Este artigo abordará alguns algoritmos de pesquisa e descrições de pontos de imagem específicos. Aqui, este tópico já foi
levantado e mais
de uma vez . Considerarei que as definições básicas já são familiares para o leitor, examinaremos detalhadamente os algoritmos heurísticos FAST, FAST-9, FAST-ER, BREVE, rRIVE, ORB e discutiremos as idéias cintilantes subjacentes a eles. Em parte, esta será uma tradução livre da essência de vários artigos [1,2,3,4,5]; haverá algum código para "try".

Algoritmo RÁPIDO
O FAST, proposto pela primeira vez em 2005 em [1], foi um dos primeiros métodos heurísticos para encontrar pontos singulares, que ganharam grande popularidade devido à sua eficiência computacional. Para tomar uma decisão sobre considerar um determinado ponto C como especial ou não, esse método considera o brilho dos pixels em um círculo centrado no ponto C e no raio 3:

Comparando o brilho dos pixels do círculo com o brilho do centro C, para cada um obtemos três resultados possíveis (mais claro, mais escuro, ao que parece):
$ inline $ \ begin {array} {l} {I_p}> {I_C} + t \\ {I_p} <{I_C} -t \\ {I_C} -t <{I_p} <{I_C} + t \ end {array} $ inline $
Aqui estou o brilho dos pixels, t é um limite de brilho predeterminado.
Um ponto é marcado como especial se houver n = 12 pixels em uma linha mais escura ou 12 pixels mais claros que o centro.
Como a prática demonstrou, em média, para tomar uma decisão, foi necessário verificar cerca de 9 pontos. Para acelerar o processo, os autores sugeriram primeiro verificar apenas quatro pixels com números: 1, 5, 9, 13. Se entre eles houver 3 pixels mais claro ou mais escuro, será realizada uma verificação completa em 16 pontos; caso contrário, o ponto será imediatamente marcado como " não é especial. Isso reduz bastante o tempo de trabalho; para tomar uma decisão em média, basta pesquisar apenas cerca de 4 pontos de um círculo.
Um pouco de código ingênuo está
aquiParâmetros variáveis (descritos no código): raio do círculo (assume valores 1,2,3), parâmetro n (no original, n = 12), parâmetro t. O código abre o arquivo in.bmp, processa a imagem e salva em out.bmp. As imagens são comuns de 24 bits.
Construindo uma árvore de decisão, Árvore FAST, FAST-9
Em 2006, em [2], foi possível desenvolver uma idéia original usando aprendizado de máquina e árvores de decisão.
O FAST original tem as seguintes desvantagens:
- Vários pixels adjacentes podem ser marcados como pontos especiais. Precisamos de alguma medida da "força" de um recurso. Uma das primeiras medidas propostas é o valor máximo de t no qual o ponto ainda é tomado como especial.
- Um teste rápido de 4 pontos não é generalizado para n menor que 12. Portanto, por exemplo, visualmente os melhores resultados do método são alcançados com n = 9, e não 12.
- Eu também gostaria de acelerar o algoritmo!
Em vez de usar uma cascata de dois testes de 4 e 16 pontos, propõe-se fazer tudo de uma só vez na árvore de decisão. De maneira semelhante ao método original, compararemos o brilho do ponto central com os pontos do círculo, mas nesta ordem para tomar a decisão o mais rápido possível. E acontece que você pode tomar uma decisão para apenas ~ 2 (!!!) comparações, em média.
