Na Internet moderna, mais de 630 milhões de sites, mas apenas 6% deles contêm conteúdo em russo. A barreira do idioma é o principal problema de disseminação do conhecimento entre os usuários da rede, e acreditamos que ela deve ser resolvida não apenas pelo ensino de idiomas estrangeiros, mas também pelo uso de tradução automática no navegador.
Hoje, contaremos aos leitores da Habr sobre duas importantes mudanças tecnológicas no tradutor Yandex.Browser. Primeiro, a tradução de palavras e frases selecionadas agora utiliza um modelo híbrido, e lembramos como essa abordagem difere do uso de redes exclusivamente neurais. Em segundo lugar, a rede neural do tradutor agora leva em conta a estrutura das páginas da Web, cujos recursos também discutiremos em detalhes.
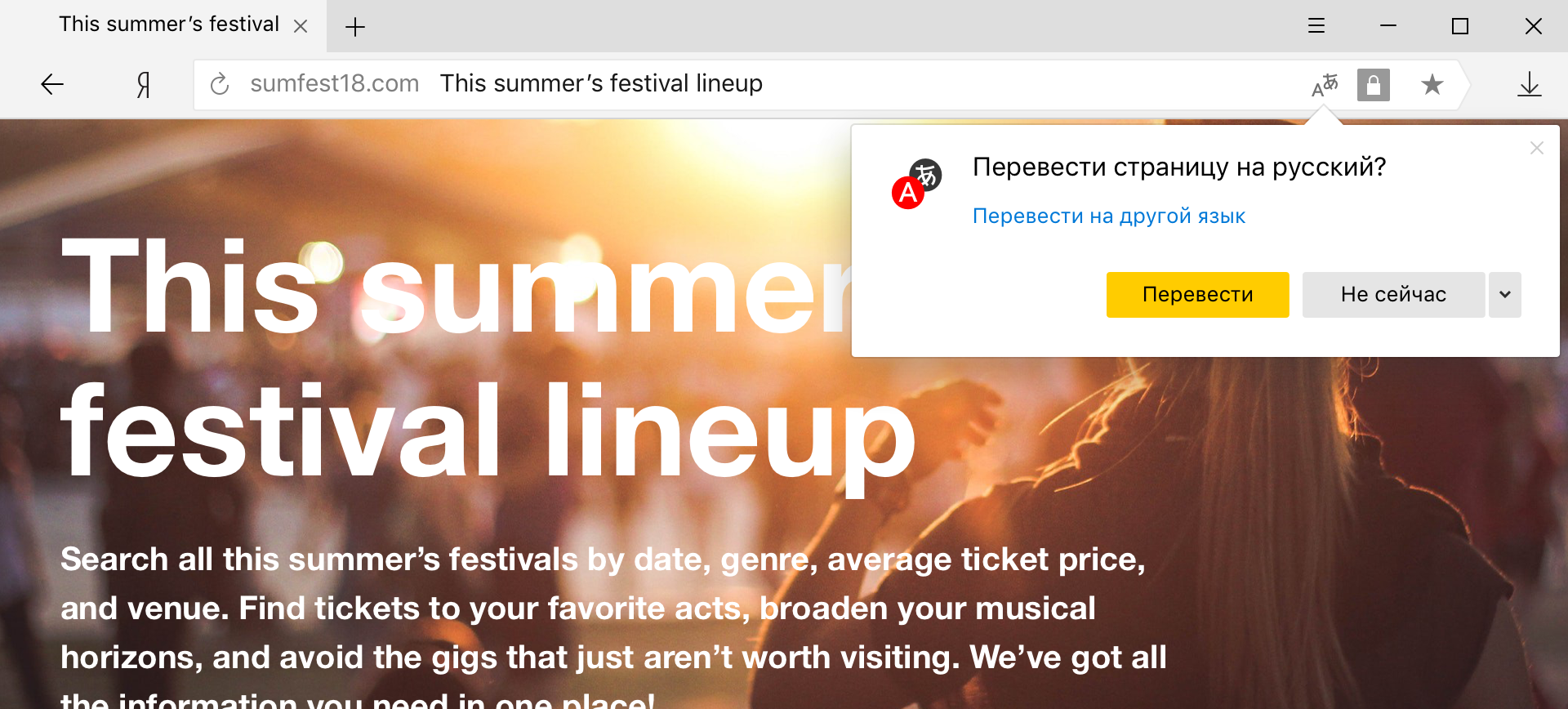
Tradutor de palavras e frases híbrido
Os primeiros sistemas de tradução automática foram baseados em
dicionários e regras (na verdade, regulares escritos à mão), que determinavam a qualidade da tradução. Linguistas profissionais trabalham há anos para criar regras manuais cada vez mais detalhadas. Esse trabalho consumia tanto tempo que prestou muita atenção apenas aos pares de idiomas mais populares, mas mesmo dentro da estrutura deles as máquinas lidaram mal. A linguagem viva é um sistema muito complexo que obedece mal às regras. É ainda mais difícil descrever as regras de correspondência dos dois idiomas.
