Mais recentemente, procuramos um cientista de dados na equipe (e encontramos - olá,
nik_son e Arseny!). Ao conversar com os candidatos, percebemos que muitas pessoas querem mudar de emprego porque estão fazendo algo “na mesa”.
Por exemplo, eles assumem a previsão complexa que o chefe propôs, mas o projeto para porque a empresa não entende o que e como incluir na produção, como obter lucro, como "recuperar" os recursos gastos no novo modelo.

O HeadHunter não possui grande poder de computação, como o Yandex ou o Google. Entendemos como é difícil lançar ML complexo em produção. Portanto, muitas empresas enfatizam o fato de que os modelos lineares mais simples estão sendo lançados na produção.
No processo da próxima implementação do ML no sistema de recomendação e na busca de vagas, encontramos vários "ancinhos" clássicos. Preste atenção a eles se você pretende implementar o ML em casa: talvez esta lista o ajude a não os seguir
e encontrar seu rake pessoal .
Rake No. 1: Data Scientist - Artista grátis
Em toda empresa que começa a introduzir o aprendizado de máquina, incluindo redes neurais, em seu trabalho, existe uma lacuna entre o que o cientista de dados deseja fazer e o que beneficia a produção. Inclusive porque o negócio nem sempre pode explicar o que é o benefício e como ele pode ajudar.
Lidamos com isso da seguinte maneira: discutimos todas as idéias emergentes, mas apenas implementamos o que beneficiará a empresa - agora ou no futuro. Não fazemos pesquisas no vácuo.
Após cada implementação ou experimento, consideramos a qualidade, os recursos e os efeitos econômicos e atualizamos nossos planos.
Rake número 2: atualizando bibliotecas
Este problema ocorre em muitos. Muitas bibliotecas novas e convenientes estão aparecendo, das quais ninguém tinha ouvido falar há alguns anos atrás, ou nenhuma. Eu gostaria de usar as bibliotecas mais recentes, porque são mais convenientes.
Mas existem vários obstáculos:
1. Se o prod usa, por exemplo, o 14º Ubuntu, provavelmente não há novas bibliotecas nele. A solução é transferir o serviço para o docker e instalar as bibliotecas Python usando pip (em vez de pacotes deb).
2. Se um formato dependente de código for usado para armazenamento de dados (como pickle), isso congelará as bibliotecas usadas. Ou seja, quando o modelo de aprendizado de máquina foi obtido usando a biblioteca do scikit-learn versão 15 e salvo no formato pickle, para a recuperação correta do modelo, será necessária a biblioteca do scikit-learn de quinze versões. Você não pode atualizar para a versão mais recente, e essa é uma armadilha muito mais insidiosa do que a descrita no parágrafo 1.
Existem duas maneiras de fazê-lo:
- Use um formato independente de código para armazenar modelos
- sempre seja possível treinar novamente qualquer modelo. Em seguida, ao atualizar a biblioteca, será necessário treinar todos os modelos e salvá-los com a nova versão da biblioteca.
Nós escolhemos o segundo caminho.
Ancinho número 3: trabalhe com modelos antigos
Fazer algo novo em um modelo antigo e aprendido é menos útil do que fazer algo simples em um novo. Muitas vezes, no final, verifica-se que a introdução de modelos mais simples, porém mais recentes, é mais útil e a quantidade de esforço é menor. É importante lembrar disso e sempre levar em conta a quantidade de esforços comuns na busca de padrões.
Rake número 4: apenas experiências locais
Muitos especialistas em ciência de dados gostam de experimentar localmente em seus servidores de aprendizado de máquina. Somente os produtos não têm essa flexibilidade: como resultado, são reveladas várias razões pelas quais é impossível arrastar essas experiências para a produção.
É importante configurar a comunicação entre o especialista em DS e os engenheiros de vendas para um entendimento comum - como esse ou aquele modelo funcionará na produção, se há a capacidade e a capacidade física necessárias para implementá-lo. Além disso, quanto mais complexos forem os modelos e fatores, mais difícil será torná-los confiáveis e poder treiná-los novamente a qualquer momento. Diferentemente das competições do Kaggle, na produção geralmente é melhor sacrificar dez milésimos das métricas locais e até um pouco de KPI on-line, mas implementar a versão dos modelos é muito mais simples, estável em resultados e fácil em recursos de computação.
A co-propriedade do código (desenvolvedores e cientistas de dados sabem como o código escrito por outros desenvolvedores funciona), a reutilização de sinais e meta-atributos em vários modelos, tanto no processo de aprendizado quanto no trabalho em prod, nos ajudam a não usar esse rake: nós), testes unitários e automáticos, que conduzimos com frequência, codificam a integração com o novo teste. Colocamos os modelos finais nos repositórios git e os usamos também na produção.
