Grandes empresas e empresas sangrentas há muito tempo substituem os RDBDS adultos por DWH e análises. O DWH está migrando massivamente para o DataLake e o Hadoop. Parece que as pequenas empresas não fazem mais sentido lançar análises em um rsbd sério. Com o crescente número de núcleos disponíveis, mesmo para pequenas empresas, tentar licenciar uma versão completa de um subtipo adulto como o Oracle faz pouco sentido. Standard Edition Oracle, embora licenciado para soquetes, mas ao mesmo tempo elimine as funcionalidades mais importantes. Em primeiro lugar, na edição padrão não há particionamento
, existe apenas uma exibição de particionamento - compartilhamento de tabela da maneira do Postgres, que pode ajudar apenas em algumas situações. Em segundo lugar, não há espera de pleno direito, as operações paralelas são cortadas. O cluster RAC é limitado a quatro soquetes. Como resultado, com o crescimento moderno dos dados, você começa rapidamente a se deparar com as limitações da edição Standard, e o preço de licenciamento da edição Enterprise torna essa tarefa inútil. No Oracle, é necessário licenciar não apenas o servidor de batalha, mas também o servidor em espera, enquanto a edição Enterprise é licenciada por núcleo. As opções de cluster, particionamento e DataGuard / Standby requerem licenciamento separado e também o núcleo. Como resultado, mesmo um servidor de nível de entrada com 16 núcleos e seu status já exigido para licenças de EE está custando muitas centenas de milhares de dólares, e até mesmo sangrentas falhas de gerenciamento corporativo.
Temos que procurar uma alternativa em khadupov. Tentei comparar algumas solicitações de uma demonstração de dados construída em arquivos parquet em um backup, contra o Oracle Standard em 8 núcleos xeon, quadros de 196 GB, uma certa loja corporativa com cache de HDD e SSD, que pode ser vasculhada em vários outros sistemas. A primeira consulta afeta 4 tabelas, no Oracle elas ocupavam 62, 12, 6,5 e 3,5 GB. Em uma placa que é maior que cerca de 880 milhões de linhas. Em um plano de solicitação, era o seguinte:
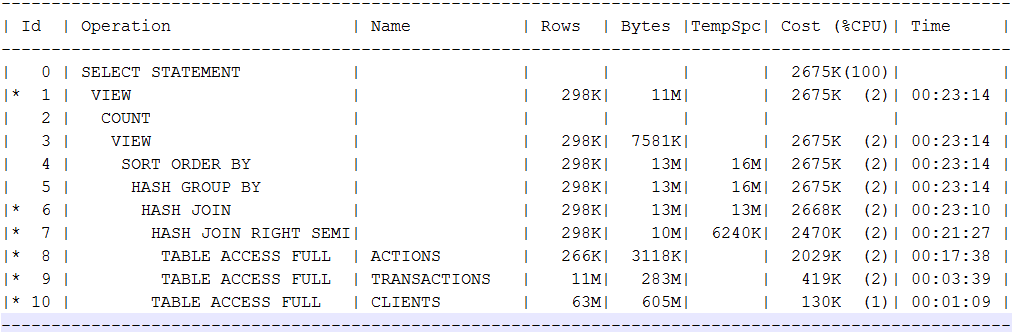
No plano, eu queria especificamente ver os fullscans e hashjoins típicos das minhas consultas analíticas. Na realidade, uma solicitação para uma edição padrão do Oracle leva cerca de 7 minutos. O Spark 2.3 lançado através do spark2-submit para 14 executores com quadros de 4 núcleos / 16 GB fornece uma resposta para quase a mesma solicitação de discos HDD de 10k em um minuto. O Cloudera Impala pressionando com fios e faísca no mesmo cluster (impalad em 8 nós, recursos comparáveis a 14 executores com 4 núcleos) fornece uma resposta estável em 11 a 12 segundos. Ao mesmo tempo, o Impala é executado constantemente em paralelo com a carga, o que deve lavar os dados em cache.
Jogos com tamanho de bloco, migrar para a edição Oracle EE com seu paralelismo e particionamento adulto provavelmente reduziriam o tempo de execução em várias vezes, mas duvido que o tempo seja comparável até ao que recebi no Spark. Por outro lado, apenas 3-4 nós do Cloudera Hadoop praticamente livre permitem que você obtenha o SQL habitual, a velocidade pela qual a Oracle teria um dinheiro incomparavelmente alto.
A Oracle deve pensar seriamente na política de licenciamento, se grandes fãs, como eu, não encontrarem motivo para pagar pela edição Enterprise.