
Olá Habr! Meu nome é Alexey Pristavko, sou o diretor de projetos da Web no DataLine. Meu artigo de hoje é sobre como corrigir ou impedir problemas de desempenho de back-end de aplicativos da web.
Isso se concentrará em como otimizar aplicativos da Web que sofrem de problemas crônicos de escalabilidade, desempenho ou confiabilidade.
Qualquer pessoa interessada - bem-vindo sob o corte!
Terminologia
Vamos começar com uma olhada na terminologia. Falando sobre o desempenho de projetos ou sistemas da web, quero dizer principalmente o back-end e o componente do servidor. O que acontece ao carregar páginas em um navegador é uma história completamente diferente, que, provavelmente, será dedicada a um artigo separado.
- A medida de desempenho do aplicativo será o número de solicitações processadas por segundo (RPS) e sua velocidade de execução (TTFB - Time to First Byte).
- Assim, por escalabilidade do sistema, queremos dizer um conjunto de oportunidades para aumentar o RPS.
Agora sobre confiabilidade. Aqui é necessário separar dois conceitos: tolerância a falhas e tolerância a desastres.
- Resiliência a falhas - a capacidade de um sistema falhar se um ou mais servidores falharem em continuar trabalhando dentro dos parâmetros necessários.
- Os sistemas com redundância de backup completo (o chamado segundo ombro) e capazes de funcionar sem uma forte redução com a falha completa de um dos data centers são considerados resistentes a desastres .
Ao mesmo tempo, um sistema tolerante a desastres é um sistema à prova de falhas. Uma situação em que um sistema tolerante a desastres, mas não tolerante a falhas, continua trabalhando em apenas um “ombro” é bastante normal. Mas se um dos servidores falhar, o sistema também falhará.
Agora que descobrimos os principais conceitos e atualizamos a terminologia atual, é hora de passar diretamente para o básico de otimização e hacks de vida.
Por onde começar a otimização

Como entender por onde começar a otimização? Antes de se apressar para otimizar, respire fundo e gaste tempo pesquisando o aplicativo.
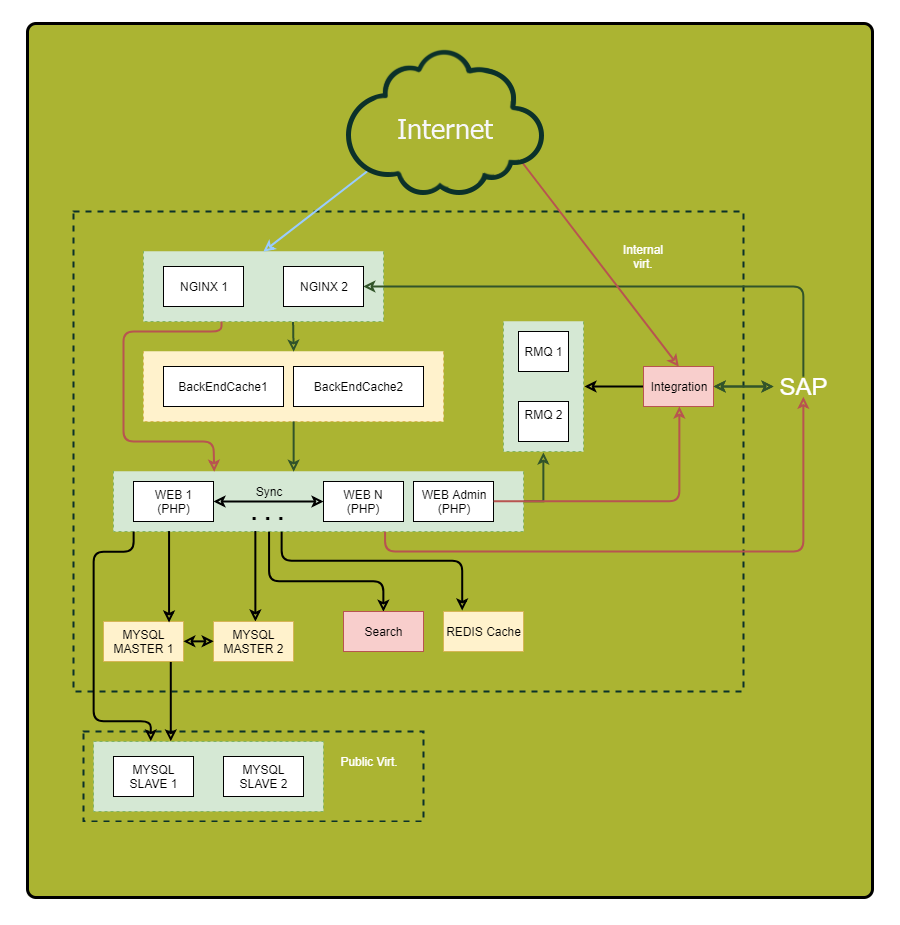
Certifique-se de desenhar um diagrama detalhado. Exiba nele todos os componentes do aplicativo e seus relacionamentos. Depois de examinar esse esquema, você pode descobrir vulnerabilidades anteriormente imperceptíveis e possíveis pontos de falha.
