Pré-processamento é um termo geral para todas as manipulações realizadas com os dados antes de transferir seu modelo, incluindo centralização, normalização, deslocamento, rotação, corte, etc. Como regra, o pré-processamento é necessário em dois casos.
- Limpeza de dados . Suponha que alguns artefatos estejam presentes nas imagens. Para facilitar o treinamento do modelo, os artefatos devem ser removidos no estágio de pré-processamento.
- Adição de dados . Às vezes, pequenos conjuntos de dados não são suficientes para o treinamento profundo de modelos de alta qualidade. Uma abordagem de suplemento de dados é muito útil para resolver esse problema. Esse é o processo de transformar cada amostra de dados de várias maneiras e adicionar essas amostras modificadas ao conjunto de dados. Dessa maneira, o tamanho efetivo do conjunto de dados pode ser aumentado.
Vamos considerar alguns métodos de transformação possíveis durante o pré-processamento e sua implementação através do Keras.

Dados
Neste e nos artigos subsequentes, um conjunto de dados será usado para analisar a coloração emocional das imagens. Ele contém 1.500 exemplos de imagens, divididas em duas classes - positiva e negativa. Vejamos alguns exemplos.
 Exemplos negativos
Exemplos negativos Exemplos positivos
Exemplos positivosTransformações de limpeza
Agora considere um conjunto de possíveis transformações comumente usadas para limpar dados, sua implementação e impacto nas imagens.
Todos os trechos de código podem ser encontrados no livro
Preprocessing.ipynb .
Reescalonar
As imagens geralmente são armazenadas no formato RGB (Vermelho Verde Azul). Nesse formato, a imagem é representada por uma matriz tridimensional (ou três canais).
 Decomposição RGB da imagem. Gráfico retirado do Wikiwand
Decomposição RGB da imagem. Gráfico retirado do WikiwandUma dimensão é usada para canais (vermelho, verde e azul), as outras duas representam a localização. Assim, cada pixel é codificado com três números. Cada número é geralmente armazenado como um tipo inteiro não assinado de 8 bits (0 a 255).
O redimensionamento é uma operação que altera o intervalo numérico de dados, simplesmente dividindo-o por uma constante predeterminada. Em redes neurais profundas, pode ser necessário limitar os dados de entrada a um intervalo de 0 a 1 devido a possíveis transbordamentos, problemas de otimização, estabilidade etc.
Por exemplo, redimensionamos nossos dados do intervalo [0; 255] para o intervalo [0; 1] A seguir, usaremos a classe Keras
ImageDataGenerator , que permite executar todas as transformações em tempo real.
Vamos criar duas instâncias dessa classe: uma para os dados transformados e outra para a fonte:

