Depois de ler o artigo “
Tradução automática automática do Google”, lembrei-me da mais recente tradução automática de falha épica do Google em execução na Internet recentemente. Quem não pode esperar muito, imediatamente chegamos ao final do artigo.
Bem, para começar, um pouco de teoria:
O GNMT é o sistema de tradução
automática neural (
NMT ) do Google que usa uma rede neural (
ANN ) para aumentar a precisão e a velocidade da tradução e, em particular, criar opções de tradução melhores e mais naturais para o texto no Google Translate.
No caso do GNMT, este é o chamado método de tradução baseado em exemplo (
EBMT ), ou seja,
A RNA subjacente ao método aprende com milhões de exemplos de tradução e, diferentemente de outros sistemas, esse método permite a chamada
tradução zero-shot , ou seja, traduzir de um idioma para outro sem exemplos explícitos para este par de idiomas específicos. no processo de aprendizagem (na amostra de treinamento).
 Fig. 1. Tradução Zero-Shot
Fig. 1. Tradução Zero-ShotAlém disso, o GNMT é projetado principalmente para melhorar a tradução de frases e sentenças, porque apenas na tradução contextual, você não pode usar a versão literal da tradução e, com frequência, a frase é traduzida de maneira completamente diferente.
Além disso, voltando à tradução zero, o Google está tentando destacar algum componente comum que é válido para vários idiomas ao mesmo tempo (ao procurar dependências e ao criar relacionamentos para frases e frases).
Por exemplo, na Figura 2, essa "comunidade" interlíngua é mostrada entre todos os pares possíveis para japonês, coreano e inglês.
 Fig. 2. Interlíngua. Apresentação tridimensional de dados de rede para japonês, coreano e inglês
Fig. 2. Interlíngua. Apresentação tridimensional de dados de rede para japonês, coreano e inglês .
A parte (a) mostra a "geometria" geral dessas traduções, onde os pontos são coloridos por significado (e a mesma cor para o mesmo significado em vários pares de idiomas).
A parte (b) mostra um aumento em um dos grupos, parte © nas cores do idioma original.
O GNMT usa o grande aprendizado profundo da
RNA (
DNN ), que, aprendido com milhões de exemplos, deve melhorar a qualidade da tradução, aplicando uma aproximação abstrata contextual para a opção de tradução mais adequada. Grosso modo, ele escolhe o melhor resultado, no sentido da gramática mais apropriada da linguagem humana, ao mesmo tempo em que leva em consideração a semelhança na construção de links, frases e sentenças para vários idiomas (ou seja, destacando e ensinando separadamente o modelo ou as camadas da interlíngua).
No entanto, o DNN, tanto no processo de aprendizado quanto no processo de trabalho, geralmente depende de inferência estatística (probabilística) e raramente é vinculado por algoritmos não probabilísticos adicionais. I.e. Para avaliar o melhor resultado possível que saiu do variador, a opção estatisticamente melhor (provável) será selecionada.
Tudo isso, naturalmente, depende adicionalmente da qualidade da amostra de treinamento (e / ou da qualidade dos algoritmos no caso de um modelo de autoaprendizagem).
Dado o método de tradução do zero-shot e lembrando-se de algum componente comum (interlíngua), na presença de alguma conexão lógica profunda positiva para um idioma e na ausência de componentes negativos para outros idiomas, algum erro abstrato surgiu no processo de aprendizagem e, como resultado, a tradução de uma determinada frase para um idioma provavelmente será repetida para outros idiomas ou mesmo pares de idiomas.
