Continuamos compartilhando nossa experiência na organização do data warehouse, sobre o qual começamos a falar em uma postagem anterior . Desta vez, queremos falar sobre como resolvemos as tarefas de instalação do CDH.

Instalação CDH
Iniciamos o servidor do Cloudera Manager, adicionamos-o ao carregamento automático e verificamos que ele mudou para o estado ativo:
systemctl start cloudera-scm-server systemctl enable cloudera-scm-server systemctl status cloudera-scm-server
Após o aumento, seguimos o link "hostname: 7180 /", efetue login (admin / admin) e continue a instalação a partir da GUI. Após a autorização, a instalação será iniciada automaticamente e uma transição será feita na página para adicionar hosts ao cluster:

Recomenda-se adicionar todos os hosts que de alguma forma estejam conectados ao ambiente implementado (mesmo que eles não hospedem os serviços Cloudera). Podem ser máquinas com ferramentas de integração contínua, ferramentas de BI ou ETL ou ferramentas de descoberta de dados. A inclusão dessas máquinas no cluster permitirá que você instale os gateways dos serviços de cluster (Gateways) contendo arquivos com a configuração e o local dos serviços de cluster, o que simplificará a integração com programas de terceiros. O Cloudera Manager também fornece ferramentas de monitoramento convenientes e a criação de monitores das principais métricas para todas as máquinas de cluster em uma única janela, o que simplificará a localização de problemas durante a operação. Os hosts são adicionados usando o botão "Nova pesquisa" - é feita uma transição para a página para adicionar máquinas ao cluster, onde é proposto fornecer dados para a conexão via SSH:

Após adicionar os hosts, prosseguimos para o estágio de escolha do método de instalação. Desde que baixamos os parsels, selecionamos o método “Use Parcels (Recommended)” e agora precisamos adicionar nosso repositório. Clicamos no botão “Mais opções”, excluímos todos os repositórios padrão instalados lá e adicionamos o endereço do repositório com o CDH parsel - “hostname / parcels / cdh /”. Após a confirmação, à direita da inscrição “Selecione a versão do CDH”, a versão do CDH apresentada no pacote baixado deve ser exibida. Para este método de instalação, nada pode ser configurado nesta guia:

A próxima guia solicitará a instalação do JDK. Como já fizemos isso em preparação para a instalação, pulamos esta etapa:

Quando você passa para a próxima guia, a instalação dos componentes do cluster nos hosts especificados é iniciada. Após a conclusão da instalação, a transição para a próxima etapa estará disponível. Se durante a instalação forem encontrados erros (eu encontrei essa situação ao instalar ambientes Dev locais), é possível ver os detalhes deles usando o comando “tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log” e clicando no botão Detalhes no lado direito da tabela:

Na próxima etapa da instalação, você será solicitado a selecionar um dos conjuntos de serviços preparados para instalação. No futuro, os serviços e suas funções poderão ser configurados manualmente, portanto, não é muito importante o que escolher nessa guia. No nosso caso, o “Core with Impala” geralmente era instalado. Também aqui você pode indicar a necessidade de instalar o Cloudera Navigator. Se você estiver instalando a versão Enterprise, deverá instalar esta ferramenta útil:

Na próxima guia de serviços do conjunto selecionado, é proposto selecionar as funções e hosts nos quais eles serão instalados. Abaixo estão algumas diretrizes para a instalação de funções em hosts.
Funções HDFS
NameNode - é colocado em uma única cópia em um dos nós principais, de preferência o mais descarregado, pois é muito importante para a operação do cluster e contribui significativamente para a utilização dos recursos.
SecondaryNameNode - é colocado em uma única cópia em um dos nós principais, de preferência não no mesmo nó que o NameNode (para garantir a tolerância a falhas).
Balanceador - é colocado em uma única cópia em um dos nós principais.
HttpFS - uma API adicional para o HDFS, você não pode instalá-lo.
Gateway NFS - uma função muito útil, permite montar o HDFS como uma unidade de rede. Ele é colocado em uma única cópia em um dos nós principais.
DataNode - coloque todos os nós de dados.
Funções do Hive
Gateway - arquivos de configuração do Hive. É colocado em todos os hosts do cluster.
O Hive Metastore Server - um servidor de metadados, é instalado em uma única cópia em um dos nós principais (por exemplo, aquele em que o PostgreSQL está instalado - ele armazena seus dados).
WebHCat - não é necessário instalar.
HiveServer2 - é
instalado em uma única cópia no mesmo Nó Mestre que o Hive Metastore Server (um requisito para o trabalho conjunto).
Funções de matiz
O Hue Server - GUI para HDFS é instalado em uma única cópia em um dos nós principais.
Load Balancer - um balanceador de carga na GUI para HDFS, é instalado em uma única cópia em um dos nós principais.
Funções da Impala
Impala StateStore - é colocado em uma única cópia em um dos nós principais.
Servidor de catálogo Impala - é colocado em uma única cópia em um dos nós principais.
Impala Daemon - coloque todos os nós de dados (você pode deixar o valor padrão).
Funções de serviços do Cloudera Manager
O Service Monitor, o Activity Monitor, o Host Monitor, o Gerenciador de Relatórios, o Servidor de Eventos e o Alert Publisher são instalados em uma única cópia em um dos Nós Principais.
Papéis de Oozie
Servidor Oozie - é colocado em uma única cópia em um dos nós principais.
Funções Fios
ResourceManager - é colocado em uma única cópia em um dos nós principais.
JobHistory Server - é
instalado em uma única cópia em um dos nós principais.
NodeManager - coloque todos os nós de dados (você pode deixar o valor padrão).
Funções do ZooKeeper
Servidor ZooKeeper - para garantir a tolerância a falhas, ele é instalado em triplicado nos nós principais.
Funções do Cloudera Navigator
Servidor de auditoria do navegador - é instalado em uma única cópia em um dos nós principais.
Servidor de metadados do navegador - é colocado em uma única cópia em um dos nós principais.

Após a distribuição de funções, há uma guia com uma pequena lista de configurações dos serviços instalados. Suas alterações estarão disponíveis após a instalação e, nesse estágio, elas poderão ser alteradas:

Após as configurações do serviço, há uma configuração de banco de dados para os serviços que precisam deles. Nós inserimos o nome completo do host no qual o PostgreSQL está instalado, nas caixas de listagem “Tipo de banco de dados”, selecionamos o item apropriado e nos campos restantes especificamos os dados para conexão com os bancos de dados correspondentes. Após a inserção de todos os dados, clique no botão "Testar conexão" e verifique se os bancos de dados estão disponíveis. Se for esse o caso, no lado direito da tabela, em frente a cada um dos bancos de dados, a inscrição “Successful” aparecerá:

Tudo está pronto para a implantação de serviços. Vá para a próxima guia e observe este processo. Se fizermos tudo certo, todas as etapas serão concluídas com êxito. Caso contrário, o processo será interrompido em uma das etapas e o log de erros estará disponível pressionando a seta:

Parabéns - o CDH está em funcionamento!

Você pode prosseguir com a instalação de analisadores adicionais.
Configurando Parselas Adicionais
Nos casos em que o conjunto básico de serviços CHD não é suficiente ou se é necessária uma versão mais recente, você pode instalar analisadores adicionais que expandem a lista disponível de serviços que podem ser implementados no cluster. Durante nosso projeto, precisávamos do serviço Spark versão 2.2 para iniciar as tarefas desenvolvidas e o funcionamento das ferramentas de Descoberta de Dados. Não faz parte do CDH, portanto, instale-o separadamente. Para fazer isso, clique no botão "Hosts" e selecione o item da lista suspensa "Parcelas":

Uma guia com parsels é aberta, mostrando uma lista de clusters gerenciados por este Cloudera Manager e os parsels instalados neles. Para adicionar um parsel com o Spark 2.2, selecione o cluster desejado e clique no botão "Configuração" no canto superior direito.