“O que? Onde Quando? - otimizar consultas
Preste atenção especial às solicitações síncronas. Deixe-me lembrá-lo, essas são solicitações quando enviamos uma solicitação no mesmo segmento e aguardamos uma resposta. É aqui que estão os motivos dos freios graves quando algo dá errado do outro lado. Portanto, se você puder reduzir o número de solicitações síncronas ou substituí-las por solicitações assíncronas, faça-o.
Aqui estão alguns truques para ajudá-lo a acompanhar suas solicitações:
- Atribua um identificador exclusivo para cada solicitação recebida. O Nginx possui uma variável interna $ request_id para isso. Passe o identificador nos cabeçalhos no back-end e grave em todos os logs. Assim, você pode rastrear convenientemente solicitações.
- Registre não apenas o final da solicitação no componente externo, mas também seu início. Então você mede a duração real da chamada externa. Pode diferir significativamente do que você vê no sistema remoto, por exemplo, devido a problemas de rede ou freios de DNS.
Então, os dados são coletados. Agora vamos analisar os pontos problemáticos. Definir:
- Onde fica mais tempo?
- De onde vem a maioria dos pedidos?
- De onde vêm os pedidos mais longos?
Como resultado, você obterá uma lista das seções mais interessantes do sistema para otimização.
Dica: Se algum ponto "coletar" muitas consultas pequenas, tente combiná-las em uma consulta grande para reduzir a sobrecarga. Os resultados de consultas longas geralmente fazem sentido no cache.
Armazenamos em cache sabiamente
Existem regras gerais de cache nas quais você deve confiar ao otimizar:
- Quanto mais próximo o cache do consumidor, mais rápido o trabalho. Para o aplicativo, o local "mais próximo" será a RAM. Para o usuário, seu navegador.
- O armazenamento em cache acelera a aquisição de dados e reduz a carga na fonte.
Se dez servidores da Web fizerem as mesmas consultas ao banco de dados, um cache intermediário centralizado, por exemplo no Redis, fornecerá uma porcentagem maior de ocorrências (em comparação com o cache local) e reduzirá a carga geral no banco de dados, o que melhorará significativamente a imagem geral.
Dica 1: Faça o cache de componentes da página finalizada no lado do Nginx usando o Edge Side Include. Ele se adapta bem à arquitetura de microsserviço / SOA e descarrega o sistema como um todo, melhorando consideravelmente a velocidade de resposta.
Dica 2: acompanhe o tamanho dos objetos no cache, a taxa de acertos e os volumes de gravação / leitura. Quanto maior o objeto, mais tempo será necessário para processar. Se você escreve no cache com mais frequência ou mais do que lê, esse cache não é seu amigo. Vale a pena remover ou pensar em aumentar sua eficácia.
Dica 3: use seus próprios caches de banco de dados sempre que possível. A configuração adequada pode acelerar o trabalho.
Carregar perfis
Passamos para carregar perfis. Como você sabe, existem dois tipos principais: OLAP e OLTP.
- Para OLAP (Online Analytical Processing), a quantidade de tráfego gasto por segundo é importante.
- Para o OLTP (Online Transaction Processing), o indicador principal é a velocidade de resposta, tempos de milissegundos.
Na maioria das vezes, é eficaz separar esses dois tipos de carga. No mínimo, você precisará de um ajuste separado do banco de dados e, possivelmente, de outros componentes do sistema.
Dica: Normalmente, as solicitações de leitura do painel do administrador são processadas usando o tipo OLAP. Crie uma cópia separada do banco de dados e um servidor web para esta tarefa descarregar o sistema principal.
Bases de dados

Portanto, abordamos naturalmente um dos estágios mais difíceis da otimização - a otimização do banco de dados.
Deixe-me lembrá-lo da regra geral: quanto menor o banco de dados, mais rápido ele funciona. A própria organização do banco de dados é crucial quando se trata de velocidade.
Se possível, armazene
dados históricos , logs de aplicativos e dados
usados com freqüência em diferentes bancos de dados. Melhor ainda, publique-os em diferentes servidores. Isso não apenas facilitará a vida útil do banco de dados principal, mas também fornecerá mais espaço para otimização adicional; por exemplo, em alguns casos, permitirá o uso de índices diferentes para cargas diferentes. Além disso, a “uniformidade” da carga simplifica a vida útil do planejador e do otimizador de consultas do servidor de banco de dados.
E novamente sobre a importância do planejamento
Para não confundir a otimização onde ela não é realmente necessária, escolha o hardware com base nas tarefas.
- Para solicitações pequenas, mas frequentes, é melhor usar mais núcleos de processador.
- Para solicitações pesadas - menos núcleos com maior velocidade de clock.
Tente colocar o volume de trabalho do banco de dados na RAM. Se isso não for possível ou se houver um grande número de solicitações de gravação, é hora de transferir os bancos de dados para SSDs. Eles fornecerão um aumento significativo na velocidade de trabalho com o disco.
