Todos os sistemas modernos de moderação usam
crowdsourcing ou machine learning, que já se tornou um clássico. No próximo treinamento de ML em Yandex, Konstantin Kotik, Igor Galitsky e Alexey Noskov conversaram sobre sua participação no concurso para a identificação em massa de comentários ofensivos. A competição foi realizada na plataforma Kaggle.
- Olá pessoal! Meu nome é Konstantin Kotik, sou cientista de dados da empresa Button of Life, estudante do departamento de física e da Escola de Negócios da Universidade Estadual de Moscou.
Hoje, nossos colegas, Igor Galitsky e Alexei Noskov, falarão sobre a competição Desafio de Classificação de Comentários Tóxicos, na qual nossa equipe DecisionGuys ficou em 10º lugar entre 4551 equipes.
Uma discussão on-line de tópicos importantes para nós pode ser difícil. Os insultos, agressão e assédio que ocorrem on-line muitas vezes obrigam muitas pessoas a abandonar a busca por várias opiniões apropriadas sobre questões de seu interesse, a se recusarem a se expressar.
Muitas plataformas lutam para se comunicar efetivamente online, mas isso muitas vezes leva muitas comunidades a simplesmente fechar os comentários dos usuários.
Uma equipe de pesquisa do Google e outra empresa está trabalhando em ferramentas para ajudar a melhorar as discussões on-line.
Um dos truques em que eles se concentram é explorar comportamentos on-line negativos, como comentários tóxicos. Estes são comentários que podem ser ofensivos, desrespeitosos ou podem simplesmente forçar o usuário a sair da discussão.

Até o momento, esse grupo desenvolveu uma API pública que pode determinar o grau de toxicidade de um comentário, mas seus modelos atuais ainda cometem erros. E nessa competição, nós, os Kegglers, fomos desafiados a construir um modelo que fosse capaz de identificar comentários contendo ameaças, ódio, insultos e afins. E, idealmente, era necessário que esse modelo fosse melhor que o modelo atual para sua API.
Temos a tarefa de processar o texto: identificar e depois classificar os comentários. Como amostras de treinamento e teste, comentários foram fornecidos nas páginas de discussão da Wikipedia. Houve cerca de 160 mil comentários no trem, 154 mil no teste.

A amostra de treinamento foi marcada da seguinte forma. Cada comentário possui seis rótulos. Os rótulos assumem o valor 1 se o comentário contiver esse tipo de toxicidade, 0 caso contrário. E pode ser que todos os rótulos sejam zero, um caso de comentário adequado. Ou pode ser que um comentário contenha vários tipos de toxicidade, imediatamente uma ameaça e obscenidade.
Devido ao fato de estarmos no ar, não posso demonstrar exemplos específicos dessas classes. Em relação à amostra de teste, para cada comentário foi necessário prever a probabilidade de cada tipo de toxicidade.
A métrica de qualidade é a média da ROC AUC sobre os tipos de toxicidade, isto é, a média aritmética da ROC AUC para cada classe separadamente.
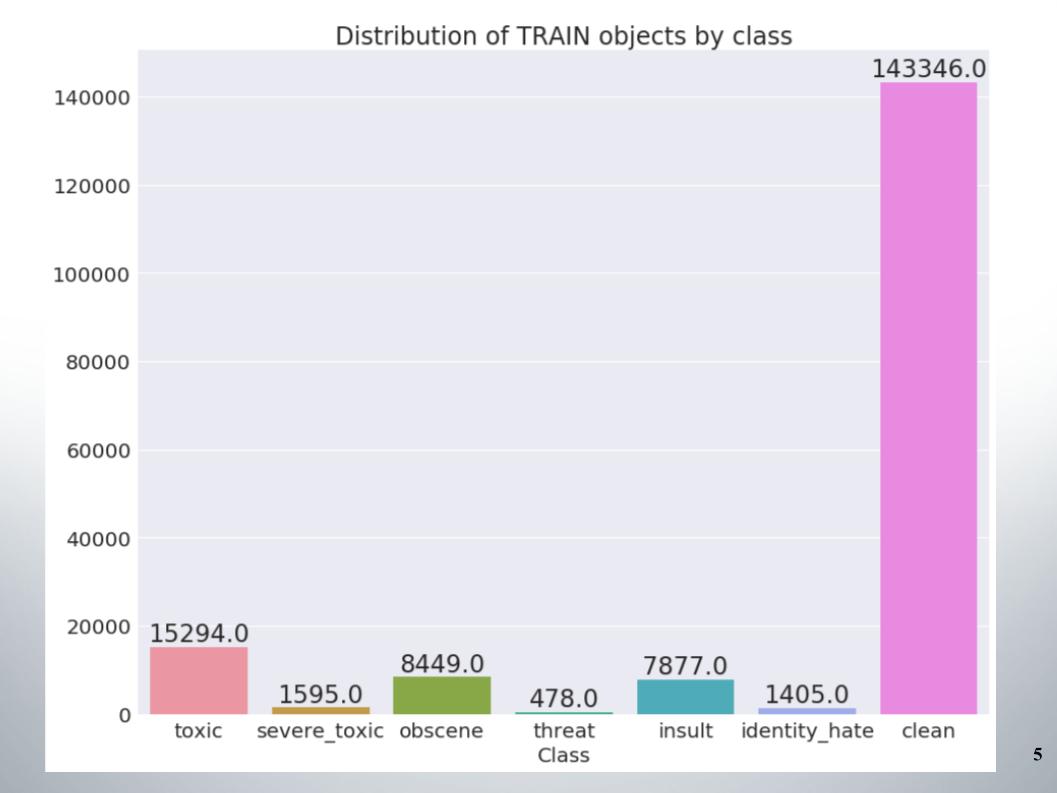
Aqui está a distribuição de objetos por classes no conjunto de treinamento. Pode-se ver que os dados são muito desequilibrados. Devo dizer imediatamente que nossa equipe obteve uma amostra de métodos para trabalhar com dados desequilibrados, por exemplo, superamostragem ou subamostragem.

Ao construir o modelo, usei um pré-processamento de dados em dois estágios. O primeiro estágio é o pré-processamento básico dos dados, essas são as transformações da exibição no slide, trazendo o texto para minúsculas, excluindo links, endereços IP, números e pontuação.

