 Foto: Alexander Korolkov / WG
Foto: Alexander Korolkov / WGEm 3 de junho, no último dia do Festival do Livro de Moscou na Praça Vermelha, o linguista
Alexander Pipersky falou sobre linguística de computador. Ele falou sobre traduções de máquinas, redes neurais, mapeamento vetorial de palavras e levantou questões sobre os limites da inteligência artificial.
Pessoas diferentes ouviram a palestra. À minha direita, por exemplo, um turista chinês bicou o nariz. Alexander, com certeza, também entendeu - alguns números extras, fórmulas e palavras sobre algoritmos, e as pessoas fugiam para a próxima tenda para ouvir escritores de ficção científica.
Pedi a Alexander que preparasse para Habr a "versão de diretoria" da palestra, onde nada foi cortado para acalmar turistas aleatórios. Afinal, a maior parte da apresentação carecia de uma audiência com perguntas sensatas e geralmente uma boa discussão. Eu acho que podemos desenvolvê-lo aqui.
Onde a IA começa?
Desde recentemente, nos comunicamos constantemente com computadores em voz, e todos os tipos de voz de Alice, Alexa e Siri nos respondem. Se você olhar de lado, parece que o computador nos entende, fornece listas de sites relevantes, informa o endereço do restaurante mais próximo, indica como chegar a ele.
Parece que estamos lidando com um dispositivo bastante inteligente. Você pode até dizer que este dispositivo tem o que é chamado de inteligência artificial (IA). Embora ninguém realmente entenda o que isso significa e para onde vão as fronteiras.
Quando nos dizem, "a IA desempenha funções criativas consideradas prerrogativas do homem" - o que isso significa? O que são recursos criativos? Qual função é criativa e qual não é? Escolher o restaurante chinês mais próximo é uma característica criativa? Agora parece que provavelmente não.
Estamos constantemente inclinados a negar inteligência artificial a um computador. Assim que nos acostumamos às manifestações intelectuais que um computador faz, dizemos: "isso não é IA, é um absurdo completo, tarefas de modelo, nada de interessante".
Um exemplo simples - do nosso ponto de vista, não há nada mais burro do que uma calculadora de bolso. É vendido em qualquer barraca por 50 rublos. Pegue a calculadora de oito bits usual, aperte os botões e obtenha o resultado em segundos. Bem, você pensa, ele pensa algumas coisas. Isso não é inteligência.
E imagine essa máquina no século XVIII. Pareceria um milagre, porque o cálculo era uma prerrogativa do homem.
O mesmo acontece com a linguística de computador. Nós tendemos a desprezar todas as suas realizações. Entro no Google uma consulta "versos de Pushkin", ele encontra uma página que diz "A.S. Pushkin - Poemas. " Parece que isso? Comportamento absolutamente normal. Mas os linguistas da computação tiveram que gastar dezenas de anos para que a palavra poema fosse encontrada na palavra poemas, para que a palavra Pushkin fosse encontrada na palavra Pushkin e não em Pushkin.
Xadrez por Computador e Tradução Automática
A linguística da computação nasceu ao mesmo tempo que o xadrez do computador - e o xadrez também já foi uma prerrogativa do homem. Claude Shannon, um dos fundadores da ciência da computação, escreveu
um artigo em 1950
sobre como programar um computador para jogar xadrez. Segundo ele, podemos desenvolver dois tipos de estratégias.
A - com busca exaustiva de sequelas. É necessário testar todos os movimentos possíveis em cada estágio.
B - repita apenas as extensões avaliadas como promissoras.
A pessoa, obviamente, usa a estratégia B. O grande mestre, provavelmente, passa apenas pelas opções que são razoáveis em sua opinião, e em um tempo bastante rápido dá uma boa jogada.
A estratégia A é difícil de implementar. De acordo com o cálculo de Shannon, para contar três jogadas, é necessário separar 10
9 opções e, se a posição for estimada em um microssegundo (super otimista em meados do século 20), serão necessários 17 minutos para fazer uma jogada. E três movimentos adiante são uma profundidade insignificante de previsão.