Dimensionamento

Acima, descrevi a mecânica chave para melhorar o desempenho do aplicativo sem aumentar seus recursos físicos.
Agora, falaremos sobre como escolher uma estratégia de dimensionamento e aumentar a resiliência.
Existem dois tipos de dimensionamento do sistema:
- vertical - o crescimento de recursos, mantendo o número de entidades;
- horizontal - um aumento no número de entidades.
Cresça alto
Vamos começar escolhendo uma estratégia de dimensionamento vertical.
Primeiro, considere o
aumento da energia do sistema . Se o seu sistema funcionar em um servidor, você deverá escolher entre aumentar a capacidade do servidor atual ou comprar outro.
Pode parecer que a primeira opção é mais fácil e segura. Mas será mais ambicioso comprar mais um servidor e receber uma grande tolerância a falhas como um bônus à produtividade. Eu falei sobre isso no começo do artigo.
Se o seu sistema possui vários servidores e a opção é aumentar a capacidade dos existentes ou comprar um pouco mais, preste atenção no lado financeiro. Por exemplo, um servidor poderoso pode ser mais caro que dois 50% "mais fraco". Portanto, será razoável considerar a segunda opção de compromisso. Ao mesmo tempo, com um grande número de servidores, a proporção de desempenho, consumo de energia e o custo de um rack completo é crucial.
Crescer
A escala horizontal é uma história sobre tolerância a falhas e cluster. No caso geral, quanto mais instâncias de uma entidade tivermos, maior a tolerância a falhas de toda a solução.
Provavelmente, a primeira coisa que você deseja escalar são os
servidores de aplicativos . O primeiro obstáculo para isso é a organização do trabalho com fontes de dados centralizadas. Além dos bancos de dados, também são dados da sessão e conteúdo estático. Aqui está o que eu recomendo que você faça:
- Para armazenar sessões, use o Couchbase, não o habitual Memcached, pois ele funciona com o mesmo protocolo, mas, diferentemente do memcached, ele oferece suporte ao cluster.
- Todas as estáticas , especialmente grandes volumes de imagens e documentos, são armazenadas separadamente e servidas usando o Nginx, e não a partir do código do aplicativo. Isso economizará dinheiro em fluxos e simplificará o gerenciamento da infraestrutura.
"Puxando" o banco de dados
Difícil de dimensionar bancos de dados. Existem duas técnicas principais para isso: fragmentação e replicação. Considere-os.
Durante a
replicação, adicionamos cópias completamente idênticas do banco de dados ao sistema, enquanto
sharding , partes separadas logicamente, shards. Ao mesmo tempo, é altamente desejável realizar sharding em paralelo com a replicação (replicação) de cada shard, para não perder a tolerância a falhas.
Lembre-se: geralmente um cluster de banco de dados consiste em um nó principal que assume o fluxo de gravação e vários nós escravos usados para leitura. Do ponto de vista da tolerância a falhas, isso é um pouco melhor que um único servidor, pois a tolerância geral a falhas é determinada pelo elemento menos estável do sistema.
Esquemas com mais de dois assistentes de banco de dados (topologia em anel) sem confirmar o registro em cada servidor, muitas vezes sofrem inconsistência. No caso de uma falha de um dos servidores, será extremamente difícil restaurar a integridade lógica dos dados no cluster.
Dica: Se, no seu caso, não for racional ter vários servidores principais, considere a possibilidade arquitetônica do sistema funcionar sem um mestre por pelo menos uma hora. Em caso de acidente, isso permitirá que você substitua o servidor sem tempo de inatividade de todo o sistema.
Dica: Se você precisar manter mais de 2 mestres de banco de dados, recomendo que considere as soluções NoSQL, pois muitas delas possuem mecanismos internos para colocar os dados em um estado consistente.
Na busca pela tolerância a falhas, em nenhum caso, não esqueça que a replicação protege você
somente contra falhas físicas do servidor . Ele não será salvo da corrupção de dados lógicos devido a erro do usuário.
Lembre-se: Todos os dados importantes devem ser armazenados em backup e armazenados como uma cópia independente e não editável.
Em vez de uma conclusão
Por fim, algumas dicas de desempenho para fazer backup:
Dica 1: extraia dados de uma réplica de banco de dados separada para não sobrecarregar o servidor ativo.
Dica 2: Tenha em mãos uma réplica adicional, ligeiramente "atrasada" no tempo do banco de dados. Em caso de acidente, isso ajudará a reduzir a quantidade de dados perdidos.
Os métodos e técnicas apresentados neste artigo nunca devem ser usados às cegas, sem analisar a situação atual e entender o que você deseja alcançar. Você pode encontrar "super otimização", e o sistema resultante será apenas 10% mais rápido, mas 50% mais vulnerável a acidentes.
Isso é tudo. Se você tiver alguma dúvida, terei prazer em respondê-las nos comentários.