Uma grande empresa de mineração criou uma tarefa interessante: existem muitos sites com sistemas de TI. Eles estão localizados nas cidades e em depósitos. São várias dezenas de escritórios regionais, além de empresas de mineração. 500 quilômetros na taiga sem estrada - fácil! Em cada instalação, há equipamentos que precisam ser "dobrados" em uma infraestrutura comum e para determinar o que e em que condições ele funciona.
O que era necessário aqui não era apenas um inventário técnico de todos os dispositivos na rede (números de série, versões de software etc.), mas um sistema de monitoramento completo. Porque Para identificar as causas principais dos acidentes e alertá-lo prontamente, construa mapas de rede, estabeleça conexões entre equipamentos, monitore o estado do ferro e os canais de comunicação, faça avisos sobre como parar o suporte ou ativar novos equipamentos não contabilizados etc. Além disso, a integração era necessária com o CMDB (levando em consideração as unidades de configuração), para que todo o ferro que o sistema de monitoramento "encontrou" seja comparado com o registrado em uma ramificação específica, ou seja, esteja de fato na rede.
Outro sistema de monitoramento precisava ser "amigo" do teleférico Asterisk, para que este último
no caso de algumas situações graves de emergência, como uma falta de energia no local em Krasnoyarsk, ele poderia ligar automaticamente rapidamente para as pessoas responsáveis. Havia também a tarefa de distinguir entre a visibilidade dos objetos de monitoramento e os poderes dos grupos de usuários. Os operadores cuidam do equipamento, Moscou - Moscou, engenheiros em campo - apenas seu campo.
O cliente escolheu entre vários sistemas de monitoramento: 1) produto shareware; 2) uma das soluções comerciais; 3) Sistema Infosim StableNet. Como resultado dos testes, as desvantagens do produto shareware ficaram claras para o cliente: era longo e difícil de configurar, além de não ter a quantidade de funcionalidade necessária (na mesma parte, por exemplo, renderizar conexões entre dispositivos na rede). Fora da caixa, ele não sabe como fazer isso, mas com os plugins acaba sendo mais ou menos. O produto comercial não possui agentes de monitoramento distribuídos - eles são instalados em um site específico e controlam apenas seus “arbustos”. Assim, paramos na Infosima - ele fechou toda a lista de desejos. E é por isso.
É assim que a tela principal do administrador do InfoSim StableNet se parece (esse não é um projeto mineral, mas uma infraestrutura de teste).
A tela principal na qual o status atual da rede é exibido:

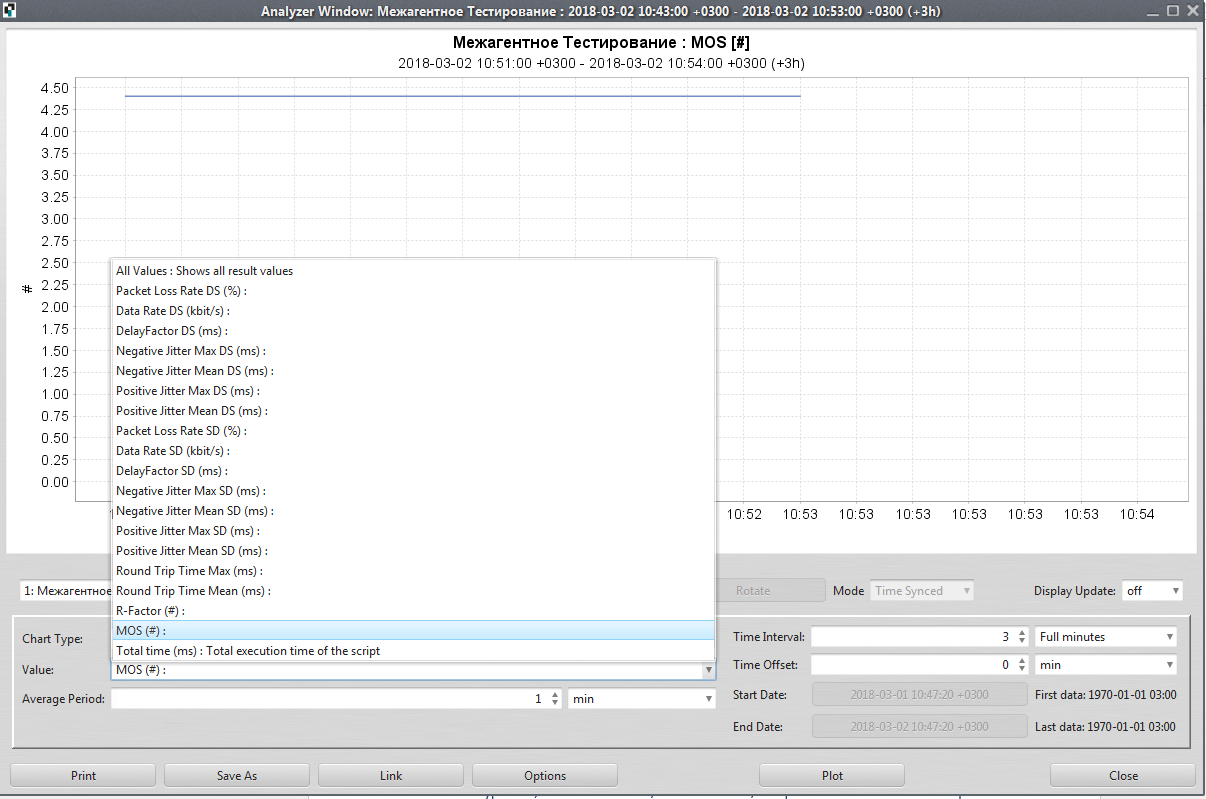
O painel de controle está visível à esquerda, no qual podemos configurar o sistema e exibir as estatísticas necessárias. Por exemplo, o botão Analisador permite exibir estatísticas de qualquer parâmetro que coletamos, em particular o tempo de ida e volta por um período de uma hora para um determinado pedaço de ferro.

