Fui informado de que em novos computadores alguns testes de regressão se tornaram mais lentos. Uma coisa comum, acontece. Configuração incorreta em algum lugar do Windows ou não dos valores mais ideais no BIOS. Mas desta vez não conseguimos encontrar a mesma configuração "derrubada". Como a mudança é significativa: 9 x 19 segundos (no gráfico, azul é o ferro velho e laranja é o novo), tive que me aprofundar mais.
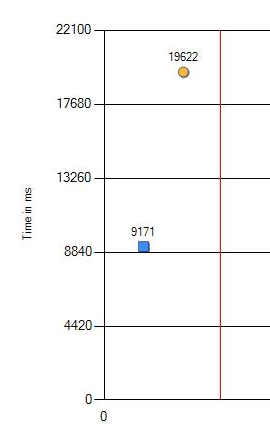
Mesmo sistema operacional, mesmo hardware, processador diferente: 2 vezes mais lento
A queda no desempenho de 9,1 para 19,6 segundos pode definitivamente ser considerada significativa. Realizamos verificações adicionais com uma alteração nas versões dos programas testados, nas configurações do Windows e do BIOS. Mas não, o resultado não mudou. A única diferença apareceu apenas em diferentes processadores. Abaixo está o resultado da última CPU.
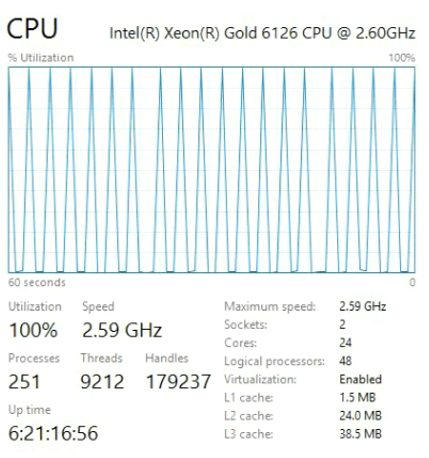
E aqui está o que é usado para comparação.

O Xeon Gold roda em uma arquitetura diferente chamada Skylake, comum aos novos processadores Intel desde meados de 2017. Se você comprar o hardware mais recente, receberá um processador com a arquitetura Skylake. São carros bons, mas, como os testes mostraram, novidade e velocidade não são a mesma coisa.
Se nada mais ajudar, você precisará usar o criador de perfil para pesquisas detalhadas. Vamos testar em equipamentos novos e antigos e obter algo parecido com isto:
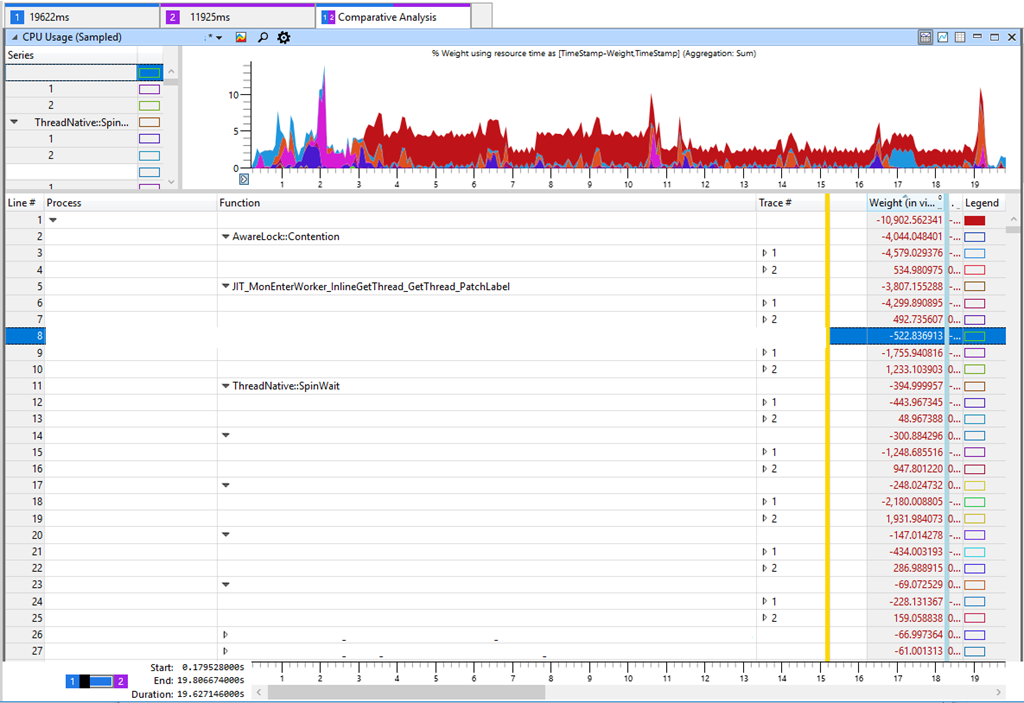
A guia no Windows Performance Analyzer (WPA) mostra na tabela a diferença entre o Rastreio 2 (11 s) e o Rastreio 1 (19 s). Uma diferença negativa na tabela corresponde a um aumento no consumo de CPU em um teste mais lento. Se você observar as diferenças mais significativas no consumo de CPU, veremos
AwareLock :: Contention ,
JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel e
