No final do inverno deste ano, foi realizada a competição Sociedade de Processamento de Sinais - Identificação de Modelo de Câmera do IEEE. Participei dessa competição por equipes como mentor. Sobre um método alternativo de formação de equipes, decisão e o segundo estágio sob o corte.
 tldr.py
tldr.pyfrom internet import yandex_fotki, flickr, wiki commons from Andres_Torrubia import Ivan_Romanov as pytorch_baseline import kaggle dataset = kaggle.data() for source in [yandex_fotki, flickr, wiki_commons]: dataset[train].append(source.download()) predicts = [] for model in [densenet201, resnext101, se_resnext50, dpn98, densenet161, resnext101 d4, se resnet50, dpn92]: with pytorch_baseline(): model.fit(dataset[train]) predicts.append(model.predict_tta(dataset[test])) kaggle.submit(gmean(predicts))
Declaração do problemaA partir da fotografia, é necessário determinar o dispositivo no qual essa fotografia foi obtida. O conjunto de dados consistiu em imagens de dez classes: dois iPhones, sete smartphones Android e uma câmera. A amostra de treinamento incluiu 275 imagens em tamanho real de cada classe. Na amostra de teste, apenas a colheita central de 512x512 foi apresentada. Além disso, um dos três aumentos foi aplicado a 50% deles: compactação jpg, redimensionamento com interpolação cúbica ou correção gama. Foi possível usar dados externos.
 Essência (tm)
Essência (tm)Se você tentar explicar a tarefa em linguagem simples, a ideia será apresentada na figura abaixo. Como regra, as redes neurais modernas são ensinadas a distinguir objetos em uma fotografia. isto é você precisa aprender a distinguir gatos de cães, pornografia de roupas de banho ou tanques de estradas. Ao mesmo tempo, deve ser sempre indiferente a como e em qual dispositivo a foto de um gato e um tanque é tirada.

No mesmo concurso, tudo foi exatamente o oposto. Independentemente do que é mostrado na foto, você precisa determinar o tipo de dispositivo. Ou seja, use itens como ruído de matriz, artefatos de processamento de imagem, defeitos ópticos etc. Este foi o principal desafio - desenvolver um algoritmo que capte recursos de imagens de baixo nível.
Recursos do trabalho em equipeA esmagadora maioria das equipes do Kaggle é formada da seguinte forma: os participantes com quase uma liderança na tabela de líderes são unidos em uma equipe, enquanto cada um está vendo sua versão da solução do começo ao fim. Eu escrevi um
post sobre um exemplo típico de tal discurso. No entanto, desta vez seguimos o outro caminho, a saber: dividimos as partes da decisão em pessoas. Além disso, de acordo com as regras da competição, as três principais equipes de estudantes receberam um ingresso para o Canadá para a segunda etapa. Portanto, quando a espinha dorsal se reuniu, a equipe foi insuficiente para cumprir as regras.
SoluçãoPara mostrar um bom resultado nessa tarefa, foi necessário montar o seguinte quebra-cabeça de acordo com as prioridades:
- Encontre e baixe dados externos. Esta competição foi autorizada a usar um número ilimitado de dados externos. E rapidamente ficou claro que um grande conjunto de dados externo estava sendo arrastado.
- Filtrar dados externos. Às vezes, as pessoas postam imagens processadas, o que mata todos os recursos do dispositivo.
- Use um esquema de validação local confiável. Como até um modelo mostrou precisão na região de 0,98+ e no teste houve apenas 2 mil fotos, a escolha do ponto de verificação do modelo era uma tarefa separada
- Modelos de trem. Uma linha de base muito poderosa foi postada no fórum. No entanto, sem uma pitada de magia, ele permitiu apenas prata.
Coleta de dadosEsta parte foi ocupada por
Arthur Fattakhov . Para esta tarefa, foi muito fácil obter dados externos, são apenas imagens de determinados modelos de telefone. Arthur escreveu um script python que usa a biblioteca para analisar convenientemente páginas html chamadas
BeautifulSoup . Mas, por exemplo, na página do álbum do flickr, blocos de fotos são carregados dinamicamente e, para contornar isso, tive que usar o
selênio , que emulava a ação do navegador. Um total de mais de 500 GB de fotos foi baixado do yandex.fotki, flickr, wiki commons.
Filtragem de dadosEssa foi minha única contribuição para a solução na forma de código. Eu apenas olhei como as fotos brutas pareciam e criaram várias regras: 1) o tamanho típico de um modelo específico 2) a qualidade do jpg está acima do limite 3) a presença das meta tags necessárias dos modelos 4) o software correto que foi processado.
