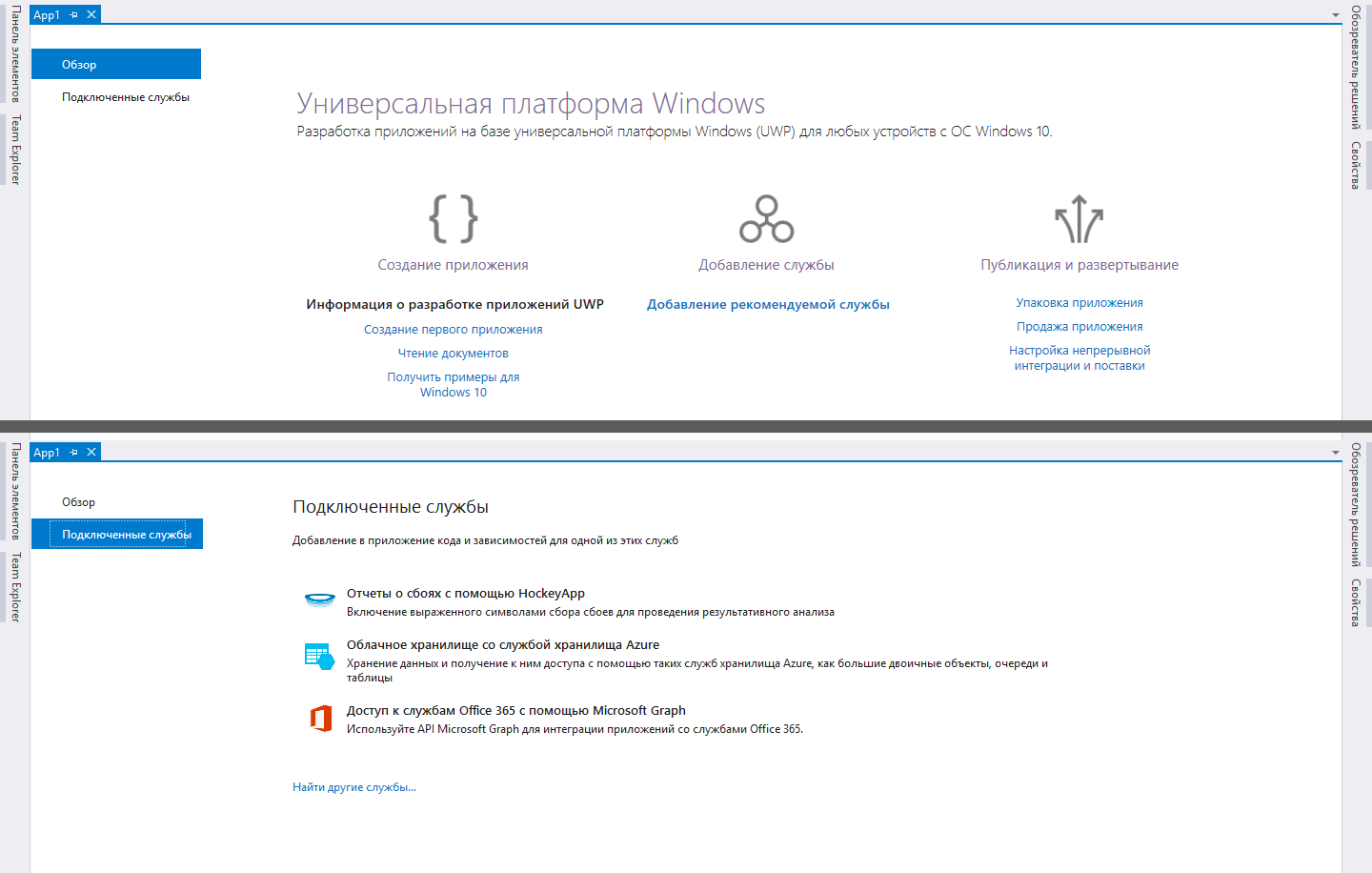
A intuição sugere que é exatamente isso que você precisa, por isso decidi me concentrar em um estudo aprofundado dessa questão, com vistas a uma maior utilização no projeto.