Toda a história subseqüente do xadrez consiste no desenvolvimento de técnicas que nos permitem não resolver tudo, mas entender o que precisa ser resolvido e o que não é necessário. E a vitória sobre o homem já foi alcançada, finalmente e irrevogavelmente. O computador contornou o campeão mundial de xadrez há cerca de 20 anos e só melhorou desde então.
O melhor programa foi considerado Stockfish. No ano passado, AlphaZero jogou 100 jogos com ela.
| Brancos | Preto | Vitória branca | Draw | Vitória do preto |
|---|
| AlphaZero | Stockfish | 25 | 25 | 0 0 |
| Stockfish | AlphaZero | 0 0 | 47 | 3 |
AlphaZero é uma rede neural artificial que apenas jogou xadrez por quatro horas consigo mesma. E ela aprendeu a tocar melhor do que todos os programas anteriores a ela.
Uma coisa semelhante está acontecendo na linguística de computadores agora - um aumento na modelagem de redes neurais. Eles começaram a trabalhar no xadrez automático simultaneamente com as traduções automáticas - em meados do século passado. Desde então, três estágios de desenvolvimento foram distinguidos.
- Tradução automática baseada em regrasEle é projetado de maneira muito simples - algo como nas aulas de gramática, o computador seleciona o assunto, o predicado e a adição. Ele entende com que palavras tudo isso é traduzido para outro idioma, aprende a expressar seu assunto, predicado, adição e tudo.
Essa tradução se desenvolveu ao longo de 30 anos, sem muito sucesso.
- Tradução estatística (frase)O computador conta com um grande banco de dados de textos traduzidos por humanos. Ele seleciona as palavras e frases que correspondem às palavras e frases do original, as reúne em frases no idioma de destino e fornece o resultado.
Quando na Internet, eles escrevem sobre as próximas “20 traduções automáticas mais estúpidas” - provavelmente, trata-se de tradução de frases. Embora ele tenha alcançado algum sucesso.
- Tradução de rede neuralFalaremos mais sobre ele. Ele entrou em uso em massa diante de nossos olhos: o Google ativou a tradução de rede neural no final de 2016. Para o russo, ele apareceu em março de 2017. A Yandex lançou no final de 2017 um sistema híbrido baseado em redes e estatísticas neurais.
Redes neurais
A tradução de rede neural é baseada na seguinte idéia: se simular e reproduzir matematicamente o trabalho dos neurônios na cabeça de uma pessoa, pode-se presumir que um computador aprenderá a trabalhar com um idioma como uma pessoa.
Para fazer isso, dê uma olhada nas células do cérebro humano.
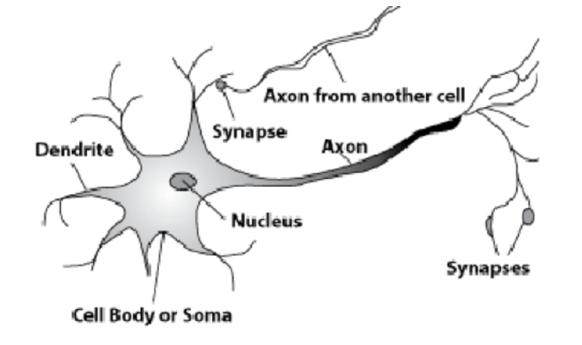
Aqui está um neurônio natural. Um processo longo, um axônio, parte do núcleo. Ele atribui a processos de outras células - sinapses. Segundo os axônios, informações sobre alguns processos eletroquímicos são transmitidas para as sinapses das células celulares. Apenas um axônio emerge de cada célula e muitas sinapses podem entrar. Os sinais se propagam e é assim que as informações são transmitidas.
Algumas células estão conectadas ao mundo exterior. Eles recebem sinais que são posteriormente processados pela rede neural.