Ancinho número 5: teste apenas prod
Cada um de nossos desenvolvedores e cientistas de dados tem seu próprio banco de testes, às vezes não um. Os principais componentes da produção HH são implantados nele. É caro, mas paga por qualidade e velocidade de desenvolvimento. É necessário, mas não o suficiente. Carregamos não apenas os modelos que já estão em produção, mas também aqueles que estarão lá em breve. Isso ajuda a entender com o tempo que os modelos que funcionam perfeitamente em máquinas locais, bancadas de teste ou em produção para 5% dos usuários e, quando ativados 100%, são muito pesados.
Usamos várias etapas de teste. Verificamos o código muito rapidamente (este é o ponto principal) - ao adicionar ou alterar componentes no repositório, o código é coletado, os testes de unidade e autoteste são executados nos componentes correspondentes, se necessário, também os testamos manualmente - e se algo estiver errado, dê uma resposta "O seu está quebrado, decida."
Rake número 6: cálculos longos e perda de foco
Se um modelo exige, digamos, uma semana para treinar, é fácil perder a concentração na tarefa devido à mudança para outro projeto. Tentamos não dar aos desenvolvedores e cientistas de dados mais de duas tarefas em uma mão. E não mais que um urgente, para que você possa mudar assim que os cálculos ou experimentos A / B forem concluídos. Essa regra é necessária para não perder o foco, e com medo de que algumas dessas tarefas geralmente correm o risco de serem perdidas, e outra parte que é lançada muito mais tarde do que o necessário.
Nós pisamos em um ancinho, mas não desistimos
Recentemente, concluímos um experimento sobre a introdução de redes neurais em um sistema de recomendação. Tudo começou com o fato de que em dois dias o hackathon interno escreveu um modelo para prever respostas por currículo, o que facilitou bastante a busca de vagas adequadas.
Mas depois aprendemos: para lançá-lo em produção, você precisa atualizar praticamente tudo - por exemplo, transferir o sistema de uso duplo, que considera sinais e ensina modelos, para o docker, bem como atualizar as bibliotecas de aprendizado de máquina.
Como foi
Utilizamos o modelo DSSM com uma rede neural de camada única. No artigo original da Microsoft, uma rede neural de três camadas foi usada, mas não observamos melhorias na qualidade com um aumento no número de camadas, por isso decidimos por uma camada.

Em resumo:
- O texto da consulta e o cabeçalho da vaga são convertidos em dois vetores de trigrama de símbolos. Usamos 20.000 trigramas de caracteres.
- O vetor trigrama é alimentado para a entrada de uma rede neural de camada única. Na entrada da camada de rede neural, existem 20.000 números, na saída, 64. De fato, a rede neural é uma matriz de 20.000 x 64 pela qual o vetor de trigrama de entrada da dimensão 1 x 20.000 é multiplicado.Um vetor constante da dimensão 1 x 64 é adicionado ao resultado da multiplicação. a saída dessa rede neural corresponde à solicitação (ou ao cabeçalho da vaga).
- O produto escalar do vetor dssm de consulta e o vetor dssm do cabeçalho de vaga é calculado. A função sigmóide é aplicada ao trabalho. O resultado final é o meta-sinal dssm.
Quando tentamos incluir esse modelo pela primeira vez, as métricas locais ficaram melhores, mas quando tentamos inseri-lo no teste A / B, vimos que não havia melhora.
Depois disso, tentamos aumentar a segunda camada de neurônios para 256 - lançada por 5% dos usuários: verificou-se que o sistema de recomendação e a pesquisa ficaram melhores, mas quando você ativou o modelo 100%, repentinamente ficou muito pesado.
Analisamos por que o modelo é tão pesado, removemos a ramificação e experimentamos novamente essa rede neural. E somente depois disso, depois de terem percorrido todo o caminho novamente, eles descobriram que o modelo é útil: o número de respostas no sistema de recomendação aumentou 700 por dia e na pesquisa, depois de todas as recontagens, 4200.
A introdução de uma rede neural não muito complexa permite que nossos clientes contratem várias dezenas de funcionários adicionais todos os dias através do hh.ru e, durante a implementação, derrotamos uma parte significativa dos grandes problemas. Portanto, planejamos desenvolver ainda mais nossas redes neurais. Os planos são tentar a obtenção geral, lematização adicional, processar os textos completos da vaga e retomar, fazer experimentos com a topologia (camadas ocultas e, possivelmente, RNN / LSTM).
A coisa mais importante que fizemos com este modelo:
- Não deixe o experimento cair no meio.
- Calculamos os indicadores de aumento de resposta e descobrimos que o trabalho nesse modelo valeu a pena. É muito importante entender quanto benefício cada implementação traz.
Curiosamente, o modelo que criamos e eventualmente adicionamos ao produto é muito semelhante ao método do componente principal (PCA) aplicado à matriz [texto da consulta, título do documento, se houve um clique]. Ou seja, para uma matriz na qual uma linha corresponde a uma consulta exclusiva, uma coluna para um cabeçalho de vaga exclusivo; o valor na célula é 1 se, após essa solicitação, o usuário clicar em uma vaga com esse cabeçalho e 0 se não houver clique.
