No festival de dados 2 em Minsk, Vladimir Iglovikov, engenheiro de visão de máquina da Lyft, observou
perfeitamente que a melhor maneira de aprender Data Science é participar de competições, executar soluções de outras pessoas, combiná-las, obter resultados e mostrar seu trabalho. Na verdade, dentro da estrutura desse paradigma, decidi examinar mais de perto a
competição de avaliação de risco de crédito ao crédito imobiliário e explicar (para iniciantes, cientistas e, antes de tudo, para mim) como analisar adequadamente esses conjuntos de dados e criar modelos para eles.
(foto
daqui )

O Grupo Home Credit Group é um grupo de bancos e organizações de crédito não bancário que conduz operações em 11 países (incluindo a Rússia como Home Credit and Finance Bank LLC). O objetivo da competição é criar uma metodologia para avaliar a capacidade creditícia dos tomadores de empréstimos que não possuem histórico de crédito. O que parece bastante nobre - os mutuários dessa categoria geralmente não conseguem crédito do banco e são forçados a recorrer a golpistas e microempréstimos. É interessante que o cliente não defina requisitos de transparência e interpretabilidade do modelo (como é geralmente o caso dos bancos), você pode usar qualquer coisa, mesmo uma rede neural.
A amostra de treinamento consiste em mais de 300 mil registros, existem muitos sinais - 122, entre os quais muitos categóricos (não numéricos). As placas descrevem o mutuário em detalhes suficientes, até o material do qual são feitas as paredes de sua casa. Parte dos dados está contida em 6 tabelas adicionais (dados da agência de crédito, saldo do cartão de crédito e empréstimos anteriores); esses dados também devem ser processados de alguma forma e carregados nas principais.
A competição parece uma tarefa de classificação padrão (1 no campo TARGET significa alguma dificuldade com pagamentos, 0 significa nenhuma dificuldade). No entanto, não é 0/1 que deve ser previsto, mas a probabilidade de problemas (que, aliás, podem ser facilmente resolvidos pelos métodos de previsão de probabilidade predict_proba que todos os modelos complexos possuem).
À primeira vista, o conjunto de dados é bastante padrão para tarefas de aprendizado de máquina, os organizadores ofereceram um grande prêmio de US $ 70 mil. Como resultado, mais de 2.600 equipes estão participando da competição hoje, e a batalha é em milésimos de um por cento. No entanto, por outro lado, essa popularidade significa que o conjunto de dados foi estudado para cima e para baixo e muitos kernels foram criados com o bom EDA (Exploratory Data Analisys - pesquisa e análise de dados na rede, incluindo gráficos), Engenharia de recursos (trabalho com atributos) e com modelos interessantes. (O kernel é um exemplo de trabalho com um conjunto de dados que qualquer um pode criar para mostrar seu trabalho a outros malabaristas.)
Os núcleos merecem atenção:
Para trabalhar com dados, geralmente é recomendado o seguinte plano, que tentaremos seguir.
- Entendendo o problema e familiarizando-se com os dados
- Limpeza e formatação de dados
- EDA
- Modelo base
- Melhoria do modelo
- Interpretação do modelo
Nesse caso, é necessário levar em consideração o fato de que os dados são bastante extensos e não podem ser sobrecarregados imediatamente, faz sentido agir em etapas.
Vamos começar importando as bibliotecas que precisamos na análise para trabalhar com dados na forma de tabelas, criar gráficos e trabalhar com matrizes.
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline
Faça o download dos dados. Vamos ver o que todos nós temos. Este local no diretório "../input/", a propósito, está conectado ao requisito de colocar seus kernels no Kaggle.
import os PATH="../input/" print(os.listdir(PATH))
['application_test.csv', 'application_train.csv', 'bureau.csv', 'bureau_balance.csv', 'credit_card_balance.csv', 'HomeCredit_columns_description.csv', 'installments_payments.csv', 'POS_CASH_balance.csv', 'previous_application.csv']Existem 8 tabelas com dados (sem contar a tabela HomeCredit_columns_description.csv, que contém uma descrição dos campos), que são interconectadas da seguinte maneira:
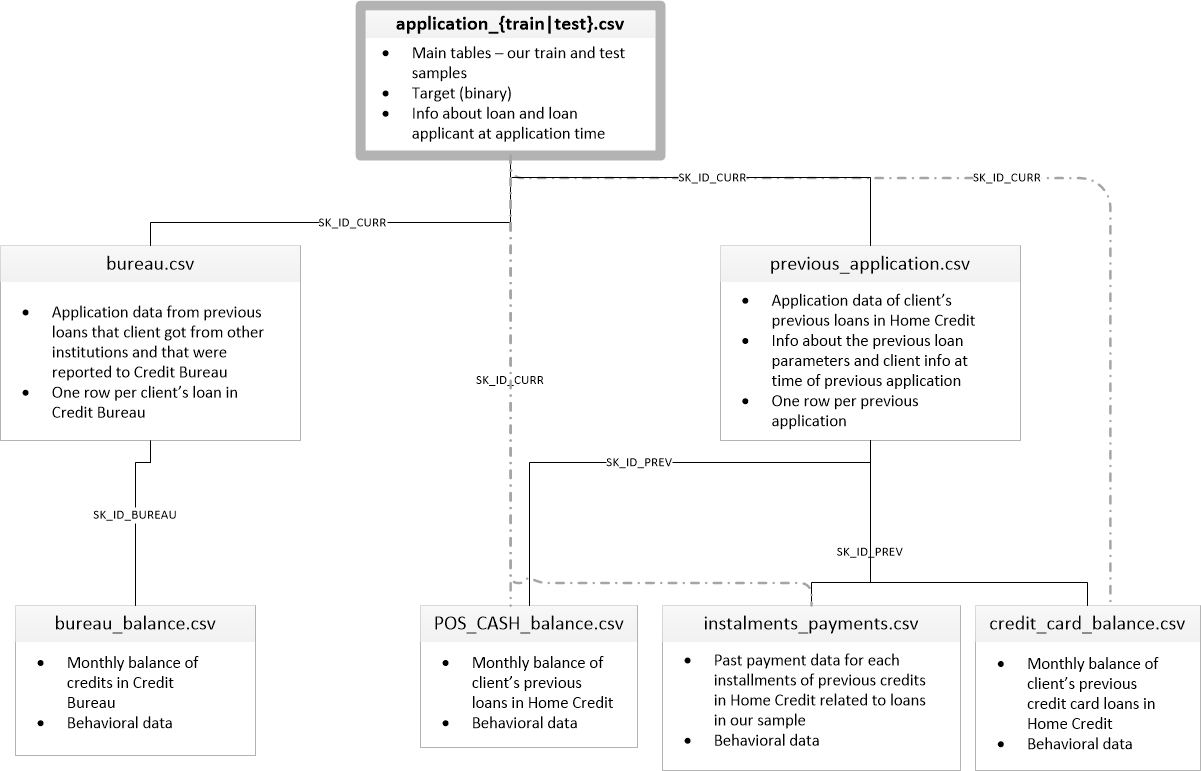
application_train / application_test: dados mestre, o mutuário é identificado pelo campo SK_ID_CURR
bureau: dados sobre empréstimos anteriores de outras instituições de crédito de uma agência de crédito
bureau_balance: dados mensais sobre empréstimos anteriores. Cada linha é o mês de utilização do empréstimo
previous_application: solicitações anteriores para empréstimos em Crédito à habitação, cada uma possui um campo exclusivo SK_ID_PREV
POS_CASH_BALANCE: dados mensais sobre empréstimos em crédito imobiliário, com emissão de caixa e empréstimos para compra de mercadorias
credit_card_balance: dados mensais do saldo do cartão de crédito em Crédito à habitação
parcelamentos_pagamento: histórico de pagamentos de empréstimos anteriores no crédito residencial.
Vamos primeiro focar na principal fonte de dados e ver quais informações podem ser extraídas dela e quais modelos construir. Faça o download dos dados básicos.
- app_train = pd.read_csv (PATH + 'application_train.csv',)
- app_test = pd.read_csv (PATH + 'application_test.csv',)
- print ("formato do conjunto de treinamento:", app_train.shape)
- print ("formato de amostra de teste:", app_test.shape)
- formato de amostra de treinamento: (307511, 122)
- formato de amostra de teste: (48744, 121)
No total, temos 307 mil registros e 122 sinais na amostra de treinamento e 49 mil registros e 121 sinais no teste. Obviamente, a discrepância se deve ao fato de não haver um atributo de destino TARGET na amostra de teste, e nós a preveremos.