O botão Inventário exibe os dados de inventário dos objetos de monitoramento, vizinhos, a tabela MAC para cada dispositivo que está no sistema. Incrivelmente conveniente: o processo de encontrar qualquer parâmetro de equipamento na rede por números de série, tipos de equipamento, versões do sistema operacional etc. é facilitado.

Quando, em algum lugar distante da taiga, os funcionários locais, por exemplo, instalaram um novo switch e não contaram a ninguém sobre ele, ele imediatamente se tornou visível no sistema. Este equipamento cai em uma ramificação especial na árvore de dispositivos "Novos dispositivos" e automaticamente no CMDB.

Os objetos de monitoramento são pesquisados não apenas para modelos e modelos seriais, mas também para carregar memória, interfaces etc. Há suporte para muitos fornecedores - em particular servidores, armazenamento, equipamentos de telecomunicações, máquinas de usuário final. Se algo estiver faltando, o cliente nos escreverá diretamente ou o fornecedor e novos pedaços de ferro serão adicionados. Tudo é simples.

O sistema integra-se aos servidores MS Active Directory e RADIUS para autorização geral e aplicação de políticas de grupo. É assim que a arquitetura do sistema se parece:
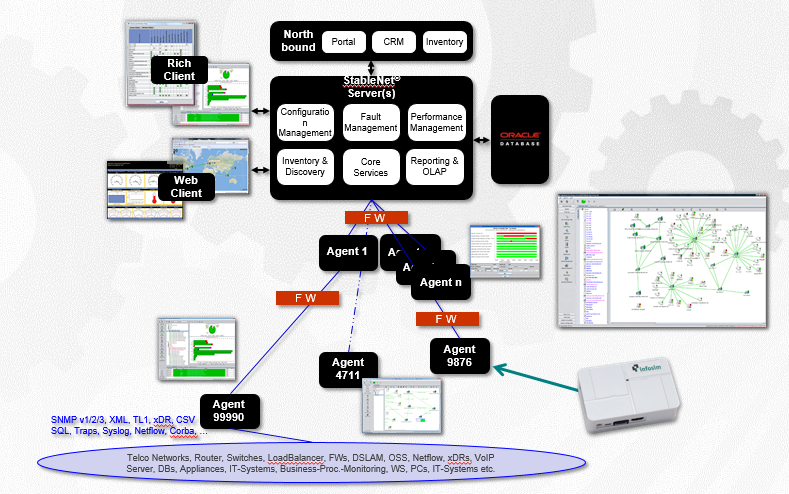
O servidor central é responsável por processar e exibir estatísticas coletadas do hardware.
O segundo componente importante é o agente responsável por interrogar os equipamentos e verificar a disponibilidade de ferro. Pode haver vários agentes (software remoto), temos um tópico de distribuição geográfica, com um agente para cada site. Isso é necessário para não direcionar o tráfego bruto de telemetria para a organização pai - o cliente possui um grande número de sites conectados por canais de satélite caros, para que apenas o resultado da medição seja enviado. E um banco de dados para armazenar tudo o que é coletado.
Se o site remoto não estiver disponível, os funcionários no local poderão se conectar diretamente ao agente e ver o status de seu "arbusto" da rede, mesmo sem acesso ao servidor central.
Um agente pode ser um servidor x64 / x86 executando o RedHat, CentOS, Ubuntu, Windows Server (para grandes plataformas) ou um micro-agente baseado em pequenos computadores ARM como o Raspberry PI (para pequenas plataformas). Não carregamos o canal com pings de ferro, o agente o faz e ele já agrega pacotes com estatísticas.