A única maneira pela qual a máquina pode se adaptar constantemente às mudanças de condições é aprender independentemente em um grande número de textos paralelos (idênticos em significado, mas escritos em diferentes idiomas). Esta é a abordagem estatística para tradução automática. O computador compara textos paralelos e revela padrões de forma independente.
Um
tradutor estatístico tem vantagens e desvantagens. Por um lado, ele se lembra bem de palavras e frases raras e complexas. Se eles foram encontrados em textos paralelos, o tradutor se lembrará deles e continuará a traduzir corretamente. Por outro lado, o resultado da tradução pode ser semelhante ao quebra-cabeça montado: a imagem geral parece compreensível, mas se você olhar de perto, poderá ver que ela é composta de peças separadas. O motivo é que o tradutor apresenta palavras individuais na forma de identificadores, que de modo algum refletem a relação entre eles. Isso não corresponde à maneira como as pessoas percebem a linguagem quando as palavras são determinadas pela forma como são usadas, como se relacionam com outras palavras e como diferem delas.
As redes neurais ajudam a resolver esse problema. A representação vetorial das palavras (incorporação de palavras) usada na tradução automática neural, por regra, combina cada palavra com um vetor de várias centenas de números. Os vetores, em contraste com os identificadores simples de uma abordagem estatística, são formados durante o treinamento de uma rede neural e levam em consideração a relação entre as palavras. Por exemplo, um modelo pode reconhecer que, como “chá” e “café” costumam aparecer em contextos semelhantes, essas duas palavras devem ser possíveis no contexto da nova palavra “derramamento”, que, digamos, apenas uma delas foi encontrada nos dados de treinamento.
No entanto, o processo de ensino de representações vetoriais é claramente mais exigente estatisticamente do que exemplos de memorização mecânica. Além disso, não está claro o que fazer com essas raras palavras de entrada que muitas vezes não eram atendidas o suficiente para a rede criar uma representação vetorial aceitável para elas. Nessa situação, é lógico combinar os dois métodos.
Desde o ano passado, o Yandex.Translator usa um
modelo híbrido . Quando o tradutor recebe o texto do usuário, ele o entrega aos dois sistemas - a rede neural e o tradutor estatístico. Em seguida, um algoritmo baseado no método de treinamento
CatBoost avalia qual tradução é melhor. Na pontuação, dezenas de fatores são levados em consideração - desde o tamanho da frase (frases curtas são melhor traduzidas pelo modelo estatístico) até a sintaxe. A tradução reconhecida como a melhor é mostrada ao usuário.
É o modelo híbrido que agora é usado no Yandex.Browser, quando o usuário seleciona palavras e frases específicas na página para tradução.
Este modo é especialmente conveniente para quem geralmente fala um idioma estrangeiro e gostaria de traduzir apenas palavras desconhecidas. Mas se, por exemplo, em vez do inglês comum, você se deparar com chinês, será difícil fazer isso sem um tradutor de páginas. Parece que a diferença está apenas no volume do texto traduzido, mas não é tão simples.
