Percebi por mim mesmo que escrevo constantemente todo tipo de pequenas coisas, informações úteis, apenas algo da área de transferência diretamente em um editor de texto. Sempre existe em algum lugar no fundo um Texto Sublime aberto com várias guias penduradas.
E também notei que é mais conveniente estruturar as informações em um arquivo usando a sintaxe Markdown - é mais agradável que o texto de origem e não o resultado exibido no mesmo github.
Com o tempo, notei que havia muitos arquivos salvos e as guias abertas não diminuíram. Mas um movimento descuidado e todas as informações acumuladas não salvas afundam no esquecimento, e você também não procura em outros dispositivos, e espalhar os pais também não é muito conveniente.
Tudo isso me levou a escrever algo como meu próprio mecanismo para armazenar todas as informações em um só lugar e de uma forma conveniente. Sim, sim, existe um monte de todos os tipos de Evernote, algumas notas incorporadas no MacOS / iOS e assim por diante que ambas têm sincronização e recursos são úteis - mas, como dizem, você deseja fazer algo de bom (por si mesmo), faça-o eu mesmo. E, como quase qualquer programador, em qualquer situação incompreensível eu pego e escrevo tudo sozinho. Então aconteceu desta vez.
Porque
Projetos semelhantes já existem e os serviços de monstro mencionados também são bastante convenientes, mas alguns de seus recursos no meu projeto oferecem algumas vantagens.
Primeiro, é mais conveniente usá-lo como documentação para o projeto (de fato, a inspiração veio do site com documentação no Kotlin, de onde eu emprestei a maioria dos estilos para o conteúdo gerado).
O projeto é totalmente gratuito e é de domínio público, um link para o github no final do artigo.
O que pode?
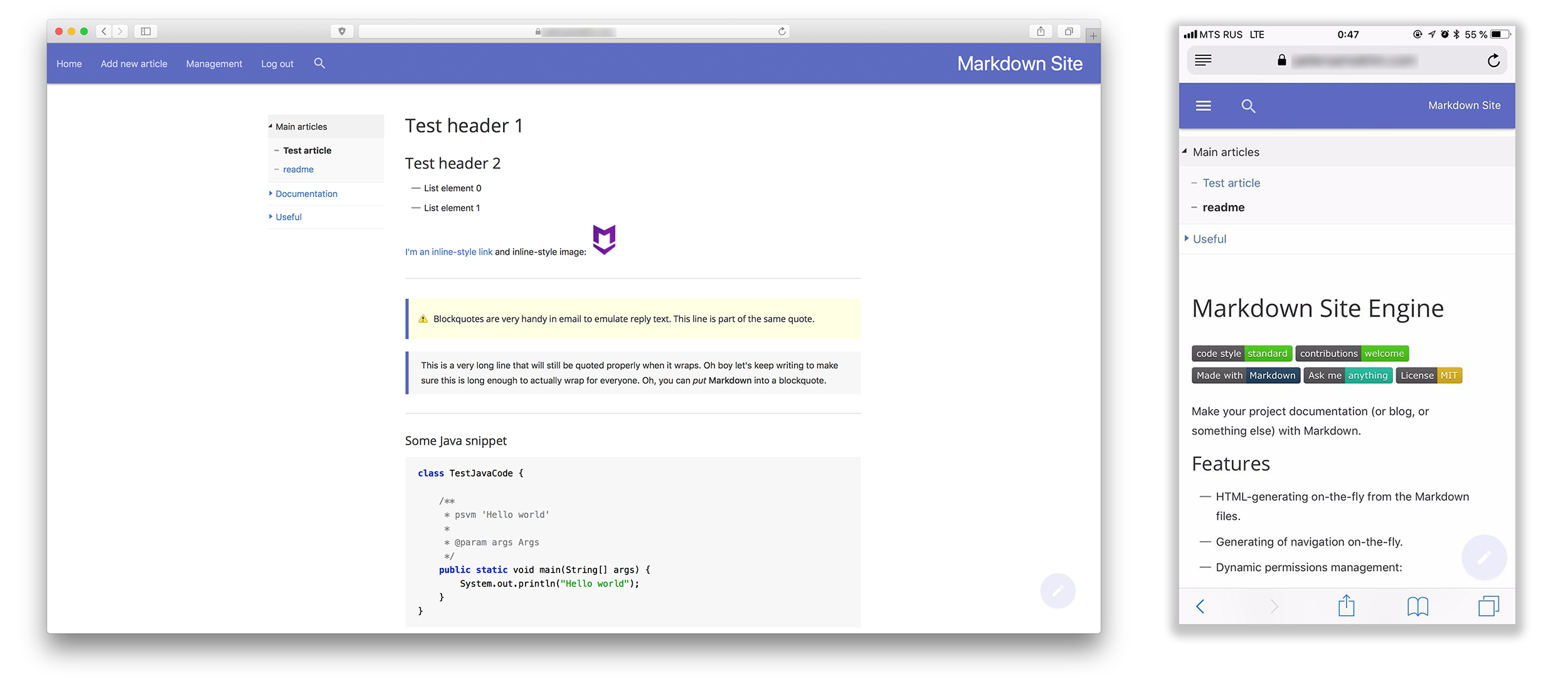
- Geração de HTML em tempo real - o resultado não é salvo. Os artigos prontos podem ser copiados em pastas inteiras para o diretório do projeto desejado. Todos os arquivos adicionados e excluídos são indexados automaticamente.