Também podemos remover atraso, instabilidade, variações de instabilidade nos equipamentos Cisco (IP SLA) e Huawei (NQA). Portanto, se no futuro o cliente adicionar outro ferro, a empresa não terá problemas - também podemos ajudar a medir indicadores de qualidade de canal, realizar testes sintéticos e carregar canais de comunicação de teste entre agentes.
O sistema de monitoramento pode receber mensagens syslog, capturar SNMP do ferro, filtrá-las e gerar mensagens de alarme. Ele cria automaticamente a topologia nos níveis L2 e L3 e, com base nisso, as dependências de situações de emergência (análise de causa raiz) são configuradas automaticamente. Isso é muito legal, pois permite que os administradores sejam informados da causa raiz do acidente, reduzindo assim o tempo necessário para resolvê-lo. Por exemplo, se em uma cadeia de cinco comutadores um no meio cair, receberemos uma mensagem de que o terceiro comutador (causa raiz) caiu e o quarto e o quinto estão inacessíveis por causa disso.

A solução funciona imediatamente, mas o processo pode ser personalizado. Assim, por exemplo, para facilitar o trabalho de nosso suporte técnico, "adicionamos" o status da fonte de alimentação ininterrupta e o status da energia: se a energia do site estiver desligada, em vez de 30 alarmes, obtemos um por energia. A correlação ocorre de acordo com a topologia, usuários e regras.
Há uma configuração de grupo de equipamentos, você não pode apenas pesquisar passivamente o hardware, mas implementar configurações como configurações nos comutadores. Registrar vlan ou ntp em 40 switches? Fácil!
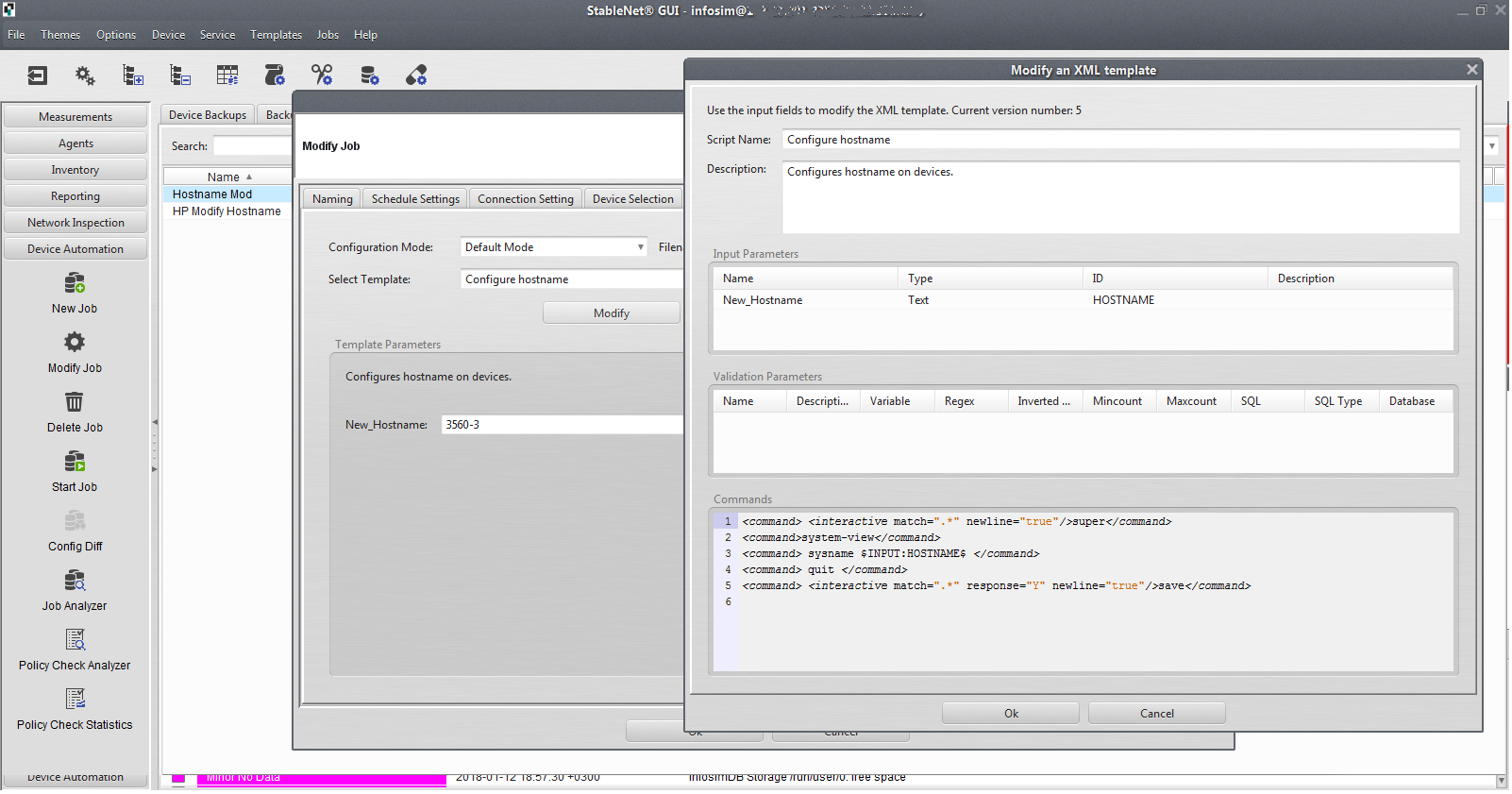
Também é muito legal que o sistema permita que o cliente faça backup da configuração do equipamento em uma programação: colete as configurações uma vez por dia ou durante um evento (por exemplo, uma mensagem sobre uma alteração na configuração é recebida - você pode definir uma tarefa que funcionará no momento em que o evento ocorrer e coletará a configuração alterada). O mesmo vale para as rampas, para eventos de emergência. Isso ajudará bastante com o "interrogatório" e a busca dos principais culpados pelas alterações na configuração. Além disso, de fato, é criado um banco de dados atualizado de todas as configurações de dispositivos na rede.