O armazenamento em nuvem é um conjunto de vários produtos para tarefas diferentes, que podem ser lidos mais
aqui , mas eu estava interessado principalmente no armazenamento de tabelas, que acabou sendo o banco de dados NoSQL.
O NoSQL é um banco de dados sem esquema, ou seja, aquele em que a tabela não precisa ser estruturada previamente. De fato, a tabela nesse caso é apenas parte do caminho para o que é chamado de seção, o que significa que uma única tabela pode conter linhas, por exemplo, com três e cinco colunas por vez. Para entender completamente os recursos do armazenamento da tabela, aconselho a ler atentamente o
manual , mas considerarei esse tópico do meu ponto de vista mundano, porque no final o material é destinado a iniciantes, quem eu sou neste tópico.
Para começar, vamos descobrir como criar uma tabela NoSQL:1. Registre uma conta
gratuita do Azure. Se você tiver uma assinatura do MSDN ou BizSpark e já estiver ativada no Azure, poderá pular esta etapa. Uma conta gratuita oferece um empréstimo de US $ 200 para o primeiro mês e, em seguida, acesso gratuito a uma certa quantidade de recursos da maioria dos serviços do Azure. Traduzido para um idioma compreensível, tudo é feito de maneira que você não precise pagar até que seu produto receba o suficiente para cobrir as despesas, sem mencionar o uso do Azure para auto-educação.
Mas mesmo se você ultrapassar o limite livre, os preços de um armazenamento de tabela são muito mais fiéis do que para uma quantidade semelhante de bancos de dados SQL. Por exemplo, no momento da redação deste artigo, criei duas tabelas, até agora com apenas uma entrada. Durante 18 dias do período coberto pelo relatório, eu me virei para ela em média 20 a 30 vezes por dia e dois copeques foram baixados da conta de crédito desse período. Ao escalonar esses custos para o volume planejado, percebi que eles são mais do que cobertos pela receita potencial do aplicativo.
2. Agora que você tem uma conta no Azure, continuamos a criar uma conta de armazenamento.
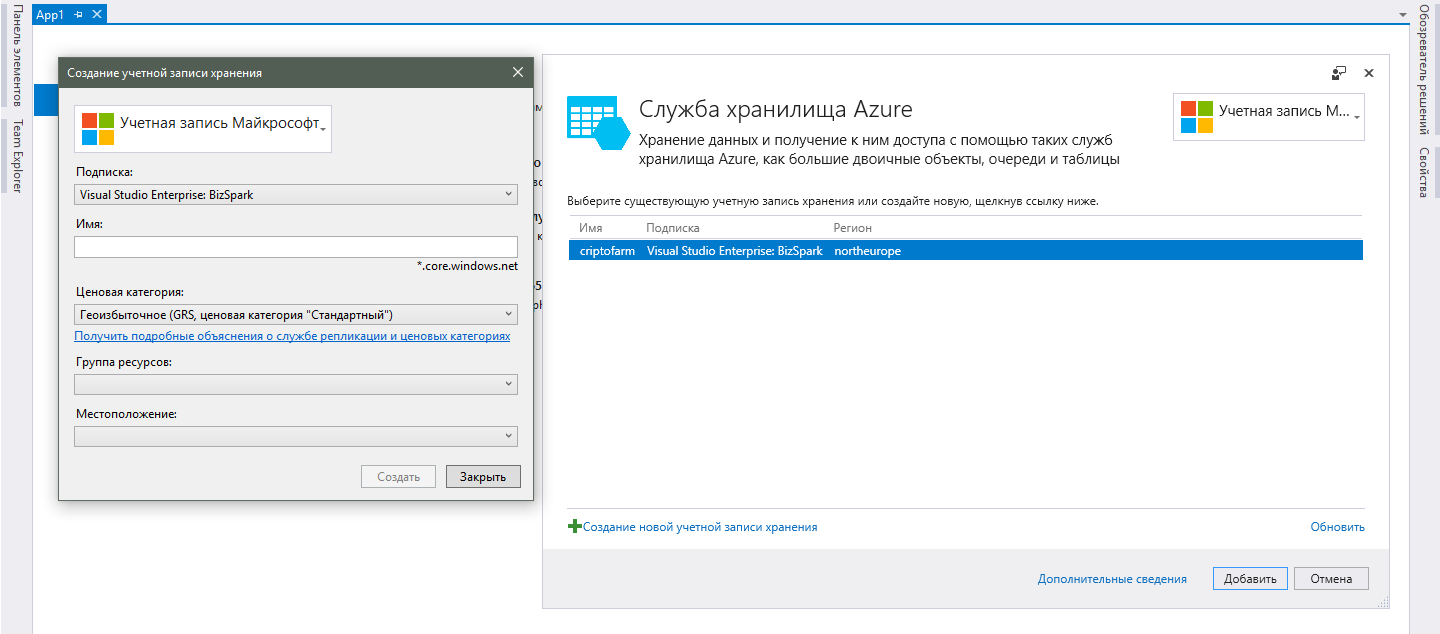
Você pode fazer isso tudo na mesma página de Conexão de Serviços do Visual Studio, que descrevi acima. Se você fechar esta página repentinamente, poderá abri-la clicando duas vezes em “Serviços Conectados” no Gerenciador de Soluções. Após selecionar o serviço necessário, uma janela com as contas de armazenamento disponíveis será aberta e, para adicionar uma nova, clique no botão correspondente.
Na nova janela, você precisará executar as seguintes etapas:- Para começar, você precisará fazer login com sua conta da Microsoft. Você precisa usar a conta à qual suas assinaturas estão vinculadas ou uma conta gratuita do Azure.