ThreadNative.SpinWait . Tudo indica uma "rotação" na CPU [girando - uma tentativa cíclica de obter um bloqueio, aprox. por.], quando os threads lutam pelo bloqueio. Mas essa é uma marca falsa, porque a fiação não é a principal razão do declínio da produtividade. O aumento da concorrência por bloqueios significa que algo em nosso software diminuiu a velocidade e manteve o bloqueio, o que resultou em um aumento na rotação da CPU. Verifiquei o tempo de bloqueio e outros indicadores importantes, como o desempenho do disco, mas não consegui encontrar nada significativo que pudesse explicar a degradação do desempenho. Embora isso não seja lógico, voltei a aumentar a carga na CPU em vários métodos.
Seria interessante encontrar exatamente onde o processador fica preso. O WPA possui colunas de arquivo e linha #, mas elas funcionam apenas com caracteres particulares, o que não temos, porque esse é o código do .NET Framework. A próxima melhor coisa que podemos fazer é obter o endereço dll onde está localizada a instrução chamada Image RVA. Se você carregar esta dll no depurador e fazer
u xxx.dll+ImageRVAentão devemos ver a instrução que grava a maioria dos ciclos da CPU, porque será o único endereço "quente".
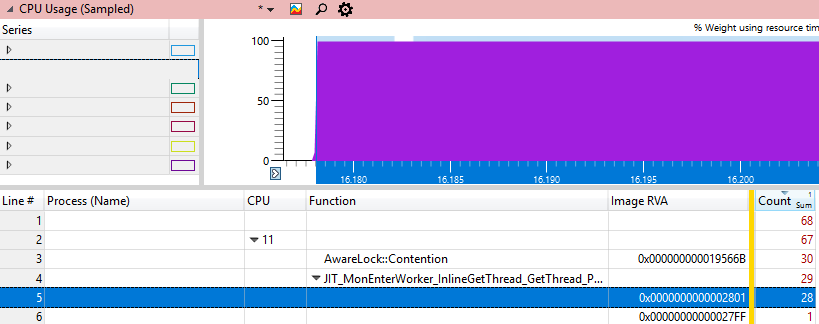
Examinaremos esse endereço usando vários métodos do Windbg:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)E com vários métodos JIT:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Agora temos um modelo. Em um caso, o endereço ativo é uma instrução de salto e, no outro, é uma subtração. Mas ambas as instruções importantes são precedidas pela mesma instrução de pausa geral. Métodos diferentes executam a mesma instrução do processador, o que, por algum motivo, leva muito tempo. Vamos medir a velocidade de execução da instrução pause e ver se raciocinamos corretamente.
Se o problema estiver documentado, ele se tornará um recurso.
| CPU | pausa em nanossegundos |
| Xeon E5 1620v3 3.5 GHz | 4 |
| Xeon® Gold 6126 a 2,60 GHz | 43 |
A pausa nos novos processadores Skylake leva uma ordem de magnitude mais longa. Claro, tudo pode ficar mais rápido e, às vezes, um pouco mais lento. Mas
dez vezes mais devagar? É mais como um bug. Uma pequena pesquisa na Internet sobre instruções de pausa leva ao
manual da Intel , que menciona explicitamente as instruções de microarquitetura e pausa da Skylake:

Não, isso não é um erro, é uma função documentada. Existe até uma
página indicando o tempo de execução de quase todas as instruções do processador.