Vamos dar uma olhada nos dados
pd.set_option('display.max_columns', None)
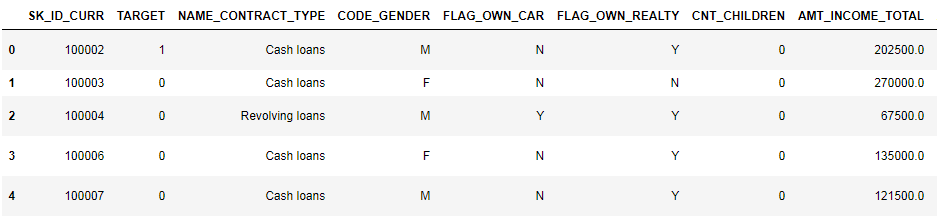
(primeiras 8 colunas mostradas)
É muito difícil assistir a dados nesse formato. Vejamos a lista de colunas:
app_train.info(max_cols=122)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 entries, 0 to 307510
Data columns (total 122 columns):
SK_ID_CURR 307511 non-null int64
TARGET 307511 non-null int64
NAME_CONTRACT_TYPE 307511 non-null object
CODE_GENDER 307511 non-null object
FLAG_OWN_CAR 307511 non-null object
FLAG_OWN_REALTY 307511 non-null object
CNT_CHILDREN 307511 non-null int64
AMT_INCOME_TOTAL 307511 non-null float64
AMT_CREDIT 307511 non-null float64
AMT_ANNUITY 307499 non-null float64
AMT_GOODS_PRICE 307233 non-null float64
NAME_TYPE_SUITE 306219 non-null object
NAME_INCOME_TYPE 307511 non-null object
NAME_EDUCATION_TYPE 307511 non-null object
NAME_FAMILY_STATUS 307511 non-null object
NAME_HOUSING_TYPE 307511 non-null object
REGION_POPULATION_RELATIVE 307511 non-null float64
DAYS_BIRTH 307511 non-null int64
DAYS_EMPLOYED 307511 non-null int64
DAYS_REGISTRATION 307511 non-null float64
DAYS_ID_PUBLISH 307511 non-null int64
OWN_CAR_AGE 104582 non-null float64
FLAG_MOBIL 307511 non-null int64
FLAG_EMP_PHONE 307511 non-null int64
FLAG_WORK_PHONE 307511 non-null int64
FLAG_CONT_MOBILE 307511 non-null int64
FLAG_PHONE 307511 non-null int64
FLAG_EMAIL 307511 non-null int64
OCCUPATION_TYPE 211120 non-null object
CNT_FAM_MEMBERS 307509 non-null float64
REGION_RATING_CLIENT 307511 non-null int64
REGION_RATING_CLIENT_W_CITY 307511 non-null int64
WEEKDAY_APPR_PROCESS_START 307511 non-null object
HOUR_APPR_PROCESS_START 307511 non-null int64
REG_REGION_NOT_LIVE_REGION 307511 non-null int64
REG_REGION_NOT_WORK_REGION 307511 non-null int64
LIVE_REGION_NOT_WORK_REGION 307511 non-null int64
REG_CITY_NOT_LIVE_CITY 307511 non-null int64
REG_CITY_NOT_WORK_CITY 307511 non-null int64
LIVE_CITY_NOT_WORK_CITY 307511 non-null int64
ORGANIZATION_TYPE 307511 non-null object
EXT_SOURCE_1 134133 non-null float64
EXT_SOURCE_2 306851 non-null float64
EXT_SOURCE_3 246546 non-null float64
APARTMENTS_AVG 151450 non-null float64
BASEMENTAREA_AVG 127568 non-null float64
YEARS_BEGINEXPLUATATION_AVG 157504 non-null float64
YEARS_BUILD_AVG 103023 non-null float64
COMMONAREA_AVG 92646 non-null float64
ELEVATORS_AVG 143620 non-null float64
ENTRANCES_AVG 152683 non-null float64
FLOORSMAX_AVG 154491 non-null float64
FLOORSMIN_AVG 98869 non-null float64
LANDAREA_AVG 124921 non-null float64
LIVINGAPARTMENTS_AVG 97312 non-null float64
LIVINGAREA_AVG 153161 non-null float64
NONLIVINGAPARTMENTS_AVG 93997 non-null float64
NONLIVINGAREA_AVG 137829 non-null float64
APARTMENTS_MODE 151450 non-null float64
BASEMENTAREA_MODE 127568 non-null float64
YEARS_BEGINEXPLUATATION_MODE 157504 non-null float64
YEARS_BUILD_MODE 103023 non-null float64
COMMONAREA_MODE 92646 non-null float64
ELEVATORS_MODE 143620 non-null float64
ENTRANCES_MODE 152683 non-null float64
FLOORSMAX_MODE 154491 non-null float64
FLOORSMIN_MODE 98869 non-null float64
LANDAREA_MODE 124921 non-null float64
LIVINGAPARTMENTS_MODE 97312 non-null float64
LIVINGAREA_MODE 153161 non-null float64
NONLIVINGAPARTMENTS_MODE 93997 non-null float64
NONLIVINGAREA_MODE 137829 non-null float64
APARTMENTS_MEDI 151450 non-null float64
BASEMENTAREA_MEDI 127568 non-null float64
YEARS_BEGINEXPLUATATION_MEDI 157504 non-null float64
YEARS_BUILD_MEDI 103023 non-null float64
COMMONAREA_MEDI 92646 non-null float64
ELEVATORS_MEDI 143620 non-null float64
ENTRANCES_MEDI 152683 non-null float64
FLOORSMAX_MEDI 154491 non-null float64
FLOORSMIN_MEDI 98869 non-null float64
LANDAREA_MEDI 124921 non-null float64
LIVINGAPARTMENTS_MEDI 97312 non-null float64
LIVINGAREA_MEDI 153161 non-null float64
NONLIVINGAPARTMENTS_MEDI 93997 non-null float64
NONLIVINGAREA_MEDI 137829 non-null float64
FONDKAPREMONT_MODE 97216 non-null object
HOUSETYPE_MODE 153214 non-null object
TOTALAREA_MODE 159080 non-null float64
WALLSMATERIAL_MODE 151170 non-null object
EMERGENCYSTATE_MODE 161756 non-null object
OBS_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_30_CNT_SOCIAL_CIRCLE 306490 non-null float64
OBS_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DEF_60_CNT_SOCIAL_CIRCLE 306490 non-null float64
DAYS_LAST_PHONE_CHANGE 307510 non-null float64
FLAG_DOCUMENT_2 307511 non-null int64
FLAG_DOCUMENT_3 307511 non-null int64
FLAG_DOCUMENT_4 307511 non-null int64
FLAG_DOCUMENT_5 307511 non-null int64
FLAG_DOCUMENT_6 307511 non-null int64
FLAG_DOCUMENT_7 307511 non-null int64
FLAG_DOCUMENT_8 307511 non-null int64
FLAG_DOCUMENT_9 307511 non-null int64
FLAG_DOCUMENT_10 307511 non-null int64
FLAG_DOCUMENT_11 307511 non-null int64
FLAG_DOCUMENT_12 307511 non-null int64
FLAG_DOCUMENT_13 307511 non-null int64
FLAG_DOCUMENT_14 307511 non-null int64
FLAG_DOCUMENT_15 307511 non-null int64
FLAG_DOCUMENT_16 307511 non-null int64
FLAG_DOCUMENT_17 307511 non-null int64
FLAG_DOCUMENT_18 307511 non-null int64
FLAG_DOCUMENT_19 307511 non-null int64
FLAG_DOCUMENT_20 307511 non-null int64
FLAG_DOCUMENT_21 307511 non-null int64
AMT_REQ_CREDIT_BUREAU_HOUR 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_DAY 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_WEEK 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_MON 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_QRT 265992 non-null float64
AMT_REQ_CREDIT_BUREAU_YEAR 265992 non-null float64
dtypes: float64(65), int64(41), object(16)
memory usage: 286.2+ MBLembre-se de anotações detalhadas por campo no arquivo HomeCredit_columns_description. Como você pode ver nas informações, parte dos dados está incompleta e parte é categórica, eles são exibidos como objeto. A maioria dos modelos não funciona com esses dados, teremos que fazer algo com eles. Com isso, a análise inicial pode ser considerada concluída, iremos diretamente para a EDA
Análise Exploratória de Dados ou Mineração de Dados Primários
No processo da EDA, contamos as estatísticas básicas e desenhamos gráficos para encontrar tendências, anomalias, padrões e relacionamentos nos dados. O objetivo da EDA é descobrir o que os dados podem dizer. Normalmente, a análise vai de cima para baixo - de uma visão geral ao estudo de zonas individuais que atraem atenção e podem ser de interesse. Posteriormente, esses achados podem ser utilizados na construção do modelo, na seleção de recursos para ele e em sua interpretação.
Distribuição variável alvo
app_train.TARGET.value_counts()
0 282686
1 24825
Name: TARGET, dtype: int64 plt.style.use('fivethirtyeight') plt.rcParams["figure.figsize"] = [8,5] plt.hist(app_train.TARGET) plt.show()
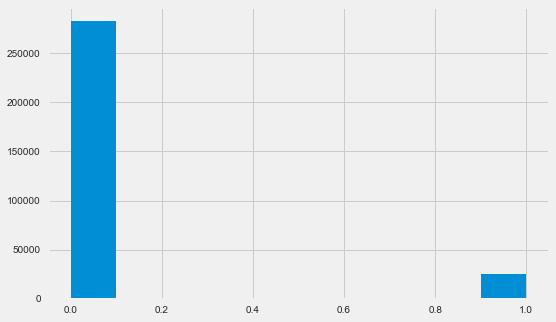
Deixe-me lembrá-lo de que 1 significa problemas de qualquer tipo com retorno, 0 significa que não há problemas. Como você pode ver, principalmente os mutuários não têm problemas com o reembolso, a parcela problemática é de cerca de 8%. Isso significa que as classes não são equilibradas e isso pode precisar ser levado em consideração ao criar o modelo.
Pesquisa de dados ausentes
Vimos que a falta de dados é bastante substancial. Vamos ver com mais detalhes onde e o que está faltando.
122 .