(ou para dados padrão). Só é necessário especificar a constante de escala. Além disso, a classe
ImageDataGenerator permite transmitir dados diretamente de uma pasta no disco rígido, usando o método
flow_from_directory .
Todos os parâmetros podem ser encontrados na
documentação , mas os principais parâmetros são: o caminho para o fluxo e o tamanho da imagem de destino (se a imagem não corresponder ao tamanho de destino, o gerador simplesmente a corta ou constrói). Finalmente, obtemos uma amostra do gerador e consideramos os resultados.
Visualmente, ambas as imagens são idênticas, mas a razão para isso é porque as ferramentas Python * redimensionam automaticamente as imagens
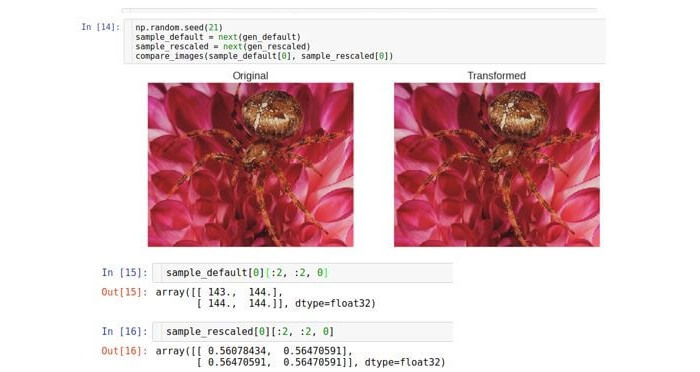
para o intervalo padrão para que eles possam ser exibidos na tela. Considere dados brutos (matrizes). Como você pode ver, os maciços brutos diferem exatamente 255 vezes.
Escala de cinza
Outro tipo de transformação que pode ser útil é a
escala de cinza , que converte uma imagem RGB colorida em uma imagem na qual todas as cores são representadas em tons de cinza. O processamento convencional de imagens pode usar a conversão em escala de cinza em combinação com um limite subsequente. Esse par de transformações pode rejeitar pixels ruidosos e definir formas na imagem. Hoje, todas essas operações são realizadas pela Rede Neural Convolucional (CNN), mas a conversão em escala de cinza como uma etapa de pré-processamento ainda pode ser útil. Execute esta etapa no Keras com a mesma classe de gerador.
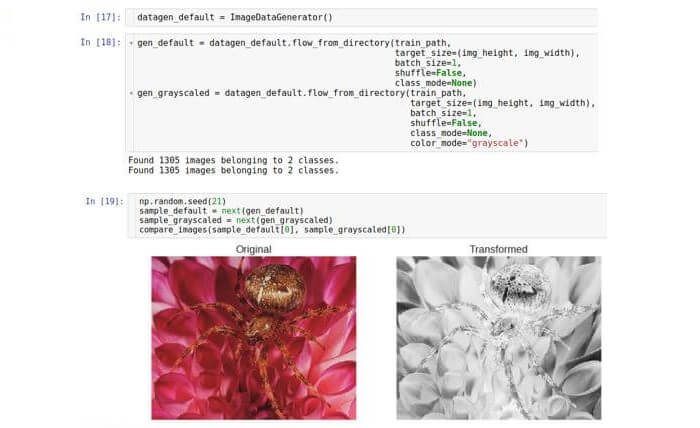
Aqui, criamos apenas uma instância da classe e usamos dois geradores diferentes. O segundo gerador define o parâmetro
color_mode como "escala de cinza" (o valor padrão é "RGB").
Amostras de centralização
Já vimos que os valores dos dados brutos estão no intervalo de 0 a 255. Portanto, uma amostra é uma matriz tridimensional de números de 0 a 255. À luz dos princípios de estabilidade da otimização (livrar-se do problema de desaparecer ou saturar valores),
pode ser necessário normalizar o conjunto de dados para que a média de cada amostra de dados seja 0 .
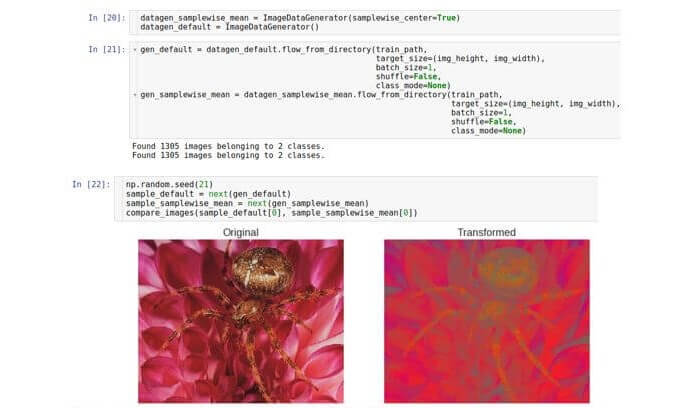
Para isso, é necessário calcular o valor médio de toda a amostra e subtraí-lo de cada número da amostra fornecida.
No Keras, isso é feito usando o parâmetro
samplewise_center .
Normalização do desvio padrão das amostras
Esse estágio de pré-processamento é baseado na mesma idéia que a centralização das amostras, mas, em vez de definir a média para 0, define o desvio padrão para 1.