- Ponte de areia 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
O número de ciclos do processador é indicado aqui. Para calcular o tempo real, você precisa dividir o número de ciclos pela frequência do processador (geralmente em GHz) e obter o tempo em nanossegundos.
Isso significa que, se você executar aplicativos altamente multithread no .NET no último hardware, eles poderão funcionar muito mais devagar. Alguém já percebeu isso e em agosto de 2017
registrou um bug . O problema foi
corrigido no .NET Core 2.1 e no .NET Framework 4.8 Preview.
Spin-wait aprimorado em várias primitivas de sincronização para melhor desempenho no Intel Skylake e microarquiteturas posteriores. [495945, mscorlib.dll, bug]
Mas como ainda há um ano antes do lançamento do .NET 4.8, solicitei o backport das correções para que o .NET 4.7.2 retornasse à velocidade normal em novos processadores. Como existem bloqueios mutuamente exclusivos (spinlocks) em muitas partes do .NET, você deve acompanhar o aumento da carga da CPU quando o Thread.SpinWait e outros métodos de giro funcionarem.

Por exemplo, o Task.Result usa internamente a rotação, portanto, prevejo um aumento significativo na carga da CPU e menor desempenho em outros testes.
Quão ruim é isso?
Examinei o código do .NET Core por quanto tempo o processador continuará girando se o bloqueio não for liberado antes de chamar o WaitForSingleObject para pagar pela opção de contexto "cara". Uma troca de contexto leva em algum lugar um microssegundo ou muito mais se muitos threads esperam o mesmo objeto do kernel.
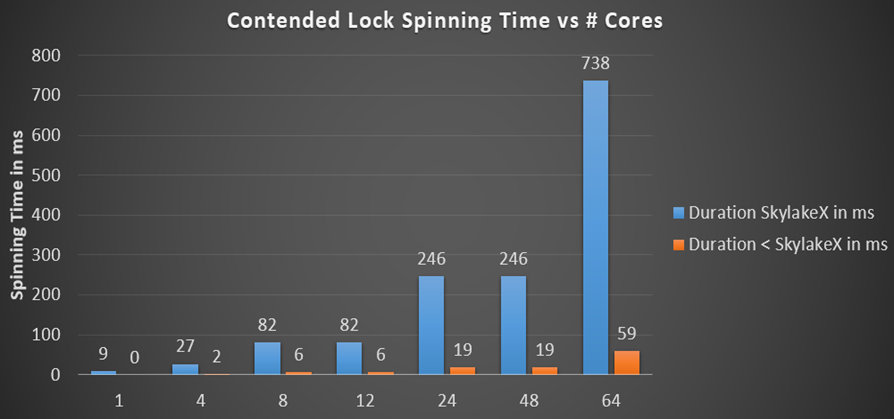
Os bloqueios do .NET multiplicam a duração máxima da rotação pelo número de núcleos, se considerarmos o caso absoluto em que o encadeamento em cada núcleo espera o mesmo bloqueio e a rotação continua por tempo suficiente para que todos trabalhem um pouco antes de pagar pela chamada do kernel. A rotação no .NET usa um algoritmo de duração exponencial quando começa com um ciclo de 50 chamadas de pausa, em que para cada iteração o número de rotações é triplicado até o próximo contador de rotações exceder sua duração máxima. Calculei a duração total da rotação por processador para vários processadores e um número diferente de núcleos:
Abaixo está o código giratório simplificado no .NET Locks:
/// <summary> /// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls /// </summary> /// <param name="nCores"></param> void Spin(int nCores) { const int dwRepetitions = 10; const int dwInitialDuration = 0x32; const int dwBackOffFactor = 3; int dwMaximumDuration = 20 * 1000 * nCores; for (int i = 0; i < dwRepetitions; i++) { int duration = dwInitialDuration; do { for (int k = 0; k < duration; k++) { Call_PAUSE(); } duration *= dwBackOffFactor; } while (duration < dwMaximumDuration); } }