Tradutor de Rede Neural na Web
Desde a época do
experimento de Georgetown até quase hoje, todos os sistemas de tradução automática foram treinados para traduzir cada frase do texto original individualmente. Enquanto uma página da web não é apenas um conjunto de frases, mas um texto estruturado no qual existem elementos fundamentalmente diferentes. Considere os elementos básicos da maioria das páginas.
Cabeçalho . Geralmente, texto brilhante e grande é exibido imediatamente quando você acessa a página. O título geralmente contém a essência das notícias, por isso é importante traduzi-las corretamente. Mas isso é difícil de fazer, porque o texto no título é pequeno e sem entender o contexto, você pode cometer um erro. No caso do idioma inglês, é ainda mais complicado, porque os títulos no idioma inglês geralmente contêm frases com gramática não tradicional, infinitivos ou até mesmo verbos ausentes. Por exemplo, o
anúncio de Game of Thrones anunciado .
Navegação Palavras e frases que nos ajudam a navegar no site. Por exemplo,
Página inicial ,
Voltar e
Minha conta dificilmente serão traduzidas como "Página inicial", "Voltar" e "Minha conta", se estiverem localizadas no menu do site e não no texto da publicação.
O texto principal . Tudo é mais simples para ele: ele difere pouco dos textos e frases comuns que podemos encontrar nos livros. Mas mesmo aqui é importante garantir a consistência das traduções, ou seja, garantir que dentro da mesma página da web os mesmos termos e conceitos sejam traduzidos da mesma maneira.
Para tradução de alta qualidade de páginas da web, não basta usar uma rede neural ou um modelo híbrido - você também deve levar em consideração a estrutura das páginas. E para isso, precisamos lidar com muitas dificuldades tecnológicas.
Classificação de segmentos de texto . Para fazer isso, usamos novamente o CatBoost e fatores baseados no próprio texto e na marcação HTML dos documentos (tag, tamanho do texto, número de links por unidade de texto, ...). Os fatores são bastante heterogêneos; portanto, é o CatBoost (baseado no aumento de gradiente) que mostra os melhores resultados (a precisão da classificação está acima de 95%). Mas a classificação por segmento por si só não é suficiente.
Desequilíbrio nos dados . Tradicionalmente, os algoritmos Yandex.Translator aprendem sobre textos da Internet. Parece que esta é uma solução ideal para treinar um tradutor de páginas da Web (em outras palavras, a rede aprende com textos da mesma natureza que aqueles em que vamos usá-la). Mas assim que aprendemos a separar segmentos diferentes um do outro, descobrimos um recurso interessante. Em média, o conteúdo ocupa cerca de 85% de todo o texto nos sites, enquanto os títulos e a navegação representam apenas 7,5% cada. Lembre-se também de que os cabeçalhos e os elementos de navegação em estilo e gramática são visivelmente diferentes do restante do texto. Esses dois fatores juntos levam ao problema de distorção de dados. É mais lucrativo para uma rede neural simplesmente ignorar os recursos desses segmentos muito mal representados no conjunto de treinamento. A rede aprende a traduzir bem apenas o texto principal, por causa do qual a qualidade da tradução dos cabeçalhos e da navegação sofre. Para neutralizar esse efeito desagradável, fizemos duas coisas: para cada par de frases paralelas, atribuímos um dos três tipos de segmentos (conteúdo, título ou navegação) como meta-informação e aumentamos artificialmente a concentração dos dois últimos no prédio de treinamento para 33%, devido ao fato de que começou a mostrar exemplos semelhantes à rede neural de aprendizado com mais frequência.