67 .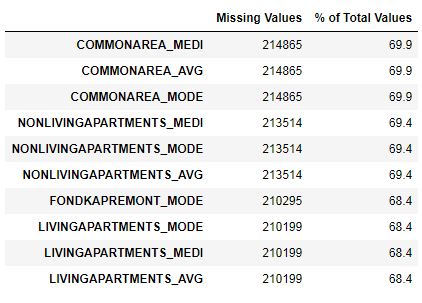
Em formato gráfico:
plt.style.use('seaborn-talk') fig = plt.figure(figsize=(18,6)) miss_train = pd.DataFrame((app_train.isnull().sum())*100/app_train.shape[0]).reset_index() miss_test = pd.DataFrame((app_test.isnull().sum())*100/app_test.shape[0]).reset_index() miss_train["type"] = "" miss_test["type"] = "" missing = pd.concat([miss_train,miss_test],axis=0) ax = sns.pointplot("index",0,data=missing,hue="type") plt.xticks(rotation =90,fontsize =7) plt.title(" ") plt.ylabel(" %") plt.xlabel("")
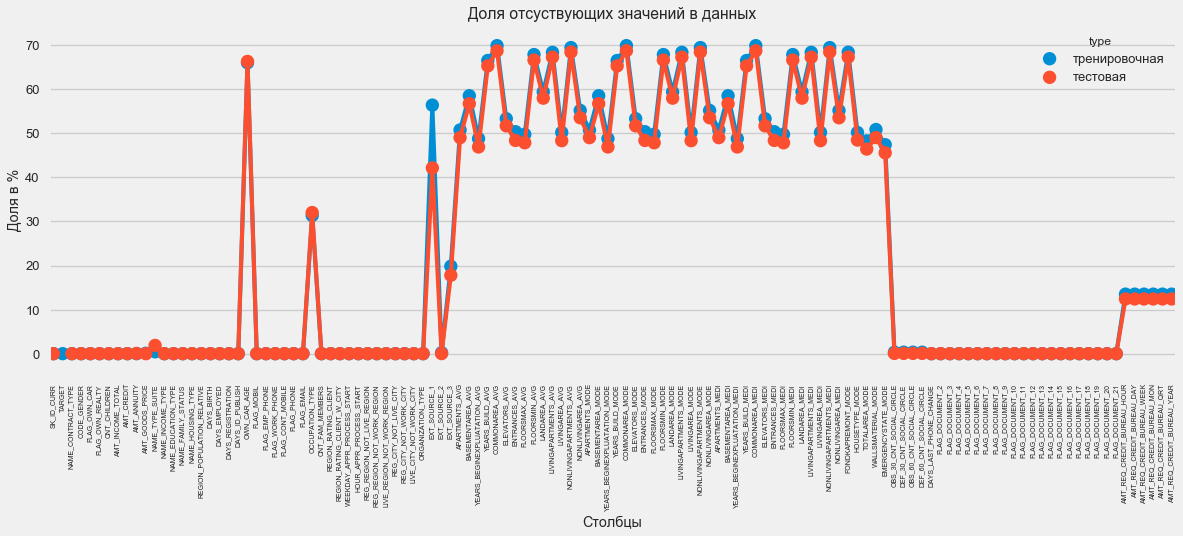
Existem muitas respostas para a pergunta "o que fazer com tudo isso". Você pode preenchê-lo com zeros, você pode usar valores medianos, você pode simplesmente excluir linhas sem as informações necessárias. Tudo depende do modelo que planejamos usar, pois alguns deles lidam perfeitamente com os valores ausentes. Enquanto nos lembramos desse fato e deixamos tudo como está.
Tipos de coluna e codificação categórica
Como nos lembramos. parte das colunas é do tipo objeto, ou seja, não possui um valor numérico, mas reflete alguma categoria. Vamos examinar essas colunas mais de perto.
app_train.dtypes.value_counts()
float64 65
int64 41
object 16
dtype: int64 app_train.select_dtypes(include=[object]).apply(pd.Series.nunique, axis = 0)
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64Temos 16 colunas, cada uma com 2 a 58 opções de valores diferentes. Em geral, os modelos de aprendizado de máquina não podem fazer nada com essas colunas (exceto algumas, como LightGBM ou CatBoost). Como planejamos experimentar modelos diferentes no conjunto de dados, algo precisa ser feito com isso. Existem basicamente duas abordagens:
- Codificação de etiqueta - as categorias recebem os dígitos 0, 1, 2 e assim por diante e são escritas na mesma coluna
- Codificação One-Hot - uma coluna é decomposta em várias de acordo com o número de opções e essas colunas indicam qual opção esse registro possui.
Entre os populares, vale destacar
a codificação média do alvo (obrigado pelo esclarecimento em
roryorangepants ).
Há um pequeno problema com a codificação de etiquetas - ela atribui valores numéricos que nada têm a ver com a realidade. Por exemplo, se estivermos lidando com um valor numérico, a renda de 100.000 do tomador de empréstimo é definitivamente maior e melhor que a de 20.000. Mas podemos dizer que, por exemplo, uma cidade é melhor que outra porque é atribuído o valor 100 e a outra 200 ?
A codificação One-Hot, por outro lado, é mais segura, mas pode produzir colunas "extras". Por exemplo, se codificarmos o mesmo gênero usando o One-Hot, obteremos duas colunas, "gênero masculino" e "gênero feminino", embora uma seja suficiente, "é masculino".
Para um bom conjunto de dados, seria necessário codificar sinais com baixa variabilidade usando Label Encoding e tudo mais - One-Hot, mas por simplicidade, codificamos tudo de acordo com o One-Hot. Praticamente não afetará a velocidade de cálculo e o resultado. O próprio processo de codificação de pandas é muito simples.
app_train = pd.get_dummies(app_train) app_test = pd.get_dummies(app_test) print('Training Features shape: ', app_train.shape) print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 246)
Testing Features shape: (48744, 242)Como o número de opções nas colunas de seleção não é igual, o número de colunas agora não corresponde. O alinhamento é necessário - você precisa remover as colunas do conjunto de treinamento que não estão no conjunto de teste. Isso torna o método de alinhamento, você precisa especificar o eixo = 1 (para colunas).
: (307511, 242)
: (48744, 242)Correlação de dados
Uma boa maneira de entender os dados é calcular os coeficientes de correlação de Pearson para os dados relativos ao atributo de destino. Este não é o melhor método para mostrar a relevância dos recursos, mas é simples e permite que você tenha uma idéia dos dados. Os coeficientes podem ser interpretados da seguinte maneira:
- 00-.19 "muito fraco"
- 20-.39 "fraco"
- 40-.59 "médio"
- 60-.79 forte
- 80-1,0 "muito forte"
:
DAYS_REGISTRATION 0.041975
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
ORGANIZATION_TYPE_XNA -0.045987
DAYS_EMPLOYED -0.044932
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64Assim, todos os dados se correlacionam fracamente com o alvo (exceto o próprio alvo, que, é claro, é igual a ele). No entanto, a idade e algumas "fontes de dados externas" são diferenciadas dos dados. Provavelmente são alguns dados adicionais de outras organizações de crédito. É engraçado que, embora o objetivo seja declarado como independência de tais dados na tomada de uma decisão de crédito, na verdade estaremos baseados principalmente neles.
Idade
É claro que, quanto mais antigo o cliente, maior a probabilidade de um retorno (até um certo limite, é claro). Mas, por algum motivo, a idade é indicada em dias negativos antes da emissão do empréstimo; portanto, ela se correlaciona positivamente com o não pagamento (o que parece um pouco estranho). Trazemos isso a um valor positivo e observamos a correlação.
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH']) app_train['DAYS_BIRTH'].corr(app_train['TARGET'])
-0.078239308309827088Vamos dar uma olhada mais de perto na variável. Vamos começar com o histograma.
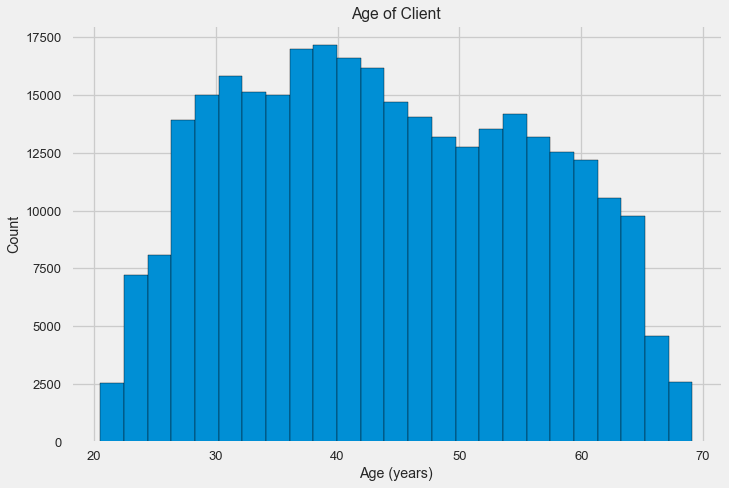
O histograma de distribuição em si pode ser um pouco útil, exceto pelo fato de não vermos valores extremos especiais e tudo parecer mais ou menos crível. Para mostrar o efeito da influência da idade no resultado, podemos construir um gráfico de estimativa da densidade do núcleo (KDE) - a distribuição da densidade nuclear, pintada nas cores do atributo de destino. Ele mostra a distribuição de uma variável e pode ser interpretado como um histograma suavizado (calculado como um núcleo gaussiano para cada ponto, que é calculado como média para suavizar).
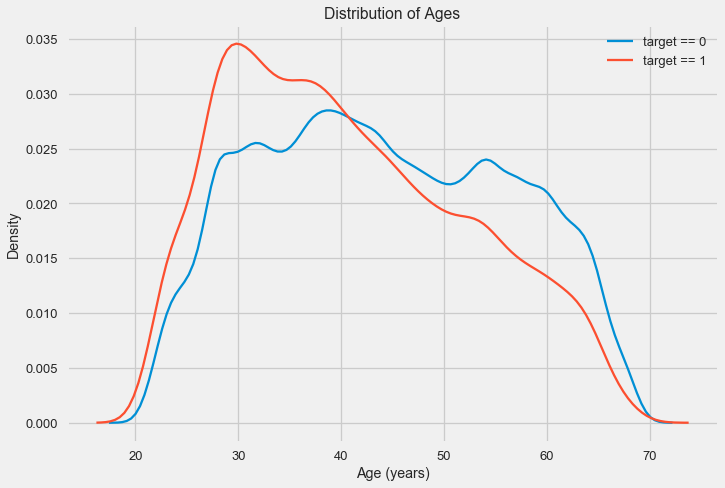
Como pode ser visto, a parcela de inadimplência é maior para os jovens e diminui com o aumento da idade. Esta não é uma razão para recusar crédito aos jovens sempre, tal “recomendação” só levará à perda de renda e de mercado para o banco. Esta é uma ocasião para pensar em um monitoramento mais completo desses empréstimos, avaliações e, possivelmente, até algum tipo de educação financeira para jovens mutuários.
Fontes externas
Vamos dar uma olhada nas “fontes de dados externas” EXT_SOURCE e sua correlação.