Anteriormente, o tempo de rotação era no intervalo de milissegundos (19 ms para 24 núcleos), o que já é muito comparado ao tempo de troca de contexto mencionado, que é uma ordem de magnitude mais rápida. Mas nos processadores Skylake, o tempo total de rotação do processador simplesmente explode até 246 ms em uma máquina de 24 bits ou 48 núcleos, simplesmente porque a instrução de pausa diminuiu 14 vezes. Isso é realmente assim? Escrevi um pequeno testador para verificar a rotação geral da CPU - e os números calculados estão bem de acordo com as expectativas. Aqui estão 48 threads em uma CPU de 24 núcleos aguardando um bloqueio, que eu chamei de Monitor.PulseAll:
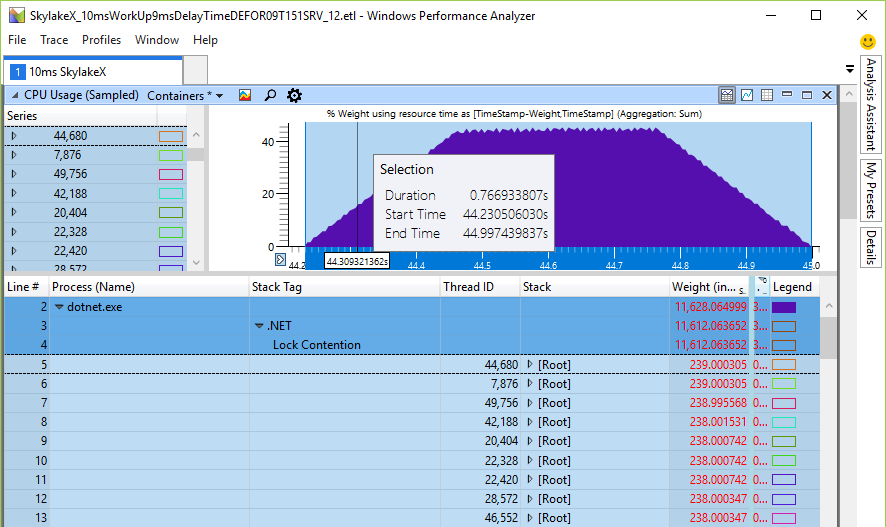
Apenas um fio vencerá a corrida, mas 47 continuarão girando até perder a freqüência cardíaca. Essa é uma evidência experimental de que realmente temos um problema de carga da CPU e que a rotação muito longa é real. Isso prejudica a escalabilidade, porque esses ciclos vão em vez do trabalho útil de outros encadeamentos, embora a instrução de pausa libere alguns recursos comuns da CPU, proporcionando um tempo de suspensão mais longo. O motivo da rotação é uma tentativa de obter um bloqueio mais rápido sem acessar o kernel. Nesse caso, aumentar a carga na CPU seria apenas nominal, mas não afetou o desempenho, porque os kernels estão envolvidos em outras tarefas. Mas os testes mostraram uma diminuição no desempenho em operações quase de thread único, em que um thread adiciona algo à fila de trabalho, enquanto o thread de trabalho espera um resultado e, em seguida, executa uma determinada tarefa com o item de trabalho.
O motivo é mais fácil de mostrar no diagrama. O giro adversário ocorre com um triplo de giro a cada passo. Após cada rodada, o bloqueio é verificado novamente para ver se o encadeamento atual pode recebê-lo. Embora o spinning tente ser honesto e alterne de tempos em tempos para outros threads, para ajudá-los a concluir seu trabalho. Isso aumenta as chances de liberar o bloqueio na próxima verificação. O problema é que a verificação de uma tomada é possível apenas no final de uma rodada completa:

Por exemplo, se, no início da quinta rodada, uma trava sinalizar disponibilidade, você poderá executá-la somente no final da rodada. Tendo calculado a duração do giro da última rodada, podemos estimar o pior caso de atraso para o nosso fluxo:

Muitos milissegundos de espera até o giro terminar. Isso é um problema real?
