Dizer o que são caches, o que é o cache de resultados, como é feito no Oracle e em outros bancos de dados não é muito interessante e bonito. Mas tudo assume cores completamente diferentes quando se trata de exemplos específicos.
Alexander Tokarev (
shtock ) construiu seu relatório no Highload ++ 2017 com base em casos. E foi precisamente com base nos casos que ele contou quando um cache caseiro pode ser conveniente, qual é a dor do cache de resultados do servidor e como substituí-lo por um do lado do cliente e, em geral, ele trouxe várias dicas úteis para configurar o cache de resultados no Oracle.
Sobre o palestrante: Alexander Tokarev trabalha na DataArt e lida com questões relacionadas aos bancos de dados, tanto em termos de construção de sistemas a partir do zero quanto na otimização dos existentes.
Vamos começar com algumas perguntas retóricas. Você já trabalhou com o Oracle Result Cache? Você acredita que o Oracle é um banco de dados adequado para todas as ocasiões? De acordo com a experiência de Alexander, a maioria das pessoas responde negativamente à última pergunta:
cem sonhadores têm um sonhador . Mas, graças à sua fé, o progresso está se movendo.
A propósito, a Oracle já possui 14 bancos de dados - até agora 14 - o que acontecerá no futuro é desconhecido.
Como já mencionado, todos os problemas e soluções serão ilustrados com casos específicos. Esses serão dois casos de projetos DataArt e um exemplo de terceiros.
Caches de banco de dados
Para começar, quais caches estão nos bancos de dados. Tudo está claro aqui:
- Cache de buffer - cache de dados - cache para páginas / blocos de dados;
- Cache de instruções - cache de instruções e seus planos - plano de cache de consultas;
- Cache de resultados - cache dos resultados da linha - linhas de consultas;
- Cache do SO - cache do sistema operacional.
Além disso, o cache de resultados, em geral, é usado apenas no Oracle. Ele já esteve no MySQL, mas foi heroicamente cortado. No PostgreSQL, ele também não existe, está presente de uma forma ou de outra apenas no produto pgpool de terceiros.
Caso 1. Cofre do varejista
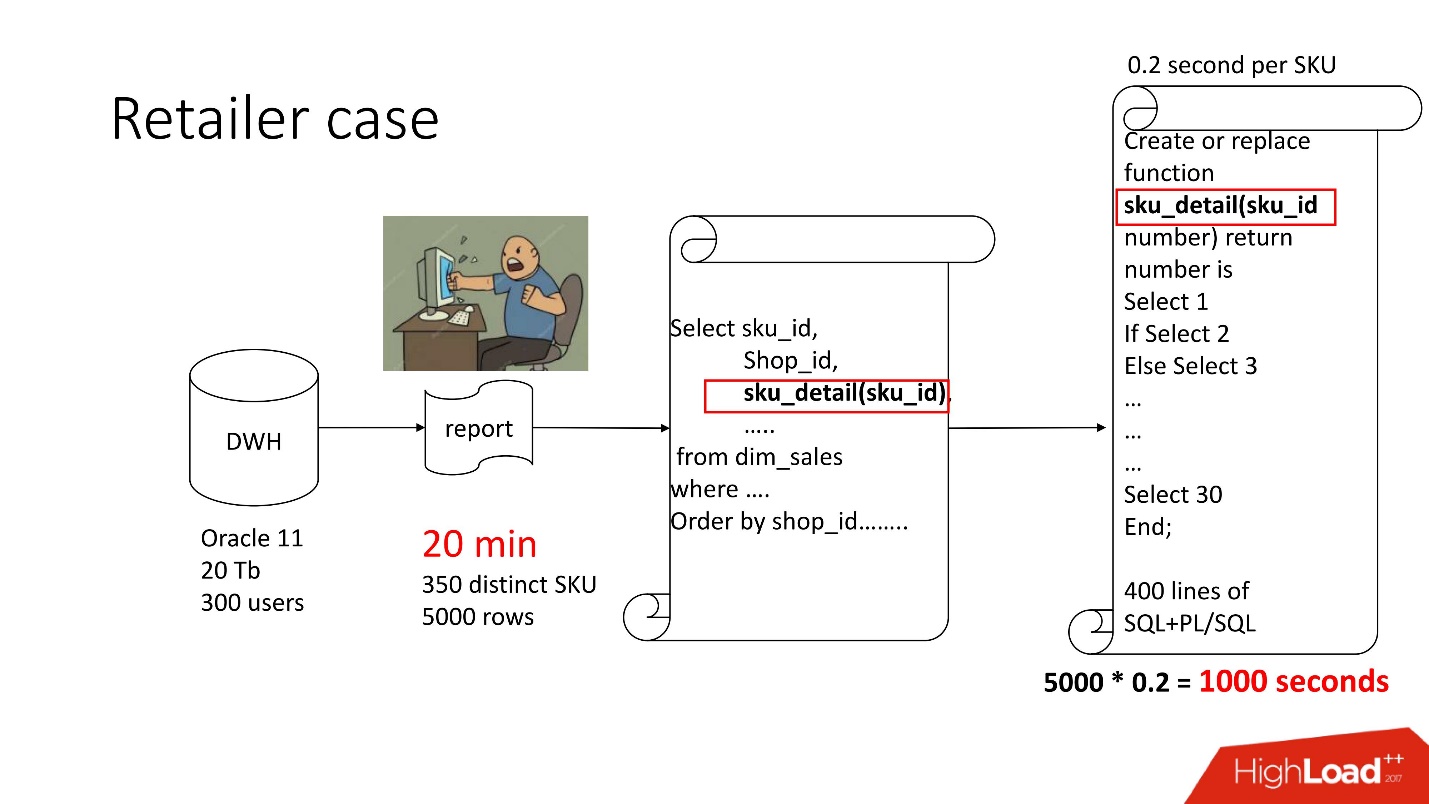
Acima está o diagrama do produto que acompanhamos - o repositório (Oracle 11, 20 TB, 300 usuários) e contém algum tipo de relatório sombrio, no qual havia 350 produtos exclusivos por 5000 linhas de dados. Levou cerca de 20 minutos e os usuários ficaram tristes.
A apresentação deste relatório, como todo mundo, está disponível no site da conferência Highload ++.
Este relatório possui SELECT, JOINs e uma função. Uma função como uma função, tudo ficaria bem, apenas calcula um parâmetro misterioso chamado “valor do preço de transferência”, funciona por 0,2 s - parece nada, mas é chamado quantas vezes houver linhas na tabela. Essa função possui 400 linhas de SQL + PL / SQL, pois o produto é compatível, é assustador alterá-lo.
Pelo mesmo motivo, result_cache não pôde ser usado.
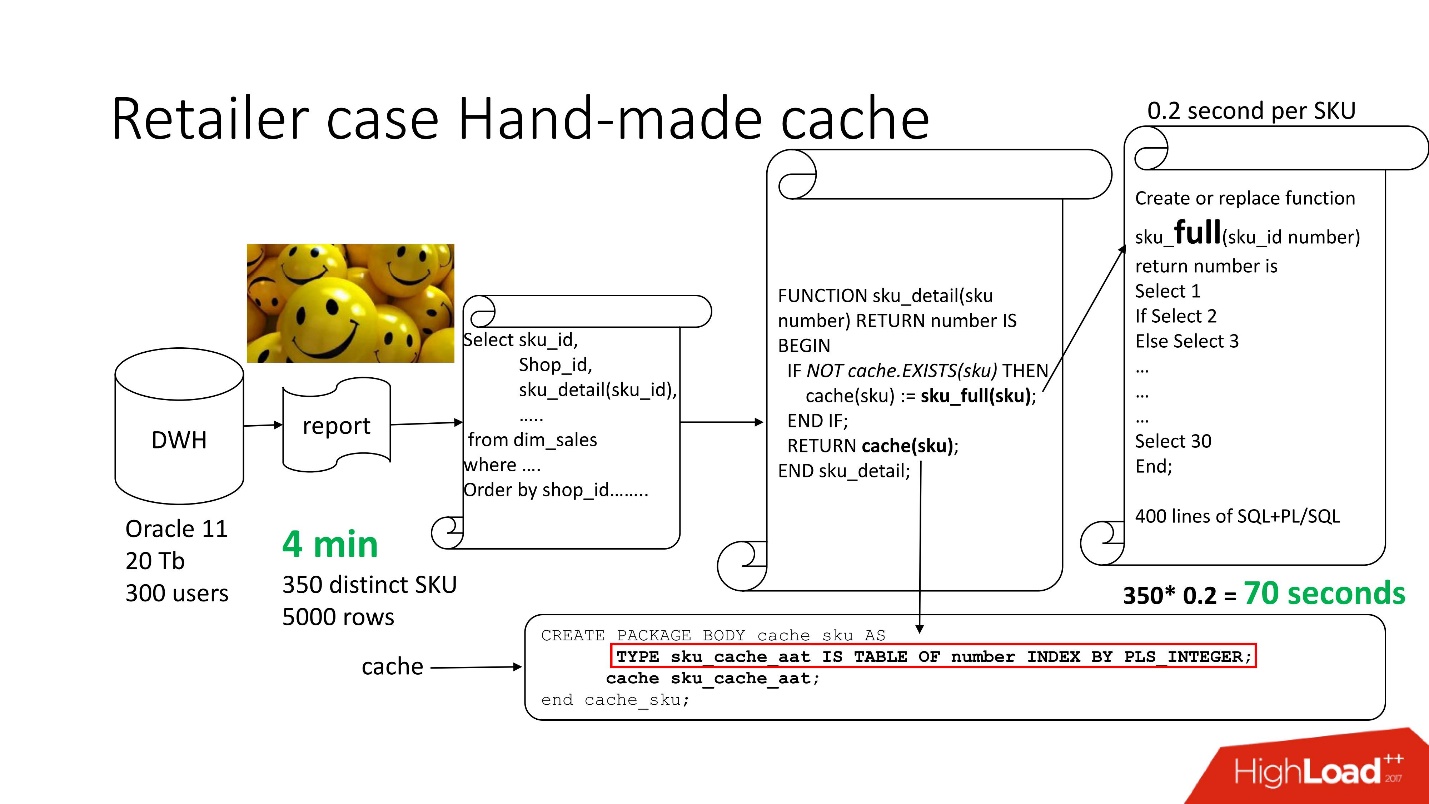
Para resolver o problema, usamos a
abordagem padrão
com o armazenamento em cache feito à mão : deixamos os 3 primeiros blocos do circuito, como era, simplesmente renomeie nossa função sku_detail () para sku_full () e declare uma matriz associativa, onde respectivamente:
- chaves são nossos SKUs (itens básicos),
- Os valores são o preço de conversão de transferência calculado.
Tornamos a função de cache (sku) óbvia: se não houver esse ID em nossa matriz associativa, nossa função é iniciada, o resultado é armazenado em cache, salvo e retornado. Por conseguinte, se esse ID for, tudo isso não acontece. De fato, temos
cache sob demanda .
Assim, reduzimos o número de chamadas de função à quantidade realmente necessária.
O tempo de processamento do relatório diminuiu para 4 minutos , todos os usuários se sentiram bem.
Memória cache feita à mão
As desvantagens e vantagens deste sistema são evidentes nesta grande imagem inteligente, que abordaremos muito - essa é a arquitetura da memória.
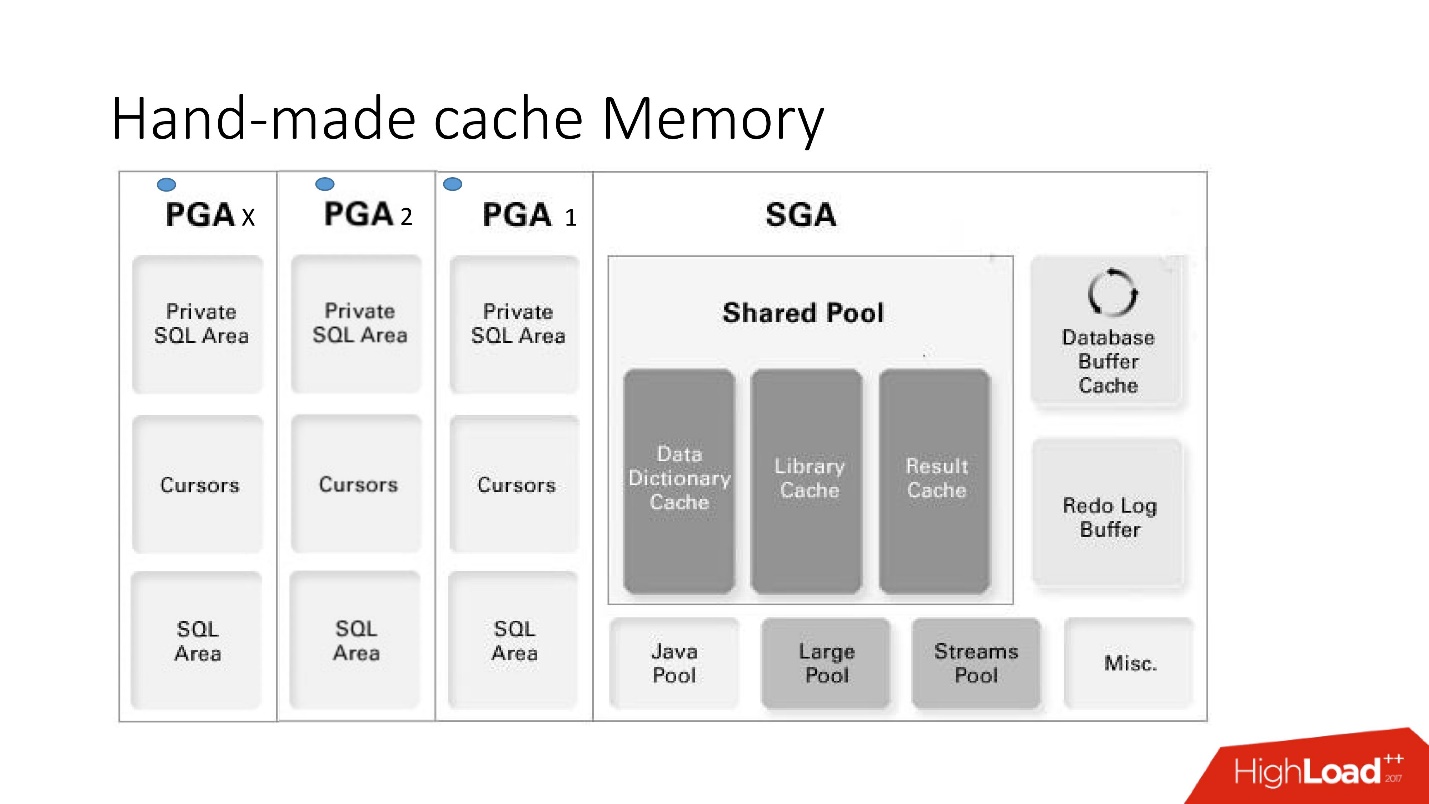
É importante entender em qual área de memória as coleções estão localizadas. Eles são colocados em uma área de memória chamada PGA.
A área global do programa é instanciada em todas as conexões com o banco de dados. Isso é o que determina as vantagens e desvantagens, uma vez que mais conexões - mais memória e
mais memória, servidores e administradores
caros .

