Oi Meu nome é Sergey, trabalho como engenheiro-chefe em Sbertekh. Estou no campo de TI há cerca de 10 anos, dos quais 6 estão envolvidos em bancos de dados, processos ETL, DWH e tudo relacionado a dados. Neste artigo, falarei sobre o Vertica - um DBMS analítico e verdadeiramente colunar que compacta, armazena, entrega rapidamente dados e é ótimo como uma solução de big data.

Informação geral
O big data começou a se desenvolver nos anos 2000, e eram necessários mecanismos que pudessem digerir tudo. Em resposta a isso, vários DBMS colunares destinados a esse fim apareceram - incluindo o Vertica.
A Vertica não apenas armazena seus dados em colunas, mas racionalmente, com um alto grau de compactação, também agenda com eficiência consultas e fornece dados rapidamente. As informações, que em um DBMS clássico em minúsculas ocupam cerca de 1 TB de espaço em disco, no Vertica levarão de 200 a 300 GB, assim, obtemos boas economias em discos.
O Vertica foi originalmente projetado como uma coluna DBMS. Outras bases basicamente tentam imitar vários mecanismos de coluna, mas nem sempre são bem-sucedidas porque o mecanismo ainda é projetado para processar seqüências de caracteres. Como regra, os imitadores simplesmente transpõem a tabela e depois a processam com o mecanismo de linha usual.
O Vertica é tolerante a falhas, não possui um nó de controle - todos os nós são iguais. Se houver problemas com um dos servidores no cluster, ainda receberemos os dados. Muitas vezes, o recebimento de dados no prazo é fundamental para os clientes comerciais, especialmente no momento em que os relatórios são fechados e você precisa fornecer informações às autoridades financeiras.
Áreas de aplicação
Vertica é principalmente um armazém de dados analíticos. Você não deve escrever em pequenas transações, não deve estragar em nenhum site, etc. O Vertica deve ser considerado como um tipo de camada em lote, onde vale a pena imergir dados em pacotes grandes. Se necessário, a Vertica está pronta para fornecer esses dados rapidamente - consultas para milhões de linhas são concluídas em segundos.
Onde isso pode ser útil? Tomemos, por exemplo, uma empresa de telecomunicações. O Vertica pode ser usado nele para geoanalítica, desenvolvimento de rede, gerenciamento de qualidade, marketing direcionado, estudando informações de centros de contato, gerenciando saídas de clientes e soluções antifraude / antispam.