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']] ext_data_corrs = ext_data.corr() ext_data_corrs
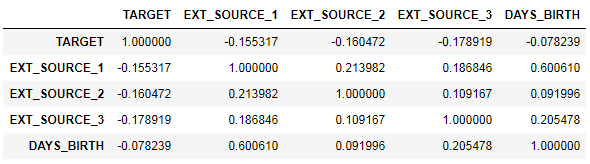
Também é conveniente exibir correlação usando o mapa de calor
sns.heatmap(ext_data_corrs, cmap = plt.cm.RdYlBu_r, vmin = -0.25, annot = True, vmax = 0.6) plt.title('Correlation Heatmap');
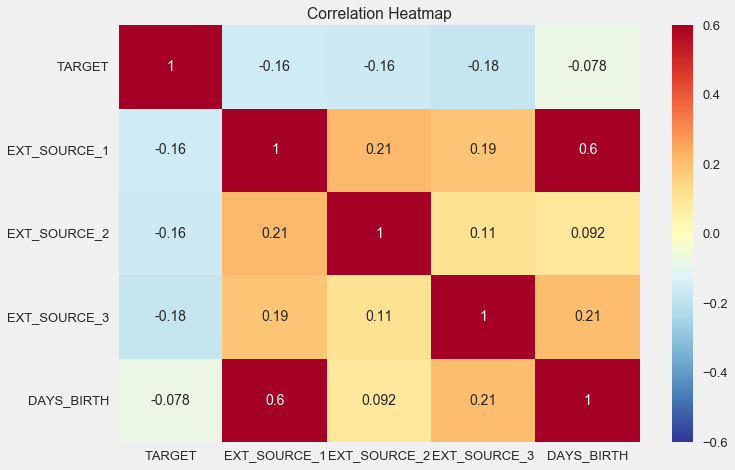
Como você pode ver, todas as fontes mostram uma correlação negativa com o destino. Vamos dar uma olhada na distribuição do KDE para cada fonte.
plt.figure(figsize = (10, 12))
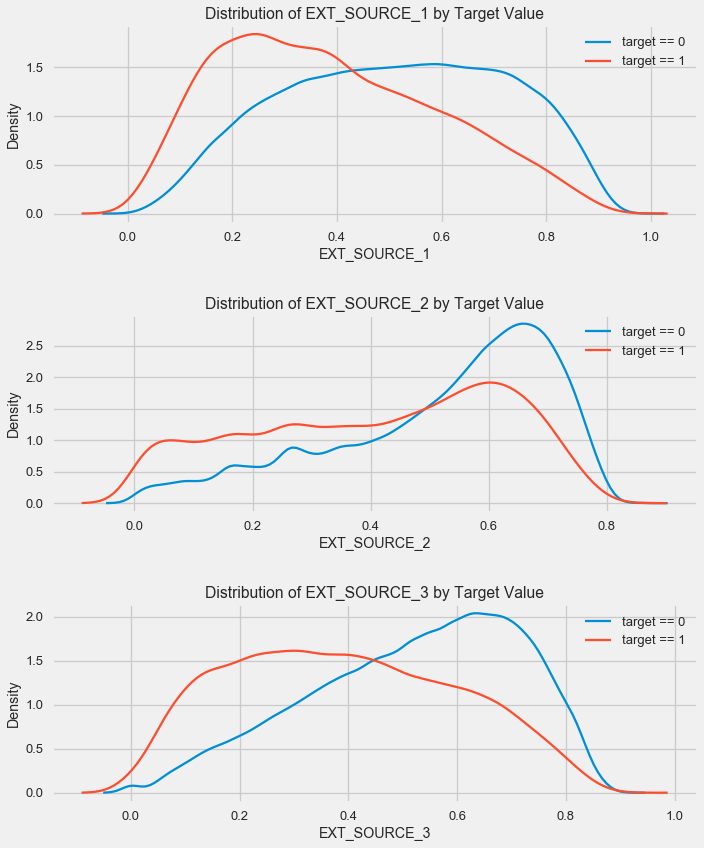
O quadro é semelhante à distribuição por idade - com um aumento no indicador, a probabilidade de retorno do empréstimo aumenta. A terceira fonte é a mais poderosa a esse respeito. Embora em termos absolutos a correlação com a variável alvo ainda esteja na categoria "muito baixa", fontes de dados externas e idade serão da maior importância na construção do modelo.
Programação de par
Para entender melhor o relacionamento dessas variáveis, você pode criar um gráfico de pares, nele podemos ver o relacionamento de cada par e um histograma da distribuição ao longo da diagonal. Acima da diagonal, você pode mostrar o gráfico de dispersão e abaixo - 2d KDE.
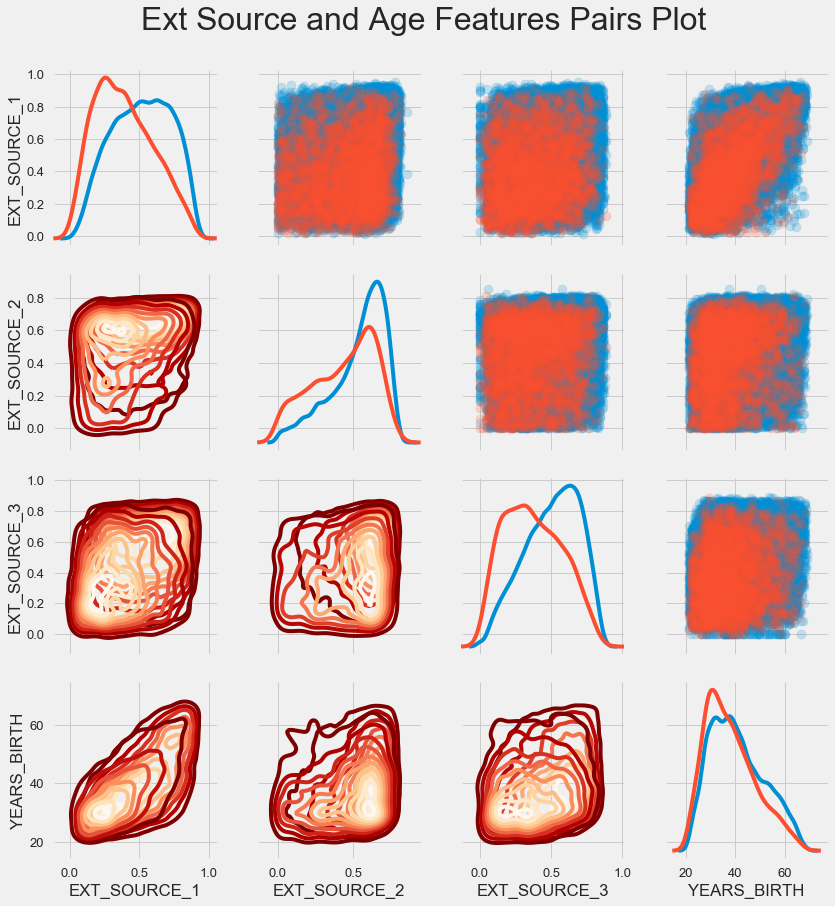
Empréstimos reembolsáveis são mostrados em azul, não reembolsáveis em vermelho. Interpretar tudo isso é bastante difícil, mas uma boa impressão em uma camiseta ou em uma foto de um museu de arte moderna pode sair dessa imagem.
Exame de outros sinais
Vamos considerar com mais detalhes outros recursos e sua dependência da variável de destino. Como existem muitos categóricos (e já conseguimos codificá-los), novamente precisamos dos dados iniciais. Vamos chamá-los um pouco diferente para evitar confusão
application_train = pd.read_csv(PATH+"application_train.csv") application_test = pd.read_csv(PATH+"application_test.csv")
Também precisaremos de algumas funções para exibir lindamente as distribuições e sua influência na variável de destino. Muito obrigado
a eles pelo
autor deste
kernel def plot_stats(feature,label_rotation=False,horizontal_layout=True): temp = application_train[feature].value_counts() df1 = pd.DataFrame({feature: temp.index,' ': temp.values})
Então, vamos considerar os principais sinais dos clientes
Tipo de empréstimo
plot_stats('NAME_CONTRACT_TYPE')
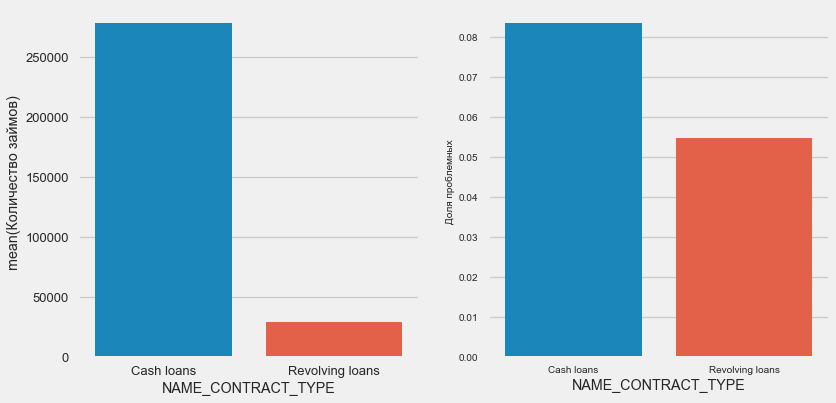
Curiosamente, empréstimos rotativos (provavelmente descobertos ou algo parecido) representam menos de 10% do número total de empréstimos. Ao mesmo tempo, o percentual de não retorno entre eles é muito maior. Um bom motivo para revisar a metodologia de trabalho com esses empréstimos e talvez até abandoná-los.