O próprio sal é como encontrar a ordem certa para comparar pontos. Encontre usando o aprendizado de máquina. Suponha que alguém notou para nós na imagem muitos pontos especiais. Nós os usaremos como um conjunto de exemplos de treinamento, e a idéia é escolher com
entusiasmo aquele que fornecerá a maior quantidade de informações nesta etapa, como o próximo ponto. Por exemplo, suponha que inicialmente em nossa amostra houvesse 5 pontos singulares e 5 pontos não singulares. Na forma de um tablet como este:
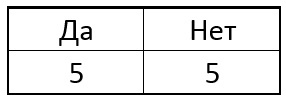
Agora escolhemos um dos pixels p do círculo e, para todos os pontos singulares, comparamos o pixel central com o selecionado. Dependendo do brilho do pixel selecionado próximo a cada ponto específico, a tabela pode ter o seguinte resultado:
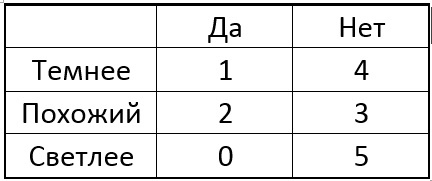
A idéia é escolher um ponto p para que os números nas colunas da tabela sejam os mais diferentes possíveis. E se agora, para um novo ponto desconhecido, obtivermos o resultado da comparação “Mais leve”, já podemos dizer imediatamente que o ponto “não é especial” (consulte a tabela). O processo continua recursivamente até que os pontos de apenas uma das classes caiam em cada grupo depois de se dividirem em "mais escuros". Acontece uma árvore da seguinte forma:
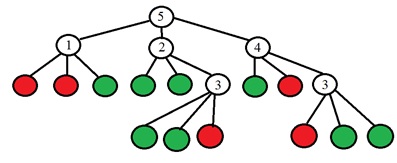
O valor binário está nas folhas da árvore (vermelho é especial, verde não é especial) e nos outros vértices da árvore está o número do ponto que precisa ser analisado. Mais especificamente, no artigo original, eles propõem a escolha do número do ponto alterando a entropia. A entropia do conjunto de pontos é calculada:
$$ display $$ H = \ left ({c + \ overline c} \ right) {\ log _2} \ left ({c + \ overline c} \ right) - c {\ log _2} c - \ overline c {\ log _2} \ overline c $$ display $$
c é o número de pontos singulares,
$ inline $ {\ bar c} $ inline $ É o número de pontos não singulares do conjunto
Alteração na entropia após o ponto de processamento p:
exibição $$ $$ \ Delta H = H - {H_ {dark}} - {H_ {equal}} - {H_ {brilhante}} $$ exibição $$
Consequentemente, um ponto é selecionado para o qual a alteração na entropia será máxima. O processo de divisão para quando a entropia é zero, o que significa que todos os pontos são singulares ou vice-versa - nem todos são especiais. Com uma implementação de software, depois de tudo isso, a árvore de decisão encontrada é convertida em um conjunto de construções do tipo "if-else".
O último passo do algoritmo é a operação de suprimir valores não máximos para obter um de vários pontos adjacentes. Os desenvolvedores sugerem o uso da medida original com base na soma das diferenças absolutas entre o ponto central e os pontos do círculo nesta forma:
$$ display $$ V = \ max \ left ({\ sum \ limits_ {x \ in {S_ {bright}}} {\ left | {{I_x} - {I_p}} \ right | - t, \ sum \ limites_ {x \ in {S_ {escuro}}} {\ left | {{I_p} - {I_x}} \ right | - t}}} \ right) $$ display $$
Aqui
$ inline $ {S_ {bright}} $ inline $ e
$ inline $ {S_ {dark}} $ inline $ respectivamente, grupos de pixels são mais claros e mais escuros, t é o valor do brilho limite,
$ inline $ {I_p} $ inline $ - brilho do pixel central,
$ inline $ {{I_x}} $ inline $ - brilho do pixel no círculo. Você pode tentar o algoritmo com o
seguinte código . O código é retirado do OpenCV e liberado de todas as dependências, basta executá-lo.
Otimizando a árvore de decisão - FAST-ER
O FAST-ER [3] é um algoritmo dos mesmos autores que o anterior, um detector rápido é construído de forma semelhante, a sequência ótima de pontos também é pesquisada para comparação, uma árvore de decisão também é construída, mas usando um método diferente - o método de otimização.
Já entendemos que um detector pode ser representado como uma árvore de decisão. Se tivéssemos algum critério para comparar o desempenho de diferentes árvores, podemos maximizar esse critério classificando através de diferentes variantes de árvores. E, como tal critério, propõe-se o uso de "Repetibilidade".