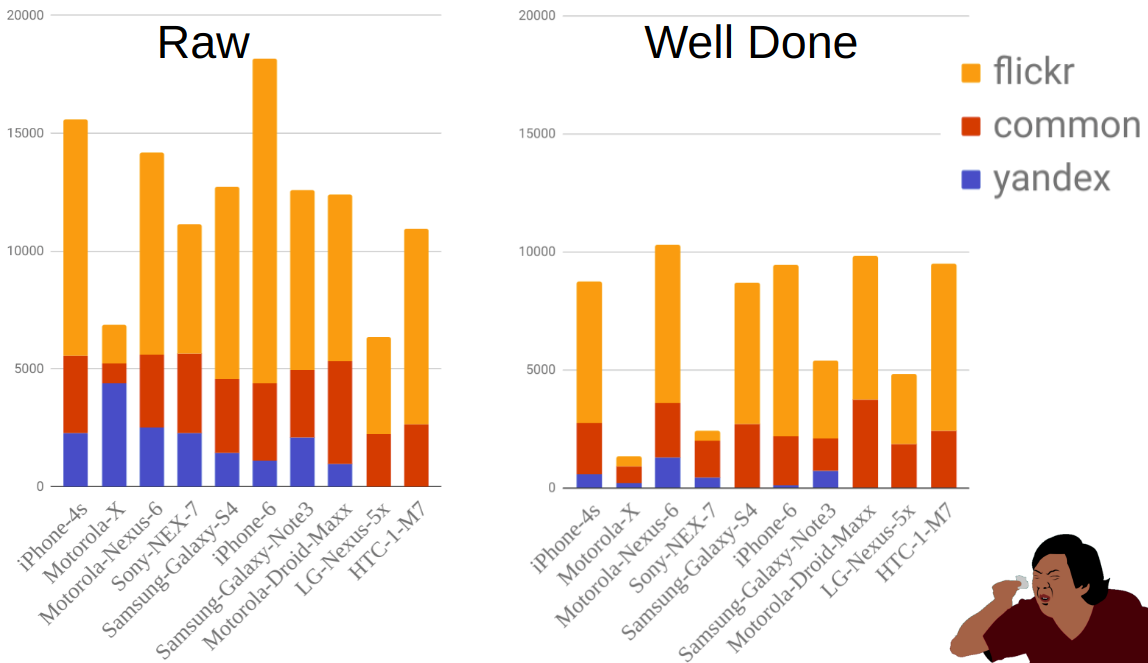
A figura mostra a distribuição das fotografias por fonte e móvel antes e depois da filtragem. Como você pode ver, por exemplo, o Moto-X é muito menor que outros telefones. Ao mesmo tempo, havia muitos deles antes da filtragem, mas a maioria deles foi eliminada devido ao fato de haver muitas opções para este telefone e os proprietários nem sempre indicarem corretamente o modelo.
ValidaçãoA implementação da parte com treinamento e validação foi realizada por
Ilya Kibardin . A validação em um pedaço de trem kaggle não funcionou de jeito nenhum - a grade atingiu quase 1,0 pontos de precisão e, na tabela de classificação, foi de cerca de 0,96.
Portanto, a validação foi tirada fotos de
Gleb Posobin , que ele tirou de todos os sites com críticas por telefone. Houve um erro: em vez do iPhone 6, havia um iPhone 6+. Nós o substituímos por um iPhone 6 real e deixamos cair 10% das imagens do trem do kagla para equilibrar as classes.
Ao aprender, a métrica foi considerada da seguinte maneira:
- Consideramos a entropia cruzada e o akurasi no centro da colheita a partir da validação.
- Consideramos a entropia cruzada e o akurasi (manipulação + centro da colheita) para cada uma das 8. Manipulações, com média média de mais de oito manipulações com média aritmética.
- Adicionamos a velocidade do item 1 e do item 2 com os pesos 0,7 e 0,3.
Os melhores pontos de verificação foram selecionados de acordo com a entropia cruzada ponderada obtida na Seção 3.
Modelo de treinamentoEm algum lugar no meio da competição,
Andrés Torrubia postou o
código inteiro
para sua decisão . Ele era tão bom em termos de precisão dos modelos finais que várias equipes voaram com ele na liderança. No entanto, ele foi escrito em keras e o nível de código desejado.
A situação mudou uma segunda vez quando
Ivan Romanov postou uma
versão pytorch desse código. Era mais rápido e, além disso, se comparava facilmente a várias placas de vídeo. O nível de código, no entanto, ainda não era muito bom, mas isso não é tão importante.