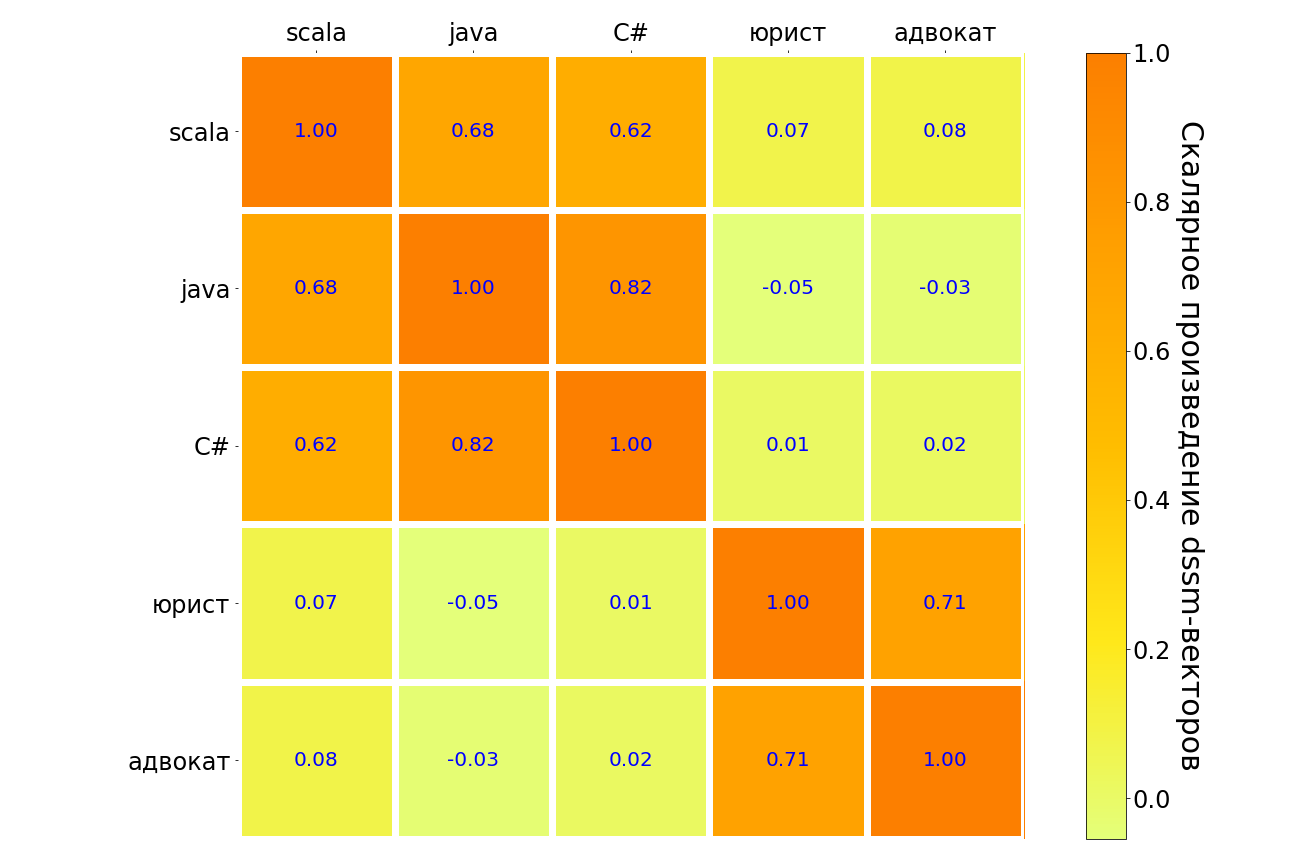
Os resultados da aplicação desse modelo às solicitações de scala, java, C #, "advogado", "advogado" estão na tabela abaixo. Pares de consultas com significado semelhante são destacados em escuro, ao contrário de claro. Pode-se observar que o modelo entende a conexão entre diferentes linguagens de programação, existe uma forte conexão entre a solicitação “advogado” e “advogado”. Mas entre o "advogado" e qualquer linguagem de programação, a conexão é muito fraca.
Em algum momento, eu realmente quero desistir - os experimentos estão em andamento, mas não estão "acendendo". Nesse ponto, um cientista de dados pode achar útil apoiar a equipe e mais uma vez calcular os benefícios: pode valer a pena "enterrar a aeromoça" e não tentar "montar o cavalo morto", isso não é um fracasso, mas um experimento bem-sucedido com resultado negativo. Ou, depois de ponderar os prós e os contras, você realizará outro experimento que será "filmado". Foi o que aconteceu conosco.