Em outros setores de negócios, tudo é o mesmo - análises oportunas e confiáveis são importantes para o lucro. No comércio, por exemplo, todo mundo está tentando personalizar de alguma forma os clientes, distribuir cartões de desconto para isso, coletar dados sobre onde, o que e quando uma pessoa comprou, etc. Ao analisar as matrizes de informações de todos esses canais, podemos compará-las, criar modelos e tomar decisões que levem ao crescimento do lucro.
Limiar de entrada
Hoje, qualquer empregador exige que um analista entenda o que é SQL. Se você conhece o ANSI SQL, pode ser chamado de usuário confiável da Vertica. Se você pode criar modelos em Python e R, então você é apenas um "massagista" de dados. Se você domina o Linux e possui conhecimentos básicos de administração da Vertica, poderá trabalhar como administrador. Em geral, o limiar de entrada no Vertica é baixo, mas, é claro, todas as nuances podem ser encontradas apenas com o auxílio de uma mão durante a operação.
Arquitetura de hardware
Considere o Vertica em nível de cluster. Esse DBMS fornece processamento de dados massivamente paralelo (MPP) em uma arquitetura de computação distribuída - “nada compartilhado” - onde, em princípio, qualquer nó está pronto para captar as funções de qualquer outro nó. Propriedades principais:
- Não há um ponto único de falha
- cada nó é independente e independente,
- Não há um único ponto de conexão para todo o sistema,
- nós de infraestrutura são duplicados,
- os dados nos nós do cluster são copiados automaticamente.
O cluster é dimensionado linearmente sem problemas. Simplesmente colocamos os servidores em uma prateleira e os conectamos através de uma interface gráfica. Além de servidores seriais, a implantação em máquinas virtuais é possível. O que pode ser alcançado com a extensão?
- Aumento de volume para novos dados
- Aumentar a carga de trabalho máxima
- Melhorando a resiliência. Quanto mais nós no cluster, menor a probabilidade de falha do cluster devido a falha e, portanto, mais próximos estamos de garantir a disponibilidade 24/7.
Mas há algumas coisas a considerar. Periodicamente, os nós devem ser removidos do cluster para manutenção. Outro caso bastante comum em grandes organizações é que os servidores ficam fora da garantia e passam de produtivos para algum tipo de ambiente de teste. Em seu lugar, há novos que estão sob a garantia do fabricante. Com base nos resultados de todas essas operações, é necessário reequilibrar. Esse é um processo em que os dados são redistribuídos entre os nós - portanto, a carga de trabalho é redistribuída. Este é um processo que consome muitos recursos e, em clusters com uma grande quantidade de dados, pode reduzir bastante o desempenho. Para evitar isso, você precisa selecionar a janela de serviço - o momento em que a carga é mínima, caso em que os usuários não notarão.
Projeções
Para entender como os dados são armazenados no Vertica, você precisa lidar com um dos conceitos básicos - projeção.
As unidades lógicas de armazenamento de informações são diagramas, tabelas e visualizações. Unidades físicas são projeções. As projeções são de vários tipos:
- Superprojeção
- Projeções específicas de consulta
- Projeções Agregadas
Ao criar qualquer tabela, é criada automaticamente uma
super projeção que contém todas as colunas da nossa tabela. Se você precisar acelerar qualquer um dos processos regulares, podemos criar uma
projeção orientada a consultas especial que conterá, por exemplo, 3 das 10 colunas.
O terceiro tipo também se destina
a projeções agregadas por aceleração. Não vou entrar nas subclasses deles - isso não é muito interessante. Quero avisar imediatamente que não vale a pena resolver constantemente seus problemas com a execução de consultas, criando novas projeções. Eventualmente, o cluster começará a ficar mais lento.
Ao criar projeções, precisamos avaliar se nossas consultas têm superprojeções suficientes. Se ainda queremos experimentar, adicionamos estritamente uma nova projeção. Se surgirem problemas, será mais fácil encontrar a causa raiz. Para tabelas grandes, crie uma projeção segmentada. Ele é dividido em segmentos que são distribuídos por vários nós, o que aumenta a tolerância a falhas e minimiza a carga em um nó. Se os tablets forem pequenos, é melhor fazer projeções não segmentadas. Eles são completamente copiados para cada nó e, portanto, o desempenho é aumentado. Farei uma reserva: em termos de Vertica, uma tabela "pequena" tem cerca de 1 milhão de linhas.
Tolerância a falhas
A tolerância a falhas no Vertica é implementada usando o mecanismo K-Safety. É bastante simples em termos de descrição, mas complexo em termos de trabalho no nível do motor. Pode ser controlado usando o parâmetro K-Safety - pode ter um valor de 0, 1 ou 2. Este parâmetro define o número de cópias dos dados de projeção segmentados.
Cópias de projeções são chamadas de projeções de amigos. Eu tentei traduzir essa frase através do tradutor Yandex e resultou em algo como uma "projeção de ajudante". Google ofereceu opções e mais interessante. Normalmente, essas projeções são chamadas de parceiras ou vizinhas, de acordo com sua finalidade funcional. Essas são projeções que são simplesmente armazenadas em nós vizinhos e, portanto, reservadas. Projeções não segmentadas não têm projeções de amigos - elas são copiadas completamente.
Como isso funciona? Considere um cluster de cinco máquinas. Seja K-safety igual a 1.

Os nós são numerados e, abaixo deles, são projetadas gravações de parceiros que são armazenadas neles. Suponha que tenhamos um nó desconectado. O que vai acontecer?