Para todos os modelos, esse pré-processamento de dados básico foi usado. Na segunda etapa, foi realizado um pré-processamento parcial dos dados - substituindo emoticons pelas palavras correspondentes, decifrando abreviações, corrigindo erros de digitação em palavrões, trazendo os diferentes tipos de tapetes para a mesma forma e também excluindo imagens. Em alguns comentários, links para imagens foram indicados, nós simplesmente os removemos.
Para cada um dos modelos, foi utilizado pré-processamento parcial de dados e seus vários elementos. Tudo isso foi feito para que os modelos de base reduzissem a correlação cruzada entre os modelos de base ao construir uma composição adicional.
Vamos para a parte mais interessante - a construção de um modelo.
Abandonei imediatamente a abordagem clássica do saco de palavras. Devido ao fato de que nessa abordagem, cada palavra é um atributo separado. Essa abordagem não leva em consideração a ordem geral das palavras; supõe-se que as palavras sejam independentes. Nessa abordagem, a geração do texto ocorre para que haja alguma distribuição em palavras, uma palavra é selecionada aleatoriamente nessa distribuição e inserida no texto.
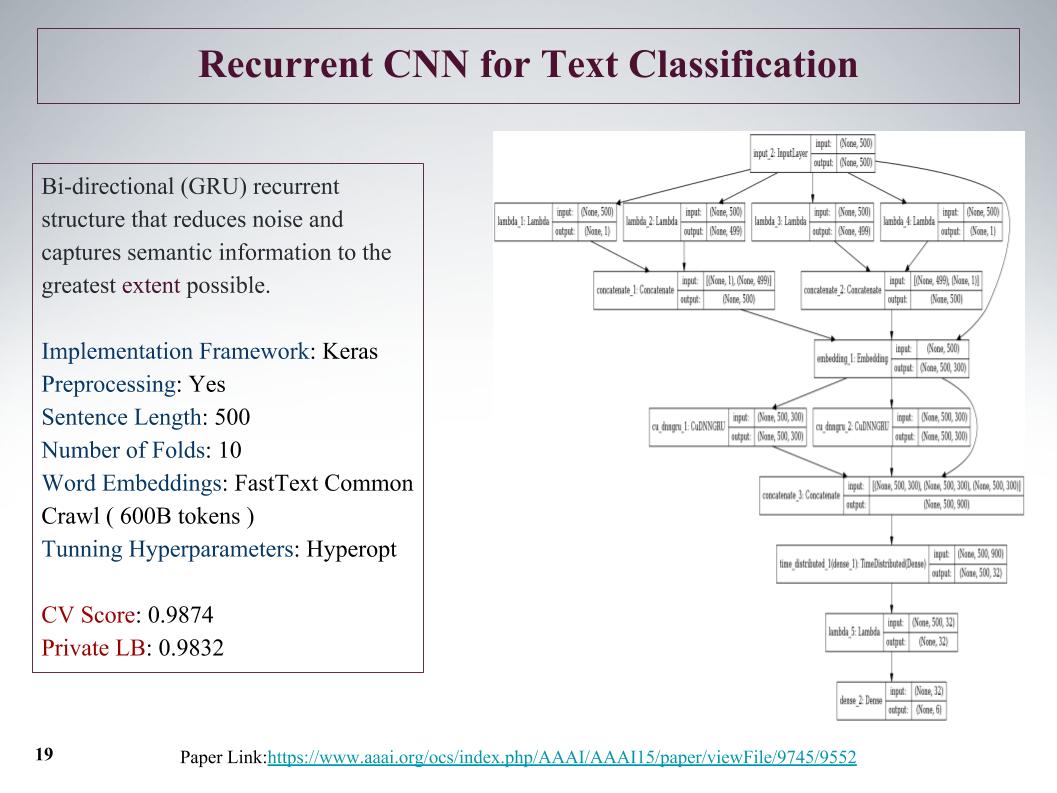
Obviamente, existem processos generativos mais complexos, mas a essência não muda - essa abordagem não leva em conta a ordem geral das palavras. Você pode ir para engramas, mas somente a ordem das palavras da janela será levada em consideração, e não geral. Portanto, também entendi meus colegas de equipe que precisavam usar algo mais inteligente.
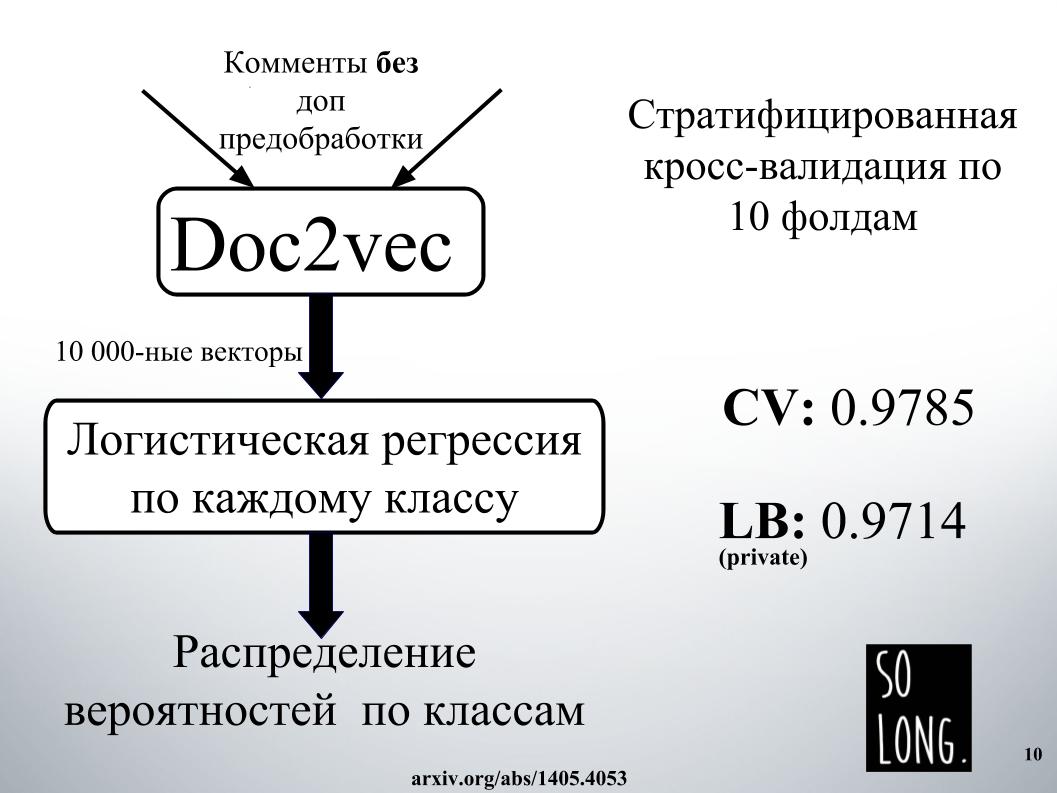
A primeira coisa inteligente que me ocorreu foi usar uma representação vetorial usando o Doc2vec. Este é o Word2vec mais um vetor que leva em conta a exclusividade de um documento específico. No artigo original, esse vetor é chamado como o parágrafo de identificação.
Em seguida, de acordo com essa representação vetorial, estudou-se a regressão logística, onde cada documento foi representado por um vetor de 10.000 dimensões. A avaliação da qualidade foi realizada com uma validação cruzada de dez dobras, foi estratificada e é importante notar que a regressão logística foi estudada para cada classe, seis problemas de classificação foram resolvidos separadamente. E no final, o resultado foi uma distribuição de probabilidade por classe.
A regressão logística é treinada há muito tempo. Eu geralmente não me encaixava na RAM. Nas instalações de Igor, eles passaram um dia em algum lugar para obter o resultado, como em um slide. Por esse motivo, imediatamente nos recusamos a usar o Doc2vec devido a grandes expectativas, embora isso pudesse ser melhorado em 1000 se um comentário com pré-processamento de dados adicional fosse feito.

