
Em março, nossa equipe de desenvolvimento com o orgulhoso nome "Hands-Auki" lutou vigilante por dois dias nos campos digitais do hackathon AI.HACK. No total, foram propostas cinco tarefas de diferentes empresas. Focamos na tarefa da Gazpromneft: prever a demanda de combustível de clientes B2B. De acordo com dados anônimos, era necessário aprender a prever quanto um determinado cliente comprará no futuro, de acordo com a região de compra de combustível, número de combustível, tipo de combustível, preço, data e ID do cliente. Olhando para o futuro - nossa equipe resolveu esse problema com a maior precisão. Os clientes foram divididos em três segmentos: grande, médio e pequeno. Além da tarefa principal, também construímos uma previsão do consumo total para cada um dos segmentos.
O descarregamento continha dados de compras de clientes para o período de novembro de 2016 a 15 de março de 2018 (para o período de 1 de janeiro de 2018 a 15 de março de 2018, os dados NÃO incluíam volumes).
Dados de exemplo:
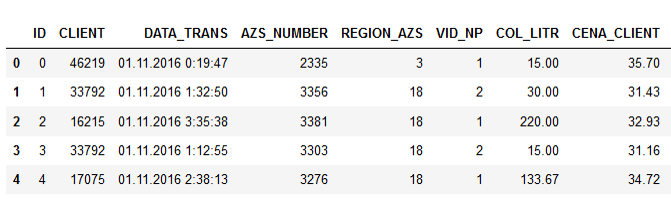
Os nomes das colunas falam por si, acho que não faz sentido explicar.
Além da amostra de treinamento, os organizadores forneceram uma amostra de teste por três meses deste ano. Os preços são para clientes corporativos, levando em consideração descontos específicos, que dependem do consumo de um cliente em particular, de ofertas especiais e outros pontos.
Depois de receber os dados iniciais, nós, como todo mundo, começamos a experimentar os métodos clássicos de aprendizado de máquina, tentando construir um modelo adequado, buscando a correlação de alguns sinais. Tentamos extrair recursos adicionais, construímos modelos de regressão (XGBoost, CatBoost etc.).
A afirmação do problema propriamente dita implicava inicialmente que o preço do combustível influencia de alguma forma a demanda, e é necessário entender com mais precisão essa dependência. Mas quando começamos a analisar os dados fornecidos, vimos que a demanda não se correlaciona com o preço.

Correlação de sinal:
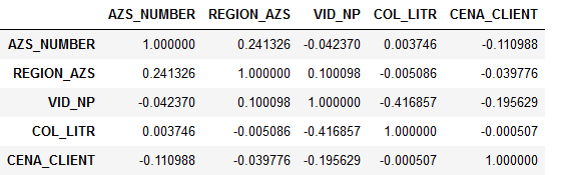
Descobriu-se que o número de litros praticamente não depende do preço. Isso foi explicado logicamente. O motorista vai na estrada, ele precisa reabastecer. Ele tem uma escolha: ou reabastecerá em um posto de gasolina com o qual a empresa colabora ou em algum outro local. Mas o motorista não se importa quanto custa o combustível - a organização paga por isso. Portanto, ele simplesmente desliga para o posto de gasolina mais próximo e enche o tanque.
No entanto, apesar de todos os esforços e modelos testados, não foi possível alcançar a precisão mínima aceitável da previsão (linha de base), que foi calculada usando esta fórmula (erro percentual absoluto médio simétrico):
Tentamos todas as opções, nada funcionou. E então ocorreu a um de nós cuspir no aprendizado de máquina e recorrer às boas estatísticas antigas: basta pegar o valor médio para o tipo de combustível, validar e ver qual precisão você obtém.
Então, primeiro excedemos o valor limite.
Começamos a pensar em como melhorar o resultado. Tentamos obter valores medianos por grupos de clientes, tipos de combustível, regiões e números de postos de gasolina. O problema era que nos dados de teste estavam faltando cerca de 30% dos IDs de clientes que estavam na amostra de treinamento. Ou seja, novos clientes apareceram no teste. Este foi um erro que os organizadores não verificaram. Mas tivemos que resolver o problema nós mesmos. Não conhecíamos o consumo de novos clientes e, portanto, não conseguimos construir previsões para eles. E aqui o aprendizado de máquina apenas ajudou.
Na primeira etapa, os dados ausentes foram preenchidos com o valor médio ou mediano de toda a amostra. E surgiu a ideia: por que não criar novos perfis de clientes com base nos dados existentes? Temos cortes por região, quantos clientes compram combustível lá, com que frequência e quais tipos. Agrupamos clientes existentes, compilamos perfis específicos para diferentes regiões e treinamos o XGBoost neles, que "completaram" os perfis de novos clientes.
Isso nos permitiu entrar em primeiro lugar. Ainda faltavam três horas para resumir os resultados. Ficamos encantados e começamos a resolver o problema do bônus - previsão por segmentos com três meses de antecedência.