O nó 1 contém uma projeção amigável do nó 2. Portanto, a carga no nó 1 aumentará, mas o cluster não parará de funcionar. E agora esta situação:
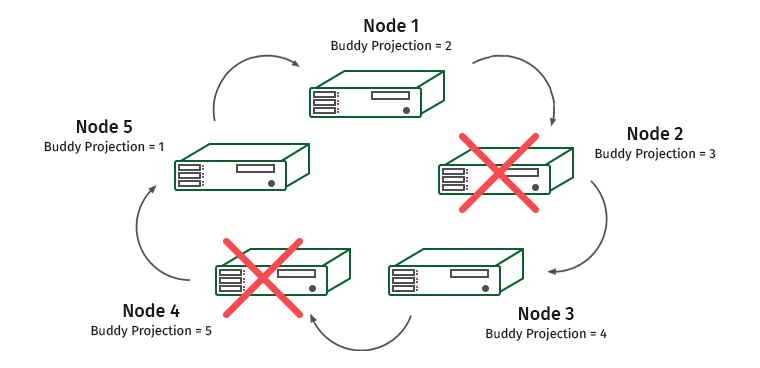
O nó 3 contém a projeção do nó 4 e os nós 1 e 3 serão sobrecarregados.
Nós complicamos a tarefa. K-Safety = 2, desative dois nós adjacentes.
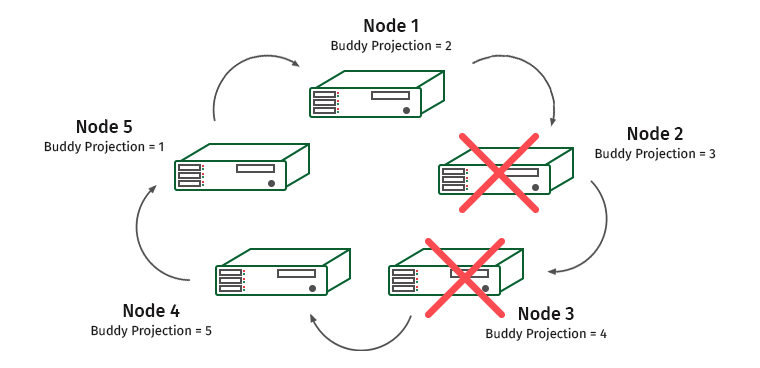
Aqui os nós 1 e 4 serão sobrecarregados (o nó 2 contém a projeção do nó 1 e o nó 3 contém a projeção do nó 4).
Nessas situações, o mecanismo do sistema reconhece que um dos nós não está respondendo e a carga é transferida para o nó vizinho. Ele será usado até que o nó seja restaurado novamente. Quando isso acontece, a carga e os dados são redistribuídos novamente. Assim que perdemos mais da metade do cluster ou nós que contêm todas as cópias de alguns dados, o cluster é ativado.
Armazenamento de dados lógicos
A Vertica possui áreas de armazenamento otimizadas para gravação, áreas otimizadas para leitura e um mecanismo de Tuple Mover que permite que os dados fluam do primeiro para o segundo.
Ao usar as operações COPY, INSERT, UPDATE, terminamos automaticamente no WOS (Write Optimized Store), uma área em que os dados não são otimizados para leitura e classificados apenas quando solicitados, armazenados sem compactação ou indexação. Se os volumes de dados forem muito grandes para a área WOS, usando a instrução DIRECT adicional, eles deverão ser gravados imediatamente no ROS. Caso contrário, o WOS estará cheio e nós travaremos.
Após o tempo especificado nas configurações expirar, os dados do WOS fluem para o ROS (Read Optimized Store) - uma estrutura otimizada e orientada para a leitura do armazenamento em disco. O ROS armazena a maior parte dos dados, aqui eles são classificados e compactados. Os dados do ROS são divididos em contêineres de armazenamento. Um contêiner é um conjunto de linhas criadas por operadores de tradução (COPY DIRECT) e é armazenado em um grupo específico de arquivos.
Independentemente de onde os dados são gravados - no WOS ou no ROS - eles estão disponíveis imediatamente. Mas a leitura do WOS é mais lenta porque os dados não estão agrupados lá.

O Tuple Mover é uma ferramenta de limpeza que executa duas operações:
- Mudança - compacta e classifica dados no WOS, move-os para o ROS e cria novos contêineres para eles no ROS.
- Mergeout - varrendo para trás quando usamos DIRECT. Nem sempre conseguimos carregar tanta informação para obter grandes contêineres ROS. Portanto, periodicamente combina pequenos contêineres ROS em outros maiores, limpa os dados marcados para exclusão enquanto trabalha em segundo plano (de acordo com o tempo especificado na configuração).
Quais são os benefícios do armazenamento em coluna?
Se lermos linhas, por exemplo, para executar um comando
SELECT 1,11,15 from table1
teremos que ler a tabela inteira. Esta é uma enorme quantidade de informações. Nesse caso, a abordagem de coluna é mais lucrativa. Permite contar apenas as três colunas necessárias, economizando memória e tempo.