- Depois de fazer login na sua conta, sua assinatura (a) aparecerá no campo "Assinatura". Tudo é simples com a escolha, então os comentários são supérfluos.
- No campo "Nome", especifique o nome desejado do serviço de armazenamento. Como esse também é o nome de domínio do serviço, ele deve ser exclusivo em todas as contas disponíveis no Azure e não apenas na sua.
- O campo "Categoria de preço" exigirá que você entenda as diferenças entre uma plataforma em nuvem e a hospedagem convencional, pois clicando no link abaixo do campo, você poderá ver uma lista de preços, mas não uma explicação inteligível, que oferece cada opção. Obviamente, na natureza dos sitelinks, você pode encontrar informações abrangentes sobre todas essas abreviações, como GRS e LRS, mas isso é supérfluo para o desenvolvedor médio. É suficiente entender que, quanto mais cara a tarifa, mais centros de dados estarão envolvidos no processamento e armazenamento dos seus dados e maior a probabilidade de sua segurança. Para um projeto pequeno, a menor taxa de LRS é boa.
- Um "grupo de recursos" é uma combinação de vários serviços do Azure para um único gerenciamento. No nosso caso, crie um novo, atribuindo qualquer nome amigável e siga em frente.
- A última coisa a escolher é o "Local" para o seu serviço. Por localização, entende-se a localização real dos data centers que serão responsáveis por trabalhar com nossos dados. Observe que falo no plural, pois em uma região podem existir vários data centers e o trabalho pode ser distribuído entre eles (caso você escolha uma categoria de preço de consultoria). Escolha a que mais se aproxima da sua base de usuários principal. No entanto, se você planeja crescer na escala do mundo inteiro e precisa de uma resposta máxima em qualquer lugar do mundo, ninguém o incomoda em cada versão regional do aplicativo para criar uma conta de armazenamento separada e implementar a sincronização de dados entre eles. É um alto nível de extensibilidade que é a principal vantagem da nuvem.
3. Após criar a conta de armazenamento, ela será adicionada à lista e você poderá continuar clicando no botão "Adicionar". O resultado dessa ação será adicionar um pacote NuGet para trabalhar com o Azure ao projeto e salvar a cadeia de conexão no arquivo app.config do projeto.
Infelizmente, é impossível trabalhar com valores desse arquivo no UWP (ou possivelmente com muletas terríveis); portanto, basta copiar a seqüência de conexão para o serviço de armazenamento de lá para um local conveniente no projeto e prosseguir para a próxima etapa.
4. Agora resta criar uma tabela e começar a trabalhar com ela. E aqui começa o trabalho individual, dependendo diretamente das tarefas.