Aprendizagem multitarefa . Como agora podemos separar textos em páginas da Web em três classes de segmentos, pode parecer uma idéia natural treinar três modelos separados, cada um deles lidando com a tradução de seu próprio tipo de texto - títulos, navegação ou conteúdo. Isso realmente funciona bem, mas o esquema funciona ainda melhor quando treinamos uma rede neural para traduzir todos os tipos de textos de uma só vez. A chave para o entendimento está na idéia do MTL (
Mutli-Task Learning ): se houver uma conexão interna entre várias tarefas de aprendizado de máquina, um modelo que aprende a resolver esses problemas ao mesmo tempo pode aprender a resolver cada um dos problemas melhor do que um modelo especializado de perfil restrito!
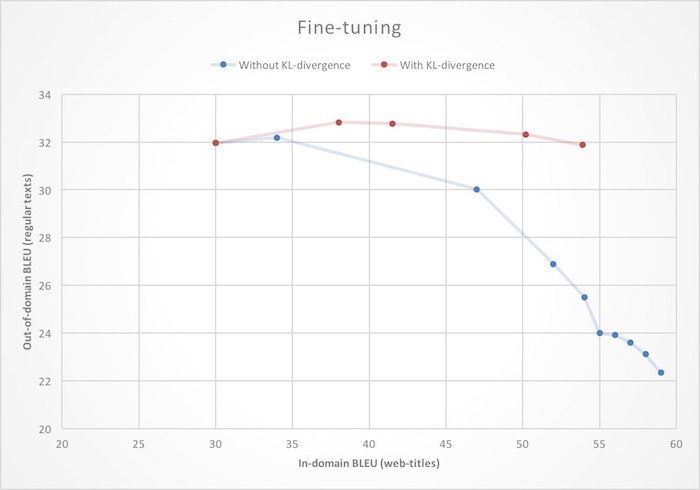
Ajuste fino . Já tínhamos uma tradução automática muito boa, portanto não seria razoável treinar um novo tradutor para o Yandex.Browser do zero. É mais lógico usar um sistema básico para traduzir textos comuns e treiná-lo novamente para trabalhar com páginas da web. No contexto de redes neurais, isso geralmente é chamado de ajuste fino. Mas se você abordar essa tarefa de frente, ou seja, apenas para inicializar os pesos da rede neural com os valores do modelo finalizado e começar a aprender sobre novos dados, você pode encontrar o efeito de uma mudança de domínio: à medida que aprender, a qualidade da tradução de páginas da Web (no domínio) aumentará, mas a qualidade da tradução de palavras comuns (fora do domínio) ) os textos cairão. Para se livrar desse recurso desagradável, durante a reciclagem, impomos uma restrição adicional à rede neural, proibindo-o de alterar muito os pesos em comparação com o estado inicial.
Matematicamente, isso é expresso adicionando o termo à função de perda, que
é a distância Kullback - Leibler (divergência de KL) entre as distribuições de probabilidade da próxima palavra gerada pela fonte e pelas redes recicladas. Como você pode ver na ilustração, isso leva ao fato de que o aumento na qualidade da tradução de páginas da web não leva mais à degradação da tradução do texto sem formatação.
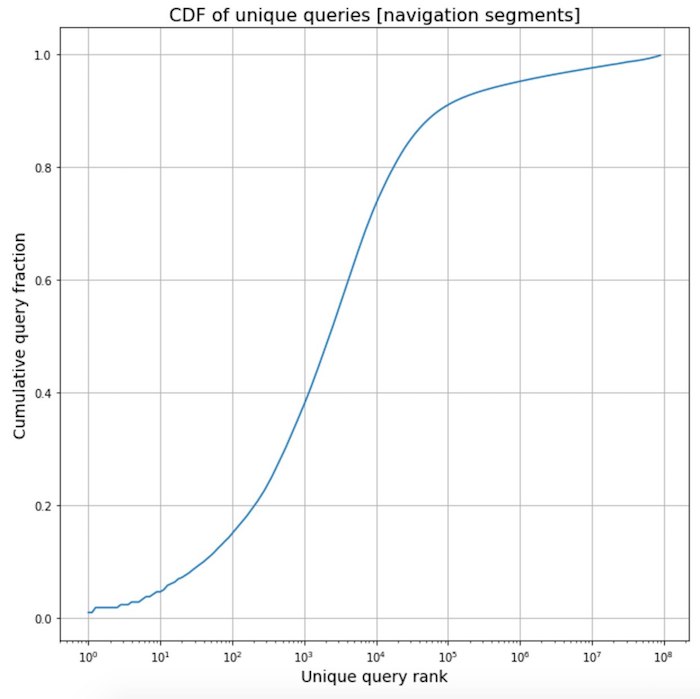
 Polir frases de frequência da navegação
Polir frases de frequência da navegação . No processo de trabalhar em um novo tradutor, coletamos estatísticas sobre os textos de vários segmentos de páginas da web e vimos uma interessante. Os textos relacionados aos elementos de navegação são bastante padronizados, com frequência são as mesmas frases de modelo. Esse é um efeito tão poderoso que mais da metade de todas as frases de navegação encontradas na Internet representam apenas 2 mil das mais frequentes.