- Prós: tudo funciona muito rápido, muito fácil de fazer, sem configuração necessária, sem problemas com o envolvimento entre processos.
- Os contras são compreensíveis: se a lógica armazenada é proibida no projeto, eles não podem ser usados, não há mecanismo para invalidação automática e, como a memória no cache é alocada em uma sessão do banco de dados, não em uma instância, seu consumo é exagerado . Além disso, no caso do caso de uso do conjunto de conexões, lembre-se de liberar os caches se houver um cache diferente para cada sessão.
Existem outras opções para caches feitos à mão com base em visualizações materializadas, tabelas temporárias, mas a partir delas existe uma grande carga no sistema de entrada e saída, portanto, aqui não as consideramos. Eles são mais aplicáveis a outros bancos de dados nos quais esses problemas geralmente são resolvidos armazenando o procedimento armazenado em alguma tabela intermediária e retirando os dados dele antes de acessar uma solicitação pesada. E somente se não for encontrado o necessário, a solicitação inicial será chamada.

A ilustração acima é uma ilustração dessa abordagem para o problema de armazenamento em cache para obter uma lista de produtos relacionados no MsSQL. Em geral, a abordagem é relativamente semelhante, mas não funciona na memória do banco de dados, tanto em termos de obtenção de dados quanto de preenchimento primário, por isso
pode ser mais lenta .
Em geral, result_cache caseiro é usado ativamente, mas result_cache no banco de dados é uma abordagem diferente para a implementação desta tarefa. Ele e como não funcionou rapidamente ganharemos mais adiante.
Caso 2. Processamento da documentação financeira
Então, nosso segundo caso.
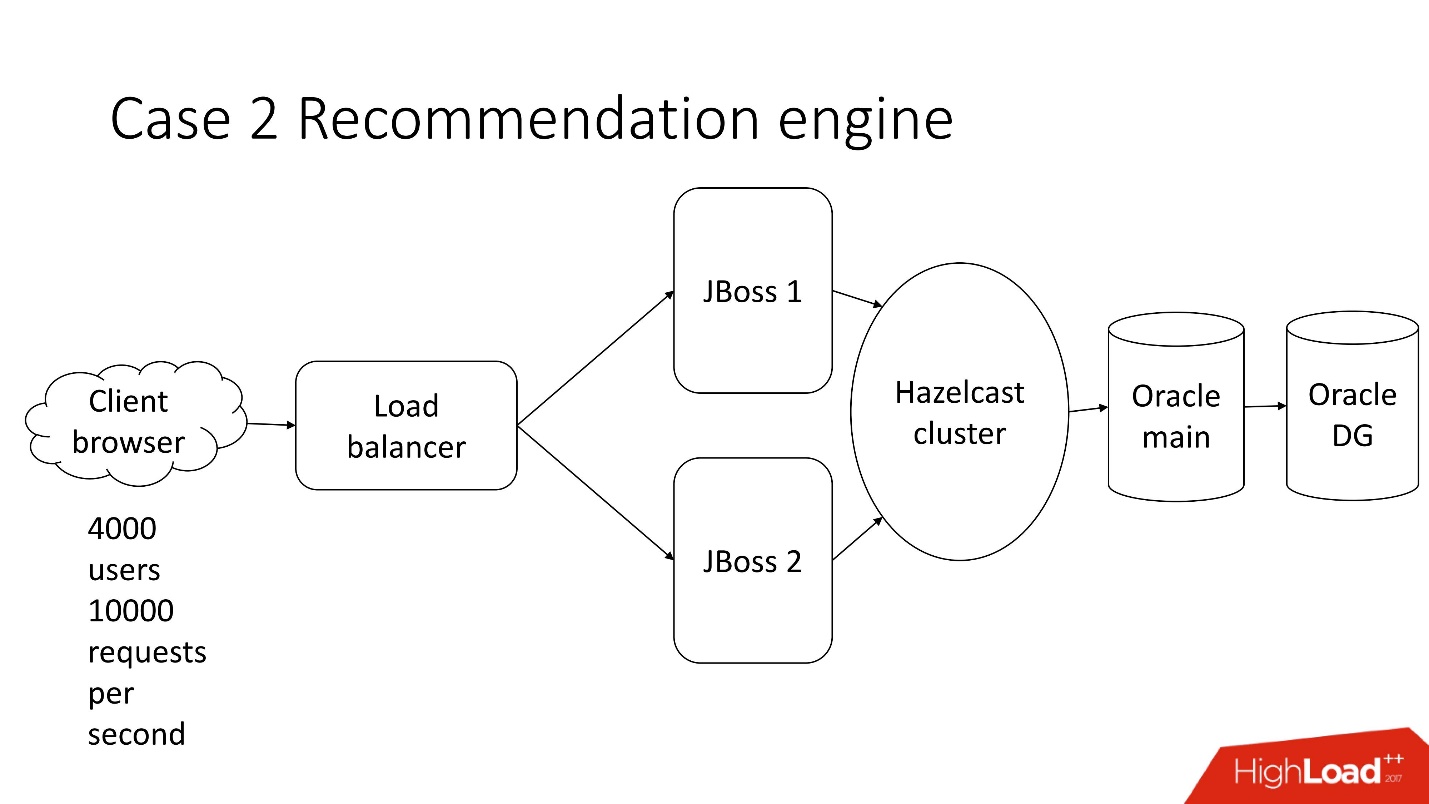
Este é um sistema de processamento de documentação financeira semi-automatizado - uma empresa sombria com uma arquitetura clássica, que inclui:
- thin client;
- 4.000 usuários que vivem em diferentes partes do mundo;
- balanceador;
- 2 JBoss para calcular a lógica de negócios;
- cluster na memória;
- núcleo Oracle;
- Backup Oracle
Uma das muitas tarefas deste sistema é o
cálculo de recomendações .

Existem documentos, para cada indicador que não é reconhecido automaticamente pelo sistema, um conjunto de indicadores é oferecido a partir de documentos de clientes anteriores, de um setor semelhante ou de uma lucratividade semelhante, enquanto o indicador é comparado com o valor reconhecido para não oferecer muito. O que é importante, os
documentos são multilíngues .
O usuário seleciona o valor desejado e repete a operação para cada linha vazia.
Simplificada, esta tarefa consiste no seguinte: os documentos chegam na forma de pares de valores-chave de diferentes sistemas de reconhecimento e os parâmetros são reconhecidos em algum lugar, mas não em algum lugar. É necessário garantir que, no final, os usuários processem os documentos e todos os valores sejam reconhecidos. A recomendação visa precisamente a simplificação desta tarefa e leva em consideração:
- Multilinguismo - cerca de 30 idiomas. Cada idioma tem seus próprios termos, sinônimos e outros recursos.
- Os dados anteriores deste cliente, ou, na sua ausência, os dados de um cliente do mesmo setor ou de um cliente com lucro semelhante.
De fato, trata-se de 12 regras muito complexas.
Premissas iniciais:- Não mais que 100 usuários por vez;
- 2-3 colunas para reconhecimento;
- 100 linhas.
Sem carga alta - tudo é chato.
Então, é hora de lançar. O congelamento de código ocorreu, o Java tem medo de tocar e leva pelo menos 5 minutos para processar um documento.
Eles chegam à equipe de desenvolvimento de banco de dados pedindo ajuda. Obviamente, porque
se algo diminuir na JVM, então, por si só, você precisará alterar ou reparar o banco de dados .