E aqui está o modelo matemático mais simples do que podemos fazer aqui. Desenhei nove círculos conectados. Estes são neurônios.

Os seis neurônios à esquerda são a camada de entrada, que recebe um sinal do ambiente externo. Os neurônios da segunda e terceira camada não tocam o ambiente, mas apenas com outros neurônios. Introduzimos a regra - se pelo menos duas setas dos neurônios ativados entram no neurônio, esse neurônio também é ativado.
A rede neural processa o sinal recebido na entrada e, finalmente, a saída correta - o neurônio acende ou não acende. Com essa arquitetura, para ativar o neurônio direito, você precisa de pelo menos quatro neurônios ativados na linha esquerda. Se 6 ou 5 estiver aceso, ele definitivamente acenderá; se de 0 a 3, ele definitivamente não acenderá. Mas se quatro queimarem, acenderá apenas se estiverem distribuídas uniformemente: 2 na metade superior e 2 na parte inferior.
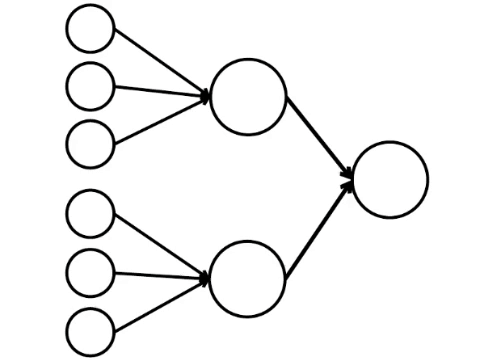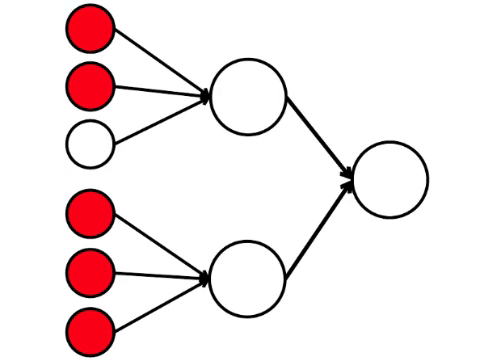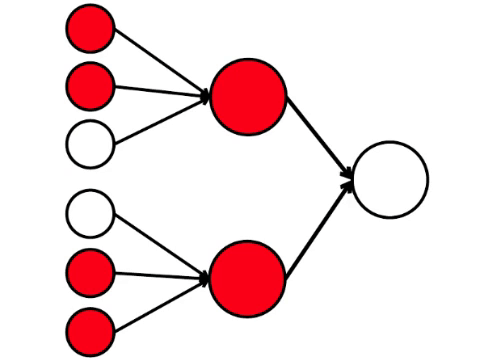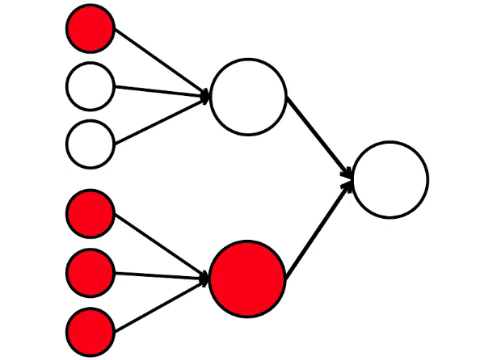
Acontece que o esquema mais simples de nove círculos leva a um argumento bastante ramificado.
As redes neurais artificiais funcionam da mesma maneira, mas geralmente não com coisas simples como "iluminadas / não iluminadas" (ou seja, 1 ou 0), mas com números reais.