- A navegação também é gerada, não codificada.
- Pesquise por conteúdo.
- Controle de acesso - funciona aproximadamente como "grupos" para organizações no github: cada grupo (eu chamei de função ) tem uma lista de usuários e uma lista de caminhos para pastas / arquivos que os usuários deste grupo podem assistir.
- Ao pesquisar, na navegação, etc. o usuário não verá as páginas às quais ele não tem acesso.
- Os artigos também podem ser adicionados em um editor visual (possui destaque de sintaxe, botões como no github, visualização etc.)
- Tudo é facilmente configurado através da página de configurações, que também é gerada (e você pode adicionar novos itens sem dificuldade). Total - você pode instalar o projeto localmente em alguns comandos, soltar os arquivos Markdown finalizados no seu pai, configurar rapidamente o acesso e o uso.
- Vários outros chips pequenos, como links de ancoragem para todos os cabeçalhos, botões para copiar trechos com código etc. etc.
Como isso funciona?
Sobre o que?
Usei o NodeJS e express , pois para mim essa pilha parecia a que consumia menos tempo para implementar essa tarefa em particular.
Direitos de acesso
A lógica é bastante simples - o passport resolve todos os problemas com autorização. Direitos para usuários e artigos são armazenados no MongoDB e os caminhos para os artigos correspondem aos caminhos para os arquivos no disco.
Os "grupos" em si não são armazenados em nenhum lugar, o controle ocorre "de baixo": cada usuário e caminho (para o artigo ou categoria - ou seja, para o arquivo e a pasta) tem sua própria lista de "papéis". Se um usuário tiver pelo menos uma "função" na lista do caminho que ele segue, será considerado que ele tem acesso. Para visualizar qualquer caminho, o usuário deve ter acesso ao próprio caminho e a todos os pais: por exemplo, para ver a página /pages/Documentation/Habr , você deve ter acesso a /pages , /pages/Documentation e /pages/Documentation/Habr .
Se o usuário puder visualizar a página, passamos para o arquivo no disco, lemos seu conteúdo e o exibimos.
Artigos
Para a conversão, Ruby uma biblioteca para Ruby , chamada kramdown - todos os seus recursos também são suportados.
Após gerar o HTML, a marcação é incorporada no modelo preparado, onde a navegação gerada também é incorporada.
A geração de navegação funciona de maneira bastante simples - você obtém recursivamente uma lista completa de todos os arquivos e pastas, depois são filtrados pelos direitos do usuário e a estrutura resultante é "anexada" ao modelo.
A pesquisa funciona da mesma maneira.
Para o design, usei materialize , estilos do site de documentação do Kotlin para os artigos, tirei idéias do editor no github etc.
→ O código fonte está disponível aqui.
Eu não sou o NodeJS - ou um desenvolvedor de back-end, mas gosto de me distrair com algo interessante. Escrevi o artigo porque achava que a coisa parecia bastante útil.
Sim, existem análogos com a mesma ideia (para ser honesto, descobri após o desenvolvimento) - mas eles não têm muitos dos recursos descritos acima (e não descritos aqui), e a implementação parece mais complicada: o mesmo site de documentação que a Kotlin codifica em navegação, sabe como executar recursos adicionais o código e, ao que parece, tudo - embora o projeto em si seja bastante grande.
PS : Não pareci violar as regras de Habr, e o artigo não contém uma descrição geral, exceto um link para um github. Se, de repente, as pessoas demonstrarem interesse, eu posso escrever uma série de artigos com uma descrição detalhada de todo o processo de desenvolvimento ou pontos específicos - porque é improvável que possamos dar um jeito aqui.