O mais inteligente que nós e os outros concorrentes usamos foram redes neurais recorrentes. Eles recebem sequencialmente as palavras na entrada, atualizando seu estado oculto após cada palavra. Igor e eu usamos a rede recorrente GRU para a incorporação de palavras no fastText, que é especial porque resolve muitos problemas independentes de classificação binária. Preveja a presença ou ausência da palavra de contexto de forma independente.
Também realizamos uma avaliação de qualidade na validação cruzada de dez dobras, não foi estratificada aqui e aqui a distribuição de probabilidade foi imediatamente obtida por classe. Cada problema de classificação binária não foi resolvido separadamente, mas um vetor seis-dimensional foi gerado imediatamente. Foi o nosso um dos melhores modelos individuais.
Você pergunta, qual era o segredo do sucesso?
Consistia em mistura, havia muito, com empilhamento e criação de redes na abordagem. A abordagem de rede precisa ser descrita como um gráfico direcionado.
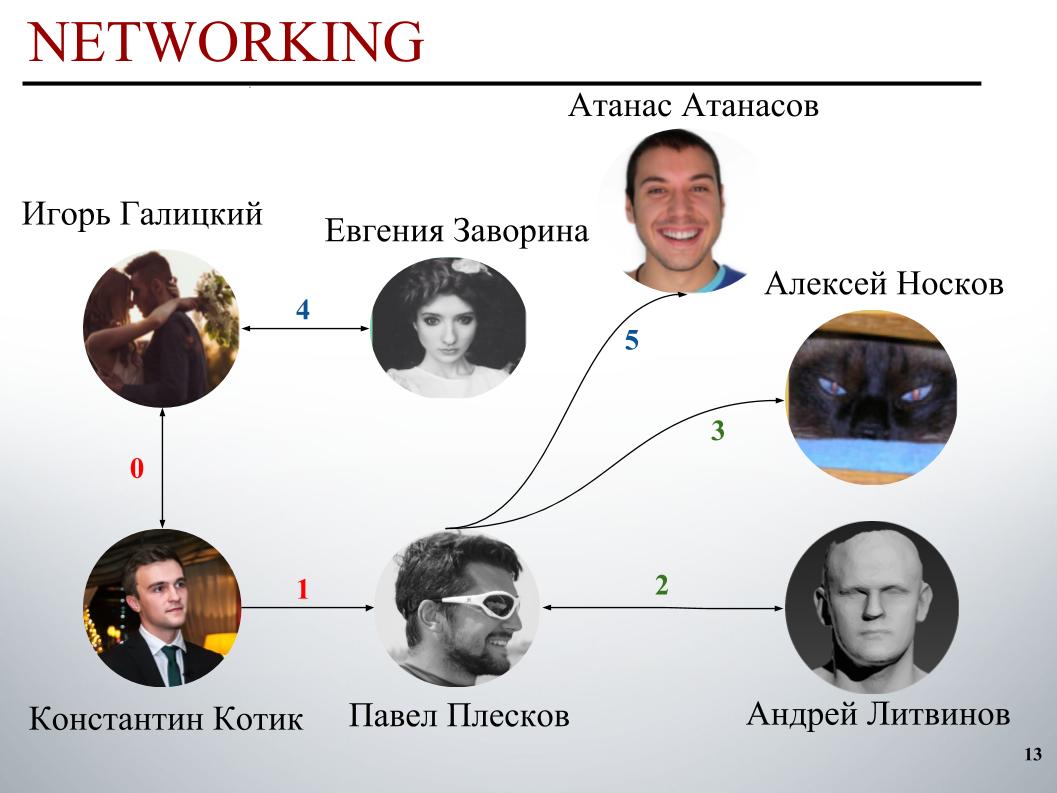
