Expressividade é uma propriedade interessante de linguagens de programação. Simplesmente combinando expressões, você pode obter resultados impressionantes. Algumas línguas rejeitam deliberadamente a idéia de expressividade, mas Kotlin definitivamente não é essa linguagem.
Usando construções básicas de linguagem e um pouco de açúcar, tentaremos recriar o SQL na sintaxe do Kotlin o mais próximo possível.

Link do GitHub para os impacientes
Nosso objetivo é ajudar o programador a capturar um subconjunto específico de erros no estágio de compilação. Kotlin, sendo uma linguagem fortemente tipada, nos ajudará a eliminar expressões inválidas na estrutura da consulta SQL. Como bônus, obteremos mais proteção contra erros de digitação e ajuda do IDE ao escrever solicitações. Não é possível corrigir completamente as falhas do SQL, mas é possível corrigir algumas áreas problemáticas.
Este artigo informará sobre a biblioteca Kotlin, que permite escrever consultas SQL na sintaxe do Kotlin. Além disso, examinamos o interior da biblioteca para entender como isso funciona.
Pouco de teoria
SQL significa Structured Query Language, ou seja, a estrutura das consultas está presente, embora a sintaxe seja ruim - a linguagem foi criada para que pudesse ser usada por qualquer usuário que nem sequer possua habilidades de programação.
No entanto, no SQL existe uma base bastante poderosa na forma da teoria dos bancos de dados relacionais - tudo é muito lógico lá. Para entender a estrutura das consultas, passamos a uma seleção simples:
SELECT id, name
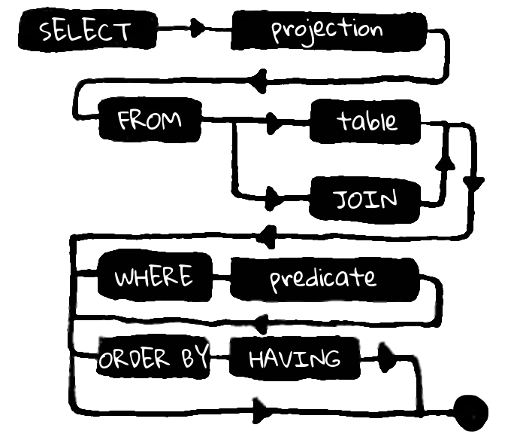
O que é importante entender: a solicitação consiste em três partes consecutivas. Cada uma dessas partes, em primeiro lugar, depende da anterior e, em segundo lugar, implica um conjunto limitado de expressões para continuar a solicitação. De fato, não é bem assim: a expressão FROM aqui é claramente primária em relação ao SELECT, porque o conjunto de campos que podemos escolher depende da tabela na qual a seleção é feita, mas não vice-versa.
Portando para Kotlin
Portanto, FROM é primário em relação a qualquer outra construção de linguagem de consulta. É a partir dessa expressão que surgem todas as opções possíveis para continuar a consulta. No Kotlin, refletimos isso através da função from (T), que aceita um objeto de entrada, que é uma tabela que possui um conjunto de colunas.
object Employees : Table("employees") { val id = Column("id") val name = Column("name") val organizationId = Column("organization_id") }
A função retornará um objeto que contém métodos que refletem a possível continuação da solicitação. A construção from sempre vem primeiro, antes de qualquer outra expressão, por isso envolve um grande número de extensões, incluindo o SELECT final (em oposição ao SQL, onde SELECT sempre vem antes de FROM). O código equivalente à consulta SQL acima terá a seguinte aparência:
from(Employees) .where { e -> e.organizationId eq 1 } .select { e -> e.id .. e.name }
Curiosamente, dessa maneira, podemos evitar SQL inválido, mesmo em tempo de compilação. Cada expressão, cada chamada de método na cadeia implica um número limitado de extensões. Podemos controlar a validade da solicitação usando o idioma Kotlin. Como um exemplo, a expressão where não implica uma continuação na forma de outro where e, além disso, de, mas o groupBy, tendo as construções orderBy, limit, offset e final select são todos válidos.
Lambdas transmitidos como argumentos para as instruções where e select são projetados para construir o predicado e a projeção, respectivamente (mencionamos-os anteriormente). Uma tabela é passada para a entrada lambda para que você possa acessar as colunas. É importante que a segurança do tipo seja mantida também nesse nível - com a ajuda da sobrecarga do operador, podemos garantir que o predicado acabe sendo uma expressão pseudo-booleana que não pode ser compilada se houver um erro de sintaxe ou um erro relacionado ao tipo. O mesmo vale para a projeção.
fun where(predicate: (T) -> Predicate): WhereClause<T> fun select(projection: (T) -> Iterable<Projection>): SelectStatement<T>
Aderir
Os bancos de dados relacionais permitem trabalhar com muitas tabelas e os relacionamentos entre elas. Seria bom dar ao desenvolvedor a oportunidade de trabalhar com o JOIN em nossa biblioteca. Felizmente, o modelo relacional se encaixa bem com tudo o que foi descrito anteriormente - você só precisa adicionar o método join, que adicionará uma segunda tabela à nossa expressão.
fun <T2: Table> join(table2: T2): JoinClause<T, T2>
JOIN, nesse caso, terá métodos semelhantes aos fornecidos pela expressão FROM, com a única diferença de que as lambdas de projeção e predicado terão dois parâmetros cada para poder acessar as colunas de ambas as tabelas.
from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } .where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name }
Gerenciamento de dados
A linguagem de manipulação de dados é uma ferramenta de linguagem SQL que, além de consultar tabelas, permite inserir, modificar e excluir dados. Esses projetos se encaixam bem com o nosso modelo. Para dar suporte à atualização e exclusão, precisamos apenas suplementar as expressões from e where com uma variante com a chamada dos métodos correspondentes. Para dar suporte à inserção, introduzimos uma função adicional.
from(Employees) .where { e -> e.id eq 1 } .update { e -> e.name("John Doe") } from(Employees) .where { e -> e.id eq 0 } .delete() into(Employees) .insert { e -> e.name("John Doe") .. e.organizationId(1) }
Descrição dos dados
O SQL trabalha com dados estruturados na forma de tabelas. As tabelas requerem uma descrição antes de trabalhar com elas. Essa parte do idioma é chamada de linguagem de definição de dados.
As instruções CREATE TABLE e DROP TABLE são implementadas da mesma forma - a função over servirá como ponto de partida.
over(Employees) .create { integer(it.id).primaryKey(autoIncrement = true).. text(it.name).unique().notNull().. integer(it.organizationId).foreignKey(references = Organizations.id) }
over(Employees).drop()