 Oi Meu nome é Marco, trabalho no Badoo no departamento de Plataforma. Temos muitas coisas escritas no Go, e muitas vezes são críticas para o desempenho do sistema. É por isso que hoje ofereço uma tradução de um artigo que realmente gostei e, tenho certeza, será muito útil para você. O autor mostra passo a passo como ele abordou os problemas de desempenho e como eles os resolveram. Incluindo você se familiarizará com as ferramentas avançadas disponíveis no Go para esse trabalho. Boa leitura!
Oi Meu nome é Marco, trabalho no Badoo no departamento de Plataforma. Temos muitas coisas escritas no Go, e muitas vezes são críticas para o desempenho do sistema. É por isso que hoje ofereço uma tradução de um artigo que realmente gostei e, tenho certeza, será muito útil para você. O autor mostra passo a passo como ele abordou os problemas de desempenho e como eles os resolveram. Incluindo você se familiarizará com as ferramentas avançadas disponíveis no Go para esse trabalho. Boa leitura!Algumas semanas atrás, li o artigo “
Bom código contra código incorreto no Go ”
, em que o autor, passo a passo, demonstra a refatoração de um aplicativo real que resolve problemas reais de negócios. Ele se concentra em transformar "código incorreto" em "código válido": mais idiomático, mais compreensível, utilizando totalmente as especificidades do Go. Mas o autor também afirmou a importância do desempenho do aplicativo em questão. A curiosidade surgiu em mim: vamos tentar acelerar!
O programa, grosso modo, lê o arquivo de entrada, analisa-o linha por linha e preenche os objetos na memória.
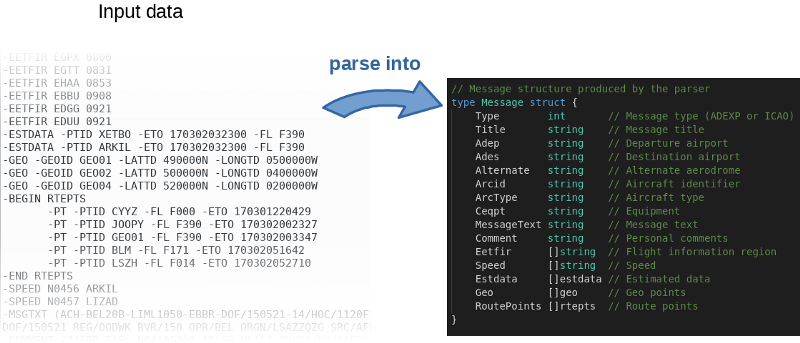
O autor não apenas postou o
código fonte no GitHub , mas também escreveu uma referência. Essa é uma ótima ideia. De fato, o autor convidou todos a brincar com o código e tentar acelerá-lo. Para reproduzir os resultados do autor, use o seguinte comando:
$ go test -bench=.
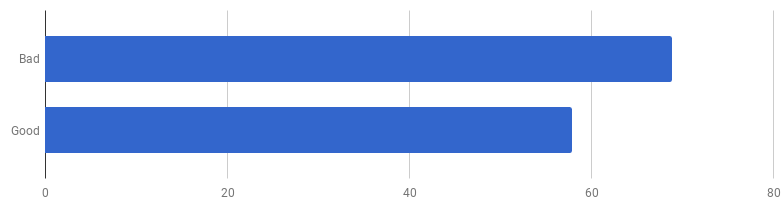 μs por chamada (menos - melhor)
μs por chamada (menos - melhor)Acontece que no meu computador o “código bom” é 16% mais rápido. Podemos acelerar?
Na minha experiência, há uma correlação entre qualidade e desempenho do código. Se você refatorou o código com sucesso, o tornou mais limpo e menos conectado, provavelmente o tornou mais rápido porque ficou menos confuso (e não há mais instruções desnecessárias que foram executadas em vão). Talvez durante a refatoração você tenha notado algumas oportunidades de otimização ou agora tenha apenas a oportunidade de criá-las. Mas, por outro lado, se você quiser tornar o código ainda mais produtivo, provavelmente precisará se afastar da simplicidade e adicionar vários hacks. Você realmente economiza milissegundos, mas a qualidade do código sofrerá: ficará mais difícil lê-lo e falar sobre ele, ficará mais frágil e flexível.