Sexo do cliente
plot_stats('CODE_GENDER')
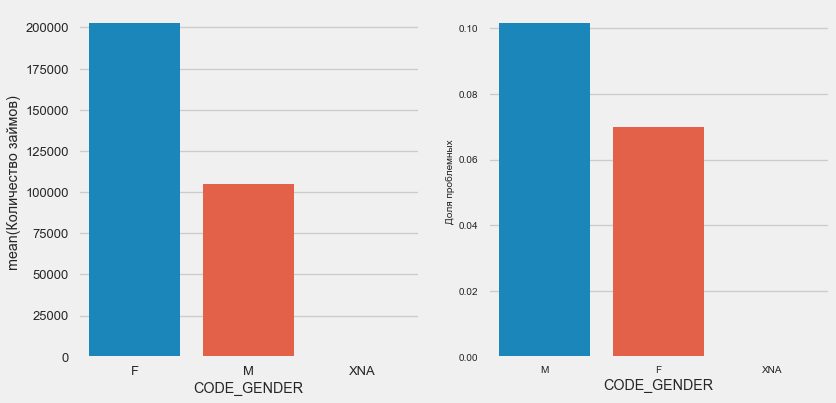
Há quase o dobro de clientes mulheres do que homens, com os homens apresentando um risco muito maior.
Propriedade de carro e propriedade
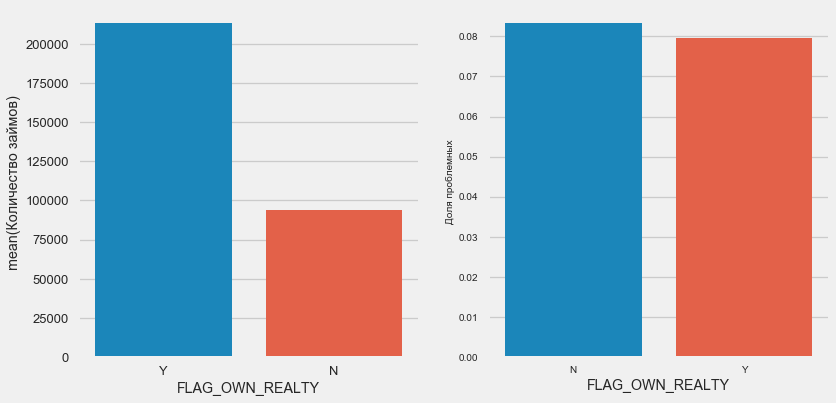
plot_stats('FLAG_OWN_CAR') plot_stats('FLAG_OWN_REALTY')
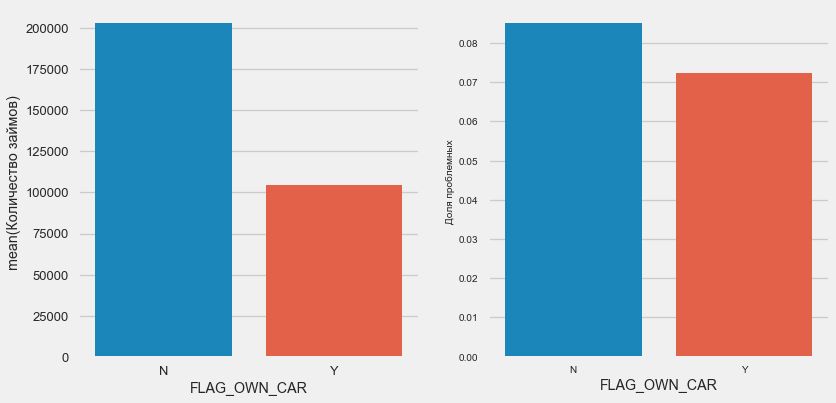
Clientes com o carro são metade do que "sem cavalos". O risco é quase o mesmo, os clientes com a máquina pagam um pouco melhor.
No setor imobiliário, o oposto é verdadeiro - há metade do número de clientes sem ele. O risco para os proprietários também é um pouco menor.
Estado civil
plot_stats('NAME_FAMILY_STATUS',True, True)
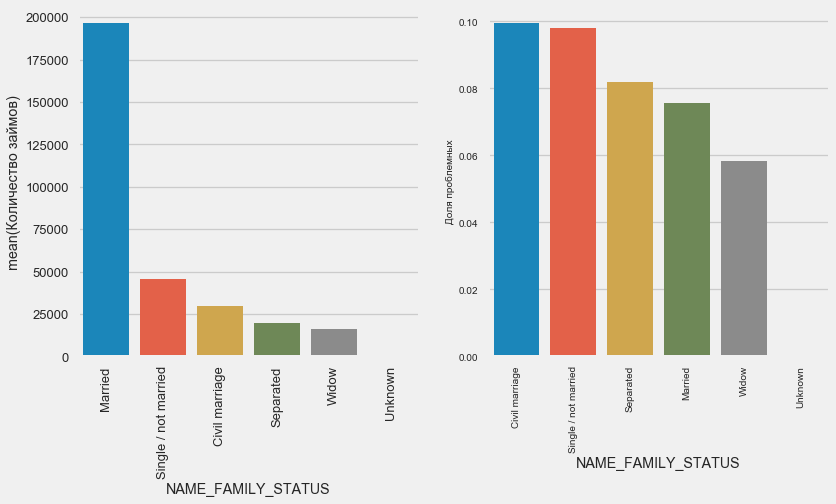
Enquanto a maioria dos clientes é casada, os mais arriscados são clientes civis e solteiros. Os viúvos mostram um risco mínimo.
Número de filhos
plot_stats('CNT_CHILDREN')
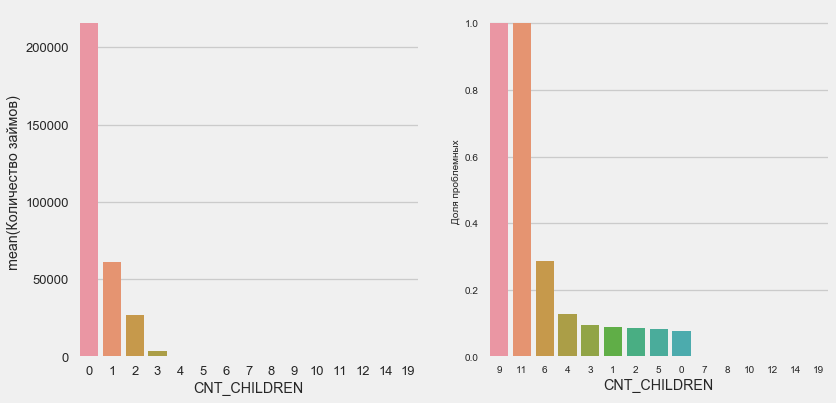
A maioria dos clientes não tem filhos. Ao mesmo tempo, clientes com 9 e 11 filhos mostram um reembolso total não reembolsável
application_train.CNT_CHILDREN.value_counts()
0 215371
1 61119
2 26749
3 3717
4 429
5 84
6 21
7 7
14 3
19 2
12 2
10 2
9 2
8 2
11 1
Name: CNT_CHILDREN, dtype: int64Como mostra o cálculo dos valores, esses dados são estatisticamente insignificantes - apenas 1-2 clientes de ambas as categorias. No entanto, todos os três entraram no padrão, assim como metade dos clientes com 6 filhos.
Número de membros da família
plot_stats('CNT_FAM_MEMBERS',True)
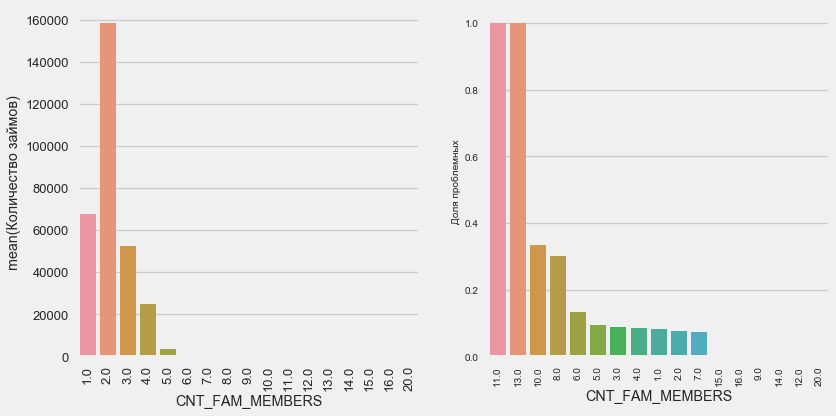
A situação é semelhante - quanto menos bocas, maior o retorno.
Tipo de renda
plot_stats('NAME_INCOME_TYPE',False,False)
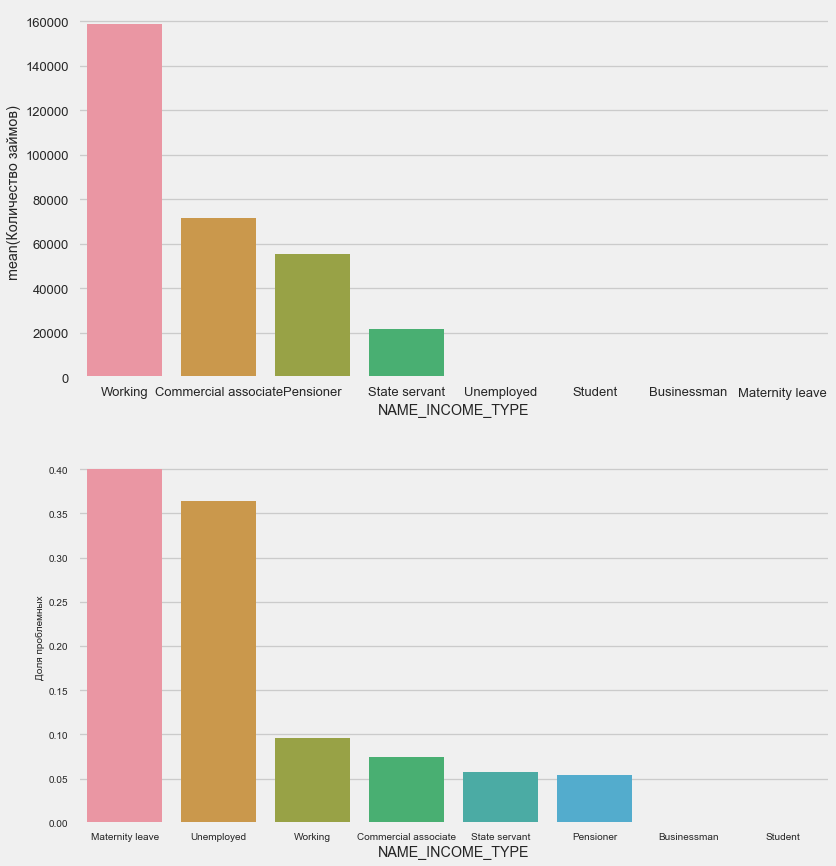
Mães solteiras e desempregadas provavelmente serão cortadas na fase de inscrição - há muito poucas delas na amostra. Mas os problemas estão mostrando de forma estável.