Existe uma API para integração. Em nosso projeto, foi feita a monitoração da integração com o CMDB 1C: Gerenciamento de tecnologia da informação corporativa da ITIL para armazenar todas as informações sobre equipamentos (ativos tangíveis). As informações da pesquisa são comparadas com o que está nos ativos, quando ele detecta equipamentos não contabilizados, o sistema diz: "Aqui está uma chave incompreensível". Descubra o que é, eles obstruem todos os campos necessários - o local da instalação, o nome etc. O número de série, o nome, o número da peça e a versão do firmware são obtidos no hardware. Em seguida, a tarefa é enviada para monitoramento - o nome da peça de ferro no sistema é alterado, é definido na posição correta na árvore de locais, as configurações de monitoramento são aplicadas dependendo do tipo de peça de ferro (por exemplo, o equipamento de limite deve ser interrogado com mais frequência do que o resto), o nome do host no próprio dispositivo muda e assim por diante d.
Processo de campo
Antes de tudo, configuramos a integração com o AD. Isso facilitou a vida para nós durante a implementação e também nas operações subseqüentes. Não há necessidade de criar e excluir contas para usuários o tempo todo. O sistema receberá automaticamente todas as contas ativas do AD. Se, de repente, alguém sair, o próprio sistema desativa essa conta em casa e ninguém mais pode entrar nela.
Para administradores e gerência intermediária, uma tarefa muito urgente era obter muitos relatórios. Durante o lançamento, foram configurados relatórios de utilização e acessibilidade dos canais, disponibilidade de bucins nos locais, principais situações de emergência, relatórios sobre tipos específicos de acidentes, versões de SO, relatórios de alterações na configuração do equipamento e outros.
