Recentemente, a competição Desafio iMaterialist (Furniture) terminou em Kaggle, na qual a tarefa era classificar imagens em 128 tipos de móveis e utensílios domésticos (a chamada classificação refinada, onde as classes são muito próximas umas das outras).
Neste artigo, descreverei a abordagem que nos trouxe o terceiro lugar com o
m0rtido , mas antes de
prosseguir com o assunto, proponho o uso da rede neural natural na minha cabeça para resolver esse problema e a divisão das cadeiras na foto abaixo em três classes.

Você adivinhou certo? Eu também não.
Mas pare, primeiro as coisas primeiro.
Declaração do problema
Na competição, recebemos um conjunto de dados no qual 128 classes de objetos domésticos comuns foram apresentados, como cadeiras, televisões, panelas e travesseiros na forma de personagens de anime.
A parte de treinamento do conjunto de dados consistia em ~ 190 mil imagens (é difícil dizer o número exato, porque os participantes receberam apenas um conjunto de URLs de download, alguns dos quais, é claro, não funcionaram) e a distribuição das aulas estava longe de ser uniforme (veja a imagem clicável abaixo) .

O conjunto de dados de teste foi representado por 12800 imagens e foi perfeitamente equilibrado: havia 100 imagens para cada classe. Também foi emitido um conjunto de dados de validação, que também tinha uma distribuição equilibrada de classes e tinha exatamente a metade do tamanho do teste.
A métrica de avaliação de tarefas foi
.
Como decidimos?
Primeiro, baixamos os dados e examinamos uma pequena parte com nossos olhos. Em vez de muitas fotos, foi baixada uma imagem 1x1 ou um espaço reservado com erro. Excluímos imediatamente essas imagens com um script.
Transferência de aprendizado
Era óbvio que, com o número disponível de imagens e prazos, não é uma boa ideia treinar redes neurais a partir do zero nesse conjunto de dados. Em vez disso, usamos a abordagem de aprendizado de transferência, cuja ideia é a seguinte: o peso da rede treinada em uma tarefa pode ser usado para um conjunto de dados completamente diferente e obter qualidade decente ou até um aumento na precisão em comparação com o aprendizado do zero.
Como isso funciona? Camadas ocultas em redes neurais profundas atuam como extratores de recursos, extraindo recursos que são então usados pelas camadas superiores diretamente para classificação.
Aproveitamos isso ao concluir uma série de CNNs profundas previamente treinadas no ImageNet. Para esses fins, usamos o Keras e seu zoológico de modelos, onde o código a seguir foi suficiente para carregar a arquitetura finalizada:
base_model = densenet.DenseNet201(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3), pooling='avg')
Depois disso, extraímos os chamados sinais de gargalo (recursos na saída da última camada convolucional) da rede e treinamos softmax com
dropout em cima deles.
Em seguida, conectamos os pesos "superiores" treinados à parte convolucional da rede e treinamos toda a rede de uma só vez.
Ver código. for layer in base_model.layers: layer.trainable = True top_model = Sequential() top_model.add(Dropout(0.5, name='top_dropout', input_shape=base_model.output_shape[1:])) top_model.add(Dense(128, activation='softmax', name='top_softmax')) top_model.load_weights('top-weights-densenet.hdf5', by_name=True) model = Model(inputs=base_model.input, outputs=top_model(base_model.output)) initial_lrate = 0.0005 model.compile(optimizer=Adam(lr=initial_lrate), loss='categorical_crossentropy', metrics=['accuracy'])
Com esse ajuste fino das redes, conseguimos experimentar os seguintes hacks:
- Aumento de dados . Para combater o super ajuste, usamos um aumento muito rigoroso: reflexão horizontal, zoom, mudanças, rotações, inclinações, adição de ruído de cores, mudanças de canal de cores, treinamento em cinco linhas de corte (ângulos e centro da imagem). Também queríamos experimentar o FancyPCA , mas falhamos devido à falta de recursos de computação.
- TTA Para prever aulas de validação e teste, usamos aumento, um pouco menos agressivo do que durante o treinamento, e calculamos a média dos resultados das previsões para aumentar a precisão.