Estudamos os documentos e percebemos que em pares de valores-chave os valores são repetidos com frequência - 5 a 10 vezes. Dessa forma, decidimos usar o banco de dados para armazenar em cache, porque ele já foi testado.
Decidimos usar o cache de resultados do servidor Oracle, porque:
- as oportunidades para otimizar o SQL foram esgotadas, porque ele usa o mecanismo de pesquisa de texto completo do Oracle;
- cache será usado para parâmetros duplicados;
- a maioria dos dados para recomendações é recalculada uma vez por hora, pois eles usam um índice de texto completo;
- PL / SQL é proibido .
Cache de Resultados Oracle
Cache de resultados - cache de resultados do Oracle - possui as seguintes propriedades:
- Essa é a área de memória na qual todos os resultados da consulta são revistados;
- leia consistente, e sua invalidação automática ocorre;
- são necessárias alterações mínimas no aplicativo. Você pode fazer com que o aplicativo não precise ser alterado;
- bônus - você pode armazenar em cache a lógica PL / SQL, mas é proibida aqui.
Como habilitá-lo?Método número 1
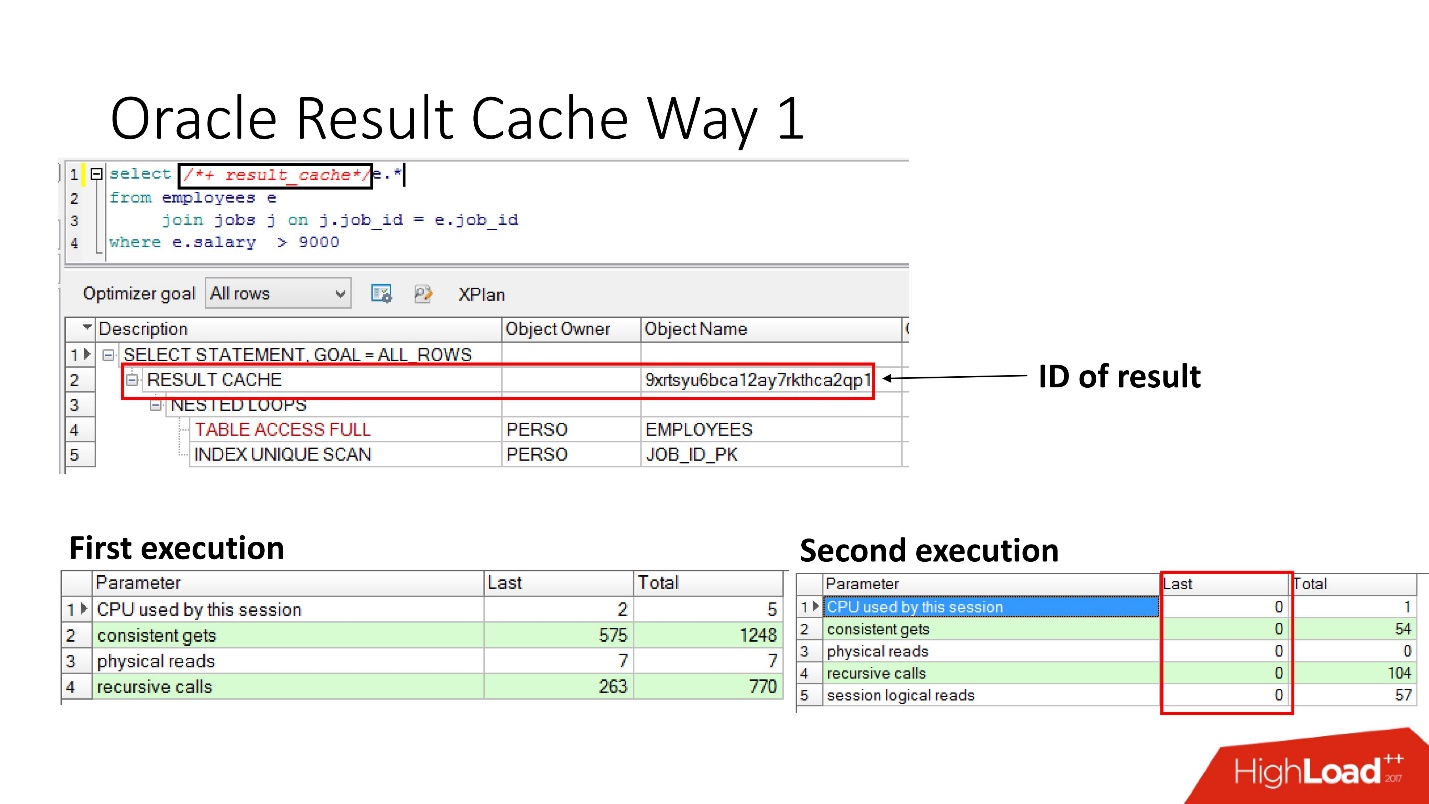
É muito simples
especificar a instrução result_cache . O slide mostra que o identificador de resultado apareceu. Portanto, na primeira vez em que a consulta é executada, o banco de dados realiza algum trabalho; durante a execução subsequente, nesse caso, nenhum trabalho é necessário. Está tudo bem.
Método número 2
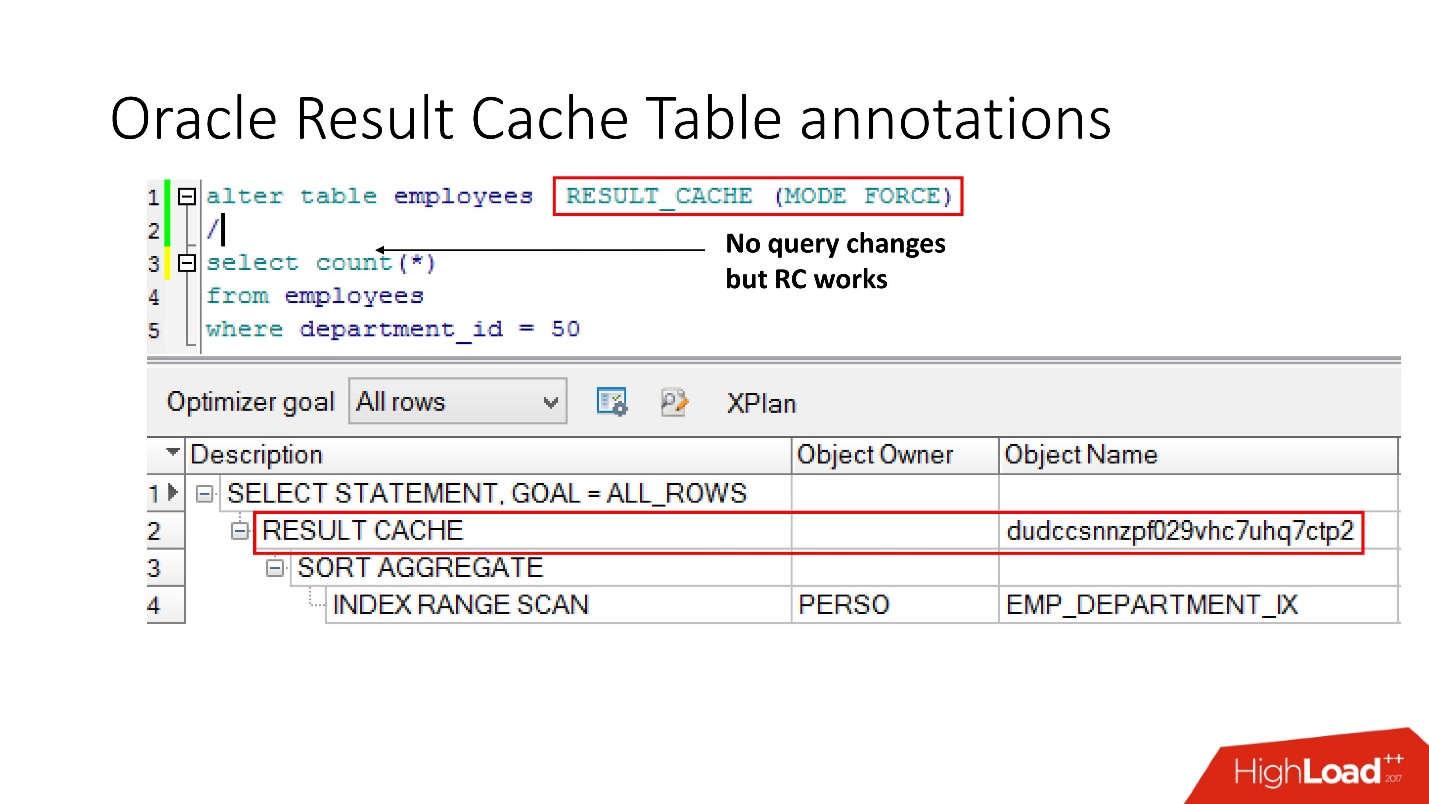
A segunda maneira permite que os desenvolvedores de aplicativos não façam nada - essas são as chamadas anotações. Indicamos uma marca de seleção para a tabela em que a solicitação deve ser colocada em result_cache. Portanto, não há dica, não tocamos no aplicativo e tudo já está em result_cache.
A propósito, o que você acha, se uma consulta se refere a duas tabelas, uma das quais está marcada como result_cache e a segunda não, o resultado dessa consulta é armazenado em cache?
A resposta é não, de maneira alguma.
Para que seja armazenada em cache, todas as tabelas que participam da consulta devem ter anotação result_cache.
Rastreamento de dependência
Existem visualizações relevantes nas quais você pode ver o que são dependências.
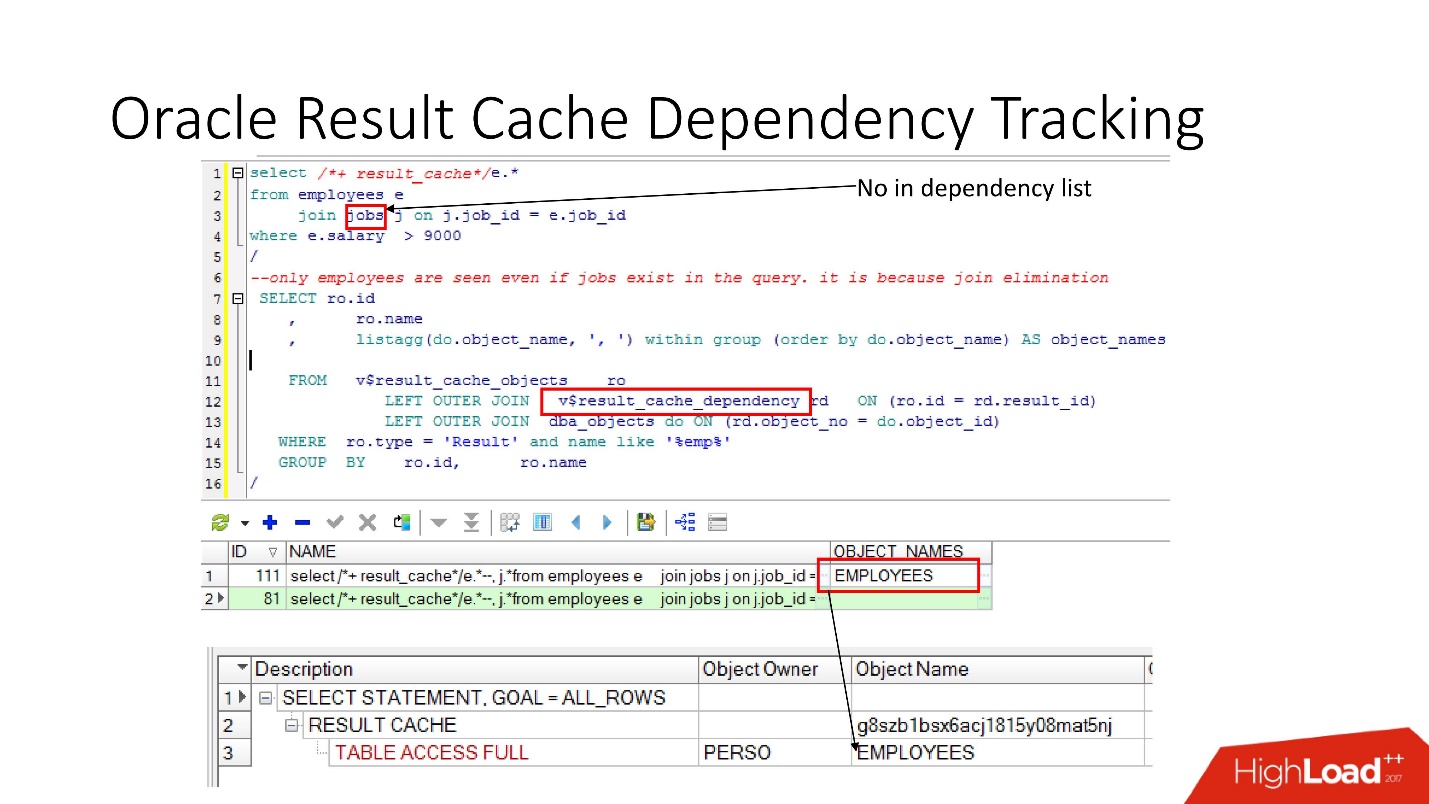
No exemplo acima, a consulta JOIN é uma tabela na qual existe uma dependência. Porque Porque o Oracle determina a dependência não apenas analisando, mas a implementa de
acordo com os resultados do plano de trabalho .
Nesse caso, esse plano foi escolhido porque apenas uma tabela é usada e, de fato, a tabela de tarefas está vinculada à tabela de funcionários por meio de restrição de chave estrangeira. Se removermos a restrição de chave estrangeira que permite essa transformação de eliminação de junção, veremos duas dependências, porque o plano mudará dessa maneira.
O Oracle não rastreia o que não precisa ser rastreado .
No PL / SQL, a dependência é executada em tempo de execução, para que você possa usar o SQL dinâmico e fazer outras coisas.
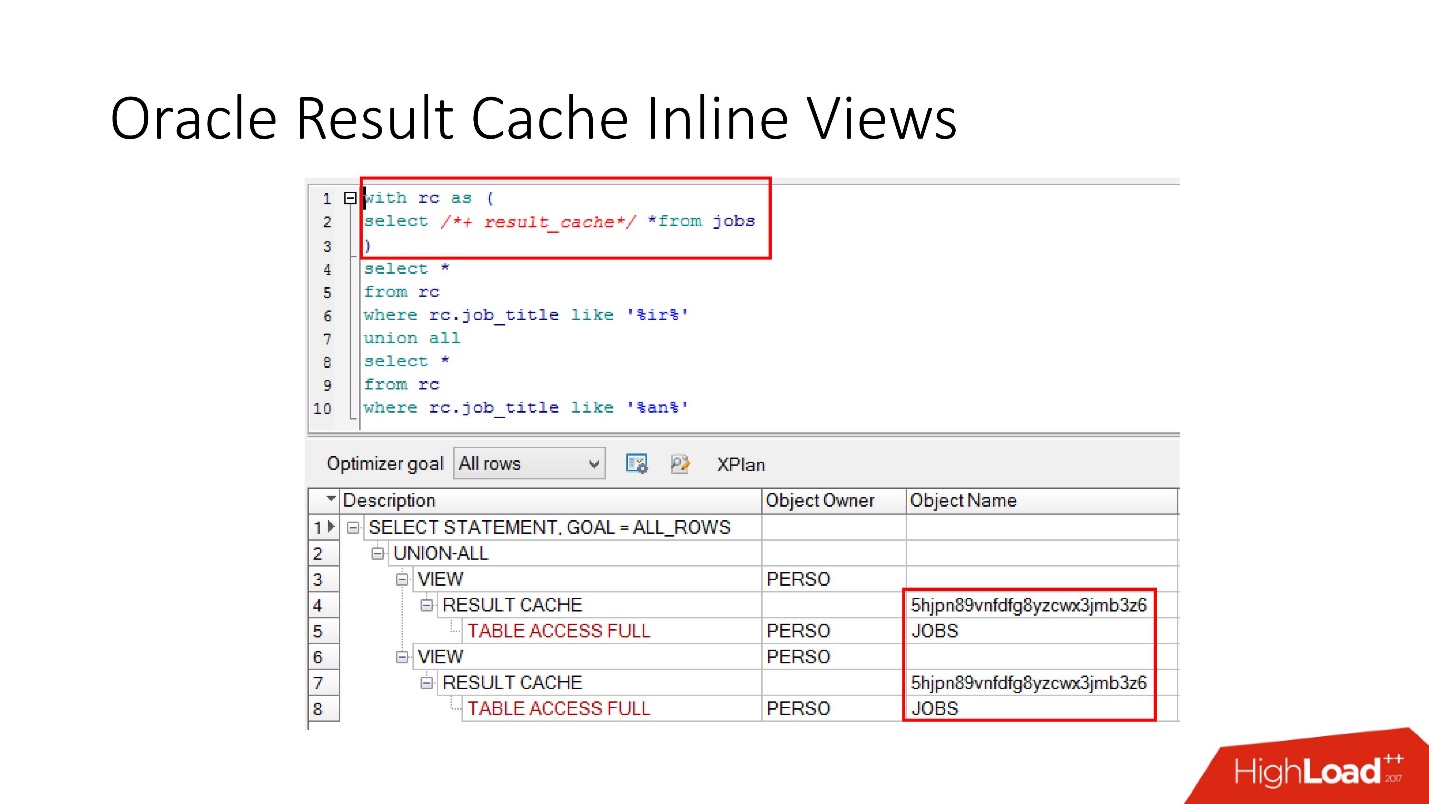
Observe que você pode armazenar em cache não apenas toda a solicitação, mas
também pode armazenar em cache a exibição em linha com e de . Suponha que, por um lado, precisamos de um cache, e o outro seria melhor ler do banco de dados para não sobrecarregá-lo. Adotamos uma visualização embutida, declaramos novamente como result_cache e vemos que apenas uma parte é armazenada em cache e, na segunda, acessamos o banco de dados todas as vezes.
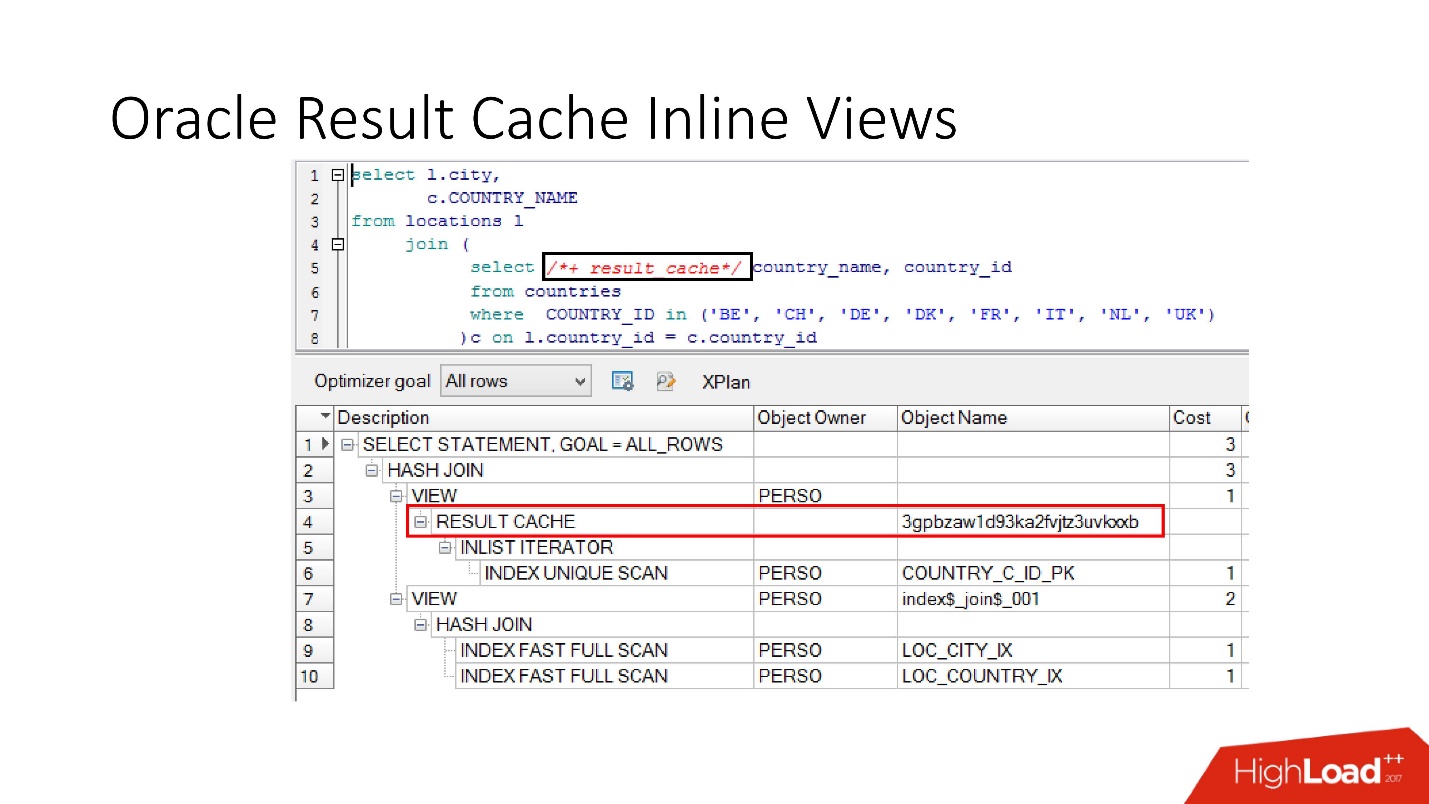
E, finalmente, os
bancos de dados também têm encapsulamento , embora ninguém acredite nele. Temos uma visão, colocamos result_cache nela, e nossos programadores nem percebem que ela está armazenada em cache. Abaixo, vemos que, de fato, apenas uma parte funciona.
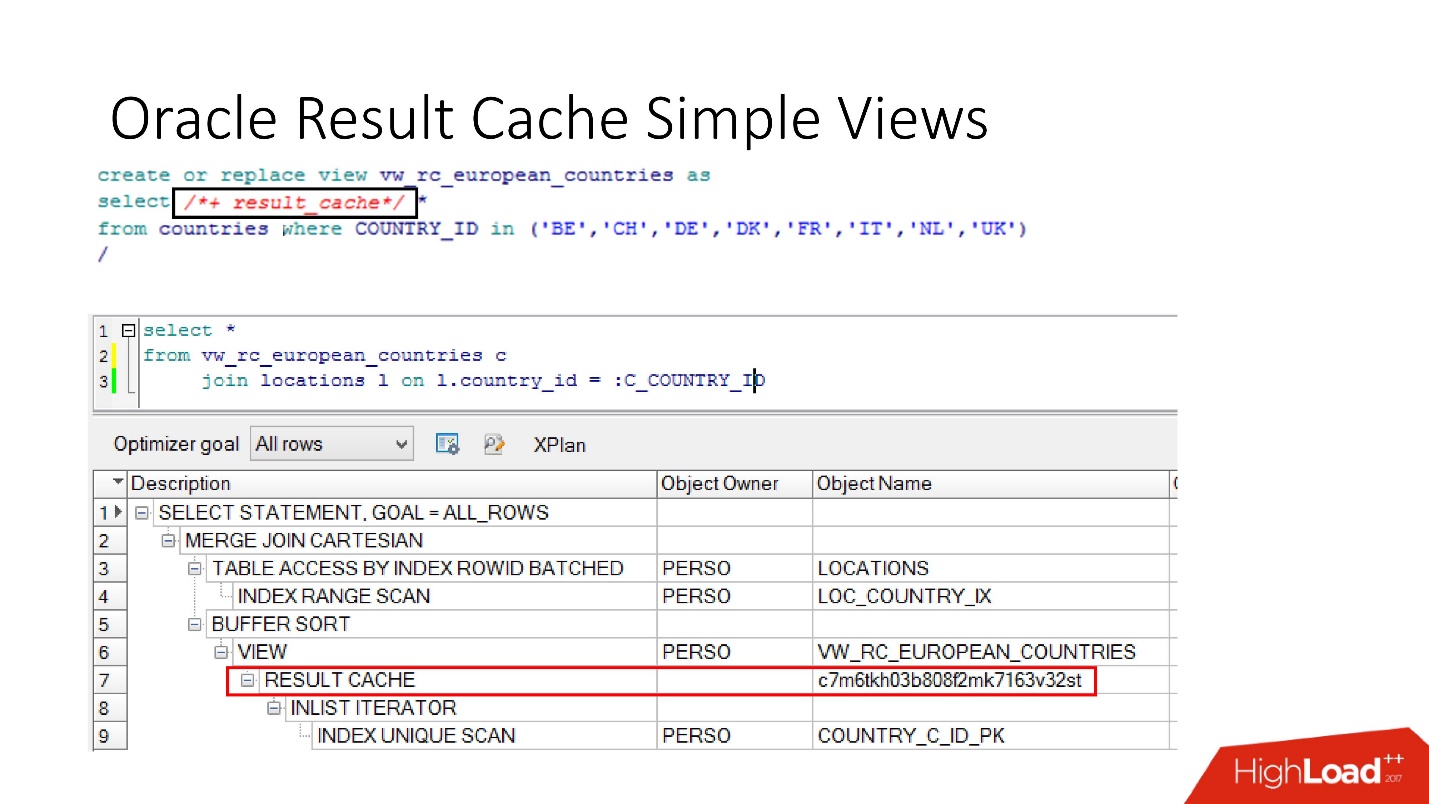
Deficiência
Então, vamos ver quando o Oracle invalida o result_cache.O status Publicado mostra o estado atual da validade do cache. Quando a solicitação para result_cache, como eu disse, não há trabalhos no banco de dados
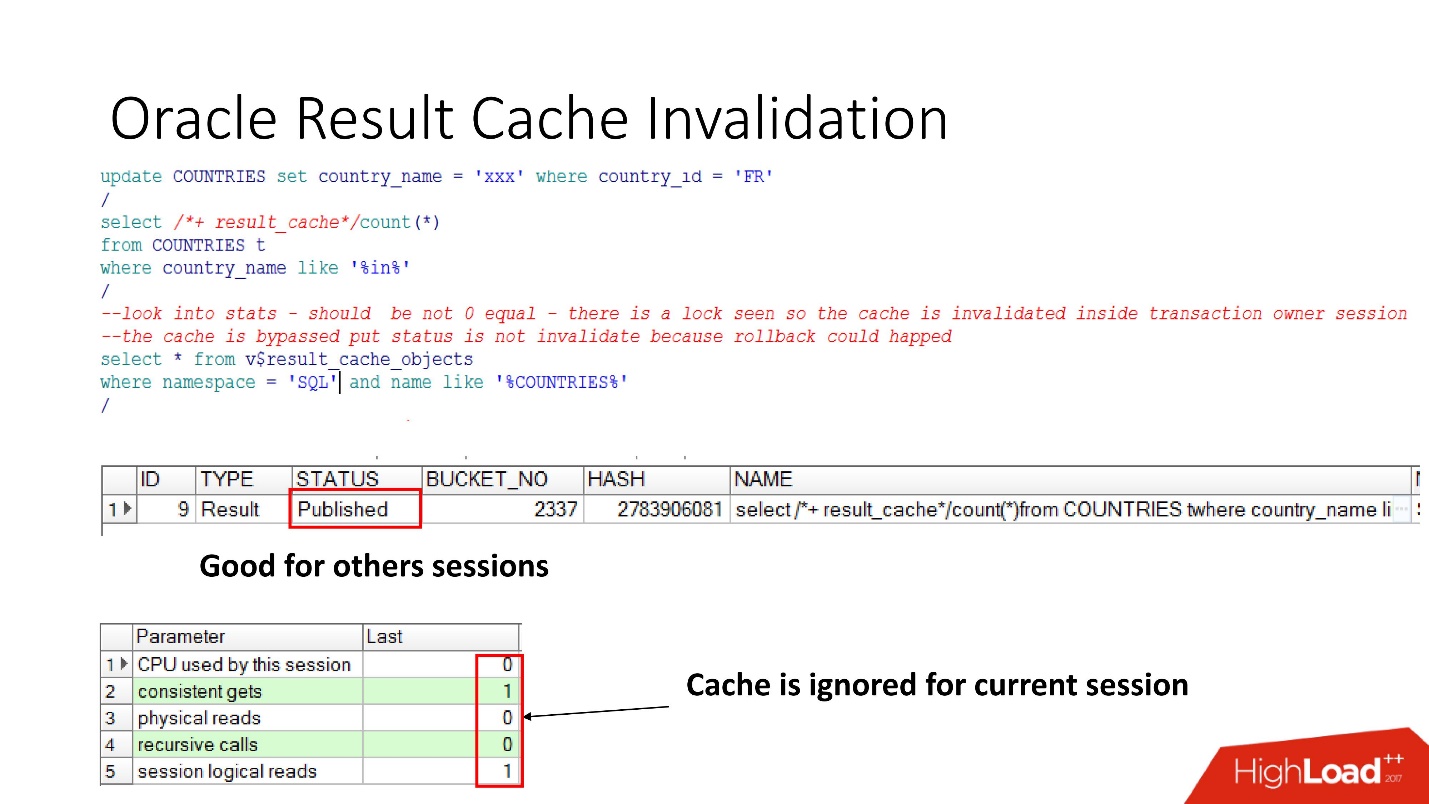
Quando fizemos a atualização, o status ainda é publicado, porque a atualização não foi confirmada e outras sessões devem exibir o resultado_cache antigo. Essa é a notória consistência da leitura.
Mas, na sessão atual, veremos que a carga acabou, pois é nessa sessão que o cache é ignorado. Isso é bastante razoável, vamos fazer o commit - o resultado se tornará Inválido, tudo funciona por si só.