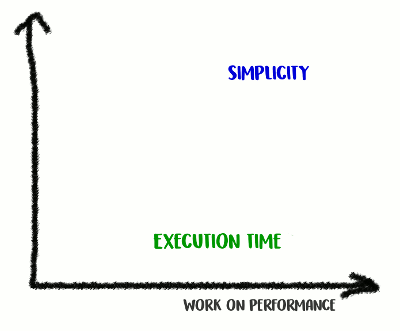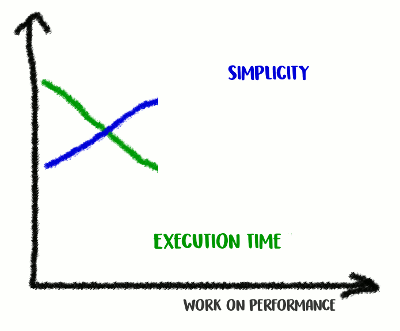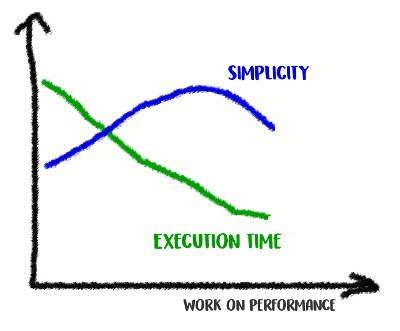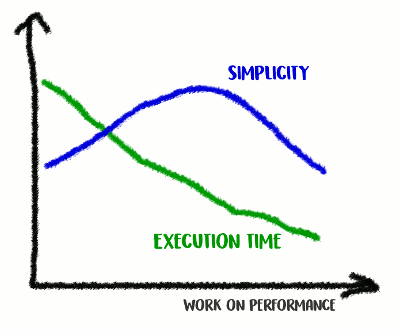 Subimos a montanha da Simplicidade e depois descemos dela
Subimos a montanha da Simplicidade e depois descemos delaEsta é uma troca: até onde você está disposto a ir?
Para priorizar adequadamente o trabalho de aceleração, a estratégia ideal é encontrar gargalos e focar neles. Para fazer isso, use as ferramentas de criação de perfil.
pprof e
trace são seus amigos:
$ go test -bench=. -cpuprofile cpu.prof $ go tool pprof -svg cpu.prof > cpu.svg
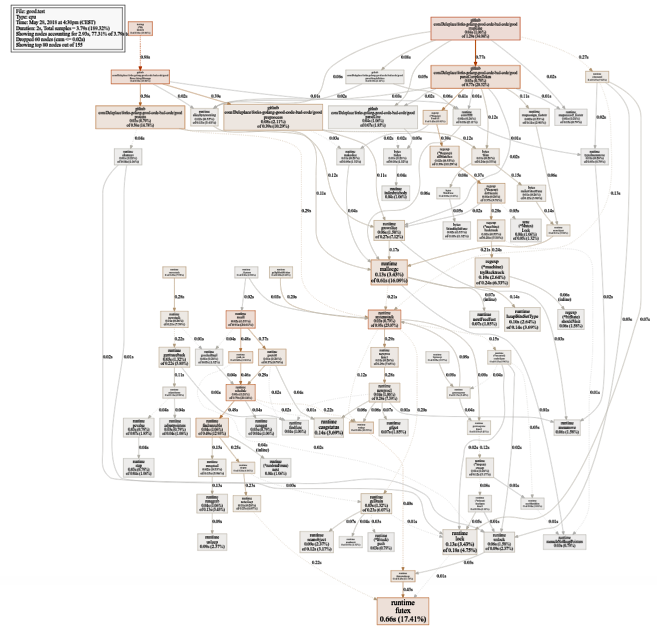 Um gráfico bastante amplo do uso da CPU (clique para SVG)
Um gráfico bastante amplo do uso da CPU (clique para SVG) $ go test -bench=. -trace trace.out $ go tool trace trace.out
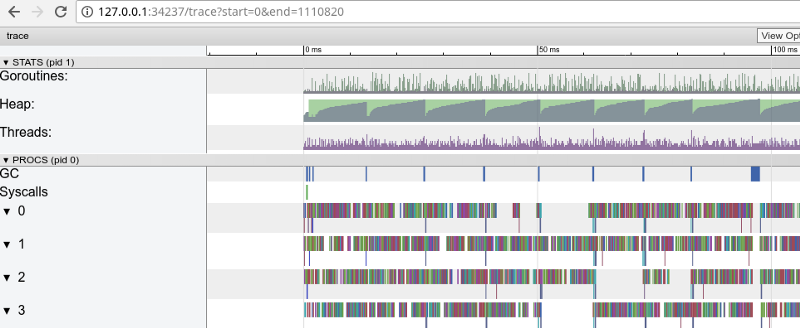 Rastreamento do arco-íris: muitas tarefas pequenas (clique para abrir, funciona apenas no Google Chrome)
Rastreamento do arco-íris: muitas tarefas pequenas (clique para abrir, funciona apenas no Google Chrome)O rastreamento confirma que todos os núcleos do processador estão ocupados (linhas abaixo de 0, 1 etc.) e, à primeira vista, isso é bom. Mas ela também mostra milhares de pequenos cálculos de cores e várias áreas vazias onde os núcleos estavam ociosos. Vamos ampliar:
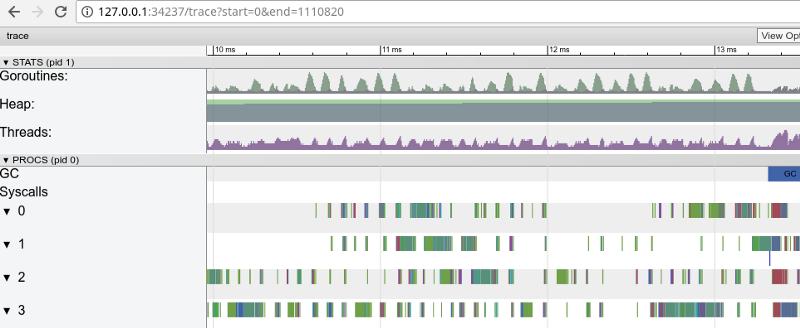 "Janela" em 3 ms (clique para abrir, funciona apenas no Google Chrome)