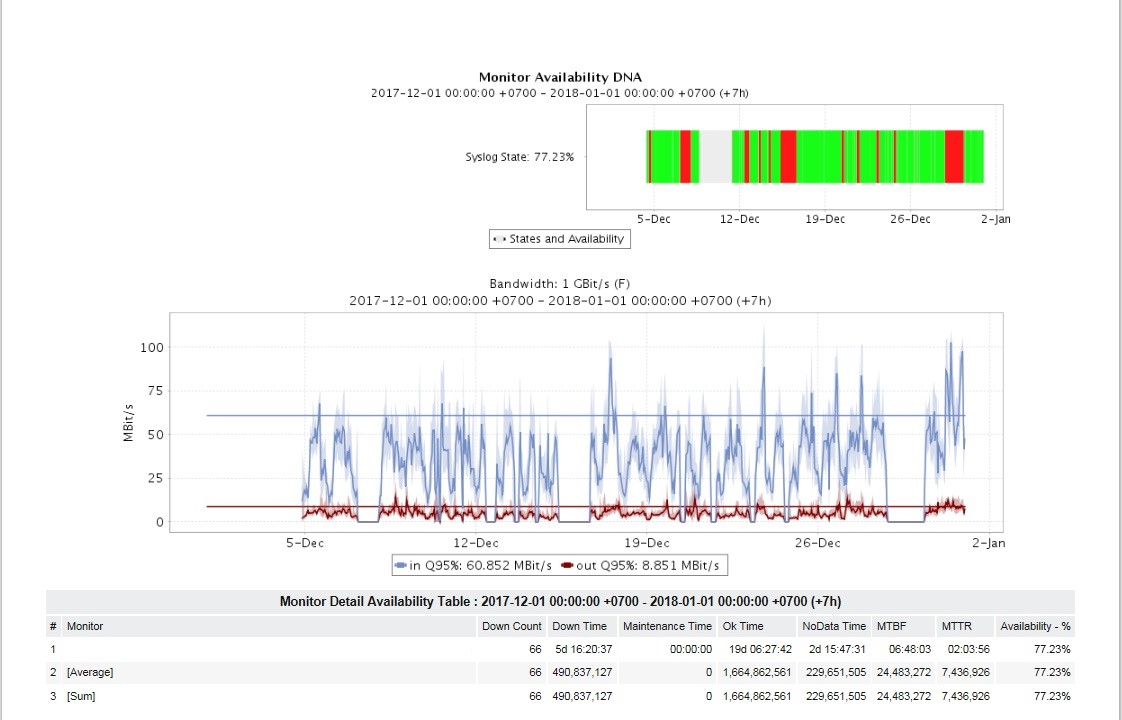
Os relatórios podem ser vistos no formato HTML, recebidos por correio nos formatos PDF e XLSX com a frequência desejada (uma vez por dia, semana, mês etc.). Para relatórios diferentes, foi configurada sua própria frequência e segmentação pessoal do consumidor do relatório.
O sistema também tem a flexibilidade de notificar e executar ações personalizadas em caso de emergência, pode enviar mensagens de email, mensagens SMS (usando um gateway SMS externo), além de escrever seus próprios scripts que serão lançados. Por exemplo, criamos um bot Telegram em nosso serviço de monitoramento em nuvem, que notifica funcionários responsáveis em nosso serviço operacional sobre situações de emergência. Também pode ser interrogado para vários parâmetros: “CPU, 10.1.1.100” retorna “95%”, mas, com o suporte de um aplicativo móvel, isso pode parecer um pouco redundante, embora conveniente.
Em seguida, escrevemos um script para integração com a central telefônica. Agora, quando surge uma situação megacrítica (falha de energia em locais críticos ou data centers), o sistema chama pessoas responsáveis em telefones celulares e com uma voz como a Siri diz: "A tensão nesse objeto está abaixo de um nível crítico". Isso é feito de maneira simples: o acidente é duplicado em uma pasta específica da central telefônica, onde é processado pelo serviço de telefonia - você só precisa especificar antecipadamente os números para os quais ligar automaticamente. De fato, automatizamos o processo de notificar os administradores ou a gerência responsável em caso de acidente. Em outras palavras, eles substituíram a pessoa que deveria ligar e relatar o acidente.
Função de pesquisa muito conveniente para usuários e glândulas. O usuário liga, diz: "Minha rede não funciona". Por seu endereço IP, você pode ver imediatamente onde está conectado (qual switch, qual porta, qual papoula) e onde está conectado antes:

Você pode criar diferentes tipos de topologias gráficas que facilitam a vida dos engenheiros. Você precisa, por exemplo, ver onde temos algum tipo de opção. É simples: eles o encontraram no ramo certo (ou usaram a pesquisa) e abriram seus vizinhos. Vários níveis de vizinhança são suportados (o primeiro são vizinhos imediatos, o segundo são vizinhos de vizinhos etc.). E você pode ver imediatamente onde nosso switch está localizado na topologia, quais portas e onde está conectado, quais endereços de papoula estão nas portas. Ou veja o mapa de protocolo OSPF, BGP, EIGRP, STP, PIM, MPLS - o sistema processará e desenhará tudo isso sozinho.

Ou veja visualmente como a rede "se sente" em um dos sites. Por conveniência, dividimos as partes dos sites WAN e LAN e as desenhamos com cartões separados. Todos os indicadores e links são interativos. Quando você passa o mouse sobre eles, pode ver o status atual e cair em qualquer dispositivo específico. Gostaria também de chamar a atenção para o fato de que o esquema do Microsoft Visio, elaborado pelo próprio engenheiro, é usado como substrato para esse relatório. Ele viu esse esquema muitas vezes como uma imagem estática no papel ou na tela. Agora "ganha vida" e fornece feedback em tempo real. Muito confortável

De acordo com os requisitos do cliente, os direitos de acesso do usuário foram delimitados. Existem muitas funções, mas elas são configuradas com flexibilidade. Dada a diferença de fuso horário entre os objetos, o recurso do horário de trabalho nas funções era muito útil: a que horas, para quais acidentes, a quem SMS e assim por diante.
O InfoSim StableNet coleta estatísticas de incidentes. Segundo a nossa experiência, nesses casos, existem problemas com o trabalho planejado - eles estragam os relatórios e causam preocupações desnecessárias. Pode-se notar aqui que aqui e ali haverá trabalho: os alarmes entrarão no modo silencioso e o relatório indicará em uma cor diferente que esse tempo de inatividade é um plano. Sim, as atividades planejadas não são anunciadas retroativamente.

Se não houver oportunidades suficientes prontas, você poderá criar modelos auto-escritos. Por exemplo, havia pontos de acesso da Motorola no projeto. Não havia modelos prontos para eles. Usando o “assistente” interno, criamos modelos e monitoramos os parâmetros que o cliente queria ver (nível do sinal, relação sinal / ruído).
Houve outro caso em que o sistema "não entendeu" um fabricante russo e mostrou o código do fabricante em vez de um nome. Nesse caso, o sistema possui uma funcionalidade que permite adicionar novos fornecedores e modelos de hardware em questão de segundos.
Aqui está a lista de recursos que o sistema de monitoramento atualmente permite ao cliente executar:
- Monitore a disponibilidade usando pings do ICMP.
- Colete informações usando o SNMP.
- Digitalize sub-redes em busca de novo hardware.
- Envie relatórios por período.
- Implemente configurações de backup.
- Analise a disponibilidade.
- “Toque o alarme” sobre a indisponibilidade de equipamentos ou a saída de indicadores fora da faixa normal.
- Cria traps SNMP como gatilhos, dados de syslog e qualquer entrada.
- Integre-se ao AD.
- Detecte automaticamente a conectividade do dispositivo (vizinhança CDP, LLDP, L3) e, com base nisso, desenhe automaticamente um mapa de rede.
- Crie "mapas climáticos" para visualizar o status da rede com a capacidade de usar substratos gráficos.
- Crie telas de trabalho (painéis) para exibir informações operacionais sobre o status da rede e dos dispositivos.
- Realizar um inventário de equipamentos (tipo de equipamento, fabricante, modelo, versão do software, quando chegar a data de EoS / EoL, etc.)
- Existe uma API REST para integração profunda com o CMDB 1C e outros sistemas externos.
- Execute a configuração de grupo do equipamento no sistema de monitoramento.
- Verifique a configuração do dispositivo para obter políticas da empresa
Referências
-
Bicicletas de apoio de primeira linha.-
Canais de comunicação para depósitos minerais.- Meu e-mail: DDrozhzhin@croc.ru