Tomemos, por exemplo, uma rede de 5 neurônios - dois na camada de entrada, dois no meio (oculto) e um na saída. Entre todos os neurônios das camadas vizinhas, há conexões às quais os números são atribuídos - pesos. Para descobrir o que acontece em um neurônio ainda vazio, vamos fazer uma coisa muito simples: vamos ver quais conexões levam a ele, multiplicar o peso de cada conexão pelo número que está escrito no neurônio da camada anterior a partir da qual essa conexão vem, e vamos resumir tudo isso. No neurônio verde superior do diagrama, 50 × 1 + 3 × 10 = 80 é obtido, e no inferior - 50 × 0,5 - 3 × 10 = −5.
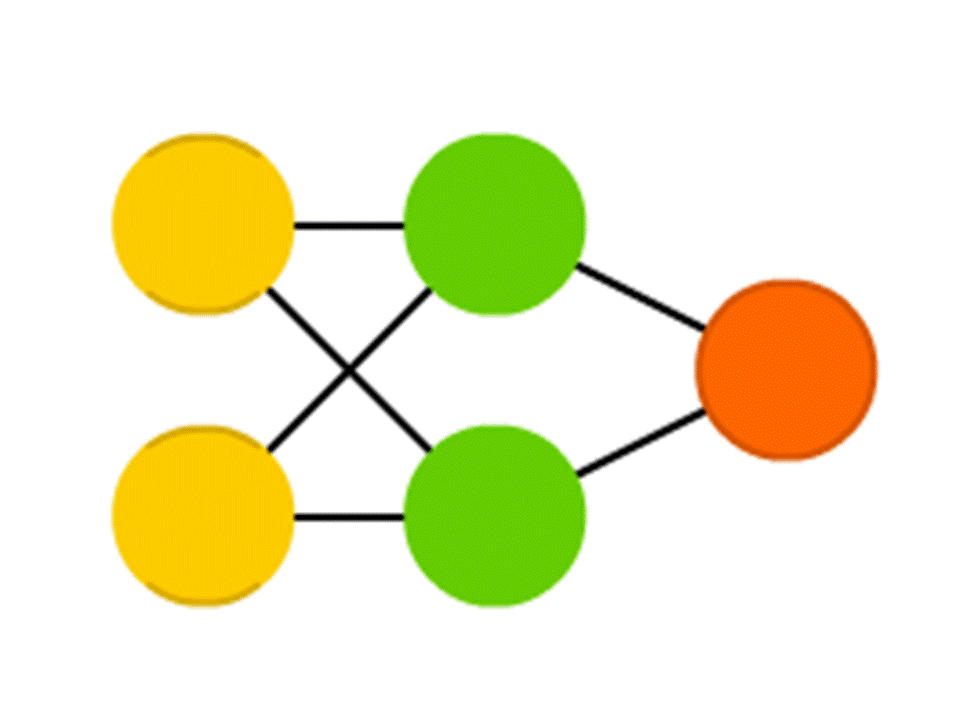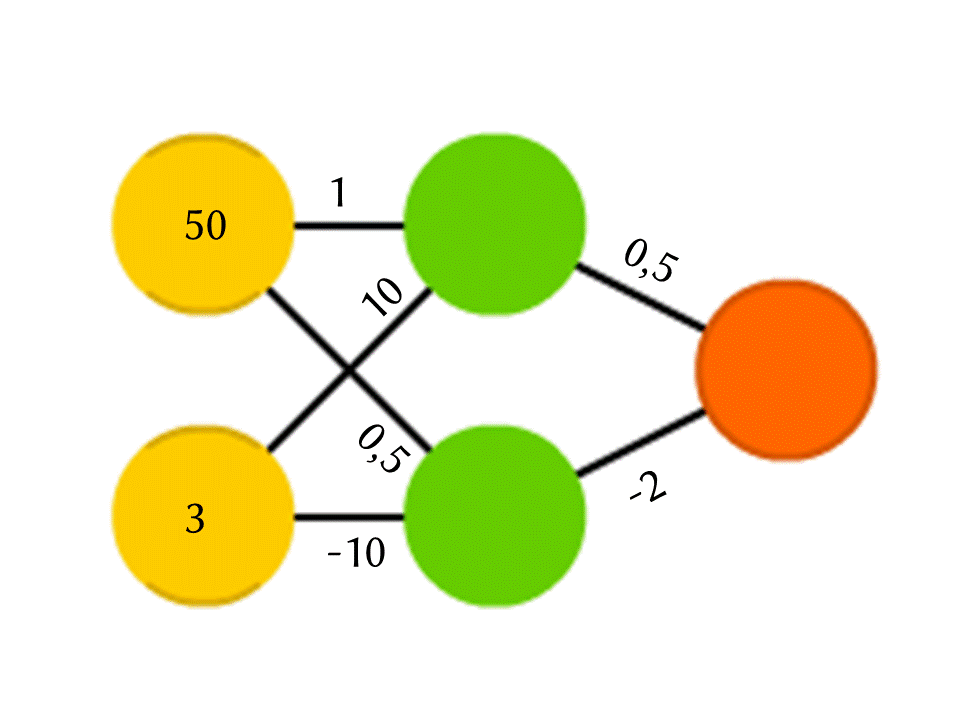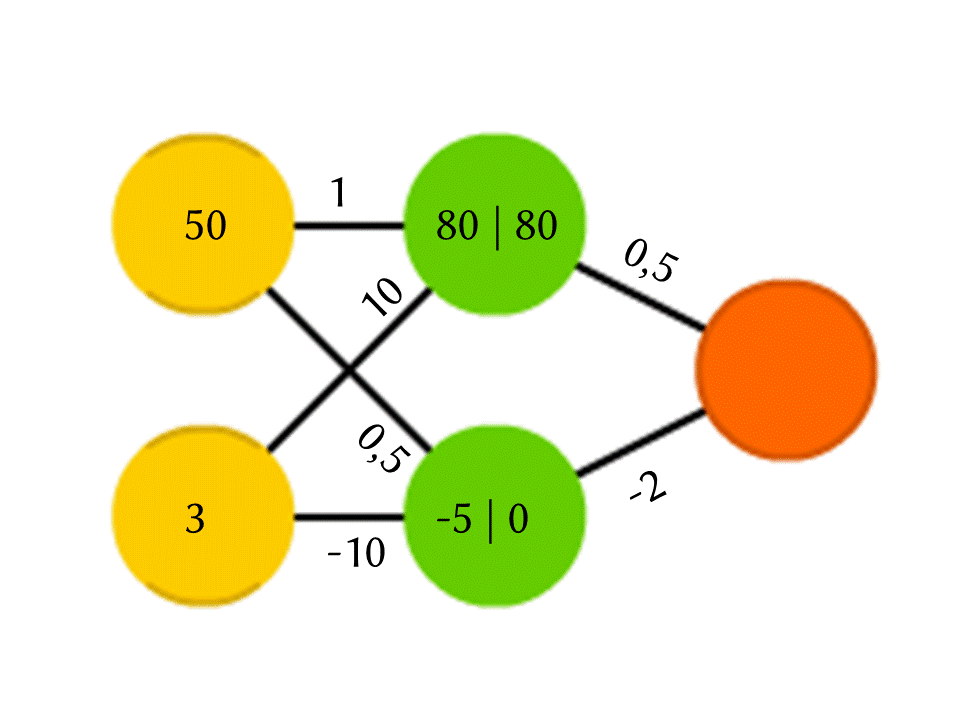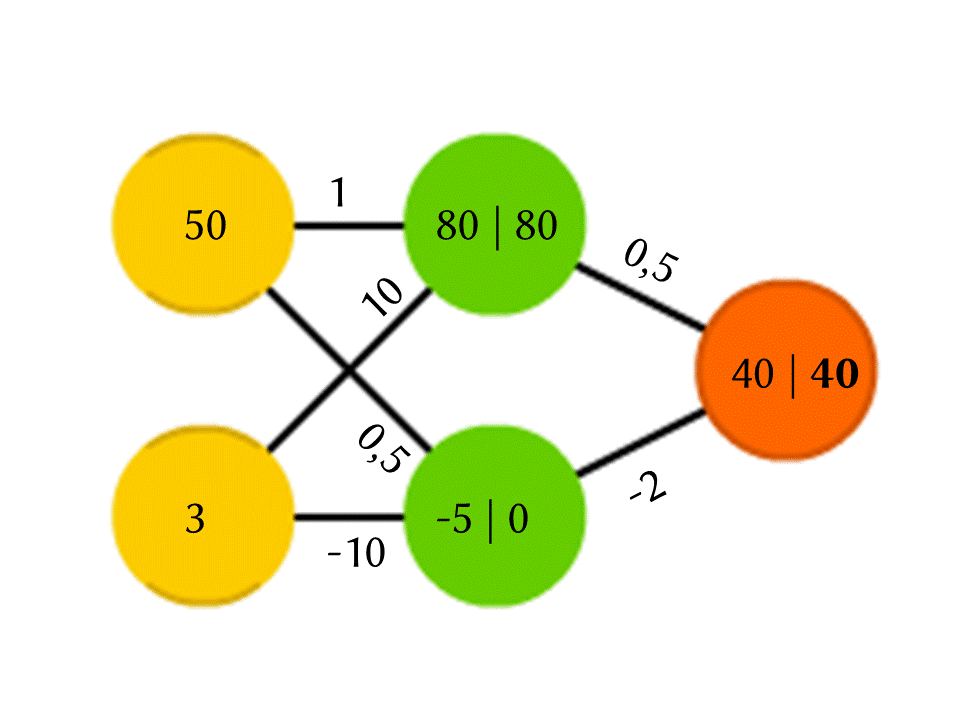
É verdade que, se você fizer exatamente isso, a saída será simplesmente o resultado do cálculo de uma função linear dos valores de entrada (no nosso exemplo, 25 Y - 0,5 X sairá, onde X é o número no neurônio amarelo