Falha épica realmente nova
Todas as imagens são clicáveis (como prova na página correspondente do Google Translate).Alemão: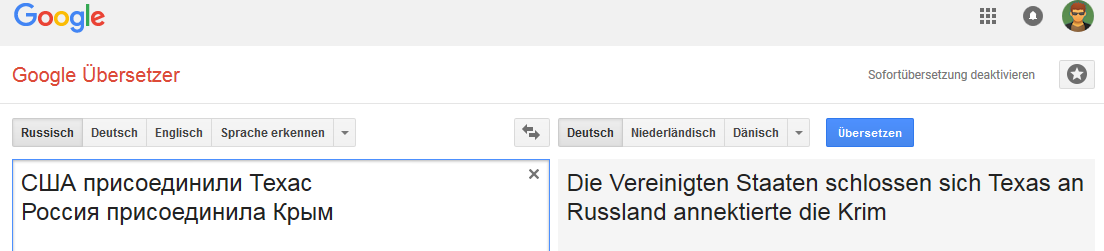 Inglês:
Inglês: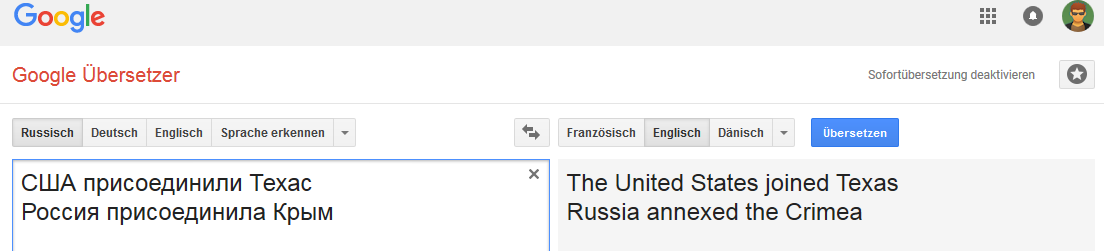 Holandês:
Holandês: Dinamarquês:
Dinamarquês: Francês:
Francês:
Etc.
Em vez de uma conclusão
A conexão é estável para a palavra Rússia (no sentido em que, quando a Rússia é substituída, por exemplo, pelo Império Russo, a opção "transferência" muda).
E não é muito estável com certas alterações em frases que não são típicas para tradução para o inglês, mas comuns, por exemplo, para russo, alemão e holandês.
Infelizmente, isso está longe de ser o único caso e a Internet está repleta de todos os tipos de erros do Google Tradutor.
E parece-me que uma parte considerável dos erros existentes se manifesta devido a uma combinação de vários fatores, desde a qualidade da amostra de treinamento até a qualidade dos algoritmos de análise semântica e morfológica para um idioma específico (e o modelo de aprendizado em particular).
Certa vez, um colega sugeriu participar do Desafio de Normalização de Texto do Google (para russo e inglês) no kaggle ...
Antes de concordar, fiz uma pequena análise da qualidade da amostra do teste de treinamento para todas as classes de fichas para os dois idiomas ... e, como resultado, me recusei a participar, porque quanto mais eu cavava, mais forte era a sensação de que a competição será como uma loteria ou quem ganhar ganhará com mais precisão, você poderá repetir todos os erros cometidos durante a criação semi-manual do conjunto de treinamento do Google.
Eu até queria escrever um artigo sobre o tema "Como jogar facilmente 50K ...", mas tempo - tudo bem.
Se alguém estiver subitamente interessado - tentarei entender um pouco.
[UPD] Por que isso é realmente um arquivo? Sem se distrair com a letra, o subtexto “político” e todo tipo de tentativa de justificar “uma pessoa traduziria dessa maneira”, etc. tópicos.
1. Esta é uma tradução errada. O ponto.
2. Neste caso ilustrativo, o GNMT mostra uma completa ausência de qualquer modelo de classificação (no sentido de
CADM , no qual o Google deve brilhar, porque eles têm muitos dados de todos os lugares). Na medida em que os sujeitos em ambos os casos são países / estados, e os suplementos são entidades geográficas (território).
Mesmo a regra mais estúpida de plausibilidade de uma classificação difusa do K-nn nunca teria cometido um erro tão grande. Já estamos em silêncio sobre algoritmos modernos para a classificação e construção de relacionamentos (semânticos).
Como o ditado não é nada pessoal, matemática simples ... Bem, se o Google decidiu indiscriminadamente alimentar sua rede com recortes da imprensa dos tablóides, então eu tenho más notícias para ele.
PS No entanto, como um professor que eu respeitei uma vez me disse: "Às vezes é muito difícil provar ao pica-pau que ele é um pica-pau, especialmente se ele tem certeza de que é mais esperto do que um professor".