No início da competição, a equipe do DecisionGuys era composta por duas pessoas. Então Pavel Pleskov, no canal ODS Slack, expressou o desejo de querer se juntar a alguém dos 200 melhores. Naquela época, estávamos em algum lugar no 157º lugar, e Pavel Pleskov no 154º lugar, em algum lugar do bairro. Igor percebeu seu desejo de participar e eu o convidei para a equipe. Então Andrey Litvinov se juntou a nós, e Pavel convidou o grão-mestre Alexei Noskov para nossa equipe. Igor - Eugene. E o último parceiro da nossa equipe foi o búlgaro Atanas Atanasov, e este foi o resultado de um conjunto internacional humano.
Agora Igor Galitsky dirá como ele ensinou o gru, com mais detalhes ele falará sobre as idéias e abordagens de Pavel Pleskov, Andrei Litvinov e Atanas Atanasov.
Igor Galitsky:
- Sou cientista de dados na Epoch8 e falarei sobre a maioria das arquiteturas que usamos.
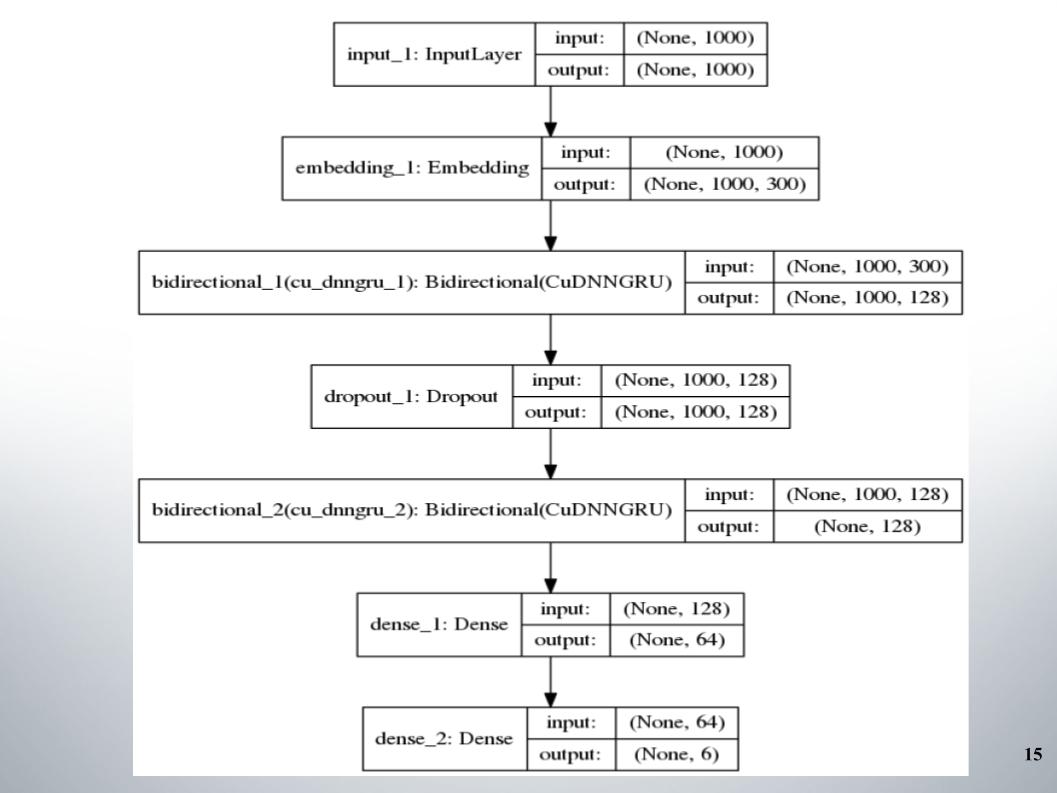
Tudo começou com o grupo didático direcional padrão com duas camadas, quase todas as equipes o usaram, e o fastText, a função de ativação do EL, foi usado como incorporação.
Não há nada de especial a dizer, arquitetura simples, sem frescuras. Por que ela nos deu bons resultados com os quais ficamos no top 150 por algum tempo? Tivemos um bom pré-processamento do texto. Era necessário seguir em frente.