A normalização do desvio
padrão é controlada pelo parâmetro
samplewise_std_normalization . Deve-se notar que esses dois métodos de normalização de amostras são frequentemente usados juntos.
Essa transformação pode ser usada em modelos de aprendizado profundo para melhorar a estabilidade da otimização, reduzindo o impacto de gradientes explosivos.
Centralização de recursos
As duas seções anteriores usaram uma técnica de normalização que analisava cada amostra individual de dados. Existe uma abordagem alternativa ao procedimento de normalização. Considere cada número na matriz de imagens como um sinal. Então
cada imagem é um vetor de recurso . Existem muitos desses vetores no conjunto de dados; portanto, podemos considerá-los como uma
distribuição desconhecida. Essa distribuição é multiparâmetros e sua dimensão será igual ao número de recursos, ou seja, largura × altura × 3. Embora a verdadeira distribuição de dados seja desconhecida, você pode tentar normalizá-la subtraindo o valor médio da distribuição. Note-se que o valor médio é um vetor da mesma dimensão, ou seja, é também uma imagem. Em outras palavras, calculamos a média de todo o conjunto de dados e não de uma amostra.
Há um parâmetro Keras especial chamado
featurewise_centering , mas, infelizmente, a partir de agosto de 2017, houve um erro na sua implementação; portanto, nós o implementamos. Primeiro, consideramos o conjunto de dados inteiro na memória (podemos pagar, pois estamos lidando com um pequeno conjunto de dados). Fizemos isso configurando o tamanho do pacote para o tamanho do conjunto de dados. Em seguida, calculamos a imagem média em todo o conjunto de dados e, finalmente, subtraímos da imagem de teste.
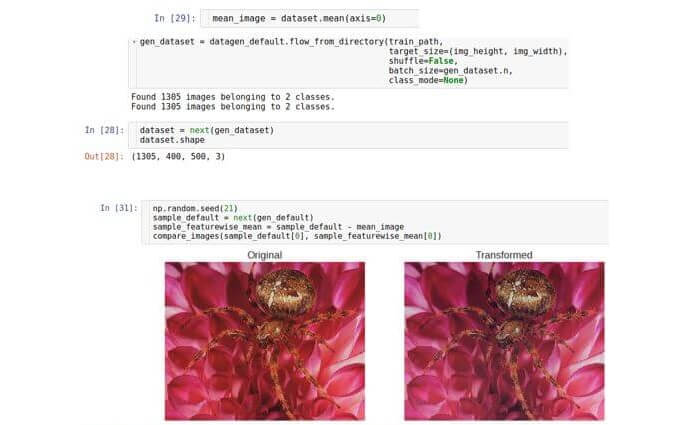
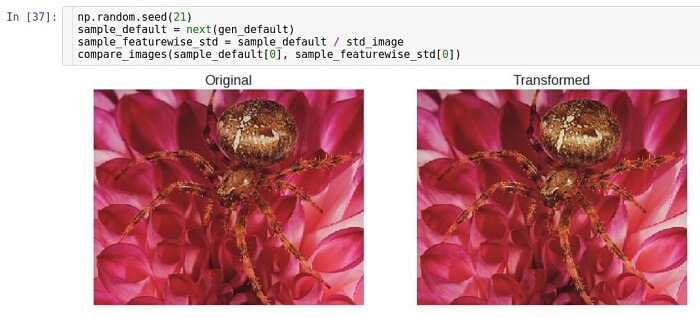
Normalização do desvio padrão dos sintomas
A idéia de normalizar o desvio padrão é exatamente a mesma que a idéia de centralização. A única diferença é que, em vez de subtrair a média, dividimos pelo desvio padrão. Visualmente, o resultado não é muito diferente. A mesma coisa aconteceu

durante o redimensionamento, uma vez que a normalização do desvio padrão nada mais é do que redimensionar com uma constante calculada de uma certa maneira e com redimensionar simples, a constante é especificada manualmente. Observe que uma idéia semelhante de normalizar pacotes de dados está no centro de uma técnica moderna de aprendizado profundo chamada
BatchNormalization .
Transformação com a adição
Nesta seção, examinamos várias transformações dependentes de dados que usam explicitamente a natureza gráfica dos dados. Esses tipos de transformações são frequentemente usados em procedimentos de adição de dados.
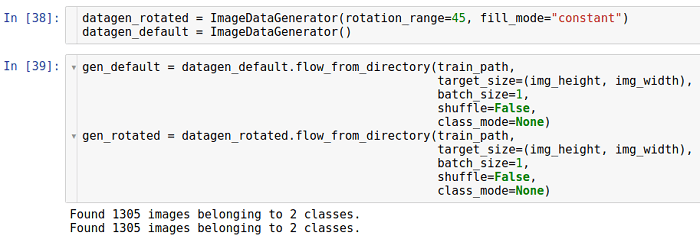
Rotação
Esse tipo de transformação gira a imagem em uma determinada direção (no sentido horário ou anti-horário).
O parâmetro que permite a rotação é chamado de
rotation_range . Indica o intervalo em graus a partir do qual o ângulo de rotação é selecionado aleatoriamente com uma distribuição uniforme. Note-se que durante a rotação o tamanho da imagem não muda. Assim, algumas partes da imagem podem ser cortadas e outras preenchidas.
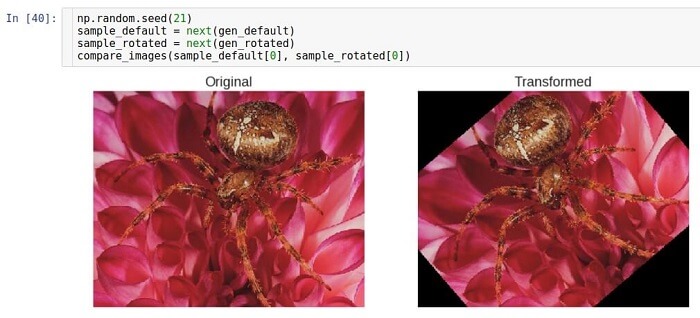
O modo de preenchimento é definido usando o parâmetro
fill_mode . Ele suporta vários métodos de preenchimento, mas aqui usamos o método
constante como exemplo.
Deslocamento horizontal
Esse tipo de transformação muda a imagem em uma determinada direção ao longo do eixo horizontal (esquerda ou direita).

