Nos últimos 10 anos, o VTB experimentou um aumento maciço na carga de computação. A cada ano, aumentava uma vez e meia e o volume de credenciais - duas. Os serviços de suporte tentaram muito, mas acompanhar esse ritmo não foi fácil: os planos de consulta estavam se afastando, o espaço em disco estava acabando, as atualizações de código do aplicativo estavam consumindo todos os recursos. Nesta postagem, mostraremos como resolver o problema sem gastar muito em outro IBM System p.

Em 2013, o processamento do cartão, então ainda banco VTB24, estava localizado em um dos servidores mais poderosos da época - IBM System p. Isso foi complementado por réplicas para diferentes relatórios. As réplicas para relatórios residiam em equipamentos adicionais: um banco de dados atualizado noturno para relatórios diários, ferramentas para a réplica ativa do Oracle Active Data Guard para relatórios operacionais e um banco de dados para relatórios do Banco Central, que atualizamos mensalmente.
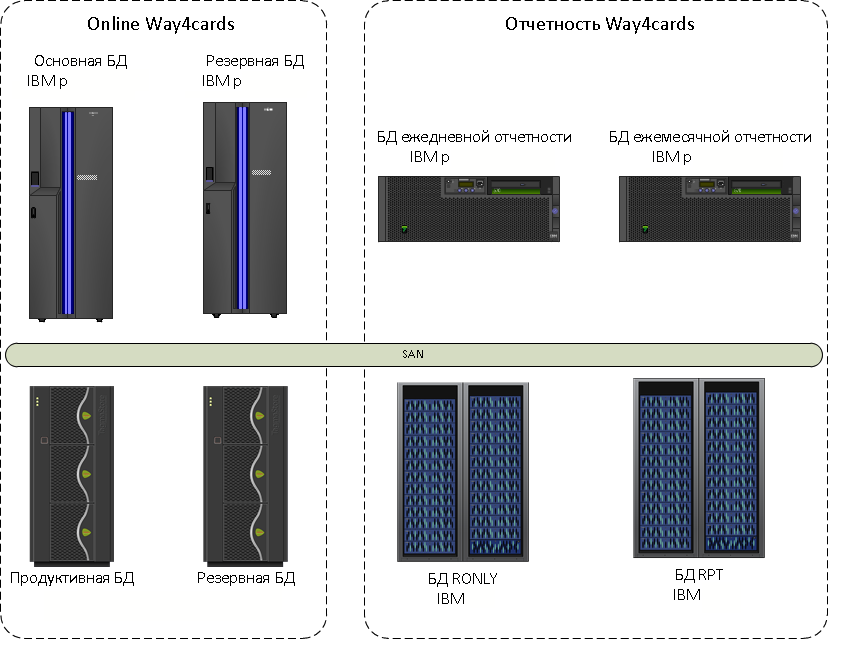
Personalizamos ativamente a funcionalidade dos sistemas - a maior parte do código do aplicativo foi ocupada por melhorias internas. Ao mesmo tempo, os dados cresceram muito rapidamente. Como resultado, o plano de consulta para quatro bases estava se deteriorando regularmente. Os sistemas frontais eram lentos. Do ponto de vista técnico, havia mais uma dificuldade: a carga OLTP das transações com cartão era misturada com a carga DWH / DSS de funcionalidade e relatório personalizados.
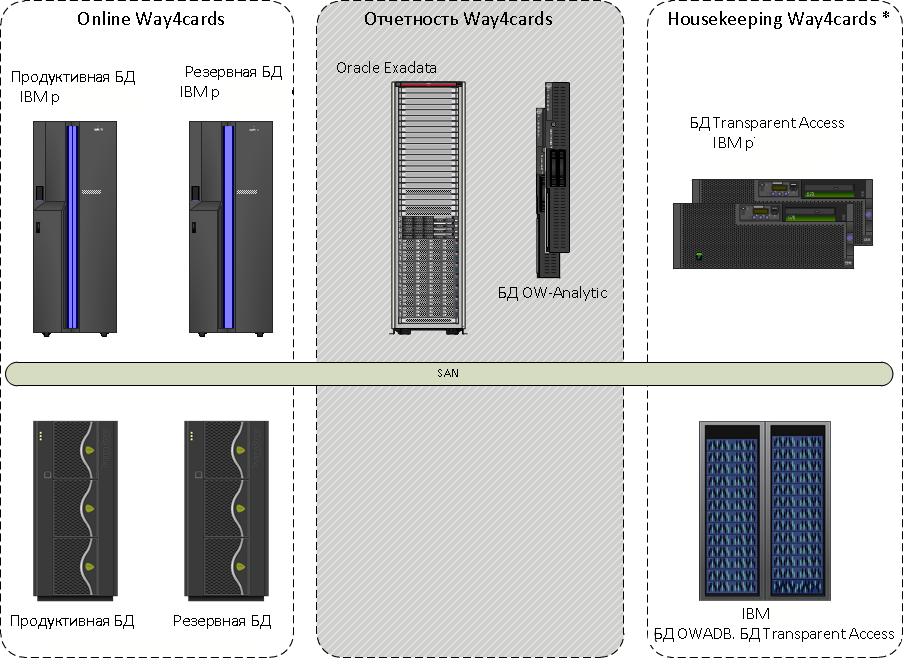
A saída padrão dessa situação é despejar recursos e alternar para um subsistema mais íngreme de armazenamento de dados. Chegamos a uma opção mais interessante: optamos por relatar réplicas dois complexos de hardware e software Oracle Exadata otimizados para operação do banco de dados.