A repetibilidade mostra quão bem os pontos singulares de uma cena são detectados de diferentes ângulos. Para um par de imagens, um ponto é chamado de "útil" se for encontrado em um quadro e, teoricamente, pode ser encontrado em outro, ou seja, Não bloqueie os elementos da cena. E o ponto é chamado de "repetido" (repetido), se também for encontrado no segundo quadro. Como a ótica da câmera não é ideal, o ponto no segundo quadro pode não estar no pixel calculado, mas em algum lugar próximo nas proximidades. Os desenvolvedores tiveram um bairro de 5 pixels. Definimos repetibilidade como a razão entre o número de pontos repetidos e o número de pontos úteis:
$$ display $$ R = \ frac {{{N_ {repetido}}}}} {{{N_ {Útil}}}} $$ display $$
Para encontrar o melhor detector, é usado um método de simulação de recozimento. Já existe um
excelente artigo sobre Habré sobre ele. Resumidamente, a essência do método é a seguinte:
- Alguma solução inicial para o problema é selecionada (no nosso caso, isso é algum tipo de árvore de detectores).
- A repetibilidade é considerada.
- A árvore é modificada aleatoriamente.
- Se a versão modificada é melhor pelo critério de repetibilidade, a modificação é aceita e, se for pior, pode ser aceita ou não, com alguma probabilidade, que depende de um número real chamado “temperatura”. À medida que o número de iterações aumenta, a temperatura cai para zero.
Além disso, a construção do detector agora envolve não 16 pontos do círculo, como antes, mas 47, mas o significado não muda:

De acordo com o método de recozimento simulado, definimos três funções:
• Função de custo k. No nosso caso, usamos a repetibilidade como valor. Mas há um problema. Imagine que todos os pontos em cada uma das duas imagens sejam detectados como singulares. Acontece que a repetibilidade é 100% - absurdo. Por outro lado, mesmo que tenhamos encontrado um ponto específico em duas figuras, e esses pontos coincidam - a repetibilidade também é de 100%, mas isso também não nos interessa. E, portanto, os autores propuseram usá-lo como critério de qualidade:
$$ display $$ k = \ left ({1 + {{\ left ({\ frac {{{w_r}}} {R}} \ right)} ^ 2}} \ right) \ left ({1 + \ frac {1} {N} \ sum \ limits_ {i = 1} {{{\ left ({\ frac {{{d_i}}}} {{{w_n}}}} à direita)} ^ 2}}} \ direita) \ esquerda ({1 + {{\ left ({\ frac {s} {{{w_s}}}} direita)} ^ 2}} \ right) $$ display $$
r é a repetibilidade
$ inline $ {{d_i}} $ inline $ É o número de ângulos detectados no quadro i, N é o número de quadros e s é o tamanho da árvore (número de vértices). W são parâmetros de método personalizado.]
• Função de mudança de temperatura ao longo do tempo:
exibição $$ $$ T \ esquerda (I \ direita) = \ beta \ exp \ left ({- \ frac {{\ alpha I}} {{{I _ {\ max}}}} \ right) exibição em $$ $$
onde
$ inline $ \ alpha, \ beta $ inline $ São os coeficientes, Imax é o número de iterações.
• Uma função que gera uma nova solução. O algoritmo faz modificações aleatórias na árvore. Primeiro, selecione algum vértice. Se o vértice selecionado é uma folha de uma árvore, com igual probabilidade, fazemos o seguinte:
- Substitua o vértice por uma subárvore aleatória com profundidade 1
- Alterar a classe desta planilha (pontos singular-não singulares)
Se NÃO for uma planilha:
- Substitua o número do ponto testado por um número aleatório de 0 a 47
- Substituir vértice por uma planilha por uma classe aleatória
- Troque duas subárvores deste vértice
A probabilidade P de aceitar a alteração na iteração I é:
$ inline $ P = \ exp \ left ({\ frac {{k \ left ({i - 1} \ right) - k \ left (i \ right)}} {T}} \ right) $ inline $
k é a função de custo, T é a temperatura, i é o número da iteração.