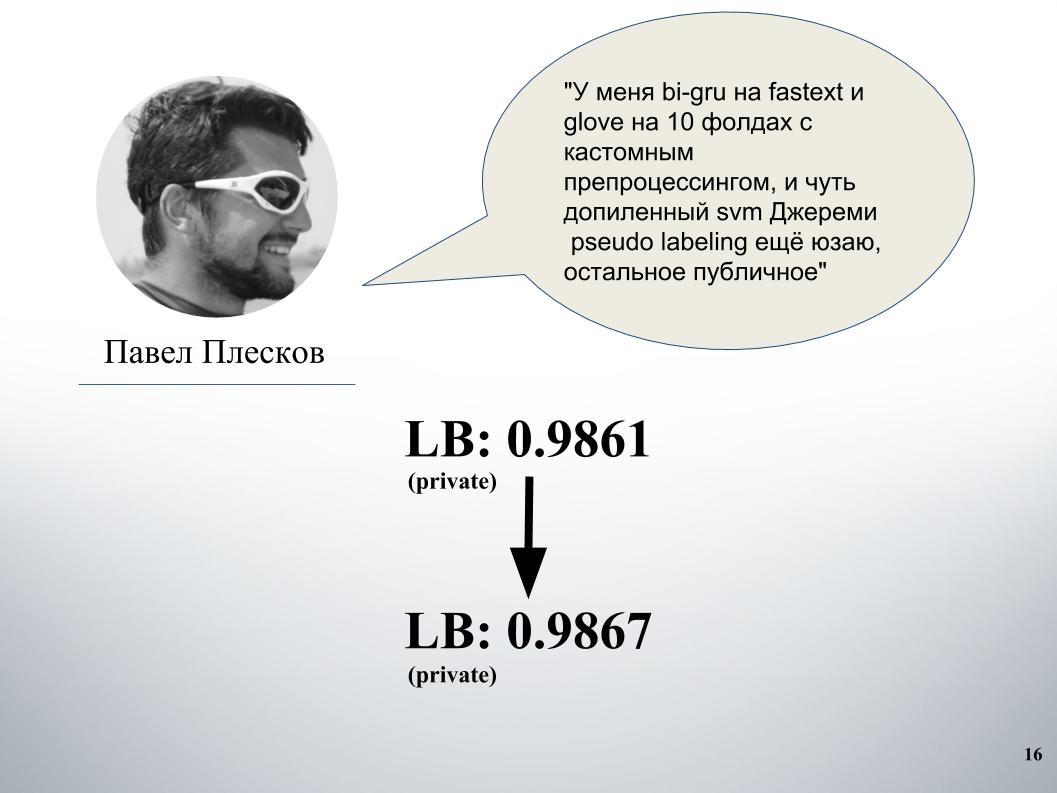
Paulo teve sua própria abordagem. Depois de nos misturarmos com os nossos, isso deu um aumento significativo. Antes disso, tínhamos gru e model blending no Doc2vec, que dava 61 LB.
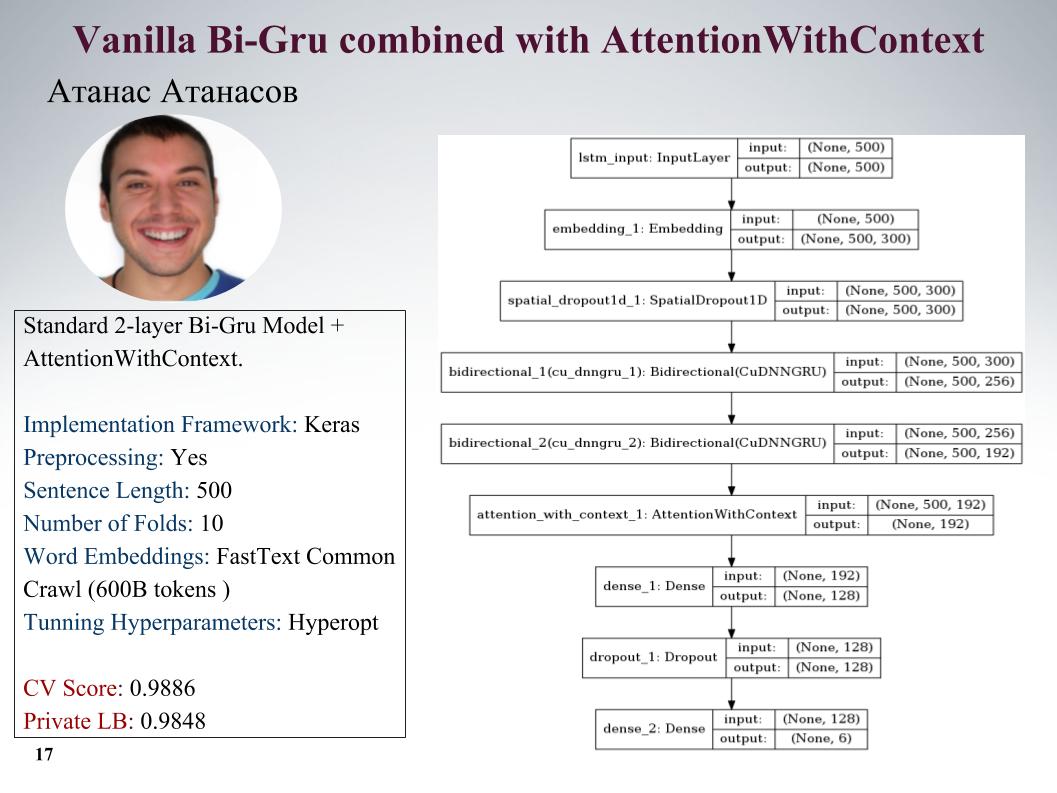
Vou falar sobre as abordagens de Atanas Atanasov, ele é diretamente um entusiasta de novos artigos. Aqui está o gru com atenção, todos os parâmetros no slide. Ele tinha muitas abordagens bem legais, mas até o último momento ele usou seu pré-processamento e todo o lucro foi nivelado. Velocidade no slide.
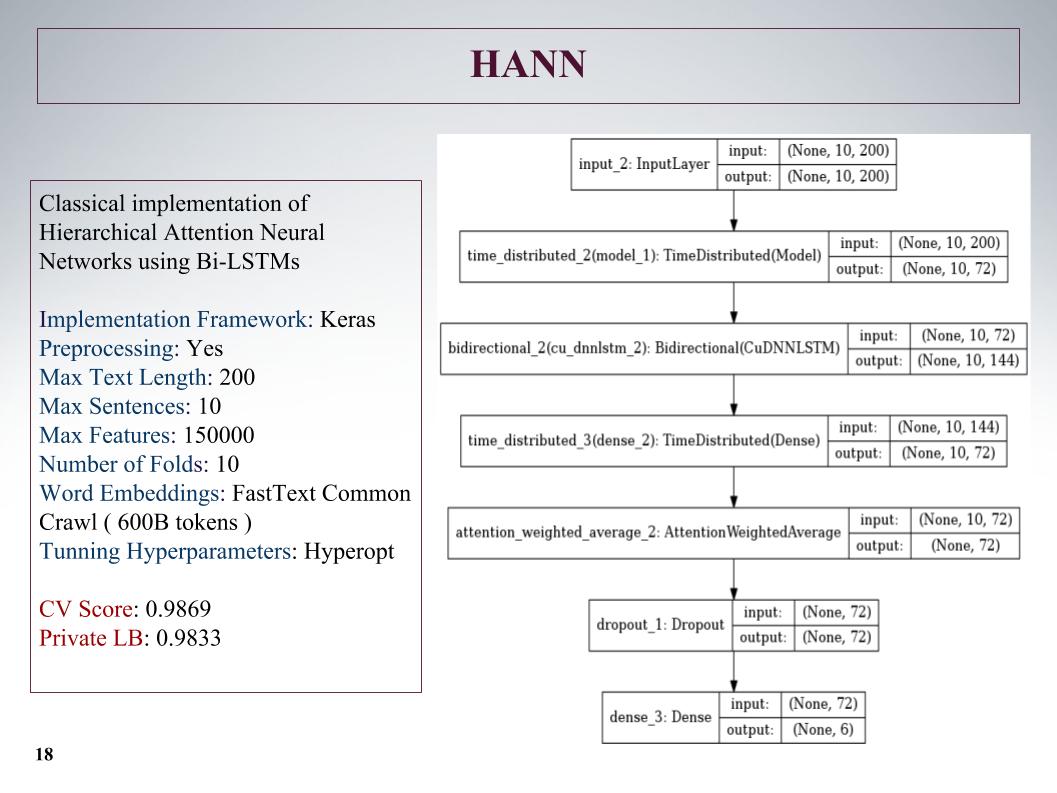
Depois, houve uma atenção hierárquica, que apresentou resultados ainda piores, pois inicialmente era uma rede para classificar documentos compostos por sentenças. Ele estragou tudo, mas a abordagem não é muito.
Houve uma abordagem interessante, podemos obter recursos da oferta inicialmente desde o início e até o final. Com a ajuda da convolução, camadas convolucionais, obtemos recursos separadamente à esquerda e à direita da árvore. Isso é do começo e do fim da frase, então eles se fundem e passam novamente pelo gru.