Parece - um sonho! A dependência é considerada correta - apenas dependendo da solicitação. Mas não, várias nuances foram reveladas.
A Oracle produz deficiências e em vários casos não óbvios :
- Em qualquer chamada SELECT FOR UPDATE, as dependências desaparecem.
- Se a tabela tiver chaves estrangeiras não indexadas e ocorrer uma atualização na tabela marcada como result_cache, que não afetou nada, mas algo mudou na tabela pai, o cache também se tornará inválido.
- Essa é a coisa mais interessante que estraga a vida o máximo possível - se houver alguma atualização malsucedida na tabela marcada como result_cache, nada funcionou, mas, na mesma transação, outras alterações foram aplicadas que de alguma forma afetaram a primeira tabela, de qualquer maneira result_cache será redefinido.
Ainda existe um antipadrão sobre o result_cache, quando os desenvolvedores, ao ouvirem que há uma coisa tão legal, pensam: “Oh, há armazenamento! Agora, vamos fazer uma solicitação que funcione em 2-3 partições - na data atual e na anterior, marque-a como result_cache, e ela sempre será retirada da memória! "
Mas quando você muda a patricia em retrospectiva, todo o cache voa, porque na verdade a unidade de rastreamento de dependência em result_cache é sempre uma tabela e não sei se haverá partições ou não.
Pensamos e decidimos que iríamos para a produção de um sistema de recomendação com essas coisas:
- Não armazenaremos em cache todas as nossas tabelas, apenas as necessárias.
- Defina result_cache para a consulta de longa execução.
Verificamos tudo, realizamos testes de desempenho,
tempo de processamento - 30 s . Tudo está ótimo, vá para produção!
Partiu - foi dormir. Chegamos de manhã. Vemos uma carta: "O reconhecimento leva pelo menos 20 minutos, as sessões congelam". Por que eles estão congelando? Como
30 segundos se transformaram em 20 minutos ?
Eles começaram a entender, olhe para o banco de dados:
- sessões ativas - 400;
- em linhas médias em um documento para reconhecimento - 500;
- mínimo de colunas - 5-8;
- o número de sessões no banco de dados é sempre igual ao número de aplicativos do usuário multiplicado por 3! E result_cache não gosta de acesso frequente a ele.
Após realizar uma investigação interna, descobrimos que os desenvolvedores Java fazem reconhecimento em 3 threads.
Ficamos chateados - uma carga, queda, degradação de 5 vezes e, mesmo com esses parâmetros, tal subsidência não deveria ter acontecido.
Obviamente, você precisa entender.
Monitoramento