A tristeza é que esses caras terminaram nos 30º e 45º lugares, respectivamente, mas em nossos corações eles sempre permaneceram no topo.
Ilya em nossa equipe pegou o código de Misha e fez as seguintes alterações.
Pré-processamento:- A partir da imagem original é feita uma colheita aleatória 960x960.
- Com uma probabilidade de 0,5, uma manipulação aleatória é aplicada. (Dependendo se foi usado, is_manip = 1 ou 0 está definido)
- É feito um corte aleatório 480x480
- Havia duas opções de treinamento: uma rotação aleatória de 90 graus é feita em uma direção específica (simulando o disparo horizontal / vertical para um telefone celular) ou uma conversão aleatória do grupo D4.
 Treinamento
TreinamentoO treinamento foi realizado por toda a rede, sem congelar as camadas convolucionais do classificador (tínhamos muitos dados + intuitivamente, os pesos que os objetos de alto nível na forma de extrato de gatos / cães podem ser adicionados porque precisamos de recursos de baixo nível).
 Dedução:
Dedução:Adam com lr = 1e-4. Quando a perda de validação deixa de melhorar durante 2-3 épocas, reduzimos lr pela metade. Então, para convergência. Substitua Adam pelo SGD e aprenda três ciclos com um lr cíclico de 1e-3 a 1e-6.
Conjunto final:Pedi à Ilya para implementar minha abordagem da competição anterior. Para o conjunto filial, treinamos 9 modelos, de cada um dos três melhores pontos de verificação, cada ponto de verificação foi previsto com TTA e, no final, todas as previsões foram calculadas pela média geométrica.
 Posfácio da primeira etapa
Posfácio da primeira etapaComo resultado, ocupamos o 2º lugar na tabela de classificação e o 1º lugar entre as equipes de estudantes. E isso significa que chegamos à 2ª etapa desta competição como parte da
Conferência Internacional IEEE de 2018 sobre Acústica, Processamento de Fala e Sinal no Canadá. Do notável, a equipe que ficou em 3º lugar também foi formalmente estudante. Se calcularmos a velocidade, verificamos que contornamos com uma imagem prevista corretamente.
Copa final de processamento de sinais IEEE 2018Depois de termos recebido todas as confirmações, eu, Valery e Andrey decidimos não ir ao Canadá para a segunda etapa. Ilya e Arthur F. decidiram ir, começaram a organizar tudo e não receberam o visto. Para evitar um escândalo internacional sobre a opressão dos cientistas mais fortes da Rússia, as orgias foram autorizadas a participar remotamente.
A linha do tempo era assim:
03.03 - dados dos trens
04.09 - dados de teste emitidos
12.04 - pudemos participar remotamente
13.04 - começamos a ver o que há com os dados
16/04 - final
Características do segundo estágioNa segunda etapa, não havia tabela de classificação: era necessário enviar apenas uma submissão no final. Ou seja, mesmo o formato das previsões não pode ser verificado. Além disso, os modelos de câmera não eram conhecidos. E isso significa dois arquivos ao mesmo tempo: não funcionará usando dados externos e a validação local pode ser muito não representativa.
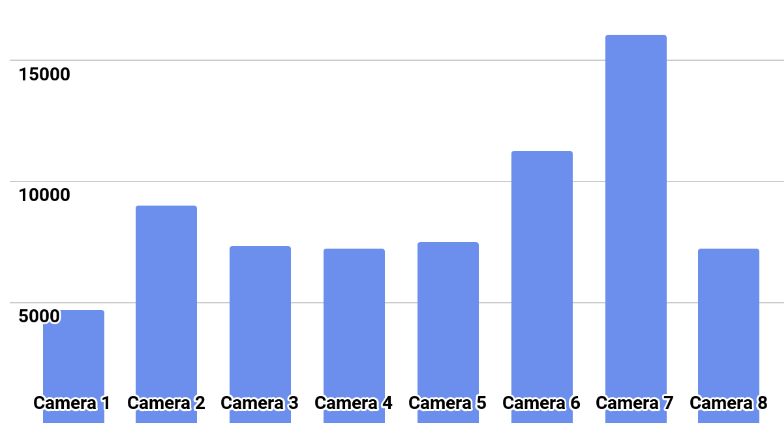
A distribuição de classes é mostrada na figura.
SoluçãoTentamos treinar modelos com um plano desde o primeiro estágio a partir das escalas dos melhores modelos. Todos os modelos treinaram alegremente com precisão de 0,97 ou mais em suas dobras, mas no teste eles deram um cruzamento de previsões na região de 0,87.
O que eu interpretei como um super ajuste rígido. Portanto, ele propôs um novo plano:
- Tomamos nossos melhores modelos do primeiro estágio como extratores de recursos.