Também Bi-GRU com bloco de atenção. Este é um dos melhores em privado foi uma rede bastante profunda, mostrou bons resultados.

A próxima abordagem é destacar os recursos o máximo possível? Após a camada da rede recorrente, fazemos mais três camadas paralelas de convolução. E aqui tomamos sentenças não tão longas, reduzimos para 250, mas devido a três convoluções, isso deu um bom resultado.

Foi a rede mais profunda. Como Atanas disse, ele só queria ensinar algo grande e interessante. Uma grade convolucional comum que aprendeu com os recursos de texto, os resultados não são nada de especial.

Essa é uma nova abordagem bastante interessante: em 2017, houve um artigo sobre esse tópico, que foi usado para o ImageNet e permitiu melhorar o resultado anterior em 25%. Sua principal característica é que uma pequena camada é lançada paralelamente ao bloco convolucional, que ensina os pesos para cada convolução nesse bloco. Ela deu uma abordagem muito legal, apesar de cortar as frases.
O problema é que o comprimento máximo de sentenças nessas tarefas alcançou 1.500 palavras, houve comentários muito grandes. Outras equipes também pensaram em como aproveitar essa grande oferta, como encontrar, porque nem tudo é muito importante. E muitos disseram que no final da frase havia um infa muito importante. Infelizmente, em todas essas abordagens, isso não foi levado em consideração, porque o começo foi levado. Talvez isso daria um aumento adicional.

Aqui está a arquitetura AC-BLSTM. O ponto principal é que, se a divisão inferior em duas partes, além da atenção, é uma atração inteligente, mas em paralelo ainda é normal, e tudo isso é concretizado. Também bons resultados.

E Atanas todo o seu zoológico de modelos, então foi uma mistura legal. Além dos modelos em si, adicionei alguns recursos de texto, geralmente comprimento, número de letras maiúsculas, número de palavrões, número de caracteres, tudo isso adicionado. Validação cruzada de cinco dobras e obteve excelentes resultados no LB 0,9867 privado.
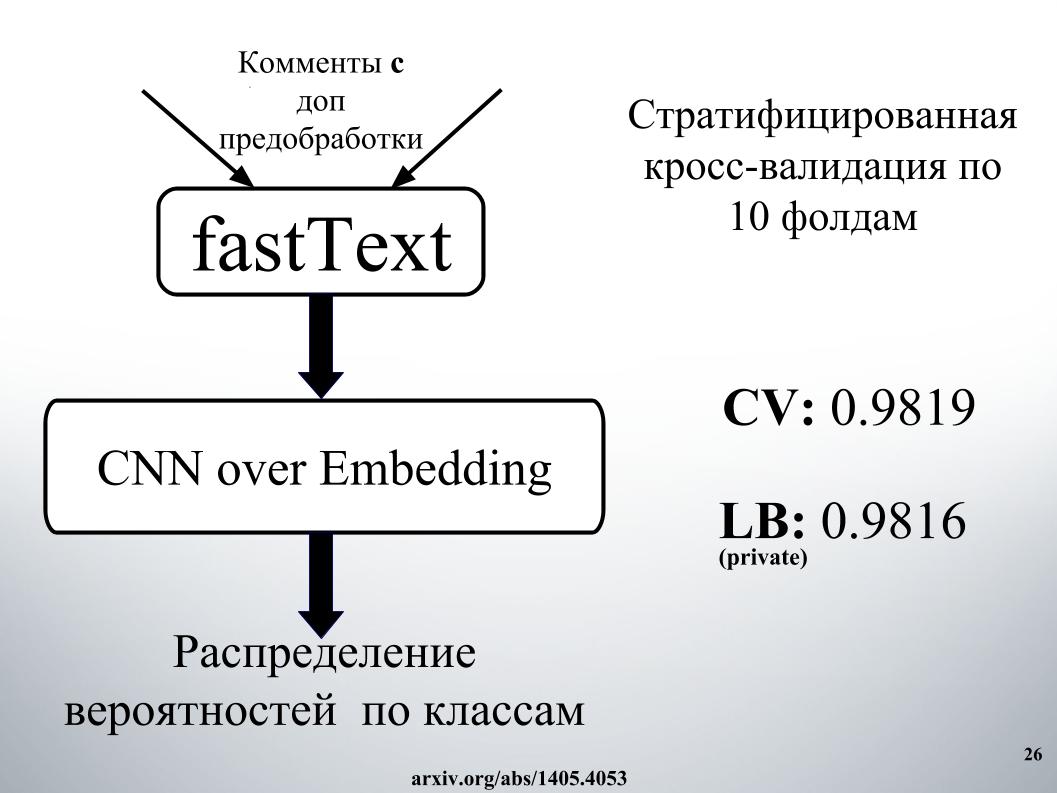
E a segunda abordagem, ele ensinou com uma incorporação diferente, mas os resultados foram piores. Todo mundo usava o fastText.
Eu queria falar sobre a abordagem de nosso outro colega, Andrei, com o apelido Laol na ODS. Ele ensinou muitos kernels públicos, bebeu-os como se estivesse fora de si, e isso realmente produziu resultados muito interessantes. Você não podia fazer tudo isso, mas apenas pegue um monte de kernels públicos diferentes, mesmo no tf-idf, existem todos os tipos de convolução gru.
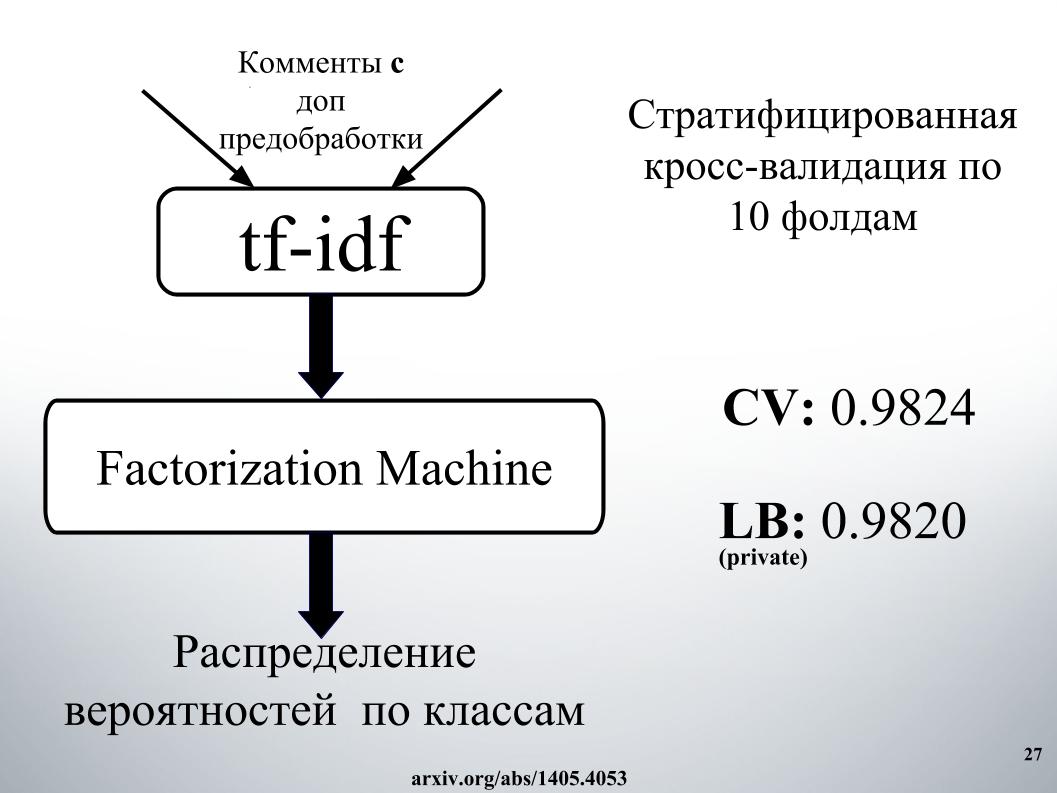
Ele teve uma das melhores abordagens, com as quais ficamos muito tempo entre os 15 primeiros, até que Alexey e Atanas se juntaram a nós, ele combinou a mistura e o empilhamento de tudo isso. E também um momento muito legal, que, pelo que entendi, nenhuma das equipes usou, também criamos recursos a partir dos resultados da API dos organizadores. Sobre isso, conte a Alex.
Alexey Noskov:
oi Vou falar sobre a abordagem que usei e como a concluímos.