superior e Y está na parte inferior), então concordaremos algo mais está acontecendo dentro do neurônio. A função mais simples e ao mesmo tempo de bons resultados é ReLU (Unidade Linear Retificada): se um número negativo for obtido em um neurônio, a saída 0 e, se não for negativa, a saída será inalterada.
Portanto, em nosso esquema, −5 na saída do neurônio verde inferior se transforma em 0, e é esse número que é usado em cálculos adicionais. Obviamente, a arquitetura de redes neurais reais usadas na prática é muito mais complicada do que nossos exemplos de brinquedos, e os pesos não são retirados do teto, mas são selecionados por treinamento, mas o próprio princípio é importante.
O que isso tem a ver com a linguagem?
O mais direto, desde que representemos o idioma na forma de números. Codificamos cada palavra e encontramos uma rede neural.
Aqui, uma conquista muito importante da linguística de computador vem ao resgate, que surgiu em termos de idéias há 50 anos e em termos de implementação, os últimos 10 anos vêm se desenvolvendo ativamente: representação vetorial de palavras.
 esta e as próximas duas fotos são de uma apresentação de Stefan Evert
esta e as próximas duas fotos são de uma apresentação de Stefan EvertEsta é uma representação de palavras como uma matriz de números com base em uma consideração muito simples. Para descobrir o significado de uma palavra, não olhamos para o dicionário, mas para grandes conjuntos de texto e consideramos ao lado do qual nossa palavra é mais comum.
Por exemplo, você conhece a palavra silenciador? Caso contrário, tente adivinhar olhando os textos em que a palavra está abafada.
- Um casaco preto e um boné branco. Bem, e ainda um silencioso indispensável ...
Ao lado dele estão roupas, um casaco e um boné, e provavelmente um silencioso dentre eles. Dificilmente é comida, dificilmente um elemento da arquitetura.
- Por alguma razão, em seu pescoço em uma noite abafada, um velho cachecol listrado foi aspergido.