O fato é que, antes de começar a criar tabelas, você deve pensar cuidadosamente na arquitetura para armazenar seus dados. Trabalhar com o armazenamento da tabela é tão conveniente que criar uma nova tabela diretamente do código é uma questão de apenas algumas linhas, e com essa conveniência, existe um desejo natural de alocar uma tabela separada para cada usuário, porque no final a tarefa é sincronizar dados entre seus dispositivos. No entanto, ao trabalhar com uma tecnologia desconhecida, você não deve tomar decisões precipitadas e precisa pesar cuidadosamente os prós e contras. Um
artigo especial
no manual pode ajudar a tomar a decisão certa, mas prepare-se para relê-lo várias vezes, pois é muito difícil aprender todos os dados imediatamente, especialmente levando em consideração a massa de novos termos.
Continuarei a história, levando em consideração o fato de você ainda ler o manual e entender alguns dos recursos do trabalho com armazenamento de tabelas. Por exemplo, percebi que conceitualmente uma tabela não é um tipo de unidade isolada e é um local para um agrupamento lógico de registros. Isso é fácil de entender se você apresentar a tabela como uma pasta na qual você armazena arquivos de dados. Uma pasta por si só não ocupa espaço e não é parte integrante dos arquivos, mas apenas define uma parte do caminho para arquivos lógicos, mas não necessários, a serem salvos nessa pasta.
A conclusão disso é bastante simples - ninguém se preocupa em armazenar as configurações de todos os usuários em uma tabela, o principal é que o par de valores nas colunas PartitionKey e RowKey são únicos dentro da tabela. Isso é implementado novamente em meu projeto, já que o ID do usuário atuará como PartitionKey e, por exemplo, a string "UserName" como RowKey, que nos permitirá determinar o registro exclusivo no qual o nome do usuário está armazenado. Mas, como eu disse acima, precisamos pesar todos os prós e contras, então vamos pesar:
- "Para" uma tabela separada para os dados de cada usuário é a conveniência de perceber a estrutura de dados. Se considerarmos a tabela como uma pasta com arquivos, é lógico que todos os arquivos de um usuário estejam na mesma pasta e é mais comum trabalhar com essa arquitetura.
- Todos os outros fatores são "contra" uma tabela separada. Dados do usuário em uma tabela separada - isso é convenientemente preciso até que o número dessas tabelas esteja na casa dos milhares. Como a conta de armazenamento está em um nível superior acima da tabela, nenhum outro agrupamento é fornecido para elas.
Dada a base de usuários em potencial, corremos o risco de se afogar em milhares de tabelas individuais, perdendo as que têm qualquer valor de prioridade. Ao mesmo tempo, armazenar as configurações de todos os usuários em uma tabela simplifica a administração e trabalha com dados para coletar informações estatísticas ou implementar funções sociais.
Além disso, o baixo custo do uso do armazenamento de tabelas permite duplicar todos os dados em tabelas separadas, de acordo com a lógica necessária. Em particular, pretendo criar uma tabela adicional com o nome de usuário, um link para o avatar e uma indicação de pertencer ao país, que será usado para tabelas de classificação ou outras funções sociais que podem ser adicionadas ao aplicativo.
Então, quando você descobriu a estrutura de armazenamento de dados, vamos finalmente adicionar uma nova tabela. Como nos recusamos a criá-lo no nível do código, restam duas opções: através do portal da Web do Azure ou usando a ferramenta especial do Microsoft Azure Storage Explorer, que pode ser baixada em storageexplorer.com. Nos dois casos, é necessário selecionar a conta de armazenamento desejada e, na seção "Serviço de tabelas / tabelas", selecione "+ Tabela / Criar tabela". Na caixa de diálogo exibida, digite o nome desejado e confirme as alterações.