- Taxa de aprendizagem de ciclismo . O aumento cíclico e a diminuição do ritmo do treinamento ajudaram os modelos a não ficarem presos em pontos baixos locais.
- Modele o treinamento em um subconjunto de classes . Como você pode ver na figura acima, o conjunto de dados continha classes muito próximas umas das outras. Tão perto que em certos grupos de objetos (por exemplo, em cadeiras e poltronas, representadas até 8 classes), nossos modelos estavam muito mais equivocados do que em outros tipos de objetos. Tentamos treinar uma CNN separada para reconhecer apenas cadeiras, esperando que essa rede aprendesse a distinguir variedades de cadeiras melhor do que uma rede de uso geral, mas essa abordagem não deu um aumento na precisão.
Porque Parte da resposta a esta pergunta é apresentada na figura antes do corte - as classes eram tão semelhantes que, mesmo com a marcação inicial dos dados, as pessoas que colocavam os rótulos das classes não conseguiam distinguir entre elas, portanto não seria possível extrair esses dados com boa precisão. - Rede de transformadores espaciais . Apesar de termos treinado uma das redes e ter uma precisão muito boa, infelizmente ela não foi incluída na submissão final.
- Função de perda ponderada . Para compensar a distribuição desequilibrada de classes, usamos perda ponderada. Isso ajudou no treinamento de softmax “tops” e no treinamento adicional de toda a rede. Os pesos foram calculados usando a função do scikit-learn e depois passados para o método de ajuste do modelo:
train_labels = utils.to_categorical(train_generator.classes) y_integers = np.argmax(train_labels, axis=1) class_weights = compute_class_weight('balanced', np.unique(y_integers), y_integers)
As redes treinadas dessa maneira representaram 90% do nosso conjunto final.
Empilhamento de tags de gargalo
Isenção de responsabilidade: nunca repita a técnica descrita mais tarde na vida real.
Portanto, como determinamos na seção anterior, os recursos de gargalo das redes treinadas no ImageNet podem ser usados para classificação em outras tarefas.
m0rtido decidiu ir mais longe e propôs a seguinte estratégia:
- Tomamos todas as arquiteturas pré-treinadas disponíveis para nós (em particular, foram adotadas NasNet Large, InceptionV4, Vgg19, Vgg16, InceptionV3, InceptionResnetV2, Resnet-50, Resnet-101, Resnet-152, Xception, Densenet-169, Densenet-121, Densenet-201 ) e extraia deles sinais de gargalo. Também contaremos os sinais para as versões refletidas das imagens (um aumento tão minimalista).
- Reduza a dimensão dos recursos de cada um dos modelos em três vezes, com a ajuda do SAR, para que eles se ajustem normalmente à RAM de 16 Gb disponível para nós.
- Concatene esses recursos em um grande vetor de recursos.
- Ensinaremos um perceptron multicamada sobre tudo isso e geraremos previsões. Também treinaremos com quebra de dobras e calcularemos a média de todas essas previsões.
O empilhamento monstruoso resultante deu um enorme aumento de precisão ao conjunto geral.
Conjunto de modelos
Depois de tudo isso, tínhamos cerca de duas dúzias de redes convolucionais obscurecidas, além de dois perceptrons em cima de sinais de gargalo. A questão era: como obter uma única previsão de tudo isso?
De uma maneira boa, na melhor tradição do Kaggle, tivemos que
empilhar tudo isso, mas para fazer o empilhamento OOF, não tínhamos tempo nem GPU, e treinar um modelo de nível superior em validação resultou em um super ajuste muito grande. Portanto, decidimos implementar um algoritmo bastante simples para a criação de conjuntos gananciosos:
- Inicialize um conjunto vazio.
- Tentamos adicionar cada modelo por vez e considerar a pontuação. Selecionamos o modelo que aumenta a métrica e o adicionamos ao conjunto. Os resultados da previsão de modelos no conjunto são simplesmente calculados em média.
- Se nenhum dos modelos melhorar o desempenho, examinamos o conjunto e tentamos removê-lo. Se você remover algum modelo para melhorar a pontuação, faremos isso e voltaremos à etapa 2.
Como uma métrica foi selecionada
. Esta fórmula foi escolhida empiricamente de tal maneira que
e
acabou por ser sobre a mesma escala. Essa métrica integral correlacionou-se bem com
na validação e em uma tabela de classificação pública.