Tipo de atividade
plot_stats('OCCUPATION_TYPE',True, False)
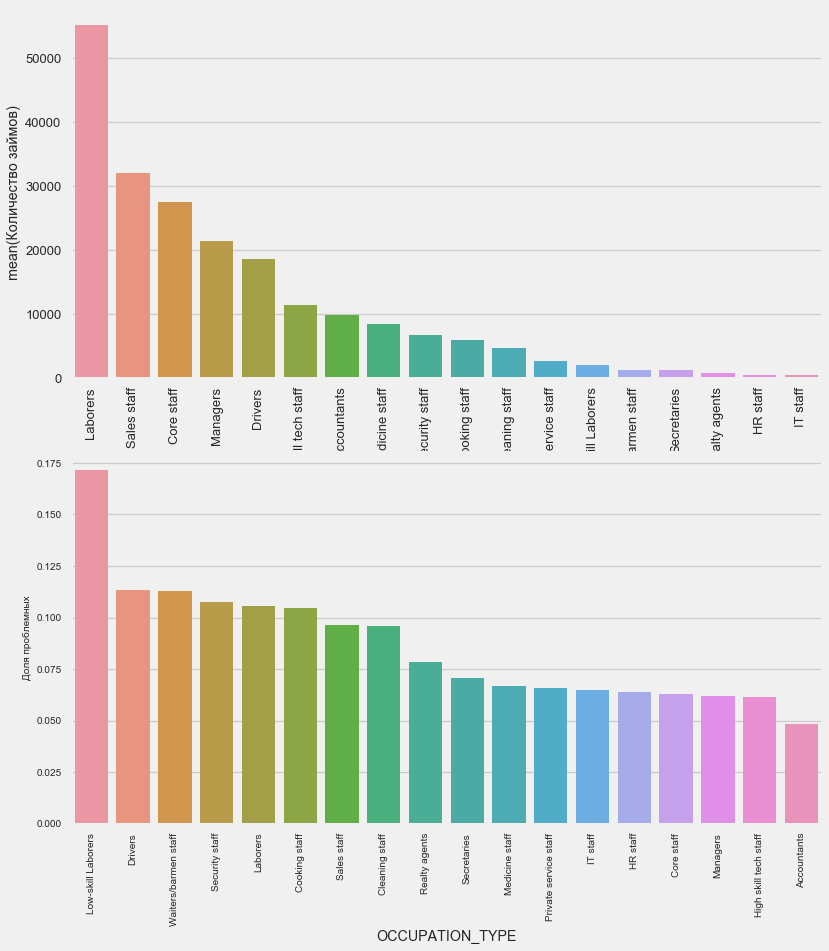
application_train.OCCUPATION_TYPE.value_counts()
Laborers 55186
Sales staff 32102
Core staff 27570
Managers 21371
Drivers 18603
High skill tech staff 11380
Accountants 9813
Medicine staff 8537
Security staff 6721
Cooking staff 5946
Cleaning staff 4653
Private service staff 2652
Low-skill Laborers 2093
Waiters/barmen staff 1348
Secretaries 1305
Realty agents 751
HR staff 563
IT staff 526
Name: OCCUPATION_TYPE, dtype: int64É de interesse dos motoristas e agentes de segurança que são bastante numerosos e enfrentam problemas com mais frequência do que outras categorias.
Educação
plot_stats('NAME_EDUCATION_TYPE',True)
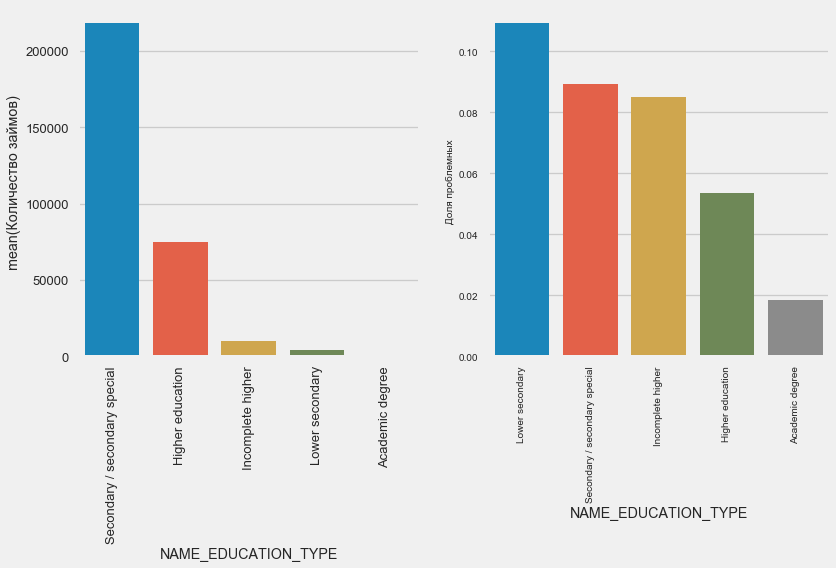
Quanto maior a educação, melhor a recorrência, obviamente.
Tipo de organização - empregador
plot_stats('ORGANIZATION_TYPE',True, False)
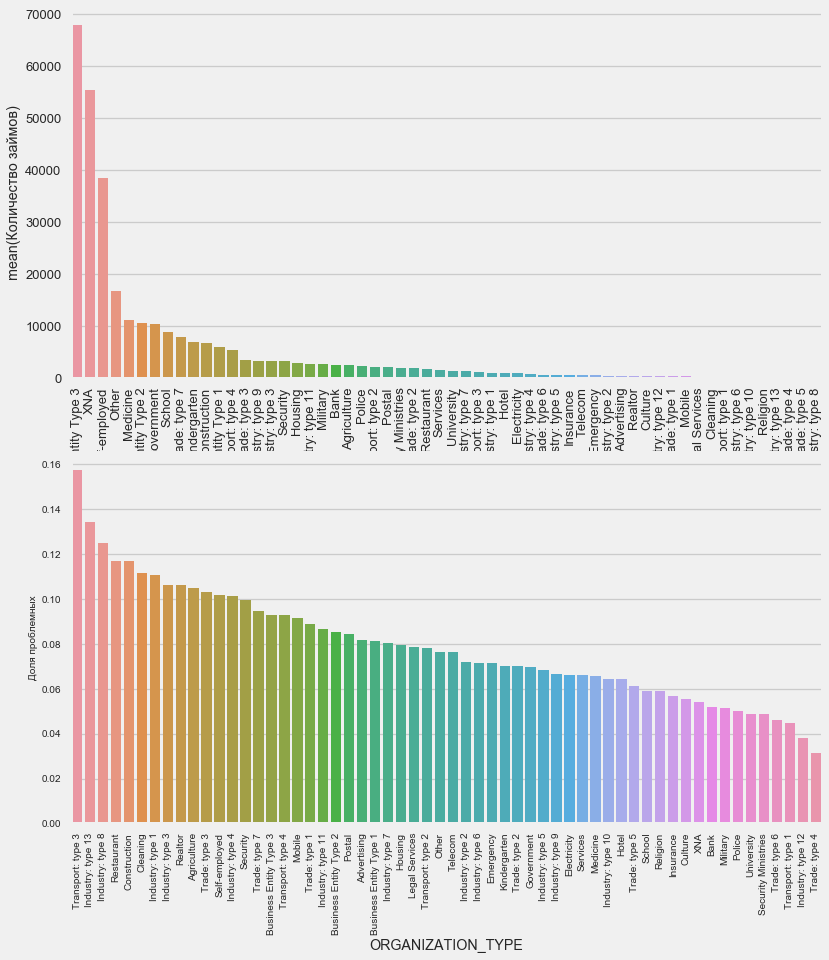
A maior porcentagem de não retorno é observada em Transporte: tipo 3 (16%), Indústria: tipo 13 (13,5%), Indústria: tipo 8 (12,5%) e Restaurante (até 12%).
