Atualmente, a visão de máquina é um assunto muito quente. Para resolver o problema de reconhecer tags de loja usando redes neurais, escolhemos a estrutura TensorFlow.
O artigo discutirá exatamente como usá-lo para localizar e identificar vários objetos no mesmo preço da loja, além de reconhecer seu conteúdo.
Uma tarefa semelhante de reconhecimento de preços da IKEA já foi resolvida no Habré usando as ferramentas clássicas de processamento de imagens disponíveis na biblioteca OpenCV.
Separadamente, gostaria de observar que a solução pode funcionar tanto na plataforma SAP HANA em conjunto com o Tensorflow Serving, quanto na plataforma em nuvem SAP.
A tarefa de reconhecer o preço dos produtos é relevante para os compradores que desejam "atrapalhar" os preços entre si e escolher uma loja para compras e para os varejistas - eles querem aprender sobre os preços dos concorrentes em tempo real.
Letra suficiente - vá para a técnica!
ToolkitPara a detecção e classificação de imagens, usamos redes neurais convolucionais implementadas na biblioteca TensorFlow e disponíveis para controle através da API de detecção de objetos.
A API de detecção de objetos do TensorFlow é um meta-quadro de código aberto baseado no TensorFlow que simplifica a criação, o treinamento e a implantação de modelos para a detecção de objetos.
Após a detecção do objeto desejado, o reconhecimento de texto foi realizado usando o Tesseract, uma biblioteca para reconhecimento de caracteres. Desde 2006, o Tesseract é considerado uma das bibliotecas de OCR mais precisas disponíveis em código aberto.
É possível que você faça uma pergunta - por que nem todo o processamento é feito no TF? A resposta é muito simples - exigiria muito mais tempo para implementação, mas não havia muito disso. Era mais fácil sacrificar a velocidade de processamento e montar um protótipo acabado do que se preocupar com um OCR caseiro.
Criação e preparação de um conjunto de dadosPara começar, era necessário coletar materiais para o trabalho. Visitamos 3 lojas e tiramos cerca de 400 fotos de diferentes preços em uma câmera de celular no modo automático
Fotos de exemplo: Fig. 1. Exemplo de uma imagem de etiqueta de preço
Fig. 1. Exemplo de uma imagem de etiqueta de preço Fig. 2. Exemplo de imagem de etiqueta de preço
Fig. 2. Exemplo de imagem de etiqueta de preçoDepois disso, você precisa processar e marcar todas as fotos dos preços. No processo de coleta de imagens, tentamos coletar imagens de alta qualidade (sem artefatos): preços de aproximadamente o mesmo formato, sem desfocagem, rotações significativas etc. Isso foi feito para facilitar a comparação do conteúdo do preço real e de sua imagem digital. No entanto, se treinarmos a rede neural apenas nas imagens de alta qualidade disponíveis, isso naturalmente levará ao fato de que a confiança do modelo na identificação de exemplos distorcidos cairá significativamente. Para treinar a rede neural a ser resistente a tais situações, utilizamos o procedimento conhecido para expandir o conjunto de treinamento com versões distorcidas de imagens (aumento). Para complementar a amostra de treinamento, aplicamos algoritmos da biblioteca Imgaug: turnos, pequenas curvas, desfoque gaussiano, ruído. Imagens distorcidas foram adicionadas à amostra, o que aumentou em cerca de 5 vezes (de 300 para 1.500 imagens).
Para marcar a imagem e selecionar objetos, foi utilizado o programa LabelImg, disponível em domínio público. Permite selecionar os objetos necessários na imagem com um retângulo e atribuir cada classe à caixa delimitadora. Todas as coordenadas e etiquetas dos quadros criados para cada foto são salvas em um arquivo XML separado.
Os seguintes objetos se destacaram em cada foto: preço do produto, preço do produto, nome do produto e código de barras do produto no preço. Em alguns exemplos de imagens, onde era justificado logicamente, as áreas foram marcadas com sobreposição.
 Fig. 3. Um exemplo de uma fotografia de um par de etiquetas de preço marcadas em LabelImg. Áreas com descrição do produto, preço e código de barras são destacadas.
Fig. 3. Um exemplo de uma fotografia de um par de etiquetas de preço marcadas em LabelImg. Áreas com descrição do produto, preço e código de barras são destacadas. Fig. 4. Um exemplo de uma fotografia de um preço marcado em LabelImg. Áreas com descrição do produto, preço e código de barras são destacadas.
Fig. 4. Um exemplo de uma fotografia de um preço marcado em LabelImg. Áreas com descrição do produto, preço e código de barras são destacadas.Depois que todas as fotos forem processadas e marcadas, preparamos o conjunto de dados com a separação de todas as fotos e os arquivos de tags em uma amostra de treinamento e teste. Geralmente, leve 80% da amostra de treinamento para 20% da amostra de teste e misture aleatoriamente.
Em seguida, na máquina onde o modelo será treinado, é necessário instalar todas as bibliotecas necessárias. Primeiro, instalamos a biblioteca de aprendizado de máquina TensorFlow. Dependendo do tipo do seu sistema e você precisa instalar uma biblioteca adicional para computação na GPU. Em seguida, instale a biblioteca da API de detecção de objetos do Tensorflow e bibliotecas adicionais para trabalhar com imagens e gráficos. Abaixo está uma lista de bibliotecas que usamos em nosso trabalho:
GPU TensorFlow v1.5, CUDA v9.0, cuDNN v7.0
Protobuf 3+, Python-tk, Pillow 1.0, lxml, tf Slim, notebook Jupyter, Matplotlib
Fluxo de tensor, Cython, Cocoapi; Opencv-python; PandasQuando todas as etapas da instalação estiverem concluídas, você poderá prosseguir com a preparação dos dados e a configuração dos parâmetros de aprendizado.
Modelo de treinamentoPara resolver nosso problema, usamos duas versões da rede neural pré-treinada MobileNet V2 e Faster-RCNN V2 no conjunto de dados coco como extratores de propriedades de imagem. Os modelos foram treinados em 4 novas classes: preço, descrição do produto, preço e código de barras. Como principal, escolhemos o MobileNet V2, que é um modelo relativamente simples que nos permite oferecer qualidade aceitável a uma velocidade agradável. O MobileNet V2 permite implementar o reconhecimento de imagens mesmo em um dispositivo móvel.
Primeiro, você precisa informar à biblioteca da API de detecção de objeto do Tensorflow o número de rótulos e os nomes desses rótulos.
A última coisa a fazer antes do treinamento é criar um mapa de atalho e editar o arquivo de configuração. O mapa de etiquetas informa o modelo e mapeia os nomes das classes para os números de identificação de classe para cada objeto.