Essas modificações na árvore permitem o crescimento da árvore e sua redução. O método é aleatório, não garante que a melhor árvore seja obtida. Execute o método várias vezes, escolhendo a melhor solução. No artigo original, por exemplo, eles são executados 100 vezes por 100.000 iterações cada, o que leva 200 horas de tempo do processador. Como mostram os resultados, o resultado é melhor que o Tree FAST, especialmente em fotos com ruído.
BREVE descritor
Depois que os pontos singulares são encontrados, seus descritores são calculados, ou seja, conjuntos de características que caracterizam a vizinhança de cada ponto singular. BREVE [4] é um descritor heurístico rápido, construído a partir de 256 comparações binárias entre o brilho dos pixels em uma imagem
borrada . O teste binário entre os pontos x e y é definido da seguinte forma:
exibição $$ $$ \ tau \ left ({P, x, y} \ right): = \ left \ {{\ begin {array} {* {20} {c}} {1: p \ left (x \ direita) <p \ esquerda (y \ direita)} \\ {0: p \ esquerda (x \ direita) \ ge p \ esquerda (y \ direita)} \ final {matriz}} \ direita. $$ display $$

No artigo original, vários métodos para escolher pontos para comparações binárias foram considerados. Como se viu, uma das melhores maneiras é selecionar pontos aleatoriamente usando uma distribuição gaussiana em torno de um pixel central. Essa sequência aleatória de pontos é selecionada uma vez e não muda mais. O tamanho da vizinhança considerada do ponto é 31x31 pixels e a abertura de desfoque é 5.
O descritor binário resultante é resistente a mudanças na iluminação, distorção de perspectiva, é rapidamente calculado e comparado, mas é muito instável à rotação no plano da imagem.
ORB - rápido e eficiente
O desenvolvimento de todas essas idéias foi o algoritmo ORB (Oriented FAST and Rotated BRIEF) [5], no qual foi feita uma tentativa de melhorar o desempenho do BRIEF durante a rotação da imagem. Propõe-se primeiro calcular a orientação do ponto singular e, em seguida, realizar comparações binárias de acordo com essa orientação. O algoritmo funciona assim:
1) Os pontos de recurso são detectados usando a rápida árvore FAST na imagem original e em várias imagens da pirâmide de miniaturas.
2) Para os pontos detectados, a medida de Harris é calculada, os candidatos com um valor baixo da medida de Harris são descartados.
3) O ângulo de orientação do ponto singular é calculado. Para isso, os momentos de brilho da vizinhança do ponto singular são calculados primeiro:
$ inline $ {m_ {pq}} = \ sum \ limits_ {x, y} {{x ^ p} {y ^ q} Eu \ esquerda ({x, y} \ right)} $ inline $
coordenadas x, y - pixel, I - brilho. E então o ângulo de orientação do ponto singular:
$ inline $ \ theta = {\ rm {atan2}} \ left ({{m_ {01}}, {m_ {10}}} \ right) $ inline $
Tudo isso, os autores chamaram de "orientação centróide". Como resultado, obtemos uma certa direção para a vizinhança do ponto singular.