Criei um aplicativo de teste simples que implementa uma fila de fabricantes de consumidores, onde o fluxo de trabalho executa cada item de trabalho por 10 ms e o consumidor tem um atraso de 1 a 9 ms antes do próximo item de trabalho. Isso é suficiente para ver o efeito:
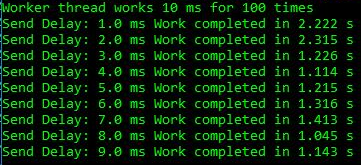
Vemos para atrasos de 1-2 ms a duração total é de 2,2 a 2,3 s, enquanto em outros casos o trabalho é mais rápido até 1,2 s. Isso mostra que o giro excessivo na CPU não é apenas um problema cosmético em aplicativos sobrecarregados. Isso realmente prejudica o simples encadeamento do produtor-consumidor, que inclui apenas dois threads. Para a execução acima, os dados ETW falam por si: é o aumento na rotação que causa o atraso observado:
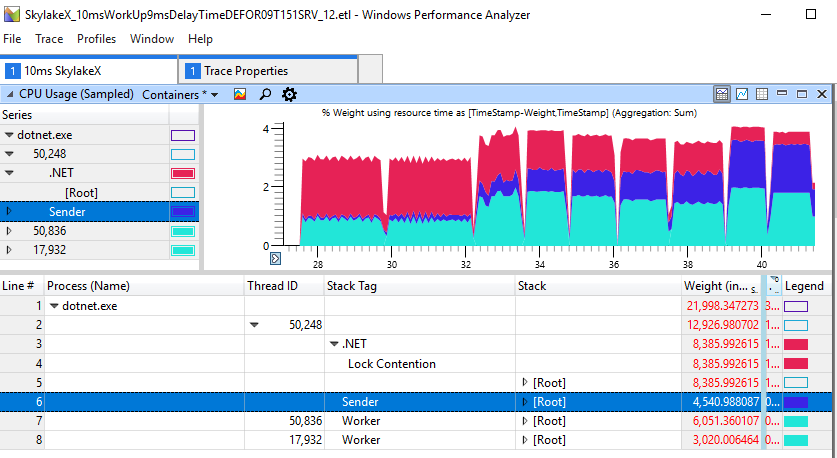
Se você observar atentamente a seção com “freios”, veremos 11 ms de giro na área vermelha, embora o trabalhador (azul claro) tenha concluído seu trabalho e tenha bloqueado há muito tempo.
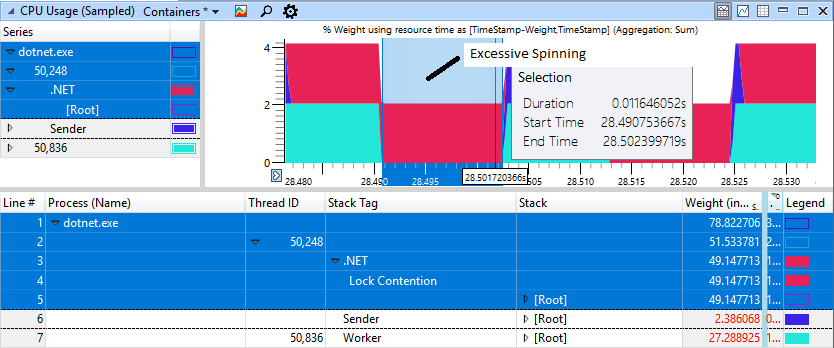
Um caso rápido e não degenerativo parece muito melhor, aqui apenas 1 ms é gasto na rotação para bloquear.
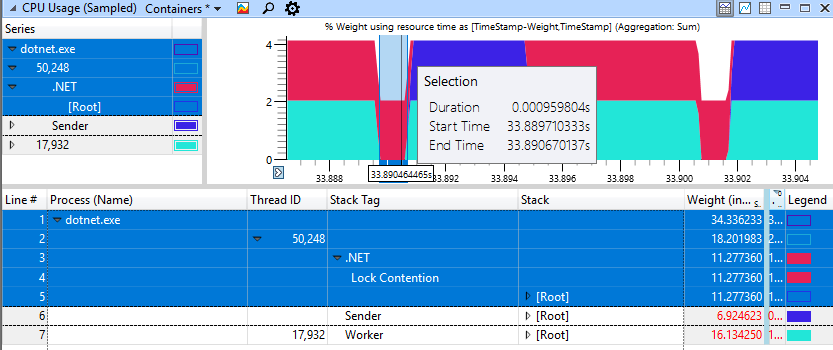
Eu usei o aplicativo de teste
SkylakeXPause . O
arquivo zip contém código-fonte e binários para o .NET Core e o .NET 4.5. Para comparação, instalei o .NET 4.8 Preview com correções e o .NET Core 2.0, que ainda implementa o comportamento antigo. O aplicativo foi desenvolvido para o .NET Standard 2.0 e .NET 4.5, produzindo exe e dll. Agora você pode verificar o antigo e o novo comportamento de centrifugação lado a lado sem a necessidade de corrigir nada, é muito conveniente.