Por fim, você precisa configurar as fontes de aprendizado para a Detecção de Objetos para determinar qual modelo e quais parâmetros serão usados no treinamento. Este é o último passo antes de iniciar o treinamento.

O procedimento de treinamento é iniciado pelo comando:
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/mobilenet.config
Se tudo estiver configurado corretamente, o TensorFlow inicializará a reciclagem da rede neural. A inicialização pode levar até 30 segundos antes do início do treinamento. À medida que a rede neural é treinada novamente a cada etapa, o valor da função de erro do algoritmo (perda) será exibido. Para o MobileNet V2, o valor inicial da função de perda é de aproximadamente 20. O modelo deve ser treinado até que a função de perda diminua para um valor de aproximadamente 2. Para visualizar o processo de aprendizado da rede neural, você pode usar o conveniente utilitário TensorBoard.
: tensorboard
O comando inicializa a interface da web na máquina local, que estará disponível no localhost: 6006. Após a parada, o procedimento de treinamento pode ser retomado posteriormente, usando pontos de verificação salvos a cada 5 minutos.
Reconhecimento de etiquetas de preço e seus elementosQuando o treinamento é concluído, o último passo é criar um gráfico de rede neural. Isso é feito pelo comando do console, onde, sob asteriscos, você deve especificar o maior número de arquivos cpkt existentes no diretório de treinamento.
python export_inference_graph.py --input_type image_tensor --pipeline_config_path training/faster_rcnn_inception_v2.config --trained_checkpoint_prefix training/model.ckpt-**** --output_directory inference_graph
Após este procedimento, o classificador de detecção de objetos está pronto para operação. Para verificar o reconhecimento de imagem, basta executar um script que acompanha a biblioteca Tensorflow Object Detection, indicando o modelo que foi treinado anteriormente e fotos para reconhecimento. Um exemplo padrão de script Python é fornecido
aqui .
Em nosso exemplo, leva cerca de 1,5 segundos para reconhecer uma foto usando o modelo ssd mobilenet em um laptop simples.
 Fig. 5. O resultado do reconhecimento de imagens com etiquetas de preço na amostra de teste
Fig. 5. O resultado do reconhecimento de imagens com etiquetas de preço na amostra de teste Fig. 6. O resultado do reconhecimento de imagens com etiquetas de preço na amostra de teste
Fig. 6. O resultado do reconhecimento de imagens com etiquetas de preço na amostra de testeQuando estamos convencidos de que os preços são detectados normalmente, é necessário ensinar o modelo a ler informações de elementos individuais: o preço dos produtos, o nome dos produtos e um código de barras. Para isso, existem bibliotecas disponíveis no Python para reconhecer caracteres e códigos de barras nas fotografias - Pyzbar e Tesseract.
Antes de começar a reconhecer caracteres e códigos de barras em uma foto, é necessário recortá-la nos elementos de que precisamos - para aumentar a velocidade e não reconhecer informações desnecessárias que não estão incluídas no preço. Também é necessário "retirar" as coordenadas dos objetos que o modelo reconheceu junto com suas classes.