Tudo foi bastante simples para mim: 10 dobras de validação cruzada, modelos pré-treinados em vetores diferentes com pré-processamento diferente, para que eles tivessem mais diversidade no conjunto, um pequeno aumento e dois ciclos de desenvolvimento. O primeiro, que basicamente funcionou no início, treinou um certo número de modelos, analisou erros de validação cruzada, em quais exemplos ele comete erros óbvios e corrigiu o pré-processamento com base nisso, porque fica mais claro como corrigi-los.
E a segunda abordagem, que foi usada mais no final, ensinou alguns conjuntos de modelos, analisou correlações, encontrou blocos de modelos que são fracamente correlacionados entre si e fortaleceu a parte deles. Essa é a matriz de correlação de validação cruzada entre meus modelos.
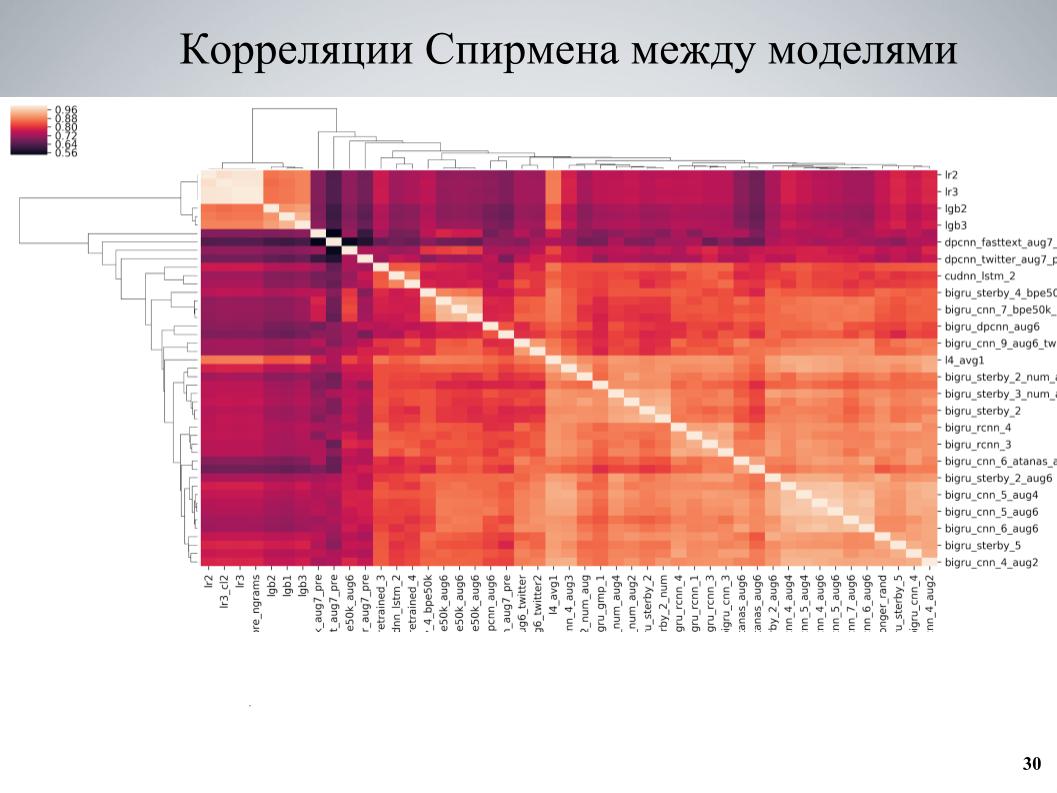
Pode-se ver que em alguns lugares ela possui uma estrutura de blocos, enquanto alguns modelos eram de boa qualidade, estavam fracamente correlacionados com os outros, e foram obtidos resultados muito bons quando eu tomei esses modelos como base, ensinei-lhes várias variações diferentes que diferem em diferentes hiperparâmetros ou pré-processamento e, em seguida, adicionados ao conjunto.

Para aumentar, a idéia que foi publicada no fórum por Pavel Ostyakov foi a que mais provocou. Consistia no fato de podermos fazer um comentário, traduzi-lo para outro idioma e depois voltar. Como resultado da tradução dupla, é obtida uma reformulação, algo está um pouco perdido, mas no geral é obtido um texto ligeiramente diferente, que também pode ser classificado e, assim, expandir o conjunto de dados.
E a segunda abordagem, que não ajudou muito, mas também ajudou, é que você pode tentar fazer dois comentários arbitrários, geralmente não muito longos, colá-los e colocar como rótulo no alvo uma combinação de rótulos ou um pouco de entusiasmo, onde há apenas um dos eles continham um rótulo.
Ambas as abordagens funcionaram bem se não fossem aplicadas antecipadamente a todo o conjunto de conjuntos, mas para alterar o conjunto de exemplos aos quais o aumento deveria ser aplicado a cada época. Cada época no processo de formação de um lote, escolhemos, digamos, 30% dos exemplos que são executados nas traduções. Antes, antes, em algum lugar paralelo já existe na memória, simplesmente selecionamos a versão para tradução com base nela e a adicionamos ao lote durante o treinamento.