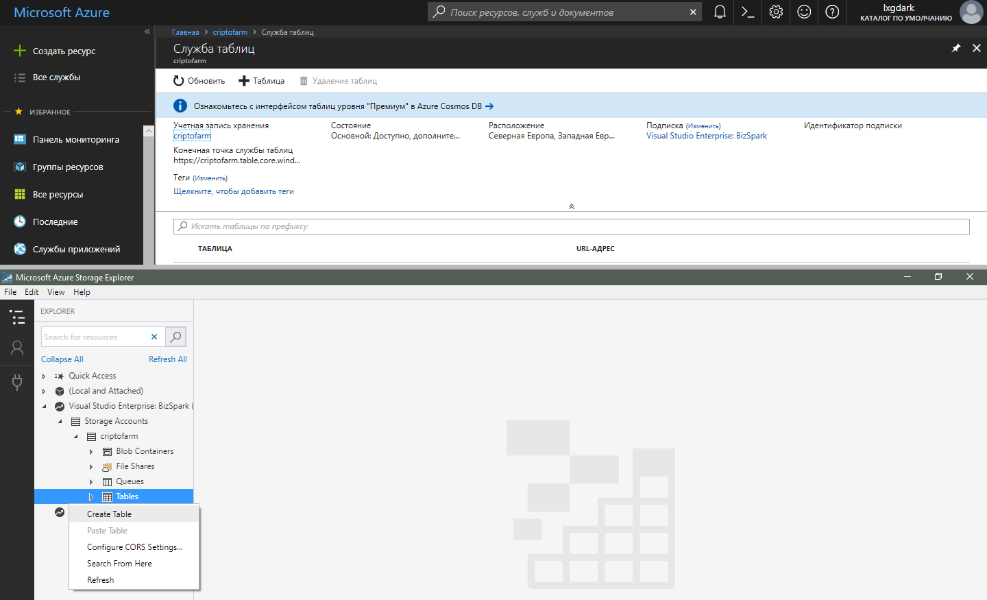
Depois disso, você pode trabalhar com a nova tabela do código sem problemas.
As principais operações que executarei com a tabela são a inserção e extração de linhas, chamadas de "entidades" na terminologia de armazenamento da tabela. Esse termo é mais fácil de entender quando você percebe que, para inserir e recuperar uma entidade, será necessário mapear uma classe herdada de TableEntity de Microsoft.WindowsAzure.Storage.Table. A classe herdeiro já conterá alguns campos obrigatórios, como, por exemplo, PartitionKey (nome da seção) e RowKey (nome da linha), e os campos que implementamos independentemente serão colunas na linha (propriedades da entidade).
Considere um exemplo de tabela na qual uma lista de todos os jogadores com nome, avatar e afiliação no país será armazenada.
: Imports Microsoft.WindowsAzure.Storage Imports Microsoft.WindowsAzure.Storage.Table
Decidi colocar os métodos para trabalhar com a tabela em uma classe separada para facilitar o trabalho em diferentes pontos do aplicativo. Crie-o e adicione imediatamente as constantes conhecidas anteriormente:
Public Class AzureWorker Private Const AzureStorageConnectionString As String = " , app.config" Private Const GamerListTableNameString As String = "GamerList" ' … End Class
Agora precisamos criar uma classe que mapearemos para a entidade (linha) dentro da tabela:
Private Class GamerListClodTableDataClass Inherits TableEntity Public Const RowKeyValue As String = "UserID" Public Sub New () RowKey = RowKeyValue End Sub Public Property UserName As String = "" Public Property UserountryID As String = "" Public Property UserAvatar As String = "" End Class
A classe a ser mapeada deve ser herdada de TableEntity e ter campos para os dados que planejamos colocar na tabela. Observe que a definição de valores para um RowKey ou PartitionKey no nível da classe não é necessária, mas no meu caso, o RowKey é definido porque é imutável, independentemente de outras entradas.
Mas, como nesse estágio você provavelmente não entendeu completamente a essência de trabalhar com o armazenamento da tabela, explicarei a lógica estabelecida nesse estágio. A maneira mais rápida de trabalhar com uma tabela é consultar a entidade pelo nome da string e do nome da seção, portanto, é necessário conhecer esses dados com antecedência. Além disso, a combinação de PartitionKey e RowKey deve ser exclusiva dentro da tabela, o que significa que é lógico escrever um ID de usuário exclusivo em uma dessas chaves e atribuir à segunda chave qualquer nome que sempre saberemos. Isso é exatamente o que é feito na classe GamerListClodTableDataClass.