No pescoço - isso significa que não são meias. Você pode pegá-lo - aparentemente, é flexível, feito de tecido, e não, digamos, de madeira ou pedra.
- Uma toalha molhada de waffle kutsey que Nerzhin pendia no pescoço como um silenciador.
Nós reabastecemos e reabastecemos o banco de exemplos e, olhando para eles, gradualmente entenderemos o que é abafado - algo como um cachecol. O computador faz exatamente a mesma coisa, que examina o texto e faz uma coisa simples - captura as palavras que estão próximas.
Aqui estão os hieróglifos egípcios.
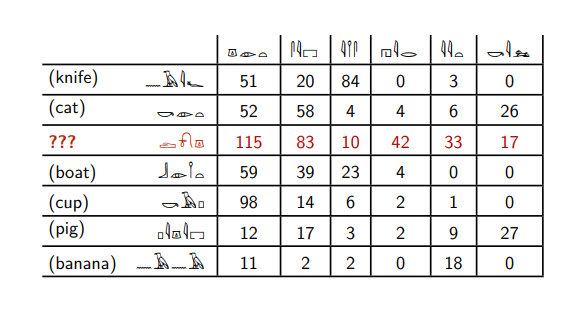
Suponha que você conheça os significados de seis deles e queira entender que tipo de palavra é destacada em vermelho. Esta tabela diz quantas vezes essas palavras são encontradas ao lado de outros hieróglifos egípcios.
A palavra vermelha ocorre com a sexta palavra - assim como as palavras
gato e
porco . E outras palavras não ocorrem com ele.
A palavra vermelha é encontrada com a segunda palavra com muito mais frequência do que com a terceira, em contraste com as palavras
faca e
banana . As palavras
gato, barco, porco e
xícara se comportam da mesma maneira.
Com base nesse raciocínio, podemos dizer que a palavra vermelha é mais semelhante às palavras
gato e
porco - somente elas se encontram com a sexta palavra, têm uma proporção semelhante da segunda e terceira.
E não nos enganaremos, porque a palavra vermelha é a palavra
cachorro .

De fato, esses não são hieróglifos egípcios, mas substantivos e verbos em inglês, para os quais é indicado quantas vezes eles aparecem juntos em uma grande coleção de textos em inglês. Essa sexta palavra é o verbo
matar .
As palavras
gato, cachorro e
porco são frequentemente encontradas à direita da palavra
matar . Facas, barcos e bananas raramente são mortas. Embora em russo, se você quiser, pode dizer: "Eu matei meu barco", mas isso é uma coisa rara.
Exatamente o que um computador faz quando processa texto. Ele simplesmente acredita que encontra algo, e não mais obras-primas da compreensão.
Além disso, o computador apresenta as palavras na forma de um determinado conjunto de números: no exemplo acima, a palavra
cão corresponde a números (115; 83; 10; 42; 33; 17). De fato, devemos calcular quantas vezes isso ocorre, não com seis palavras, mas com todas as palavras que estão em nossos textos: se todos tivermos 100.000 palavras diferentes, associaremos a palavra
cão a uma matriz de 100.000 números. Isso não é muito conveniente na prática; portanto, métodos de redução da dimensão são geralmente usados para converter os resultados de cada palavra em uma matriz de várias centenas de elementos de comprimento (mais sobre isso pode ser encontrado
aqui ).
Existem bibliotecas prontas para linguagens de programação que permitem fazer isso: por exemplo,
gensim para Python. Ao enviar para ele o
corpus em inglês browniano com um volume de aproximadamente 1 milhão de palavras, em alguns segundos eu posso construir um modelo no qual a palavra
gato terá a seguinte aparência:

Nós representamos um animal, com cabelo, cauda, mia. Meu computador, que eu ensinei inglês, representa a palavra
gato na forma de cem números que vieram das palavras ao lado.