Clicamos no botão "+", na linha que aparece, indicamos o endereço do repositório com o parsel Spark 2.2 ("hostname / parcels / spark /") e clicamos no botão "Salvar alterações":

Após essas manipulações, uma nova com o nome SPARK2 deve aparecer na lista de parcelas na guia anterior. Inicialmente, ele aparece como disponível para download; portanto, o próximo passo é fazer o download clicando no botão "Download":

A análise baixada precisa estar dispersa nos nós do cluster para que os serviços possam ser instalados a partir dele. Para fazer isso, clique no botão "Distribuir" que aparece no lado direito da linha com o parsel SPARK2:

O último passo para trabalhar com o pacote é ativá-lo. Para ativá-lo, clique no botão "Ativar", que aparece no lado direito da linha com a opção Parsel:

Após a confirmação, o serviço necessário fica disponível para instalação. Mas existem nuances. Para instalar alguns serviços no cluster, você precisa executar quaisquer ações adicionais além de instalar o parsel. Geralmente, isso está escrito no site oficial na seção sobre instalação e atualização deste serviço (aqui está o exemplo dela para o Spark 2 - www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html ). Nesse caso, você precisa fazer o download do arquivo CSD do Spark 2 (disponível na página Informações sobre versão e empacotamento - www.cloudera.com/documentation/spark2/latest/topics/spark2_packaging.html ), instalá-lo no host com o Cloudera Manager e reiniciar o último. Vamos fazer isso - faça o download deste arquivo, transfira-o para o host desejado e execute os comandos nas instruções:
mv SPARK2_ON_YARN-2.1.0.cloudera1.jar /opt/cloudera/csd/ chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar chmod 644 /opt/cloudera/csd/SPARK2_ON_YARN-2.1.0.cloudera1.jar systemctl restart cloudera-scm-server
Quando o Cloudera Manager surgir, tudo estará pronto para instalar o Spark 2. Na tela principal, clique na seta à direita do nome do cluster e selecione o item "Adicionar serviço" no menu suspenso:

Na lista de serviços disponíveis para instalação, selecione o que precisamos:

Na próxima guia, selecione o conjunto de dependências para o novo serviço. Por exemplo, aquele em que a lista é mais ampla:

Em seguida, vem a guia com a escolha de funções e hosts nos quais eles serão instalados, semelhante ao que estava durante a instalação do CDH. É recomendável que você coloque a função de servidor de histórico em uma única cópia em um dos nós principais e o gateway em todos os servidores de cluster:

Após selecionar as funções, propõe-se verificar e confirmar as alterações feitas no cluster durante a instalação do serviço. Aqui você pode deixar tudo por padrão:

A confirmação das alterações inicia a instalação do serviço no cluster. Se tudo for feito corretamente, a instalação será concluída com êxito:
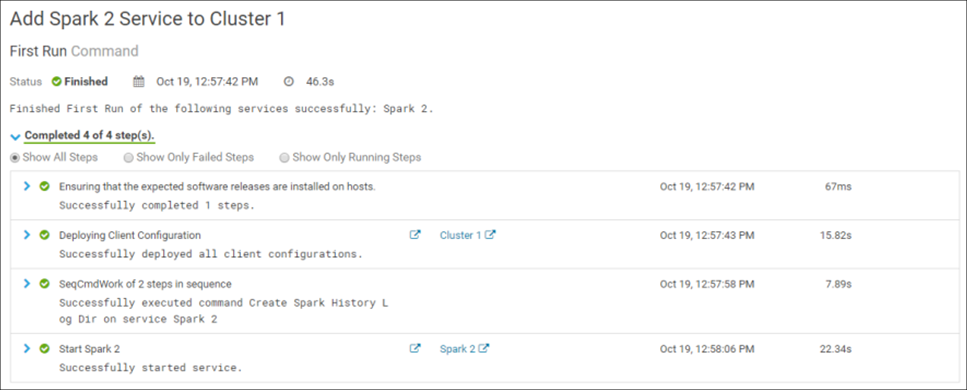
Parabéns! O Spark 2 foi instalado com sucesso no cluster:

Você deve reiniciar o cluster para concluir o processo de instalação. Depois disso, tudo está pronto para ir.
Erros podem ocorrer durante a fase de instalação do serviço. Por exemplo, ao instalar em um dos ambientes, não foi possível implantar a função do Spark 2 Gateway. A solução para esse problema foi ajudada pela cópia do conteúdo do arquivo / var / lib / alternative / spark2-conf do host no qual essa função foi instalada com êxito em um arquivo semelhante na máquina com problemas. Para diagnosticar erros de instalação, é conveniente usar os arquivos de log dos processos correspondentes, armazenados na pasta / var / run / cloudera-scm-agent / process /.
Isso é tudo por hoje. O próximo post da série abordará o tópico de administração de cluster CDH.