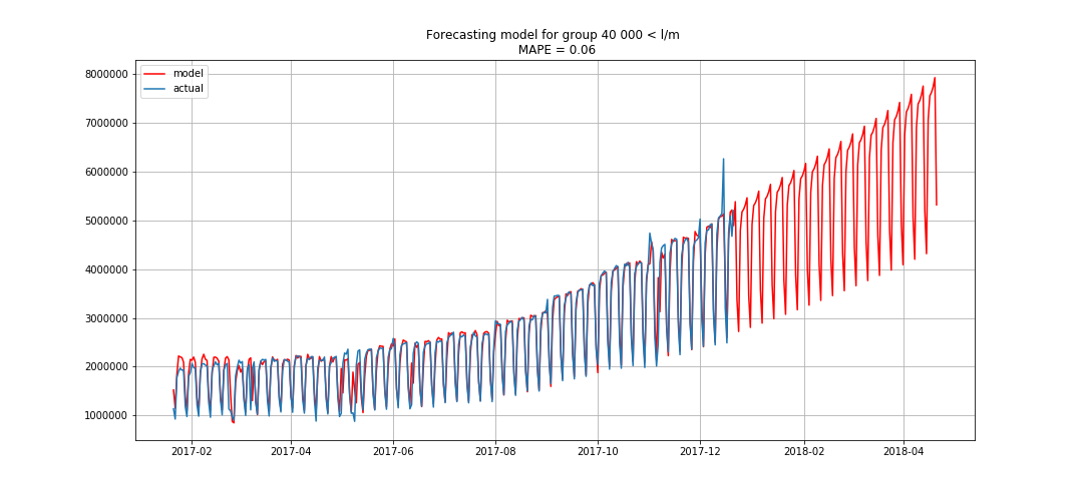
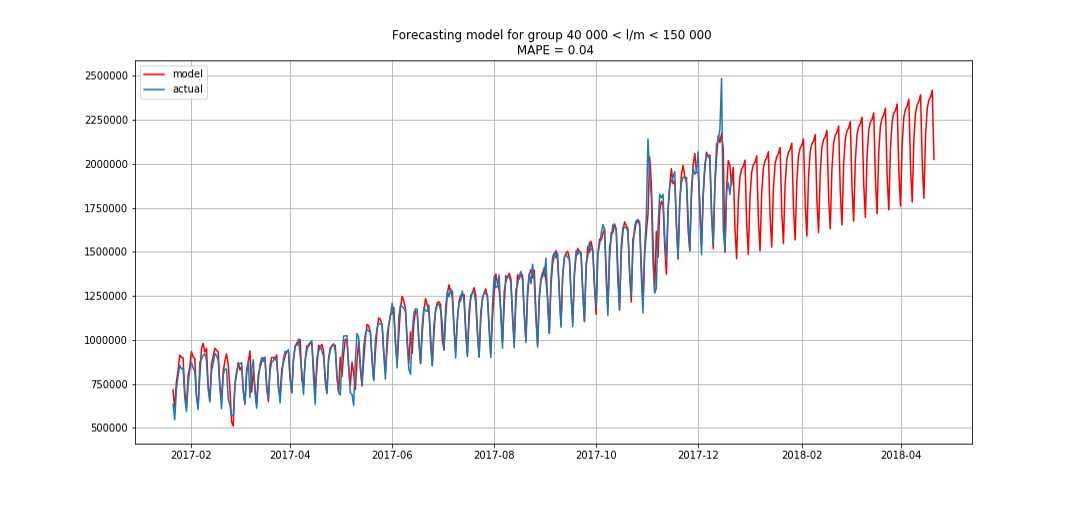
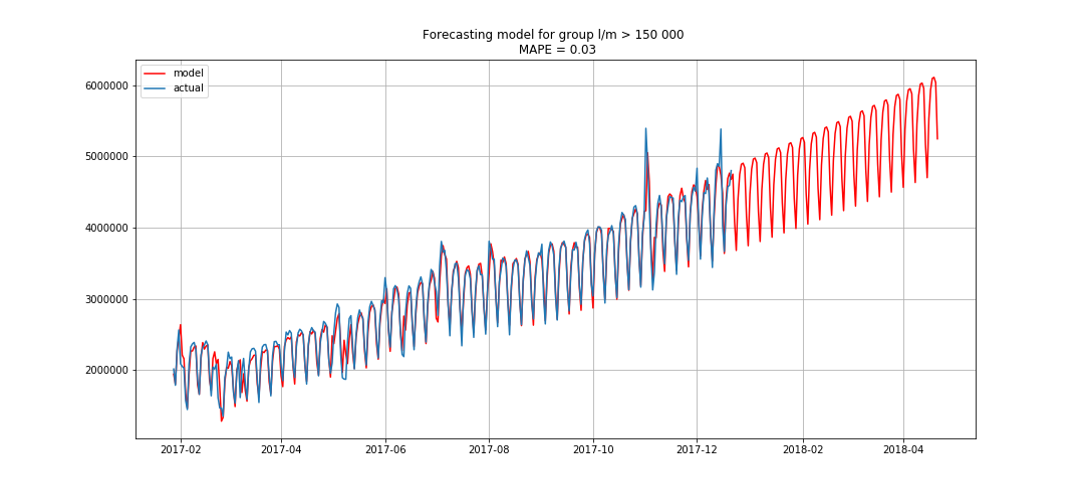
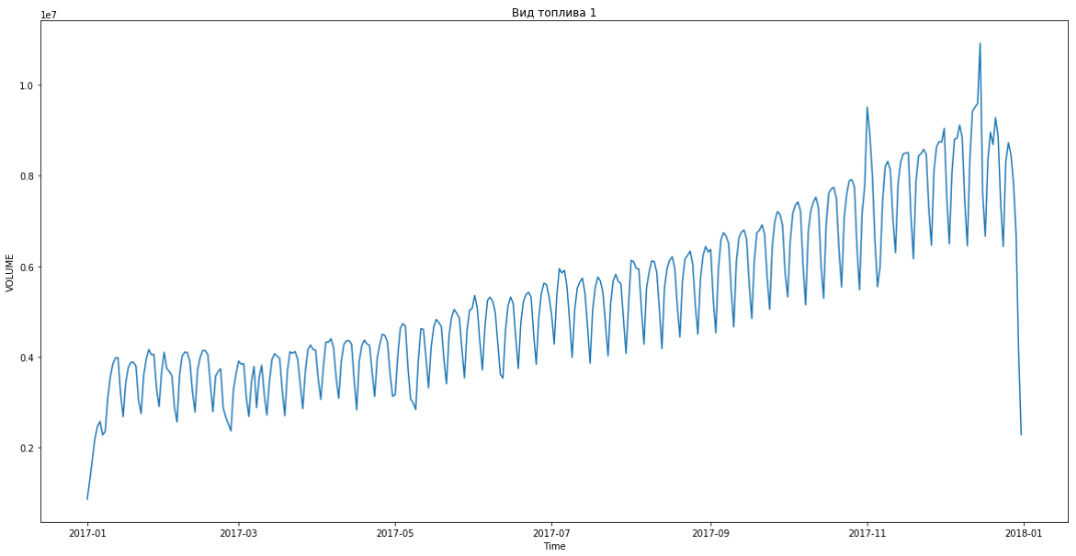
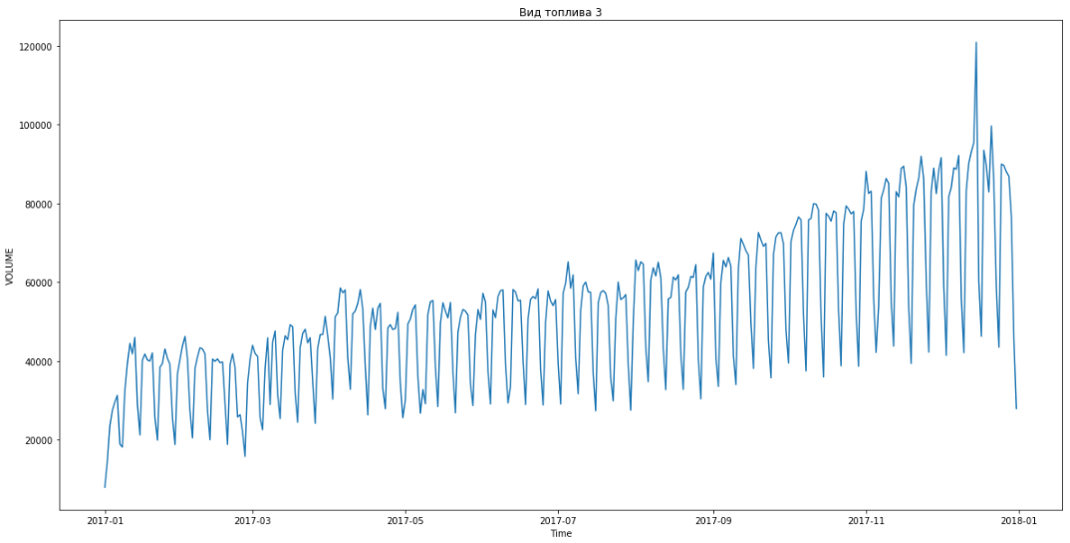
Azul mostra dados reais, vermelho - previsão. O erro variou de 3% a 6%. Pode ser calculado com mais precisão, por exemplo, levando em consideração picos sazonais e feriados.
Enquanto estávamos fazendo isso, uma equipe começou a nos acompanhar, melhorando nosso resultado a cada 15 a 20 minutos. Nós também começamos a discutir e decidimos fazer alguma coisa, caso eles nos alcançassem.
Eles começaram a criar outro modelo em paralelo, que classificava as estatísticas por grau de significância; sua precisão era ligeiramente menor que a do primeiro. E quando os concorrentes nos venceram, tentamos combinar os dois modelos. Isso nos deu um ligeiro aumento na métrica - até 37,24671%, como resultado, recuperamos nosso primeiro lugar e o mantemos até o fim.
Pela vitória, nossa equipe Ruki-Auki recebeu um certificado de 100 mil rublos, honra, respeito e ... cheio de auto-estima, fui ao spa! ;)
Equipe de desenvolvimento de Jet Infosystems