Aqui está um exemplo de material russo no site da
RusVectōres . Peguei a palavra
corvo e pedi ao computador que me dissesse quais palavras são mais parecidas com ela - ou, em outras palavras, os conjuntos de números cujas palavras são mais parecidas com o conjunto de números da palavra
corvo .

8 em cada 10 palavras eram nomes de pássaros. Sem saber nada, o computador produziu um excelente resultado - percebi que os pássaros parecem um corvo. Mas de onde vieram as palavras em brasa e ruchenka?
Você pode adivinharNos três, a palavra branco é frequentemente usada: para aquecer o branco, sob as alças brancas, o corvo branco.
Recebendo matrizes de números e passando-as por si mesmas, as redes neurais oferecem um resultado incrivelmente bom. Aqui está um texto filosófico bastante complicado de um discurso do acadêmico Andrei Zaliznyak sobre o status da ciência no mundo moderno. Foi traduzido para o inglês por um tradutor há um mês e requer uma intervenção editorial mínima.

É aqui que surge a questão filosófica global.
Esse é o problema da chamada sala chinesa - um experimento mental sobre os limites da inteligência artificial. Foi formulado pelo filósofo John Searle em 1980.
Na sala, está um homem que não sabe chinês. Ele recebeu instruções, ele tem livros, dicionários e duas janelas. Em uma janela, ele recebe anotações em chinês, e em outra janela, ele fornece respostas - também em chinês, agindo exclusivamente de acordo com as instruções.
Por exemplo, as instruções podem dizer: “aqui você tem uma anotação, encontre o caractere no dicionário. Se for o hieróglifo nº 518, dê o hieróglifo nº 409 à janela da direita; se o hieróglifo nº 711 tiver chegado, dê o hieróglifo nº 35 à janela da direita e assim por diante ”. Se a pessoa na sala seguir bem as instruções e se essas instruções estiverem bem escritas, a pessoa na rua que der e receber notas poderá assumir que a sala ou a pessoa nela sabe chinês. Afinal, não é visível do lado de fora o que está acontecendo lá dentro.
Todos sabemos que este é um homem que simplesmente recebeu instruções estúpidas. Ele faz algumas operações com eles, mas não conhece chinês. Embora do ponto de vista do observador seja o conhecimento da linguagem.
A questão filosófica - como nos relacionamos com isso? O quarto fala chinês? Talvez o autor destas instruções conheça o idioma chinês? E talvez não, porque você pode emitir instruções com base em uma variedade de perguntas e respostas prontas.
Por outro lado, o que os chineses sabem? Aqui você conhece o idioma russo. O que você pode fazer? O que está acontecendo na sua cabeça? Algum tipo de reação bioquímica. Orelhas ou olhos recebem um certo sinal, isso causa algum tipo de reação, você entende alguma coisa. Mas o que significa "entender"? O que você faz quando entende?
E uma pergunta ainda mais complicada - você está fazendo isso da maneira ideal? É verdade que você trabalha com o idioma melhor do que qualquer máquina poderia trabalhar com o idioma? Você consegue imaginar que fala russo pior do que qualquer computador? Sempre comparamos Siri, Alice com a maneira como nos falamos, e rimos se eles falam incorretamente do nosso ponto de vista. Por outro lado, você e eu demos ao computador muito do que antes era considerado prerrogativa do homem. Agora os carros são muito melhores em contar e jogar xadrez, mas antes não podiam. Talvez coisas semelhantes ocorram com computadores falantes: em 100, 10 ou até 5 anos, reconhecemos que a máquina dominou muito melhor o idioma, entende muito mais e, em geral, é um falante nativo muito melhor do que nós.
O que fazer, então, com o fato de uma pessoa ser usada para se definir através da linguagem? Afinal, eles dizem que apenas uma pessoa fala a língua.
O que acontecerá se reconhecermos a vitória no computador nesta área?Deixe suas perguntas nos comentários. Talvez um pouco mais tarde possamos fazer uma entrevista com Alexander. Ou talvez ele próprio faça um comentário no nosso convite e converse com todos os interessados.