O tamanho do turno pode ser determinado usando o parâmetro
width_shift_range e medido como parte da largura total da imagem.
Deslocamento vertical
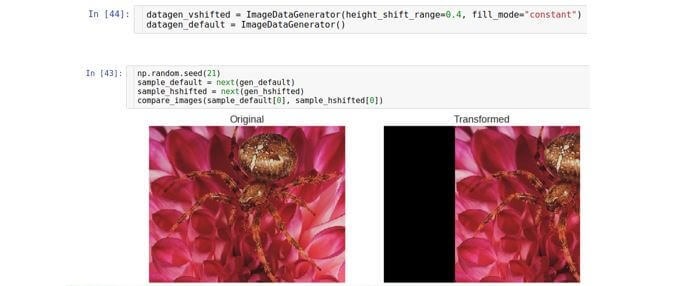
Muda a imagem ao longo do eixo vertical (para cima ou para baixo). O parâmetro que controla o intervalo de turnos é chamado de gerador
height_shift e também é medido como parte da altura total da imagem.
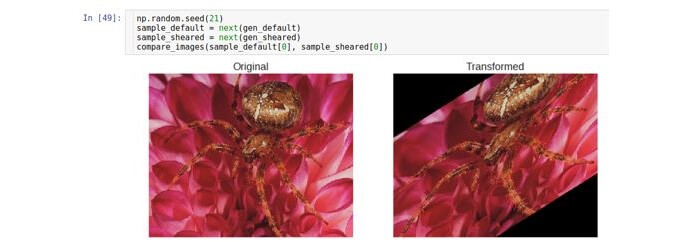
Poda
Uma conversão de corte ou corte muda cada ponto na direção vertical em uma quantidade proporcional à distância desse ponto até a borda da imagem. Observe que, no caso geral, a direção não precisa ser vertical e é arbitrária.
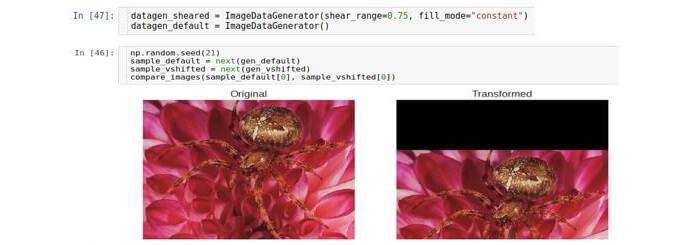
O parâmetro que controla o deslocamento é chamado
shear_range e corresponde ao ângulo de desvio (em radianos) entre a linha horizontal na imagem original e a imagem (no sentido matemático) dessa linha na imagem transformada.
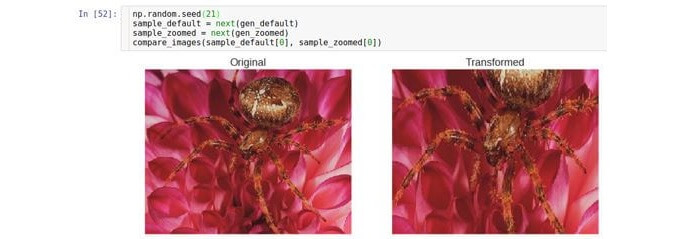
Mais / menos zoom

Esse tipo de transformação aproxima ou remove a imagem original. O parâmetro
zoom_range controla o fator de zoom.
Por exemplo, se
zoom_range for 0,5, o fator de zoom será selecionado no intervalo [0,5, 1,5].
Aleta horizontal

Inverte a imagem em relação ao eixo vertical. Pode ser ativado ou desativado usando o parâmetro
horizontal_flip .
Aleta vertical

Inverte a imagem ao redor do eixo horizontal. O parâmetro
vertical_flip (do tipo Boolean) controla a presença ou ausência dessa transformação.
Combinação
Aplicamos todos os tipos descritos de transformações do complemento ao mesmo tempo e vemos o que acontece. Lembre-se de que os parâmetros para todas as transformações são selecionados aleatoriamente em um determinado intervalo; portanto, devemos obter um conjunto de amostras com um grau significativo de diversidade.
Iniciamos o
ImageDataGenerator com todos os parâmetros disponíveis e verificamos o hidrante vermelho na imagem.

Observe que o modo de preenchimento
constante foi usado apenas para melhor visualização. Agora vamos usar um modo de preenchimento mais avançado chamado
mais próximo ; esse modo atribui a cor do pixel existente mais próximo ao pixel vazio.
Conclusão
Este artigo fornece uma visão geral das técnicas básicas de pré-processamento de imagens, como: dimensionamento, normalização, rotação, deslocamento e corte. Eles também demonstraram a implementação dessas técnicas de transformação usando Keras e sua introdução no processo de aprendizado profundo, tanto tecnicamente (classe
ImageDataGenerator ) quanto ideologicamente (suplemento de dados).