- Pegamos o PCA a partir dos recursos extraídos para que tudo aprenda da noite para o dia.
- Aprendendo o LightGBM.

A lógica aqui é a seguinte. As redes neurais já são treinadas para extrair recursos de baixo nível do sensor, óptica, algoritmo de demonstração e, ao mesmo tempo, não se apegam ao contexto. Além disso, os recursos extraídos antes do classificador final (de fato, a regressão logística) são o resultado de uma transformação fortemente não linear. Portanto, alguém poderia simplesmente ensinar algo simples, não propenso a reciclagem, como a regressão logística. No entanto, como os novos dados podem ser muito diferentes dos dados do primeiro estágio, ainda é melhor treinar algo não linear, por exemplo, aumento de gradiente nas árvores de decisão. Eu usei essa abordagem em várias competições, onde publiquei o código.
Como houve um envio, não tenho uma maneira confiável de testar minha abordagem. No entanto, o DenseNet provou ser o melhor extrator de recursos. As redes Resnext e SE-Resnext apresentaram desempenho inferior na validação local. Portanto, a decisão final ficou assim.
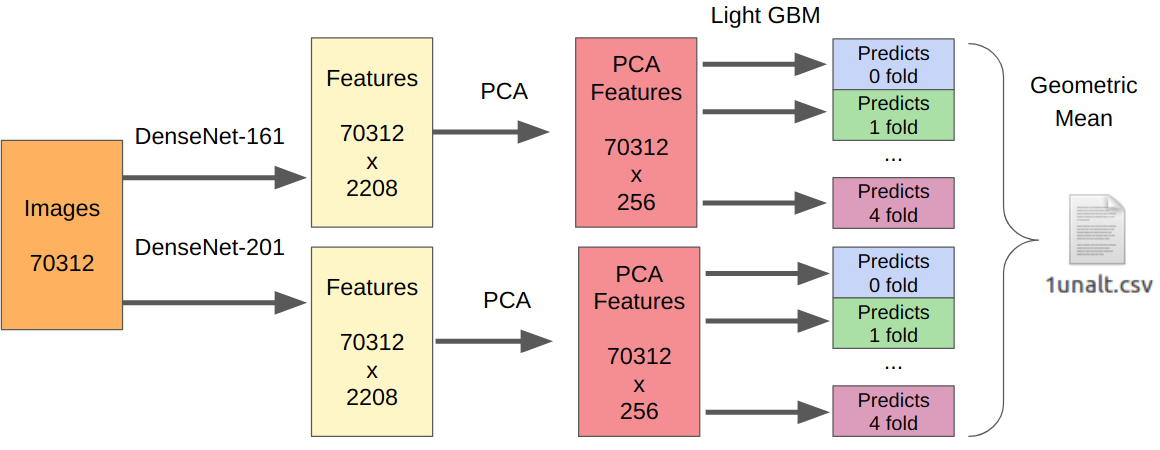
Para a parte com manipulações, o número de todas as amostras de treinamento precisa ser multiplicado por 7, pois extraí os recursos de cada manipulação separadamente.
PosfácioComo resultado, na etapa final, conquistamos o segundo lugar, mas há muitas reservas. Para começar, o local foi premiado não de acordo com a precisão do algoritmo, mas de acordo com as estimativas da apresentação do júri. A equipe, que conquistou o primeiro lugar, fez não apenas um preza, mas também uma demonstração ao vivo com o trabalho de seu algoritmo. Bem, ainda não sabemos a velocidade final de cada equipe, e as organizações não as divulgam em correspondência, mesmo após perguntas diretas.
O mais engraçado: no primeiro estágio, todas as equipes da nossa comunidade indicaram no nome da equipe [ods.ai] e ocuparam poderosamente a tabela de classificação. Depois disso, lendas kegle como
inversão e
Giba decidiram se juntar a nós para ver o que estávamos fazendo aqui.

Eu realmente gostei de participar como mentor. Com base na experiência de participar de competições anteriores, pude dar uma série de dicas valiosas sobre como melhorar a linha de base, bem como construir uma validação local. No futuro, esse formato será mais do que o caso: Kaggle Master / Grandmaster como arquiteto da solução + 2-3 Kaggle Expert para escrever código e testar hipóteses. Na minha opinião, isso é puro ganha-ganha, já que participantes experientes já estão com preguiça de escrever código e talvez não muito tempo, e os iniciantes obtêm um resultado melhor, não cometem erros triviais por inexperiência e ganham experiência ainda mais rapidamente.
→
Código da nossa solução→
Gravando desempenho com treino de ML