Para o monitoramento, temos duas coisas principais:
- V $ RESULT_CACHE_OBJECTS - uma lista de todos os objetos;
- V $ RESULT_CACHE_STATISTICS - agrega estatísticas de result_cache como um todo.
MEMORY_REPORT são variações de um tema, não precisaremos deles.
Oracle é mágico! A documentação é ótima, mas foi projetada para aqueles que alternam de outros bancos de dados para ler e pensar que o Oracle é muito legal! Mas
todas as informações no result_cache estão apenas no suporte .

Há uma nuance que consiste no fato de que, assim que nos voltamos para esses objetos, a fim de resolver o problema, nós o exacerbamos por finalmente nos enterrando! Até o Oracle12.2, antes do patch lançado em outubro do ano passado, essas solicitações tornam o resultado_cache inacessível para status e gravação até que sejam contados completamente.
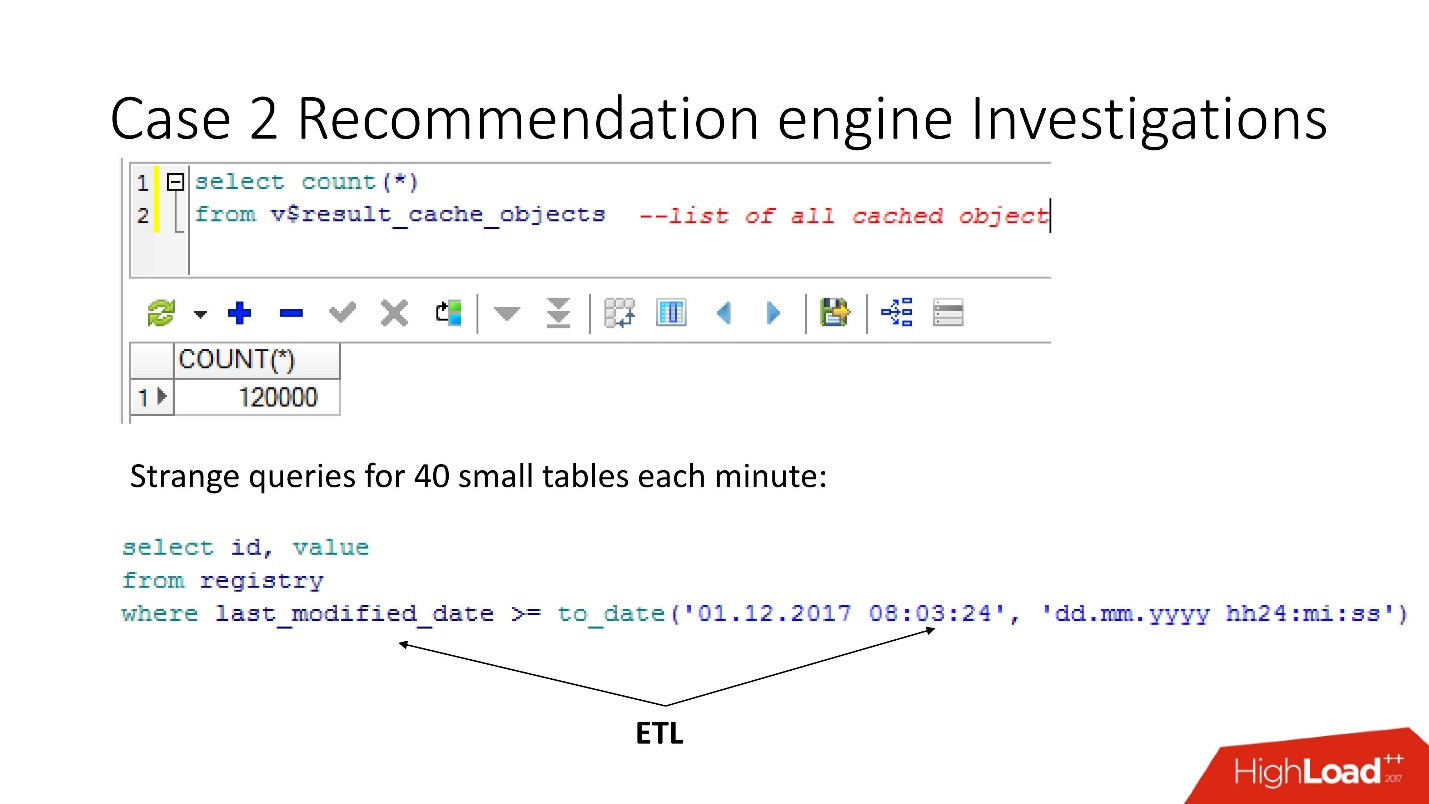
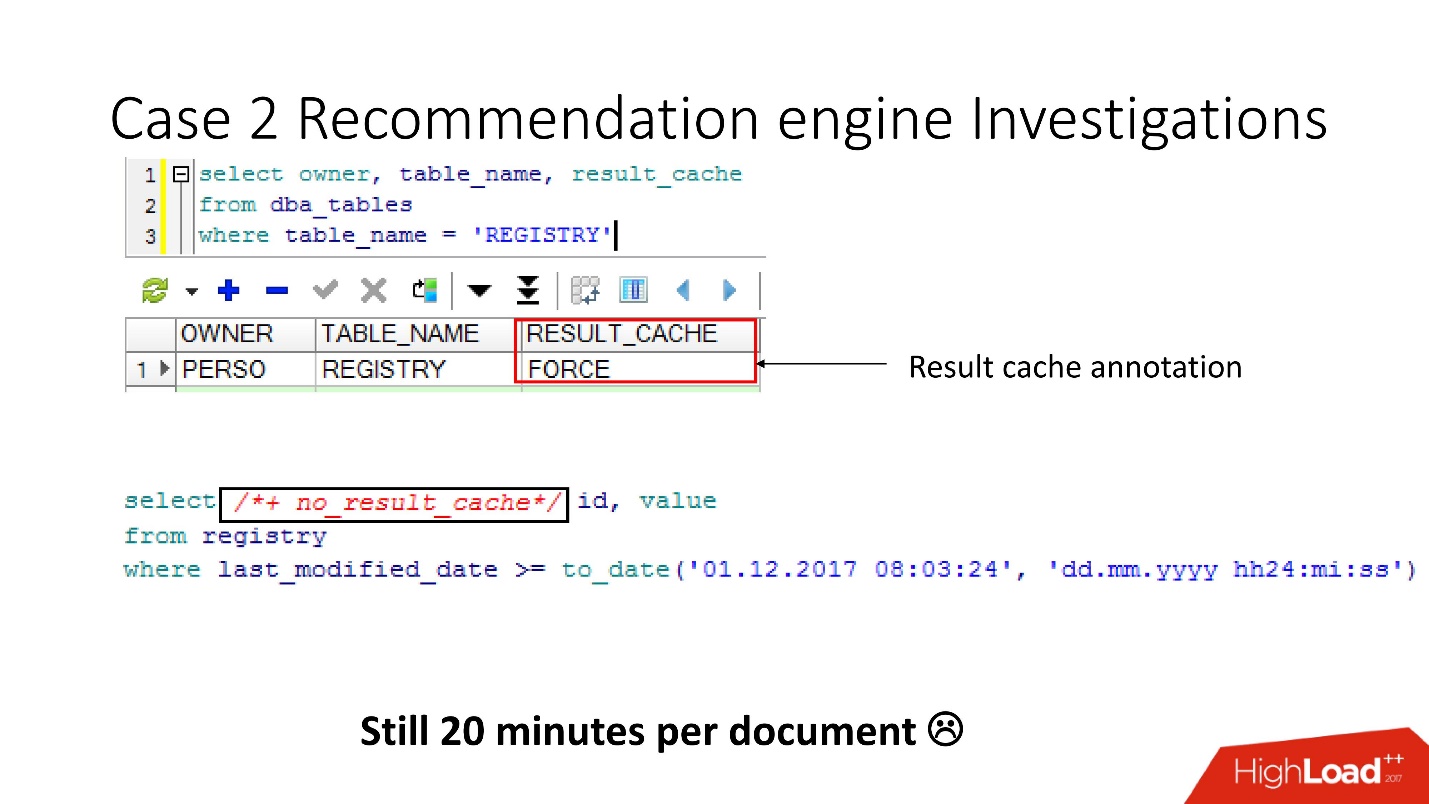
Portanto, usando a visualização v $ result_cache_objects, descobrimos que existem milhares de entradas na lista de objetos em cache - muito mais do que esperávamos. Além disso, esses eram objetos de algumas de nossas consultas em tabelas estranhas - tablets pequenos e consultas last_modified_date. Obviamente,
alguém colocou o ETL em nossa base .
Antes de falar palavrões com os desenvolvedores de ETL, verificamos que a opção result_cache force estava ativada para essas tabelas e lembramos que a ativamos, pois alguns desses dados geralmente eram exigidos pelo aplicativo e o cache era apropriado.
Mas
todos esses pedidos apenas pegam e lavam nosso cache . Felizmente, os desenvolvedores tiveram a oportunidade de influenciar o ETL na produção, portanto, pudemos alterar o result_cache para excluir essas solicitações minuciosas.
Você acha que é mais fácil? - Não se sinta melhor! O número de objetos em cache diminuiu e subiu novamente para 12.000. Continuamos estudando o que mais foi armazenado em cache, pois a velocidade não mudou.