readonly object _LockObject = new object(); int WorkItems; int CompletedWorkItems; Barrier SyncPoint; void RunSlowTest() { const int processingTimeinMs = 10; const int WorkItemsToSend = 100; Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times"); // Test one sender one receiver thread with different timings when the sender wakes up again // to send the next work item // synchronize worker and sender. Ensure that worker starts first double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; foreach (var sendDelay in sendDelayTimes) { SyncPoint = new Barrier(2); // one sender one receiver var sw = Stopwatch.StartNew(); Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay), () => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs)); sw.Stop(); Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s"); Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs } } /// <summary> /// Simulate a worker thread which consumes CPU which is triggered by the Sender thread /// </summary> void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs) { SyncPoint.SignalAndWait(); while (CompletedWorkItems != maxWorkItemsToWork) { lock (_LockObject) { if (WorkItems == 0) { Monitor.Wait(_LockObject); // wait for work } for (int i = 0; i < WorkItems; i++) { CompletedWorkItems++; SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock } WorkItems = 0; } } } /// <summary> /// Insert work for the Worker thread under a lock and wake up the worker thread n times /// </summary> void Sender(int workItems, double delayInMs) { CompletedWorkItems = 0; // delete previous work SyncPoint.SignalAndWait(); for (int i = 0; i < workItems; i++) { lock (_LockObject) { WorkItems++; Monitor.PulseAll(_LockObject); } SimulateWork(delayInMs); } }
Conclusões
Este não é um problema do .NET. Todas as implementações de spinlock usando a instrução pause são afetadas. Eu verifiquei rapidamente o núcleo do Windows Server 2016, mas não existe esse problema na superfície. Parece que a Intel foi gentil o suficiente - e sugeriu que são necessárias algumas mudanças na abordagem da fiação.
Um bug do .NET Core foi relatado em agosto de 2017 e, em setembro de 2017,
um patch e uma versão do .NET Core 2.0.3 foram lançados. O link mostra não apenas a excelente reação do grupo .NET Core, mas também o fato de que, alguns dias atrás, o problema foi corrigido na ramificação principal, além de uma discussão sobre otimizações adicionais de rotação. Infelizmente, o Desktop .NET Framework não está se movendo tão rápido, mas, diante da visualização do .NET Framework 4.8, temos pelo menos uma prova conceitual de que as correções existentes também são implementáveis. Agora estou aguardando o backport do .NET 4.7.2 usar o .NET a toda velocidade e no último hardware. Este é o primeiro bug que encontrei que está diretamente relacionado a alterações de desempenho devido a uma instrução da CPU. O ETW continua sendo o principal criador de perfil no Windows. Se eu pudesse, pediria à Microsoft para portar a infraestrutura ETW para o Linux, porque os perfis atuais do Linux ainda são péssimos. Eles recentemente adicionaram recursos interessantes do kernel, mas ainda não existem ferramentas de análise como o WPA.
Se você estiver trabalhando com o .NET Core 2.0 ou o .NET Framework da área de trabalho nos processadores mais recentes lançados desde meados de 2017, em caso de problemas com a degradação do desempenho, verifique definitivamente seus aplicativos com um criador de perfil - faça o upgrade para o .NET Core e, esperamos, em breve para .NET Desktop Meu aplicativo de teste informará sobre a presença ou ausência de um problema.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detectedou
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detectedA ferramenta relatará um problema se você estiver trabalhando no .NET Framework sem a atualização apropriada e no processador Skylake.
Espero que você tenha achado a investigação desse problema tão empolgante quanto eu. Para realmente entender o problema, você precisa criar um meio de reproduzi-lo, permitindo experimentar e procurar fatores de influência. O resto é apenas um trabalho chato, mas agora sou muito melhor para entender as causas e conseqüências de uma tentativa cíclica de bloquear a CPU.