Alocação de empréstimos
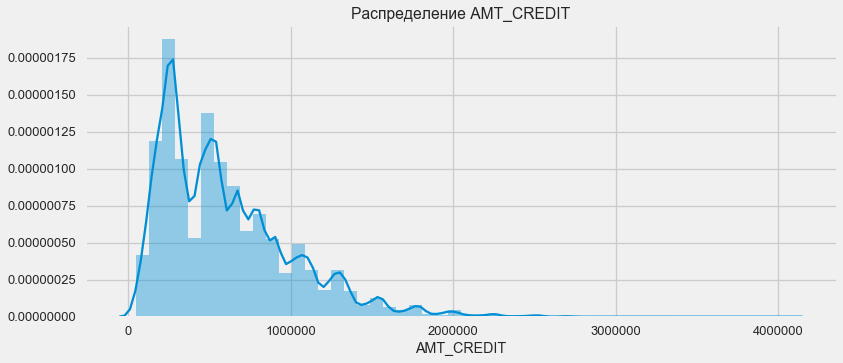
Considerar a distribuição dos valores dos empréstimos e seu impacto no reembolso
plt.figure(figsize=(12,5)) plt.title(" AMT_CREDIT") ax = sns.distplot(app_train["AMT_CREDIT"])
plt.figure(figsize=(12,5))
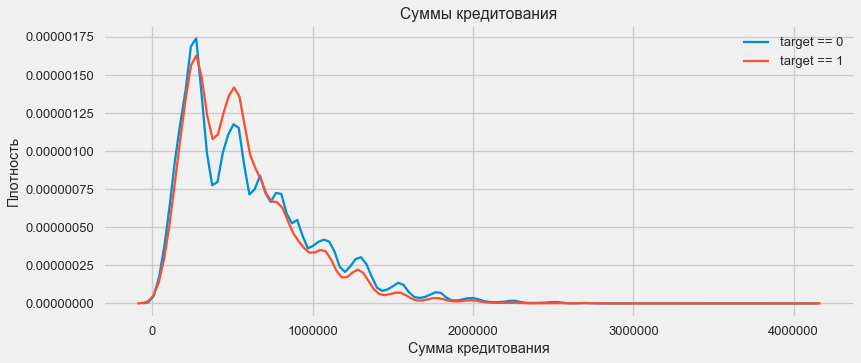
Como mostra o gráfico de densidade, quantidades robustas são retornadas com mais frequência
Distribuição de densidade
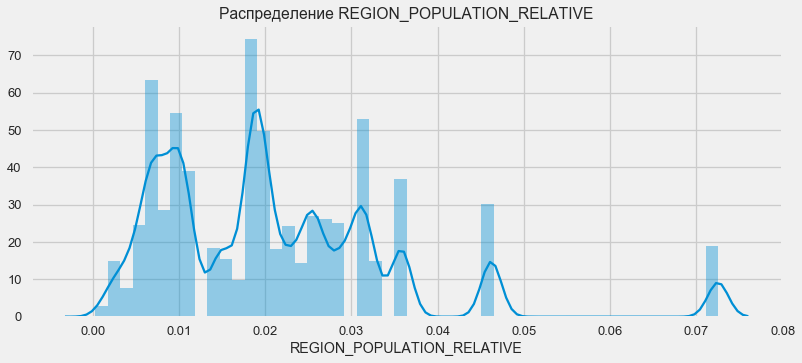
plt.figure(figsize=(12,5)) plt.title(" REGION_POPULATION_RELATIVE") ax = sns.distplot(app_train["REGION_POPULATION_RELATIVE"])
plt.figure(figsize=(12,5))
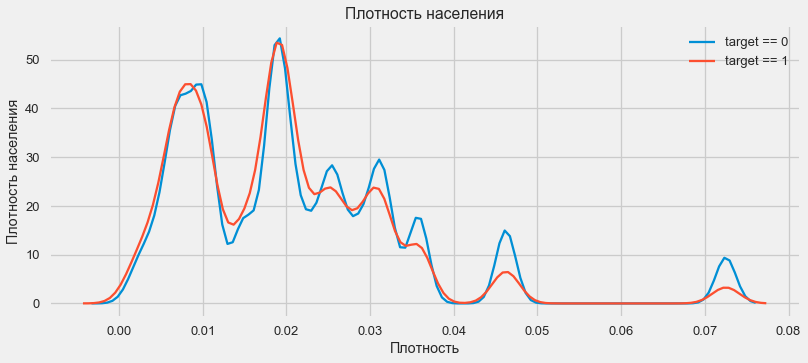
Clientes de regiões mais populosas tendem a pagar melhor empréstimos.
Assim, tivemos uma idéia das principais características do conjunto de dados e sua influência no resultado. Não faremos nada especificamente com os listados neste artigo, mas eles podem se tornar muito importantes em trabalhos futuros.
Engenharia de recursos - Conversão de recursos
As competições no Kaggle são vencidas pela transformação de sinais - quem pode criar os sinais mais úteis a partir dos dados ganha. Pelo menos para dados estruturados, os modelos vencedores agora são basicamente diferentes opções de aumento de gradiente. Na maioria das vezes, é mais eficiente gastar tempo convertendo atributos do que configurar hiperparâmetros ou selecionar modelos. Um modelo ainda pode aprender apenas com os dados que foram transferidos para ele. Garantir que os dados sejam relevantes para a tarefa é a principal responsabilidade da data do cientista.
O processo de transformação de características pode incluir a criação de novos dados disponíveis, a seleção dos mais importantes disponíveis, etc. Vamos tentar desta vez sinais polinomiais.
Sinais polinomiais
O método polinomial de construir recursos é que simplesmente criamos recursos que são o grau de recursos disponíveis e seus produtos. Em alguns casos, esses recursos construídos podem ter uma correlação mais forte com a variável alvo do que seus “pais”. Embora esses métodos sejam frequentemente usados em modelos estatísticos, eles são muito menos comuns no aprendizado de máquina. No entanto. nada nos impede de experimentá-los, especialmente porque o Scikit-Learn tem uma classe especificamente para esses fins - PolynomialFeatures - que cria recursos polinomiais e seus produtos, você só precisa especificar os recursos originais e o grau máximo em que eles precisam ser aprimorados. Usamos os efeitos mais poderosos no resultado de 4 atributos e no grau 3 para não complicar demais o modelo e evitar o excesso de ajustes (treinamento excessivo do modelo - seu ajuste excessivo na amostra de treinamento).
: (307511, 35)
get_feature_names poly_transformer.get_feature_names(input_features = ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])[:15]
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']Um total de 35 recursos polinomiais e derivados. Verifique sua correlação com o alvo.
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH -0.181283
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_2 DAYS_BIRTH -0.156873
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
Name: TARGET, dtype: float64
DAYS_BIRTH -0.078239
DAYS_BIRTH^2 -0.076672
DAYS_BIRTH^3 -0.074273
TARGET 1.000000
1 NaN
Name: TARGET, dtype: float64Portanto, alguns sinais mostram uma correlação maior que a original. Faz sentido tentar aprender com eles e sem eles (como muito mais no aprendizado de máquina, isso pode ser determinado experimentalmente). Para fazer isso, crie uma cópia dos quadros de dados e adicione novos recursos lá.
: (307511, 277)
: (48744, 277)Modelo de treinamento
Nível básico
Nos cálculos, você precisa começar com algum nível básico do modelo, abaixo do qual não é mais possível cair. No nosso caso, isso pode ser 0,5 para todos os clientes de teste - isso mostra que não temos idéia de se o cliente reembolsará o empréstimo ou não. No nosso caso, o trabalho preliminar já foi realizado e modelos mais complexos podem ser usados.Regressão logística
Para calcular a regressão logística, precisamos pegar tabelas com recursos categóricos codificados, preencher os dados ausentes e normalizá-los (levá-los a valores de 0 a 1). Tudo isso executa o seguinte código: from sklearn.preprocessing import MinMaxScaler, Imputer
: (307511, 242)
: (48744, 242)Utilizamos a regressão logística do Scikit-Learn como o primeiro modelo. Vamos pegar o modelo de desfolhamento com uma correção - abaixamos o parâmetro de regularização C para evitar o ajuste excessivo. A sintaxe é normal - criamos um modelo, treinamos e prevemos a probabilidade usando o prog_proba (precisamos de probabilidade, não 0/1) from sklearn.linear_model import LogisticRegression
Agora você pode criar um arquivo para fazer upload no Kaggle. Crie um quadro de dados a partir do ID do cliente e probabilidade de não retorno e faça o upload dele. submit = app_test[['SK_ID_CURR']] submit['TARGET'] = log_reg_pred submit.head()
SK_ID_CURR TARGET
0 100001 0.087954
1 100005 0.163151
2 100013 0.109923
3 100028 0.077124
4 100038 0.151694 submit.to_csv('log_reg_baseline.csv', index = False)
Portanto, o resultado do nosso trabalho titânico: 0,673, com o melhor resultado para hoje, é 0,802.Modelo Aprimorado - Floresta Aleatória
Logreg não se mostra muito bem, vamos tentar usar um modelo melhorado - uma floresta aleatória. Este é um modelo muito mais poderoso que pode construir centenas de árvores e produzir um resultado muito mais preciso. Nós usamos 100 árvores. O esquema de trabalhar com o modelo é o mesmo, completamente padrão - carregando o classificador, treinando. previsão. from sklearn.ensemble import RandomForestClassifier
resultado aleatório da floresta é ligeiramente melhor - 0,683Modelo de treinamento com recursos polinomiais
Agora que temos um modelo. que faz pelo menos alguma coisa - é hora de testar nossos sinais polinomiais. Vamos fazer o mesmo com eles e comparar o resultado. poly_features_names = list(app_train_poly.columns)
o resultado de uma floresta aleatória com características polinomiais se tornou pior - 0,633. O que questiona muito a necessidade de seu uso.Aumento de gradiente
O aumento de gradiente é um "modelo sério" para aprendizado de máquina. Quase todas as competições mais recentes são "arrastadas" exatamente. Vamos construir um modelo simples e testar seu desempenho. from lightgbm import LGBMClassifier clf = LGBMClassifier() clf.fit(train, train_labels) predictions = clf.predict_proba(test)[:, 1]
O resultado do LightGBM é 0,735, o que deixa para trás todos os outros modelos.Interpretação do Modelo - Importância dos Atributos
A maneira mais fácil de interpretar um modelo é examinar a importância dos recursos (o que nem todos os modelos podem fazer). Como nosso classificador processou a matriz, será necessário algum trabalho para redefinir os nomes das colunas de acordo com as colunas dessa matriz.