Obviamente, aproveitamos isso e entregamos vários milhares de frases e suas traduções mais frequentes aos nossos tradutores para verificação, para ter certeza absoluta de sua qualidade.
Alinhamentos externos. Havia outro requisito importante para um tradutor de páginas da Web no navegador - ele não deve distorcer a marcação. Quando as tags HTML estão localizadas fora das frases ou em suas bordas, não há problemas. Mas se houver, por exemplo,
duas palavras sublinhadas dentro da frase, na tradução, queremos ver "duas palavras
sublinhadas ". I.e. como resultado da transferência, duas condições devem ser atendidas:
- O fragmento sublinhado na tradução deve corresponder ao fragmento sublinhado no texto de origem.
- A consistência da tradução nas bordas do fragmento sublinhado não deve ser violada.
Para garantir esse comportamento, primeiro traduzimos o texto como de costume e, usando modelos estatísticos de
alinhamento palavra por
palavra, determinamos a correspondência entre fragmentos dos textos originais e traduzidos. Isso ajuda a entender o que precisa ser enfatizado (destaque em itálico, formato como um hiperlink, ...).
Observador de interseção . Os poderosos modelos de tradução de redes neurais que treinamos exigem significativamente mais recursos de computação em nossos servidores (CPU e GPU) do que os modelos estatísticos das gerações anteriores. Ao mesmo tempo, os usuários nem sempre lêem as páginas até o fim, portanto, o envio de todo o texto das páginas da Web para a nuvem parece desnecessário. Para economizar recursos do servidor e tráfego do usuário, ensinamos o Translator a usar a
API Intersection Observer para enviar apenas o texto exibido na tela para tradução. Devido a isso, conseguimos reduzir o consumo de tráfego para tradução em mais de 3 vezes.
Algumas palavras sobre os resultados da introdução de um tradutor de rede neural, levando em consideração a estrutura das páginas da Web no Yandex.Browser. Para avaliar a qualidade das traduções, usamos a métrica BLEU *, que compara as traduções feitas por uma máquina e por um tradutor profissional, e avalia a qualidade da tradução automática em uma escala de 0 a 100%. Quanto mais próxima a tradução automática da tradução humana, maior a porcentagem. Normalmente, os usuários percebem uma alteração na qualidade quando a métrica BLEU aumenta em pelo menos 3%. O novo tradutor Yandex.Browser mostrou um aumento de quase 18%.

A tradução automática é uma das tarefas mais complexas, quentes e pesquisadas no campo das tecnologias de inteligência artificial. Isso se deve à sua atratividade puramente matemática e à sua relevância no mundo moderno, onde a cada segundo uma quantidade incrível de conteúdo é criada na Internet em vários idiomas. A tradução automática, que até recentemente causou principalmente risos (lembre-se dos
criadores de mouse ), hoje em dia ajuda os usuários a superar barreiras linguísticas.
A qualidade ideal ainda está longe, por isso continuaremos avançando na vanguarda da tecnologia nessa direção, para que os usuários do Yandex.Browser possam ir além, por exemplo, do Runet e encontrar conteúdo útil em qualquer lugar da Internet.