Alocação de recursos
Para evitar problemas, o usuário precisa ser um pouco limitado. Sempre há uma chance de o usuário escrever uma solicitação pesada que consome todos os recursos. Por padrão, a Vertica ocupa uma parte significativa da área Geral e, além disso, são destacadas áreas separadas para o Tuple Mover, o WOS e os processos do sistema (recuperação, etc.).
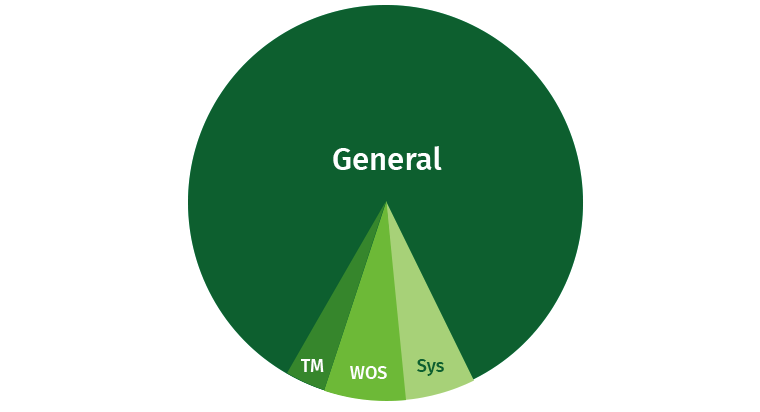
Vamos tentar compartilhar esses recursos. Criamos áreas para escritores, leitores e consultas lentas e de baixa prioridade.

Se olharmos para as tabelas do sistema em que nossos recursos estão armazenados - pools de recursos -, veremos muitos parâmetros com os quais você pode ajustar tudo de maneira mais precisa. No início, você não deve se aprofundar nisso, é melhor simplesmente limitar-se a cortar a memória para determinadas tarefas. Quando você ganha experiência e tem 100% de certeza de que está fazendo tudo corretamente, será possível experimentar.
As configurações finas incluem prioridade de execução, sessões competitivas e a quantidade de memória alocada. E mesmo com processadores, podemos consertar alguma coisa: para trabalhar com essas configurações, você precisa de total confiança na correção de suas ações, para que seja melhor contar com o apoio dos negócios e ter o direito de cometer um erro.
Abaixo está um exemplo de uma solicitação pela qual você pode ver as configurações do pool Geral:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |ANSI SQL e outros recursos
- O Vertica permite escrever no SQL-99 - todas as funcionalidades são suportadas.
- A Verica possui excelentes recursos analíticos - até ferramentas de aprendizado de máquina estão incluídas
- Vertica pode indexar textos
- Vertica processa dados semiestruturados
Integração
O Vertica, como todas as ferramentas atuais, está seriamente integrado com outros sistemas. Capaz de funcionar bem com o HDFS (Hadoop). Nas versões anteriores, o Vertica só podia baixar dados do HDFS de determinados formatos, mas agora ele pode fazer tudo, funciona com todos os formatos, por exemplo, ORC e Parquet. Pode até anexar arquivos como tabelas externas e armazenar seus dados em contêineres ROS diretamente no HDFS. Na oitava versão do Vertica, uma otimização significativa da velocidade de trabalho com o HDFS, foi realizado um catálogo de metadados e a análise desses formatos. Você pode criar um cluster Vertica diretamente em um cluster Hadoop.
A partir da versão 7.2, o Vertica pode funcionar com o Apache Kafka - se alguém precisar de um intermediário de mensagens.
O Vertica 8 tem suporte completo para o Spark. É possível copiar dados do Spark para o Vertica e vice-versa.
Conclusão
O Vertica é uma boa opção para trabalhar com big data que não requer muito conhecimento de entrada. Este DBMS possui amplos recursos analíticos. Dos pontos negativos - essa solução não é de código aberto, mas você pode tentar implantar gratuitamente com um limite de 1 TB e três nós - isso é suficiente para entender se você precisa do Vertica ou não.