Em seguida, usamos essas coordenadas para cortar nossa foto em partes para reconhecer apenas a área necessária.


 Fig. 7. Um exemplo de partes destacadas do preço
Fig. 7. Um exemplo de partes destacadas do preçoEm seguida, transferimos todas as áreas de recorte para as bibliotecas: o nome e o preço do produto são transferidos para o tesseract e o código de barras para o pyzbar, e obtemos o resultado do reconhecimento.

 Fig. 8. Um exemplo de conteúdo reconhecido é a área do preço.
Fig. 8. Um exemplo de conteúdo reconhecido é a área do preço.Nesse momento, o reconhecimento de texto e código de barras pode causar problemas se a imagem original estiver em baixa resolução ou embaçada. Se o preço puder ser reconhecido normalmente devido aos grandes números na etiqueta de preço, o nome e o código de barras do produto serão mal definidos ou nem um pouco definidos. Para fazer isso, é recomendável não usar fotos pequenas para reconhecimento e também enviar imagens sem ruído e distorção forte - por exemplo, sem a falta de foco adequado.
Exemplo de reconhecimento de imagem incorreta:



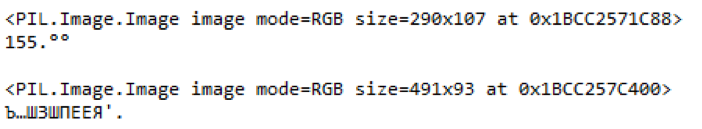 Fig. 9. Um exemplo de partes destacadas de um preço borrado e conteúdo reconhecido
Fig. 9. Um exemplo de partes destacadas de um preço borrado e conteúdo reconhecidoNeste exemplo, você pode ver que, se o preço dos produtos foi reconhecido mais ou menos corretamente na imagem de baixa qualidade, a biblioteca não conseguiu lidar com o nome dos produtos. E o código de barras não está sujeito a reconhecimento.
O mesmo texto em boa qualidade.

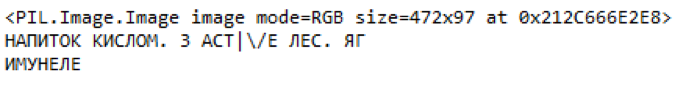 Fig. 10. Exemplo de partes destacadas do preço e conteúdo reconhecidoConclusões
Fig. 10. Exemplo de partes destacadas do preço e conteúdo reconhecidoConclusõesNo final, conseguimos obter um modelo de qualidade aceitável com uma baixa porcentagem de erros e uma alta porcentagem de detecção de objetos relevantes. O RC2N mais rápido V2 tem melhor qualidade de reconhecimento que o MobileNet SSD V2, mas tem uma ordem de magnitude inferior à velocidade, o que é uma limitação significativa.
A precisão obtida do reconhecimento de preço em uma amostra atrasada de 50 imagens é de 100%, ou seja, todos os preços foram identificados com sucesso em todas as fotos. A precisão do reconhecimento de áreas com código de barras e preço foi de 90%. A precisão do reconhecimento da área de texto é de 85%. A precisão da leitura dos preços foi de cerca de 95%, e o texto - 80-85%. Além disso, como um experimento, apresentamos o resultado do reconhecimento de preço, que é completamente diferente dos preços na amostra de treinamento.
 Fig. 11. Um exemplo de reconhecimento de preços atípicos que não estão no conjunto de treinamento.
Fig. 11. Um exemplo de reconhecimento de preços atípicos que não estão no conjunto de treinamento.Como você pode ver, mesmo com preços significativamente diferentes dos preços de treinamento, os modelos não apresentam erros, mas objetos significativos podem ser reconhecidos no preço.
O que mais poderia ser feito?1) Um artigo interessante sobre o aumento automático foi lançado recentemente, cuja abordagem pode ser usada
2) O modelo treinado acabado pode e deve ser substancialmente comprimido
3) Exemplos de publicação de serviços concluídos no SCP e TFS
Na preparação do protótipo e deste artigo, foram utilizados os seguintes materiais:1.
Trazendo o Machine Learning (TensorFlow) para a empresa com o SAP HANA2.
SAP Leonardo ML Foundation - Traga seu próprio modelo (BYOM)3.
Repositório GitHub de Detecção de Objeto TensorFlow4.
Artigo IKEA Cheque Reconhecimento5.
Artigo sobre os benefícios da MobileNet6.
Artigo de Detecção de Objeto TensorFlowO artigo foi preparado por:
Sergey Abdurakipov, Dmitry Buslov, Alexey Khristenko