Uma diferença interessante foram os modelos treinados no BPE. Existe um SentençaPiece - um tokenizador do Google que permite dividir em tokens nos quais não haverá UNK. Um dicionário limitado no qual qualquer string é dividida em alguns tokens. Se o número de palavras no texto real for maior que o tamanho alvo do dicionário, elas começarão a se dividir em partes menores, e uma abordagem intermediária será obtida entre os modelos de nível de caractere e nível de palavra.
Dois algoritmos de construção principais são usados lá: BPE e Unigram. Para o algoritmo BPE, foi fácil encontrar incorporações pré-marca registrada na rede e, com algum vocabulário fixo - eu tinha apenas um bom vocabulário de 50 mil - também podia treinar modelos que davam um bom desempenho (inaudível - aprox. Ed.), Um pouco pior, do que o habitual no fastText, mas eles estavam muito pouco correlacionados com todos os outros e deram um bom impulso.
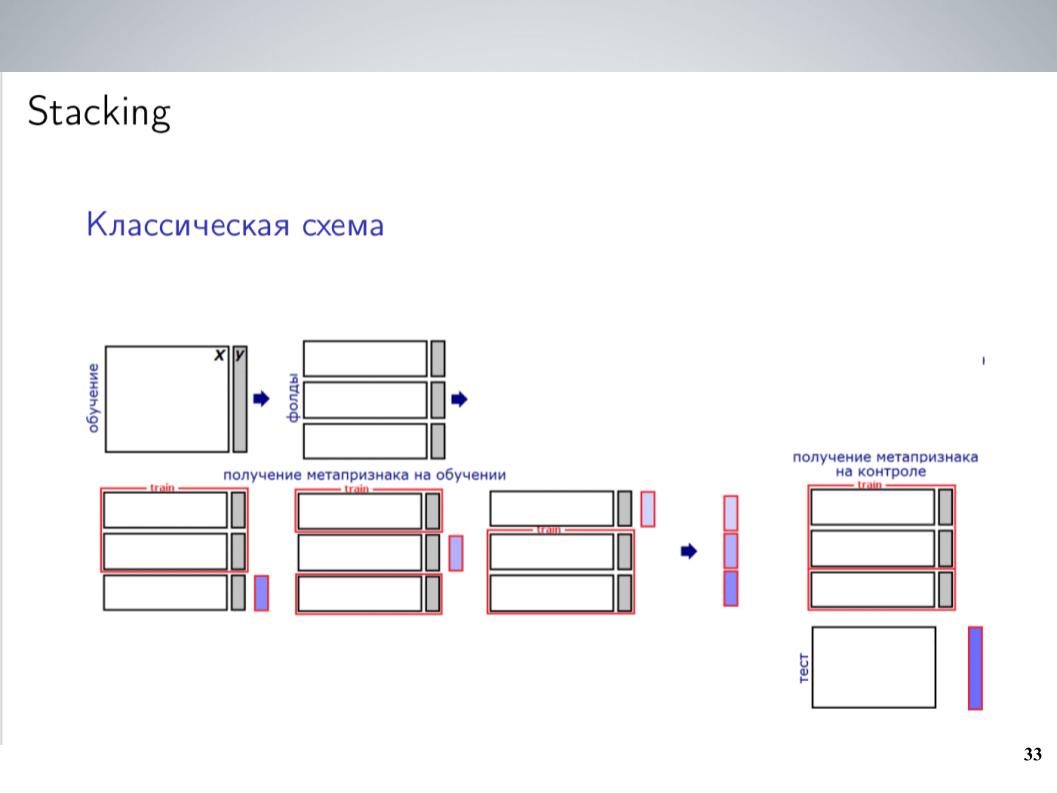
Este é um esquema de empilhamento clássico. Como regra geral, na maior parte da competição, antes da combinação, eu costumava simplesmente misturar todos os meus modelos sem pesos. Isso deu os melhores resultados. Mas após a fusão, consegui um esquema um pouco mais complexo, que no final deu um bom impulso.

Eu tinha um grande número de modelos. Basta jogá-los todos em algum tipo de empilhador? Ele não funcionou muito bem, ele treinou novamente, mas como os modelos eram grupos fortemente correlacionados, eu simplesmente os uni a esses grupos, em cada grupo calculei a média e recebi de 5 a 7 grupos de modelos muito semelhantes, dos quais como recursos para O próximo nível usou valores médios. Treinei o LightGBM nisso, corrigi 20 lançamentos com várias amostras, carreguei um pouco de meta-funcionalidade semelhante ao que Atanas fez e, no final, finalmente começou a funcionar, dando um impulso na média simples.

Acima de tudo, adicionei a API que Andrei encontrou e que contém um conjunto semelhante de rótulos. Os organizadores construíram modelos para eles inicialmente. Como era originalmente diferente, os participantes não o usavam, era impossível simplesmente compará-lo com aqueles que precisávamos prever. Mas se ele se lançasse em um empilhamento que funcionasse bem como um meta-recurso, daria um impulso maravilhoso, especialmente na classe TOXIC, que, aparentemente, foi a mais difícil na tabela de classificação, e nos permitiu pular em vários lugares no final, literalmente no último dia .

Como descobrimos que o empilhamento e a API funcionaram tão bem para nós, antes dos envios finais, tínhamos poucas dúvidas sobre o quão bem isso seria portado para o privado. Funcionou muito bem, então escolhemos dois envios de acordo com o seguinte princípio: um - uma mistura de modelos sem uma API que foi recebida antes disso, além de empilhar com metafísica da API. Aqui ficou 0,9880 em público e 0,9874 em privado. Aqui minhas marcas estão confusas.

E o segundo é uma mistura de modelos sem uma API, sem usar empilhamento e sem usar o LightGBM, porque havia receios de que isso fosse algum tipo de reciclagem menor para o público, e poderíamos voar com isso. Aconteceu que eles não voaram e, como resultado, com o resultado de 0,9876 no privado, conseguimos a décima posição. Só isso.