4) Tendo o ângulo de orientação do ponto singular, a sequência de pontos para comparações binárias no descritor BRIEF gira de acordo com esse ângulo, por exemplo:
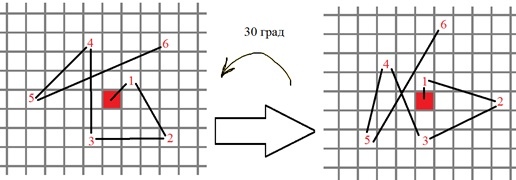
Mais formalmente, as novas posições para os pontos de teste binários são calculadas da seguinte maneira:
$$ display $$ \ left ({\ begin {array} {* {20} {c}} {{x_i} '} \\ {{y_i}'} \ end {array}} \ right) = R \ left (\ theta \ right) \ cdot \ left ({\ begin {array} {* {20} {c}} {{x_i}} \\ {{y_i}} \ end {array}} \ right) exibição em $$ $$
5) Com base nos pontos recebidos, o descritor binário BRIEF é calculado
E isso é ... não tudo! Há outro detalhe interessante no ORB que requer explicações separadas. O fato é que, no momento em que "giramos" todos os pontos singulares para um ângulo zero, a escolha aleatória de comparações binárias no descritor deixa de ser aleatória. Isso leva ao fato de que, em primeiro lugar, algumas comparações binárias se tornam dependentes umas das outras e, em segundo lugar, sua média não é mais igual a 0,5 (1 é mais leve, 0 é mais escuro quando a escolha foi aleatória e, em seguida, a média foi 0,5) e tudo isso reduz significativamente a capacidade do descritor de distinguir pontos singulares entre si.
Solução - você precisa selecionar os testes binários “corretos” no processo de aprendizado. Essa idéia dá o mesmo sabor que o treinamento em árvore para o algoritmo FAST-9. Suponha que já tenhamos vários pontos singulares. Considere todas as opções possíveis para testes binários. Se a vizinhança for 31 x 31 e o teste binário for um par de subconjuntos 5 x 5 (devido ao desfoque), existem várias opções para escolher N = (31-5) ^ 2. O algoritmo de pesquisa para testes "bons" é o seguinte:
- Calculamos o resultado de todos os testes para todos os pontos singulares
- Organize todo o conjunto de testes de acordo com a distância da média de 0,5
- Crie uma lista que conterá os testes "bons" selecionados, vamos chamar a lista R.
- Adicione a R o primeiro teste do conjunto classificado
- Nós fazemos o próximo teste e o comparamos com todos os testes em R. Se a correlação for maior que o limite, descartamos o novo teste, caso contrário, o adicionamos.
- Repita a etapa 5 até digitar o número necessário de testes.
Acontece que os testes são selecionados de modo que, por um lado, o valor médio desses testes seja o mais próximo possível de 0,5, por outro, para que a correlação entre os diferentes testes seja mínima. E é disso que precisamos. Compare como foi e como se tornou:
Felizmente, o algoritmo ORB é implementado na biblioteca OpenCV na classe cv :: ORB. Estou usando a versão 2.4.13. O construtor da classe aceita os seguintes parâmetros:
nfeatures - número máximo de pontos singulares
scaleFactor - multiplicador para a pirâmide de imagens, mais de um. O valor 2 implementa a pirâmide clássica.
nlevels - o número de níveis na pirâmide de imagens.
edgeThreshold - o número de pixels na borda da imagem em que pontos singulares não são detectados.
firstLevel - deixe zero.
WTA_K - o número de pontos necessários para um elemento do descritor. Se for igual a 2, o brilho de dois pixels selecionados aleatoriamente é comparado. É isso que é necessário.
scoreType - se 0, harris é usado como uma medida característica, caso contrário - a medida FAST (com base na soma dos módulos das diferenças de brilho nos pontos do círculo). A medida FAST é um pouco menos estável, mas mais rápida.
patchSize - o tamanho da vizinhança na qual os pixels aleatórios são selecionados para comparação. O código pesquisa e compara os pontos singulares em duas figuras, "templ.bmp" e "img.bmp"
Códigocv::Mat img_object=cv::imread("templ.bmp", 0); std::vector<cv::KeyPoint> keypoints_object, keypoints_scene; cv::Mat descriptors_object, descriptors_scene; cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
Se alguém ajudou a entender a essência dos algoritmos, não é em vão. Para todo o Habr.
Referências:
1.
Pontos e linhas de fusão para rastreamento de alto desempenho2.
Aprendizado de máquina para detecção de canto em alta velocidade3.
Mais rápido e melhor: uma abordagem de aprendizado de máquina para detecção de cantos4.
RESUMO: Recursos elementares independentes robustos binários5.
ORB: uma alternativa eficiente para SIFT ou SURF