Além disso, o fato de que a cada iteração adicionamos ou removemos um modelo (ou seja, os pesos do modelo sempre permaneceram inteiros) desempenhou o papel de um tipo de regularização, não permitindo que o conjunto se super-ajustasse ao conjunto de dados de validação.
Como resultado, o conjunto incluiu os seguintes modelos:
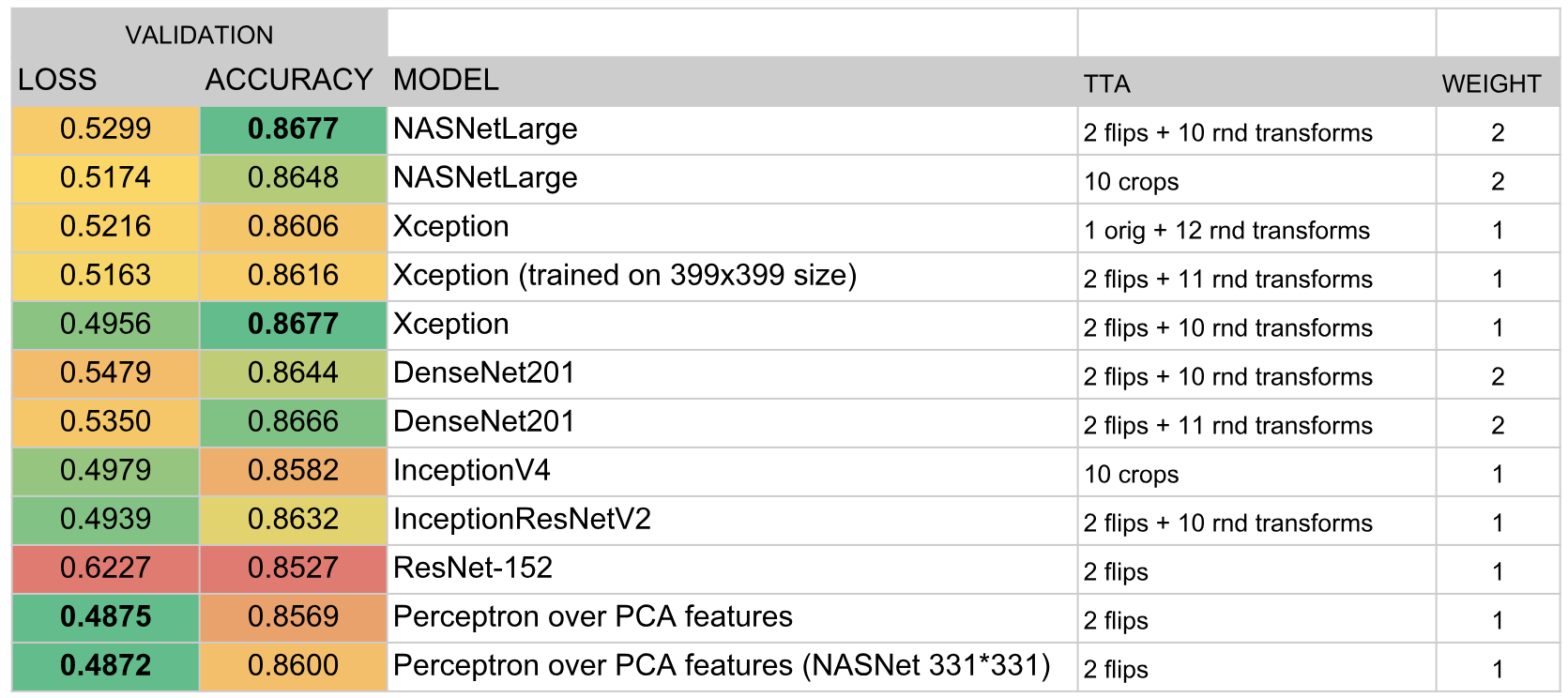
Resultados
De acordo com os resultados da competição, conquistamos o terceiro lugar. A chave do sucesso, ao que me parece, foi a escolha bem-sucedida do algoritmo do conjunto e a enorme quantidade de tempo que eu e o
m0rtido investimos no treinamento de um grande número de modelos.