Como seria de esperar, o mais importante para modelar todos os mesmos 4 características. A importância dos atributos não é o melhor método de interpretação do modelo, mas permite entender os principais fatores que o modelo usa para previsõesfeature importance
28 EXT_SOURCE_1 310
30 EXT_SOURCE_3 282
29 EXT_SOURCE_2 271
7 DAYS_BIRTH 192
3 AMT_CREDIT 161
4 AMT_ANNUITY 142
5 AMT_GOODS_PRICE 129
8 DAYS_EMPLOYED 127
10 DAYS_ID_PUBLISH 102
9 DAYS_REGISTRATION 69
0.01 = 158
Adicionando dados de outras tabelas
Agora vamos considerar cuidadosamente tabelas adicionais e o que pode ser feito com elas. Comece imediatamente a preparar as mesas para treinamento adicional. Mas primeiro, exclua as volumosas tabelas antigas da memória, limpe a memória usando o coletor de lixo e importe as bibliotecas necessárias para análises adicionais. import gc
Importe dados, remova imediatamente a coluna de destino em uma coluna separada data = pd.read_csv('../input/application_train.csv') test = pd.read_csv('../input/application_test.csv') prev = pd.read_csv('../input/previous_application.csv') buro = pd.read_csv('../input/bureau.csv') buro_balance = pd.read_csv('../input/bureau_balance.csv') credit_card = pd.read_csv('../input/credit_card_balance.csv') POS_CASH = pd.read_csv('../input/POS_CASH_balance.csv') payments = pd.read_csv('../input/installments_payments.csv')
Codifique imediatamente os recursos categóricos. Já fizemos isso antes, codificamos as amostras de treinamento e teste separadamente e, em seguida, alinhamos os dados. Vamos tentar uma abordagem um pouco diferente - encontraremos todos esses recursos categóricos, combinaremos os quadros de dados, codificaremos a partir da lista de encontrados e, em seguida, dividiremos novamente as amostras em treinamento e teste. categorical_features = [col for col in data.columns if data[col].dtype == 'object'] one_hot_df = pd.concat([data,test]) one_hot_df = pd.get_dummies(one_hot_df, columns=categorical_features) data = one_hot_df.iloc[:data.shape[0],:] test = one_hot_df.iloc[data.shape[0]:,] print (' ', data.shape) print (' ', test.shape)
(307511, 245)
(48744, 245)Dados da agência de crédito sobre o saldo mensal do empréstimo.
buro_balance.head()
 MONTHS_BALANCE - o número de meses antes da data do pedido de empréstimo. Veja mais de perto os "status"
MONTHS_BALANCE - o número de meses antes da data do pedido de empréstimo. Veja mais de perto os "status" buro_balance.STATUS.value_counts()
C 13646993
0 7499507
X 5810482
1 242347
5 62406
2 23419
3 8924
4 5847
Name: STATUS, dtype: int64Status significa o seguinte:- fechado, ou seja, empréstimo reembolsado. X é um status desconhecido. 0 - empréstimo atual, sem inadimplência. 1 - atraso de 1 a 30 dias, 2 - atraso de 31 a 60 dias e assim por diante até o status 5 - o empréstimo é vendido a terceiros ou baixado.Aqui, por exemplo, os seguintes sinais podem ser distinguidos: buro_grouped_size - o número de entradas no banco de dados buro_grouped_max - o saldo máximo de empréstimos buro_grouped_min - o saldo mínimo de empréstimosE todos esses status de empréstimo podem ser codificados (usamos o método desempilhar e, em seguida, anexamos os dados recebidos à tabela buro, pois SK_ID_BUREAU é o mesmo aqui e ali. buro_grouped_size = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].size() buro_grouped_max = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].max() buro_grouped_min = buro_balance.groupby('SK_ID_BUREAU')['MONTHS_BALANCE'].min() buro_counts = buro_balance.groupby('SK_ID_BUREAU')['STATUS'].value_counts(normalize = False) buro_counts_unstacked = buro_counts.unstack('STATUS') buro_counts_unstacked.columns = ['STATUS_0', 'STATUS_1','STATUS_2','STATUS_3','STATUS_4','STATUS_5','STATUS_C','STATUS_X',] buro_counts_unstacked['MONTHS_COUNT'] = buro_grouped_size buro_counts_unstacked['MONTHS_MIN'] = buro_grouped_min buro_counts_unstacked['MONTHS_MAX'] = buro_grouped_max buro = buro.join(buro_counts_unstacked, how='left', on='SK_ID_BUREAU') del buro_balance gc.collect()
Informações gerais sobre agências de crédito
buro.head()
 (primeiras 7 colunas são mostradas) Existemmuitos dados que, em geral, você pode tentar codificar com One-Hot-Encoding, agrupado por SK_ID_CURR, médio e, da mesma maneira, se preparar para ingressar na tabela principal
(primeiras 7 colunas são mostradas) Existemmuitos dados que, em geral, você pode tentar codificar com One-Hot-Encoding, agrupado por SK_ID_CURR, médio e, da mesma maneira, se preparar para ingressar na tabela principal buro_cat_features = [bcol for bcol in buro.columns if buro[bcol].dtype == 'object'] buro = pd.get_dummies(buro, columns=buro_cat_features) avg_buro = buro.groupby('SK_ID_CURR').mean() avg_buro['buro_count'] = buro[['SK_ID_BUREAU', 'SK_ID_CURR']].groupby('SK_ID_CURR').count()['SK_ID_BUREAU'] del avg_buro['SK_ID_BUREAU'] del buro gc.collect()
Dados sobre aplicativos anteriores
prev.head()
 Da mesma forma, codificamos recursos categóricos, medimos e combinamos sobre o ID atual.
Da mesma forma, codificamos recursos categóricos, medimos e combinamos sobre o ID atual. prev_cat_features = [pcol for pcol in prev.columns if prev[pcol].dtype == 'object'] prev = pd.get_dummies(prev, columns=prev_cat_features) avg_prev = prev.groupby('SK_ID_CURR').mean() cnt_prev = prev[['SK_ID_CURR', 'SK_ID_PREV']].groupby('SK_ID_CURR').count() avg_prev['nb_app'] = cnt_prev['SK_ID_PREV'] del avg_prev['SK_ID_PREV'] del prev gc.collect()
Saldo do cartão de crédito
POS_CASH.head()

POS_CASH.NAME_CONTRACT_STATUS.value_counts()
Active 9151119
Completed 744883
Signed 87260
Demand 7065
Returned to the store 5461
Approved 4917
Amortized debt 636
Canceled 15
XNA 2
Name: NAME_CONTRACT_STATUS, dtype: int64Codificamos recursos categóricos e preparamos uma tabela para combinar le = LabelEncoder() POS_CASH['NAME_CONTRACT_STATUS'] = le.fit_transform(POS_CASH['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = POS_CASH[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() POS_CASH['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] POS_CASH['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] POS_CASH.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Dados do cartão
credit_card.head()
 (primeiras 7 colunas)Trabalho semelhante
(primeiras 7 colunas)Trabalho semelhante credit_card['NAME_CONTRACT_STATUS'] = le.fit_transform(credit_card['NAME_CONTRACT_STATUS'].astype(str)) nunique_status = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').nunique() nunique_status2 = credit_card[['SK_ID_CURR', 'NAME_CONTRACT_STATUS']].groupby('SK_ID_CURR').max() credit_card['NUNIQUE_STATUS'] = nunique_status['NAME_CONTRACT_STATUS'] credit_card['NUNIQUE_STATUS2'] = nunique_status2['NAME_CONTRACT_STATUS'] credit_card.drop(['SK_ID_PREV', 'NAME_CONTRACT_STATUS'], axis=1, inplace=True)
Dados de pagamento
payments.head()
 (primeiras 7 colunas mostradas)Vamos criar três tabelas - com os valores médio, mínimo e máximo desta tabela.
(primeiras 7 colunas mostradas)Vamos criar três tabelas - com os valores médio, mínimo e máximo desta tabela. avg_payments = payments.groupby('SK_ID_CURR').mean() avg_payments2 = payments.groupby('SK_ID_CURR').max() avg_payments3 = payments.groupby('SK_ID_CURR').min() del avg_payments['SK_ID_PREV'] del payments gc.collect()
Junção de tabela
data = data.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_prev.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_buro.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(POS_CASH.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') test = test.merge(credit_card.groupby('SK_ID_CURR').mean().reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments2.reset_index(), how='left', on='SK_ID_CURR') data = data.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') test = test.merge(right=avg_payments3.reset_index(), how='left', on='SK_ID_CURR') del avg_prev, avg_buro, POS_CASH, credit_card, avg_payments, avg_payments2, avg_payments3 gc.collect() print (' ', data.shape) print (' ', test.shape) print (' ', y.shape)
(307511, 504)
(48744, 504)
(307511,)E, na verdade, chegaremos a essa mesa dobrada com aumento de gradiente! from lightgbm import LGBMClassifier clf2 = LGBMClassifier() clf2.fit(data, y) predictions = clf2.predict_proba(test)[:, 1]
o resultado é 0,770.OK, finalmente, vamos tentar uma técnica mais complexa, com dobras em dobras, validação cruzada e escolha da melhor iteração. folds = KFold(n_splits=5, shuffle=True, random_state=546789) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) feature_importance_df = pd.DataFrame() feats = [f for f in data.columns if f not in ['SK_ID_CURR']] for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[feats].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[feats].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier( n_estimators=10000, learning_rate=0.03, num_leaves=34, colsample_bytree=0.9, subsample=0.8, max_depth=8, reg_alpha=.1, reg_lambda=.1, min_split_gain=.01, min_child_weight=375, silent=-1, verbose=-1, ) clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=100, early_stopping_rounds=100
Full AUC score 0.785845Pontuação final no kaggle 0.783Para onde ir a seguir
Definitivamente continue a trabalhar com sinais. Explore os dados, selecione alguns dos sinais, combine-os, anexe tabelas adicionais de uma maneira diferente. Você pode experimentar os hiperparâmetros Mogheli - muitas direções.Espero que esta pequena compilação tenha mostrado métodos modernos de pesquisa de dados e preparação de modelos preditivos. Aprenda dataaens, participe de competições, seja legal!E, novamente, links para os kernels que me ajudaram a preparar este artigo. O artigo também é publicado na forma de um laptop no Github , você pode baixá-lo, conjunto de dados e executar e experimentar.Will Koehrsen. Comece aqui: uma introdução suavesban. HomeCreditRisk: EDA abrangente + linha de base [0,772]Gabriel Preda. Home Credit Default Risk Extensive EDAPavan Raj. Loan repayers v/s Loan defaulters — HOME CREDITLem Lordje Ko. 15 lines: Just EXT_SOURCE_xShanth. HOME CREDIT — BUREAU DATA — FEATURE ENGINEERINGDmitriy Kisil. Good_fun_with_LigthGBM