O complexo de processamento foi dividido em zonas "quentes" e "quentes". A zona quente não foi movida para lugar nenhum com o IBM System p e apenas seu banco de dados foi preservado. A zona "quente" era uma cópia do banco de dados principal no Exadata. Aqui estavam todos os relatórios e funcionalidades personalizadas. Dados replicados usando o Oracle GoldenGate.
Executamos testes de réplica no Exadata: em média, os relatórios se tornaram cinco vezes mais rápidos graças à arquitetura e aos recursos do software Oracle Exadata Storage - smartscans, índices de armazenamento, filtros bloom, etc. O tempo necessário para preparar relatórios para o Banco Central foi reduzido em dez vezes e agora alguns relatórios são preparados em menos de 1 hora. O principal a ser feito para otimizar as consultas durante a transferência para o Exadata foi remover as dicas que anteriormente ajudavam a trabalhar na plataforma antiga.
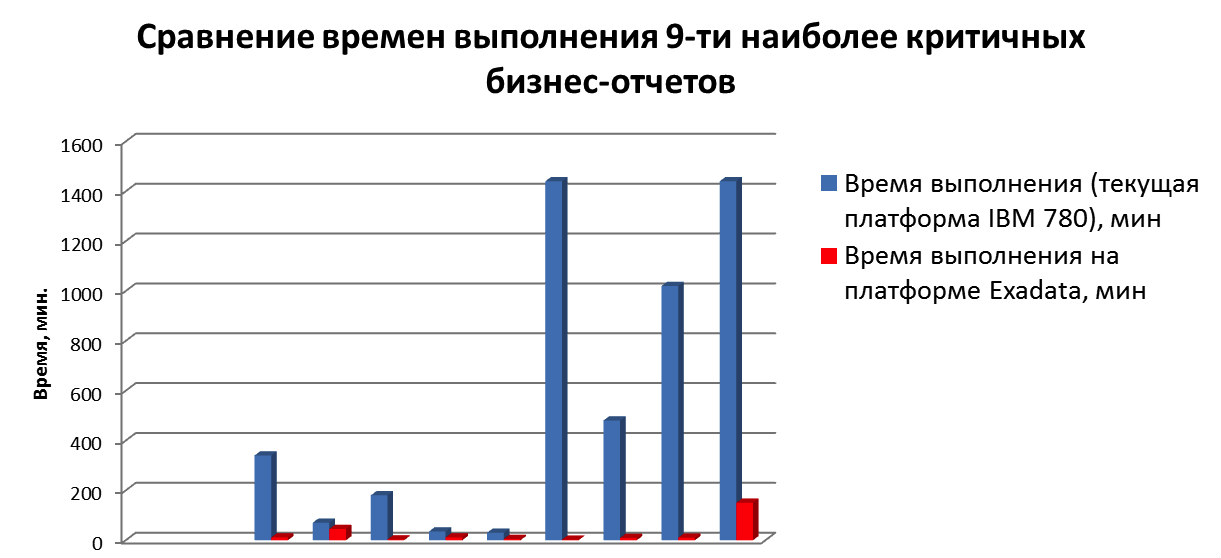
Realizamos um estudo de viabilidade, comparando opções para vários parâmetros com a extensão usual dos sistemas atuais e com o envolvimento de dois complexos Exadata.
- Performance. 40 mil IOPS versus 400 mil IOPS na Exadata. A solução Oracle é voltada para grandes quantidades de dados, a verificação completa da tabela é muito mais rápida.
- Opções de personalização. Na solução padrão, não podemos alterar a estrutura dos objetos sem alterar o banco de dados produtivo, isso é proibido pelo fornecedor. No Exadata, podemos remover índices desnecessários, adicionar os necessários e melhorar a resposta do sistema.
- Dimensionamento. Exadata fornece um aumento linear da produtividade a um custo relativamente menor.
- Relatórios. A velocidade dos relatórios com o complexo Exadata aumenta em 5 vezes, e com a escala dos sistemas existentes - em 1,5.
- Serviço. A infraestrutura Oracle possui suporte técnico unificado, um único sistema de atualização para servidores, subsistemas de disco e infraestrutura de rede. Com a escala normal, você precisa trabalhar com diferentes fornecedores - há mais tempo de inatividade e qualquer outro inconveniente.
- Custo. O Exadata vence aqui.
No início, a replicação do GoldenGate acabou sendo um ponto fraco: no caso de longas transações na fonte, ficou para trás. Resolvemos isso atualizando e refinando alguns processos de aplicativos. Depois disso, trabalhar com o Exadata revelou apenas vantagens para nós.
Introduzimos índices e particionamentos personalizados, o que nos permitiu aumentar o desempenho das funções personalizadas. A IBM não permite essa otimização.
A transferência de relatórios analíticos para a zona "quente" permitiu reduzir a profundidade do armazenamento de dados históricos da zona "quente". Isso reduziu o custo de armazenamento caro. Conseguiu acelerar a inserção em índices. A exclusão de dados através do módulo de limpeza foi filtrada no nível GoldenGate, como resultado, a réplica teve novos dados e toda a história;
O Exadata usa compactação de coluna híbrida (HCC) e isso economiza espaço em disco significativamente. Dados com mais de um ano são compactados pelo método baixo de arquivamento, mais de um mês pelo método de compactação avançado; dados mais recentes não são compactados para aumentar a velocidade.
Quanto à atualização, é mais eficiente substituir células de armazenamento inteiras no Exadata por células com discos mais espaçosos e processadores poderosos. Mas você pode usar células de armazenamento de versões diferentes no mesmo sistema - a Oracle permite isso.
Os relatórios de processamento de cartões, implementados nas tecnologias Oracle Exadata e Database, têm funcionado bem até agora, e novos sistemas bancários estão sendo construídos com o mesmo princípio.