Nós olhamos - um monte de pedidos, e tão inteligentes, mas todos incompreensíveis. Embora qualquer pessoa que tenha trabalhado com o Oracle 12 saiba que o DS SVC é uma estatística adaptativa. É necessário melhorar o desempenho, mas quando há result_cache, acontece que o mata porque a concorrência está acontecendo. Obviamente, isso é escrito
apenas como suporte .
Sabíamos como a carga de trabalho é organizada e entendemos que, no nosso caso, as estatísticas adaptativas não melhorariam radicalmente nossos planos. Portanto, heroicamente o desativamos - o resultado, conforme está escrito no manual secreto, é de 10 minutos por documento. Não é ruim, mas não o suficiente.
Travas
A competição entre result_cache e DS SVC se deve ao fato de a Oracle ter travas - pequenas travas leves.

Sem entrar em detalhes sobre como eles funcionam, tentamos colocar uma trava nomeada várias vezes - não deu certo - a Oracle pega e adormece
Qualquer pessoa que esteja no assunto pode dizer que no result_cache, duas travas são colocadas em cada bloco com busca. Estes são os detalhes. Existem dois tipos de travas em result_cache:
1. Trave pelo período enquanto escrevemos dados em result_cache.

Ou seja, se sua solicitação estiver funcionando por 8 s, durante o período desses 8 s, outras mesmas solicitações (a palavra-chave “mesmo”) não poderão fazer nada, pois aguardam até que os dados sejam gravados em result_cache. Outros pedidos serão gravados, mas aguardarão pelo bloqueio apenas na primeira linha. Quanto eles terão que esperar é desconhecido; esse é o parâmetro não documentado result_cache_timeout. Depois disso, eles começam a ignorar result_cache, por assim dizer, e trabalham lentamente. No entanto, assim que a trava da última linha na porta é liberada, eles automaticamente começam a trabalhar com o result_cache novamente.
2. O segundo tipo de bloqueios - para receber de result_cache também da 1ª linha até a última.
Mas como a busca vem da memória instantânea, eles são removidos muito rapidamente.

Lembre-se de que, quando o DBA vê travas no banco de dados, ele começa a dizer: “Travas! Tempo de espera - tudo se foi! »E aqui começa o jogo mais interessante:
convencer o DBA de que o tempo de espera das travas é realmente incomparavelmente menor do que o tempo de repetição da consulta .

Como mostra nossa experiência, nossas medições,
travas em result_cache ocupam 10% das solicitações .
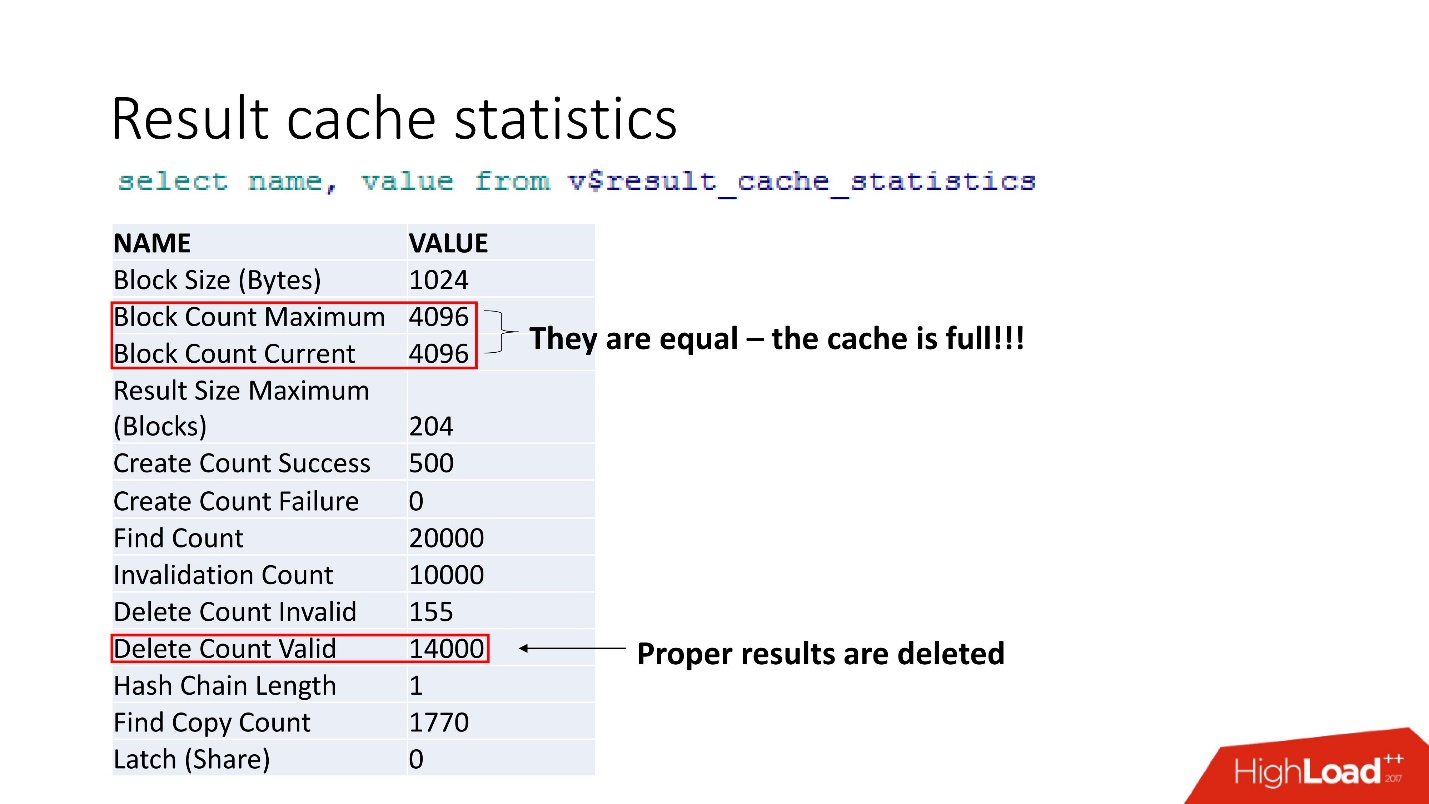
Estas são estatísticas agregadas. O fato de que tudo está ruim pode ser entendido pelo fato de o cache estar entupido. Outra confirmação é Resultados adequados são excluídos. Ou seja, o
cache é substituído . Parece que somos inteligentes e sempre consideramos o tamanho da memória - pegamos o tamanho da linha do resultado em cache para nossa recomendação, multiplicado pelo número de linhas e algo deu errado.