O último estágio preparatório antes das consultas diretas à tabela é a criação de seu objeto em uma função separada:
Private Shared Function GetCloudTable(tableName As String) As CloudTable Dim storageAccount As CloudStorageAccount = CloudStorageAccount.Parse(AzureStorageConnectionString) Dim tableClient As CloudTableClient = storageAccount.CreateCloudTableClient() Dim table As CloudTable = tableClient.GetTableReference(tableName) Return table End Function
Isso é feito para não duplicar o código toda vez que queremos ler ou gravar dados na tabela. Observe que este código não faz solicitações diretas à nuvem e será executado sem problemas quando não houver conexão. Tudo o que ele faz é criar passo a passo um objeto de tabela a partir dos dados existentes, como a cadeia de conexão de armazenamento e o nome da tabela.
Por fim, vamos trabalhar diretamente com a tabela e começar salvando os dados atuais do usuário:
Public Shared Async Function SavedOrUpdateUserData(u As UserManager) As Task(Of Boolean) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim UserDataClodTableData As New GamerListClodTableDataClass With {.PartitionKey = u.UserId, .UserName = u.UserName.Trim, .UserountryID = u.UserountryID, .UserAvatar = "https://apis.live.net/v5.0/" & u.UserId & "/picture"} Dim insertOperation As TableOperation = TableOperation.InsertOrReplace(UserDataClodTableData) Await table.ExecuteAsync(insertOperation) Return True End If Catch ex As Exception End Try Return False End Function
A solicitação é feita como uma função assíncrona para que o código de chamada possa obter o resultado da execução (Verdadeiro em caso de sucesso e Falso em caso de falha). Além disso, um parâmetro do tipo UserManager é passado para a função, que é uma referência à classe com dados do usuário. Criamos essa classe em um artigo anterior, com a única diferença: nesta versão, existe um campo UserountryID que armazena dados sobre o país do usuário.
Para consultas à tabela, primeiro você precisa criar seu objeto usando a cadeia de conexão ao repositório e o nome da tabela (colocamos esse processo em uma função separada anteriormente). Em seguida, verifique a existência da tabela e, embora tenhamos certeza de que temos uma tabela com esse nome, pode ocorrer um erro, por exemplo, devido à falta de conectividade de rede ou devido a uma falha na nuvem (é por isso que esse código é colocado no botão Try / Catch). Em seguida, antes de gravar na tabela, você precisa criar uma instância da classe UserDataClodTableData e atribuir o valor necessário aos seus campos e só então criar a operação InsertOrReplace. Como você pode imaginar, a partir do nome da operação, ela inserirá uma nova linha na tabela se as linhas com o mesmo par de PartitionKey e RowKey não existirem na tabela e substituirá os dados, se essa linha já existir. Bem, a equipe final do ExecuteAsync, de fato, executará a ação planejada no lado do armazenamento da tabela.
Ler dados de uma tabela é tão fácil quanto escrevê-los. Vamos, por exemplo, solicitar um nome de usuário:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim retrieveOperation As TableOperation = TableOperation.Retrieve(Of GamerListClodTableDataClass)(id, GamerListClodTableDataClass.RowKeyValue) Dim retrievedResult As TableResult = Await table.ExecuteAsync(retrieveOperation) If retrievedResult.Result IsNot Nothing Then Return CType(retrievedResult.Result, GamerListClodTableDataClass).UserName End If End If Catch ex As Exception End Try Return "" End Function
Esse código quase não difere do anterior e também começa criando um objeto de tabela e verificando sua existência. Além disso, como na gravação, criamos uma operação, mas desta vez uma operação de extração, que requer a indicação de PartitionKey e RowKey. Depois disso, extraímos o resultado usando ExecuteAsync e trabalhamos com o objeto resultante do tipo TableResult, que na verdade se resume em converter a propriedade Result no tipo de classe que está sendo mapeada e extrair o nome do usuário.
O trabalho com uma tabela não se limita às operações de leitura e gravação e suporta muitos scripts diferentes. Por exemplo, você pode criar uma consulta que extrairá todas as entidades com o PartitionKey especificado ou todas as entidades que possuem o campo especificado, mas é importante lembrar a velocidade de tais operações, bem como a quantidade de dados que serão transmitidos pela rede.