support 2 , ,
result_cache . .
, . , , , workload 5 . , , .
?: . , .
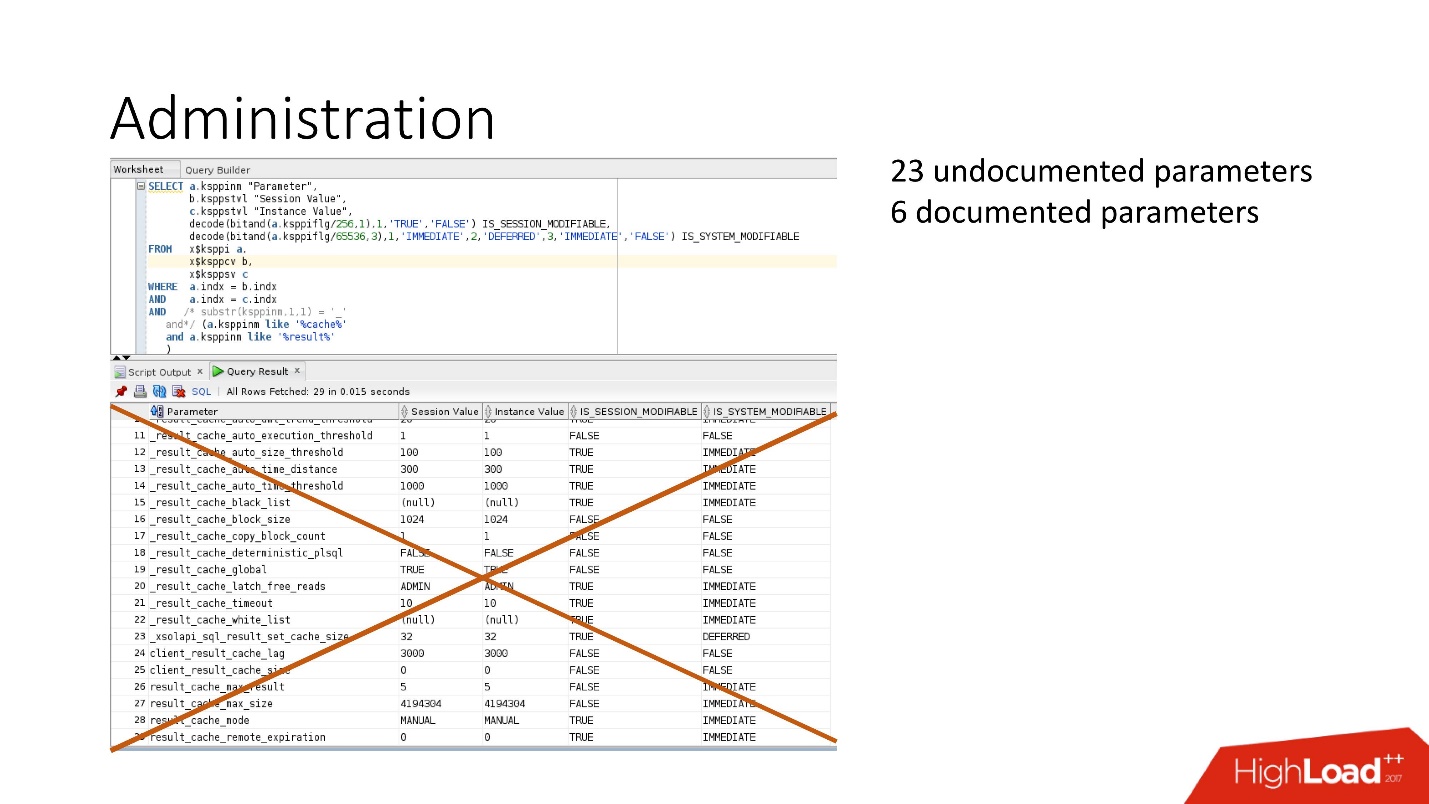
4 :
- RESULT_CACHE_MAX_SIZE;
- RESULT_CACHE_MAX_RESULT;
- RESULT_CACHE_MODE;
- _RESULT_CACHE_MAX_TIMEOUT.
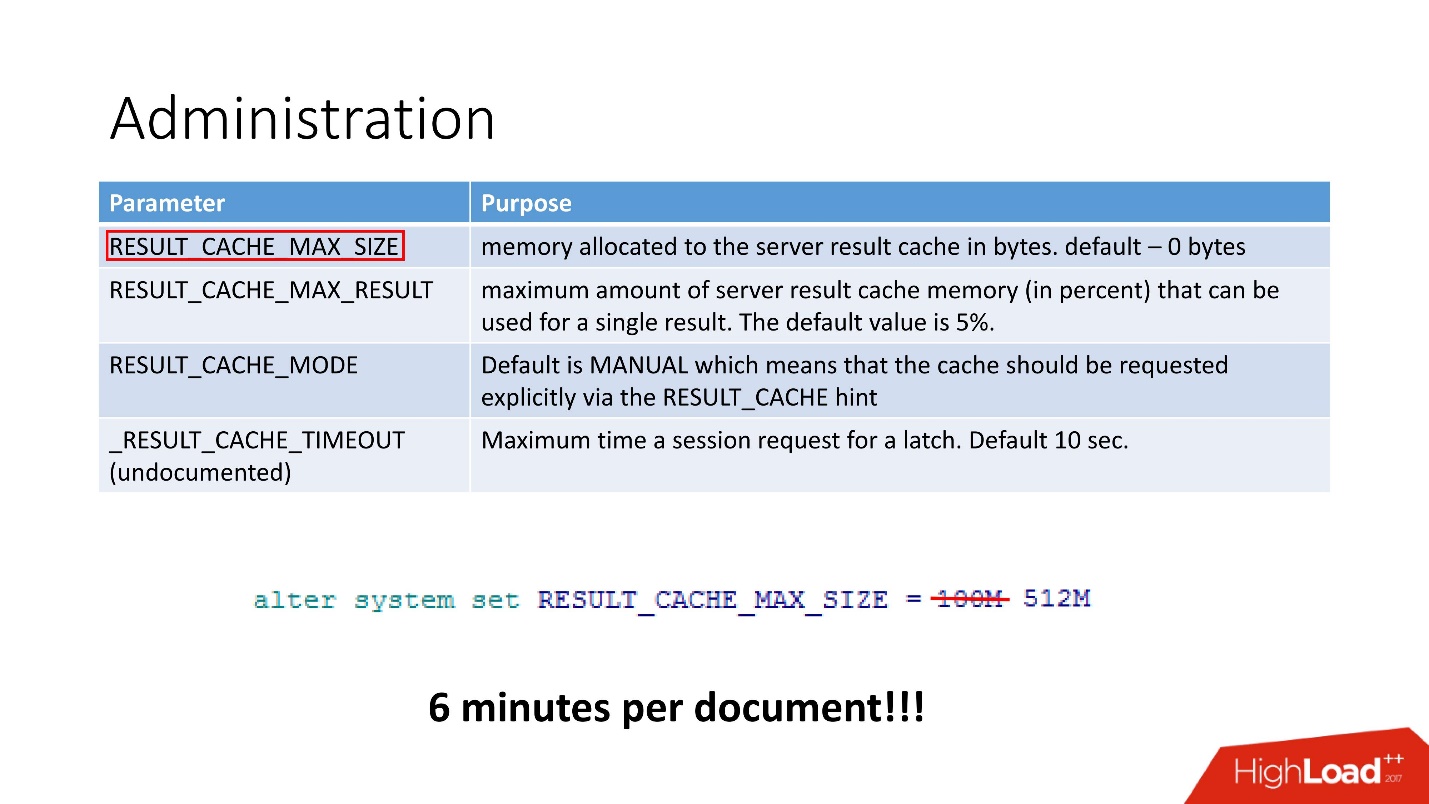
— . , 100 512, 6 .
, - . , Invalidation Count = 10000.
, . , job , . , . job , , .
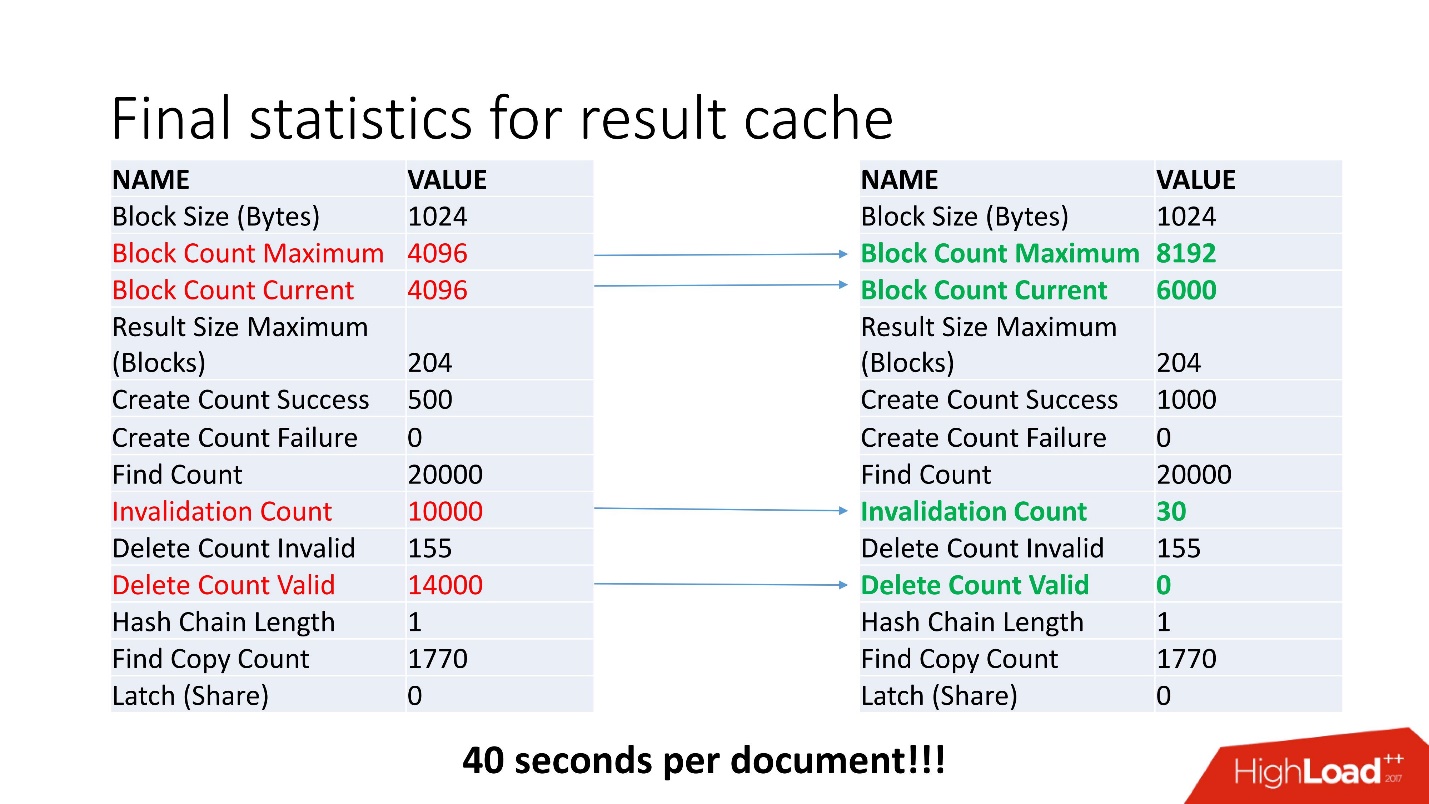
, invalid , .
40 .
, . , , Oracle. !
 SHELFLIVE
SHELFLIVE — , read-consistent , 10 , . . , , .
—
SNAPSHOT . , , read-consistent — .
:

- — SYS.
- . , , Oracle , , . , Oracle , , 12.2 . , external - support, .
- sql pl/sql : current_date, current_time . , current_time, .
- .
- , CLOB, BLOB .
Result cache inside Oracle
Result_cache — Oracle Core. , , job result_cache (, hint, ) , APEX.

, Dynamic sampling , , , result_cache.

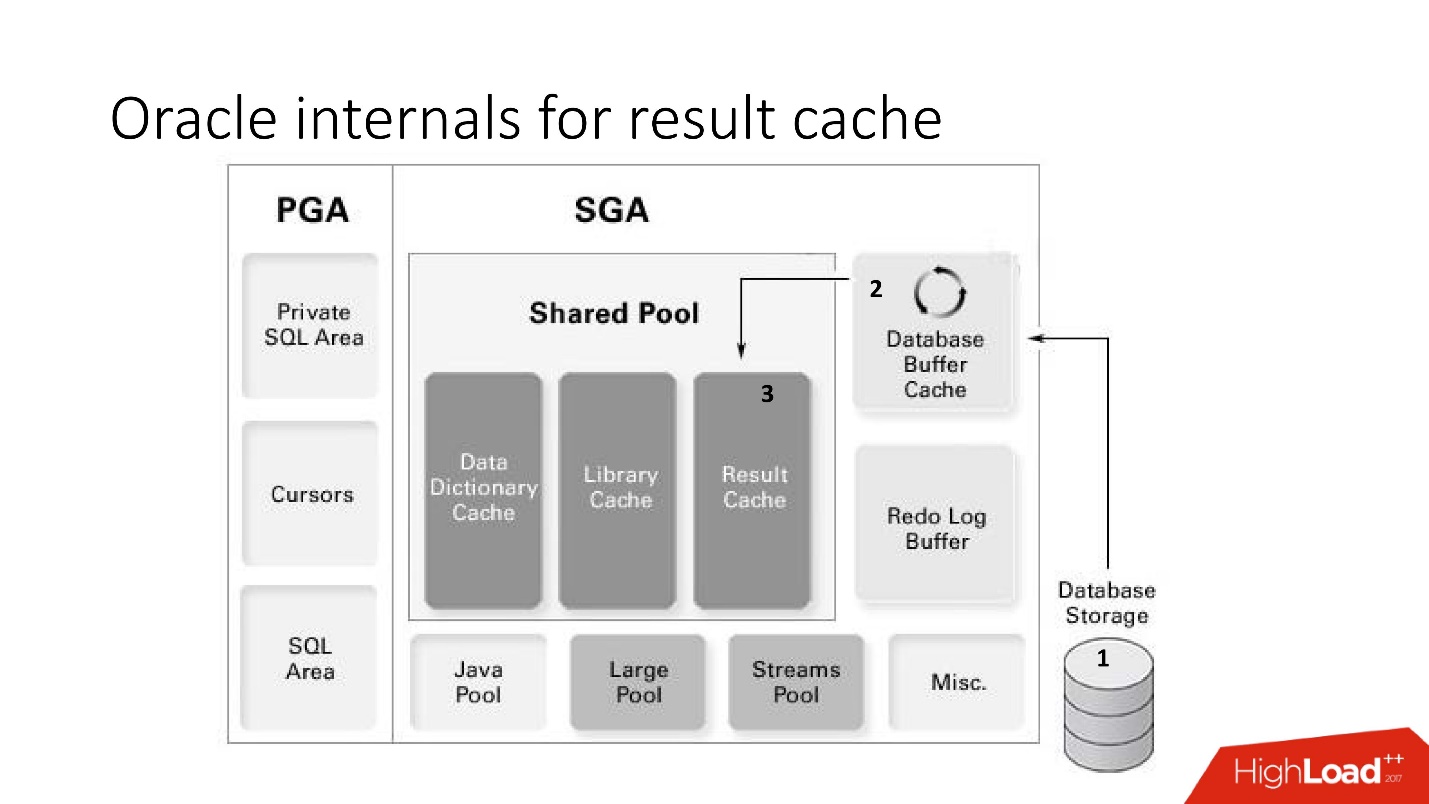
Oracle internals for result cache
result_cache:
- (storage) ;
- result_cache;
- result_cache shared pool.
 :
:- .
- read-consistent.
- Result_cache, , .
:!
, . support Oracle, , 29 2017 .: Oracle E-Business suite result_cache, .

, , . support , , .

:
- - ;
- , , , , v$result_cache_memory dbms_result_cache.memory_report, .
, , , v_result_cache_objects .
, support note — support , .

, , : - . , , :
- hint result_cache;
- hint no result_cache;
- black_list, , , -.
?,
— . Oracle , .
Client side result cache

O diagrama do seu dispositivo é mostrado acima, estes são os principais componentes do banco de dados e do driver.
Na primeira vez em que o lado do cliente é acessado, o cache de resultados acessa o banco de dados, que é pré-configurado, recebe o tamanho do cache do cliente e instala esse cache no cliente uma vez na primeira conexão. A consulta em cache primeiro acessa o banco de dados e grava dados no cache. Os segmentos restantes solicitam um cache de driver compartilhado, economizando memória e recursos do servidor. A propósito, às vezes, dependendo da carga, o driver envia estatísticas sobre o uso do cache ao banco de dados, que pode ser visualizado.
Uma pergunta interessante é: como a deficiência acontece?Existem dois modos de invalidação, que são aprimorados pelo parâmetro Invalidation lag. É o quanto o Oracle permite que o cache do driver não seja consistente.
O primeiro modo é usado quando as solicitações são frequentes e o atraso de Invalidação não ocorre. Nesse caso, o fluxo irá para o banco de dados, atualizará os caches e lerá os dados dele.
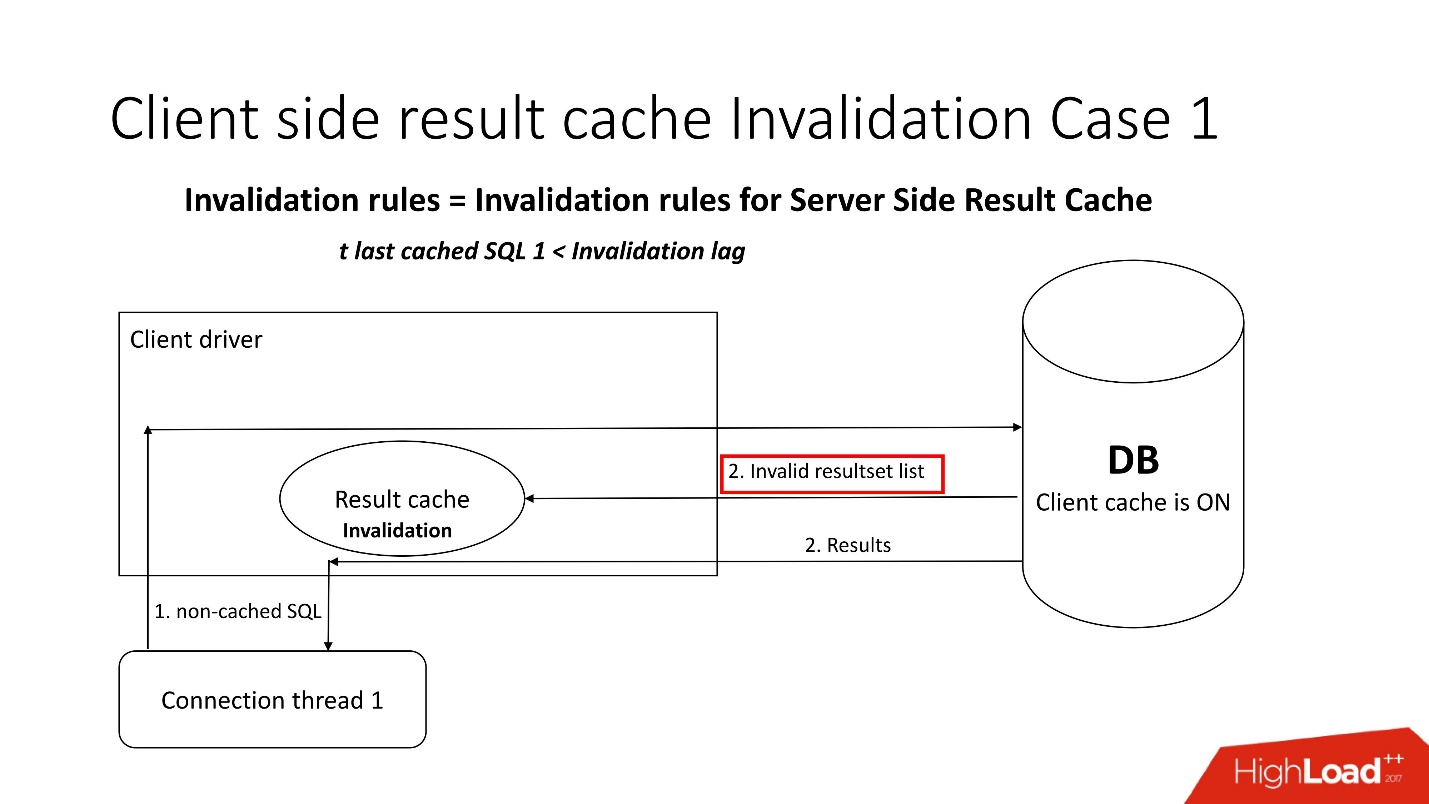
Se o atraso da Invalidação falhar, qualquer solicitação não armazenada em cache, referente ao banco de dados, além dos resultados da consulta, traz uma lista de objetos inválidos. Assim, eles são marcados como inválidos no cache e tudo funciona como na imagem desde o primeiro cenário.
No segundo caso, se tiver passado mais tempo do que o atraso da Invalidação, o próprio cliente result_cache vai ao banco de dados e diz: "Dê-me uma lista de alterações!" Ou seja, ele próprio mantém seu estado adequado.
A configuração do cache de resultados do lado do cliente é muito simples . Existem 2 opções:
- CLIENT_RESULT_CACHE_LAG - valor do atraso no cache;
- CLIENT_RESULT_CACHE_SIZE - tamanho (mínimo 32 Kb, máximo - 2 GB).

Do ponto de vista do desenvolvedor do aplicativo, o cache do cliente não é muito diferente do cache do servidor, eles também inseriram a dica result_cache. Se fosse, ele começará a ser usado pelo cliente - no .Net e no Java.

Depois de fazer 10 iterações da consulta, obtive o seguinte.

O primeiro apelo é a criação, depois 9 acessos ao cache. A tabela indica que a memória também está alocada em blocos. Também preste atenção ao SELECT - não é muito intuitivo. Para ser sincero, antes de começar a lidar com isso, eu nem sabia que havia uma representação de
GV$SESSION_CONNECT_INFO . Por que a Oracle não levou diretamente a esta tabela (e esta é uma tabela, não uma exibição), eu não conseguia entender. Mas é por isso que acredito que essa funcionalidade não é muito popular, embora, como me pareça, seja muito útil.
Vantagens do armazenamento em cache do cliente:- memória barata do cliente;
- qualquer driver disponível - JDBC, .NET, etc;
- impacto mínimo no código do aplicativo.
- Reduzindo a carga na CPU, E / S e geralmente no banco de dados;
- não há necessidade de aprender e usar todos os tipos de camadas e APIs de cache inteligente;
- sem travas.
Desvantagens:- consistência na leitura com atraso - em princípio, agora esta é uma tendência;
- precisa do cliente Oracle OCI;
- limitação de 2 GB por cliente, mas em geral 2 GB é muito;
- Para mim, pessoalmente, a principal limitação é um pouco de informação sobre produção.
No suporte, que sempre usamos ao trabalhar com o result_cache, encontrei apenas 5 bugs. Isso sugere que, provavelmente, poucas pessoas precisam disso.
Então, reunimos tudo o que foi dito acima.
Cache feito à mão
Cenários ruins:- Alteração instantânea - se, após a alteração dos dados, o cache se tornar imediatamente irrelevante. Para caches criados manualmente, é difícil criar a invalidação correta em caso de alterações nos objetos nos quais eles são criados.
- Se o uso da lógica armazenada no banco de dados for proibido pelas políticas de desenvolvimento.
Bons cenários:- Existe uma forte equipe de desenvolvimento de banco de dados.
- Implementada lógica PL / SQL.
- Existem limitações que impedem o uso de outras técnicas de armazenamento em cache.
Cache de resultados do lado do servidor
Cenários ruins:- Muitos resultados diferentes que apenas lavam o cache inteiro;
- As solicitações demoram mais que _RESULT_CACHE_TIMEOUT ou esse parâmetro está configurado incorretamente.
- Os resultados de sessões muito grandes são carregados no cache em threads paralelos.
Bons cenários:- Quantidade razoável de resultados em cache.
- Conjuntos de dados relativamente pequenos (200 a 300 linhas).
- SQL bastante caro, caso contrário, o tempo todo vai para travas.
- Tabelas mais ou menos estáticas.
- Existe um DBA, que em caso de algo virá e salvará a todos.
Cache de resultados do lado do cliente
Cenários ruins:- Quando surge o próprio problema da incapacidade instantânea.
- Drivers finos necessários.
Bons cenários:- Existe uma equipe de desenvolvimento normal da camada intermediária.
- Muito SQL já está em uso sem o uso de uma camada de cache externa que possa ser facilmente conectada.
- Existem restrições nas glândulas.
Conclusões
Acredito que minha história seja sobre a dor no cache de Resultados do lado do servidor, portanto as conclusões são as seguintes:
- Sempre avalie o tamanho da memória corretamente, levando em consideração o número de consultas e não o número de resultados, ou seja, blocos, APEX, trabalho, estatísticas adaptativas etc.
- Não tenha medo de usar as opções de liberação automática de cache (captura instantânea + validade).
- Não sobrecarregue o cache com solicitações ao carregar grandes quantidades de dados; desative o result_cache antes disso. Aqueça o cache.
- Certifique-se de que _result_cache_timeout atenda às suas expectativas.
- NUNCA use FORCE para todo o banco de dados. Precisa de um banco de dados em memória - use uma solução especializada em memória.
- Verifique se a opção FORCE é usada adequadamente para tabelas individuais, para que não funcione, como ocorre com ETLs de terceiros.
- Decida se as estatísticas adaptativas são tão boas quanto as descritas pelo Oracle (_optimizer_ads_use_result_cache = false).
Highload ++ Siberia na próxima segunda-feira, a programação está pronta e publicada no site. Existem vários relatórios no tópico deste artigo:
- Alexander Makarov (CFT GC) demonstrará um método para identificar gargalos no lado do servidor do software usando o banco de dados Oracle como exemplo.
- Ivan Sharov e Konstantin Poluektov lhe dirão quais problemas surgem ao migrar o produto para novas versões do banco de dados Oracle e também prometem dar recomendações sobre a organização e realização de tal trabalho.
- Nikolay Golov mostrará como garantir a integridade dos dados em uma arquitetura de microsserviço, sem transações distribuídas e conectividade rígida.
Encontre-me em Novosibirsk!