O exemplo acima é o mais ideal do ponto de vista da velocidade da consulta, pois o sistema de endereçamento provavelmente encontrará uma entidade no caminho "nome do armazenamento \ nome da tabela \ PartitionKey + RowKey", no entanto, para obter apenas um nome, carregamos toda a entidade como um todo, o que não é benéfico sobre a quantidade de dados transferidos.
A seguir, um código de função modificado, levando em consideração a otimização máxima da consulta:
Public Shared Async Function GetUserName(id As String) As Task(Of String) Dim table As CloudTable = GetCloudTable(GamerListTableNameString) Try If Await table.ExistsAsync Then Dim projectionQuery As TableQuery(Of DynamicTableEntity) = New TableQuery(Of DynamicTableEntity)().Where(TableQuery.CombineFilters(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, id), "and", TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, GamerListClodTableDataClass.RowKeyValue))).Select({"UserName"}) Dim resolver As EntityResolver(Of String) = Function(pk, rk, ts, props, etag) Return props("UserName").StringValue End Function Dim result As TableQuerySegment(Of String) = Await table.ExecuteQuerySegmentedAsync(projectionQuery, resolver, Nothing) If result.Count > 0 Then Return result(0) End If End If Catch ex As Exception End Try Return "" End Function
Em vez de criar um objeto de operação, neste código, criamos um objeto de solicitação que contém vários métodos para determinar o que precisa ser obtido como resultado. O método Where cria um filtro que indica a necessidade de retornar apenas as linhas para as quais PartitionKey e RowKey são iguais aos valores especificados e o próximo Select indica que apenas a coluna UserName precisa ser selecionada.
Com essa consulta, não faz sentido comparar o resultado com qualquer classe, portanto, o IDictionary é usado como valor de retorno, onde a chave é o nome da coluna e o valor é o seu conteúdo. Como a função ExecuteQuerySegmentedAsync não sabe qual resultado de sua execução será obtido, é possível (e neste caso necessário) passar um delegado EntityResolver, que se refere a uma função que utiliza o valor desejado do dicionário. O resultado de tudo isso se torna TableQuerySegment no primeiro índice do qual o nome do usuário solicitado está armazenado.
Em geral, o uso de consultas em vez da operação básica de extração permite expandir significativamente as possibilidades de trabalhar com uma tabela, mas tenha cuidado, porque, diferentemente do SQL clássico, aqui a velocidade de processamento da consulta depende diretamente de seus parâmetros. Ninguém o incomoda para executar uma consulta para recuperar todos os registros de usuários cujos nomes sejam iguais ao nome especificado, mas essa consulta será mais longa que sua contraparte no SQL. Para aprender isso, mais uma vez eu o
indico ao guia de design de tabelas que mencionei acima e também recomendo que você estude o
artigo , que fornece exemplos de como trabalhar com o armazenamento de tabelas.
Importante! Os artigos de link usam código para aplicativos clássicos do .NET e são diferentes da implementação da UWP. Felizmente, essa diferença não é significativa e os análogos são intuitivos (na maioria das vezes as diferenças estão no prefixo Async).Em conclusão, vou compartilhar os resultados do uso do armazenamento do Azure no meu projeto no momento. No primeiro início, depois de receber o ID do usuário e fazer o download dos dados do Live ID, sugiro que ele escolha um apelido (apelido), caso o nome armazenado no perfil não seja adequado a ele. Em seguida, o apelido inserido é salvo na classe UserManager, em vez da classe padrão, e todos esses dados são salvos na tabela GamerList. No próximo início, o ID do usuário é recebido em segundo plano e um alias é solicitado no repositório. Como resultado, o usuário vê seu apelido no jogo, e não o nome do perfil padrão.
Também no futuro, uma tabela com uma lista de usuários será útil para inserir funções sociais no jogo e, agora, criei pelo menos um aplicativo para esses dados. Na implementação desta tarefa, ferramentas do Azure, como Armazenamento de Filas e Funções do Azure, irão me ajudar novamente, mas falarei sobre isso em um dos seguintes artigos.