"Janela" em 3 ms (clique para abrir, funciona apenas no Google Chrome)Cada núcleo fica ocioso por um bom tempo e também “salta” entre micro-tarefas o tempo todo. Parece que a granularidade dessas tarefas não é ótima, o que leva a um grande número de
alternâncias de
contexto e à concorrência devido à sincronização.
Vamos ver o que o
detector de vôo nos diz. Existem problemas no acesso síncrono aos dados (se houver algum, temos problemas muito maiores que o desempenho)?
$ go test -race PASS
Ótimo! Tudo está correto. Não foram encontrados voos. Funções de teste e funções de benchmark são funções diferentes (
consulte a documentação ), mas aqui elas chamam a mesma função
ParseAdexpMessage ; portanto, o que verificamos para vôos de dados por testes é bom.
O modelo competitivo na versão “boa” consiste em processar cada linha do arquivo de entrada em uma goroutine separada (para usar todos os núcleos). A intuição do autor aqui funcionou bem, pois as goroutines têm uma reputação de recursos fáceis e baratos. Mas quanto ganhamos com a execução paralela? Vamos comparar com o mesmo código, mas sem usar goroutines (basta remover a palavra go que vem antes da chamada da função):

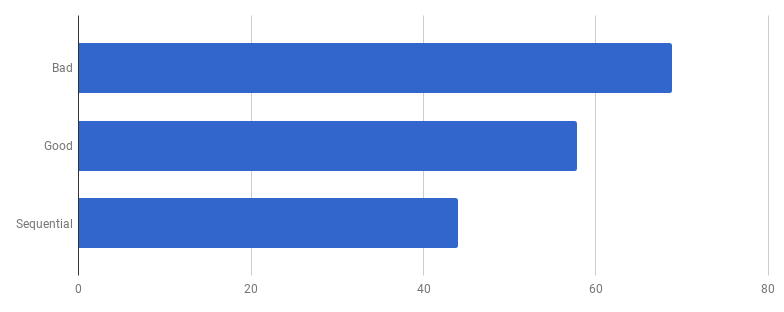
Ops, parece que o código se tornou mais rápido sem o uso de simultaneidade. Isso significa que a sobrecarga (diferente de zero) para o lançamento de goroutines excede o tempo que ganhamos usando vários núcleos ao mesmo tempo. O próximo passo natural deve ser remover a sobrecarga (diferente de zero) para usar canais para enviar os resultados. Vamos substituí-lo por uma fatia regular:
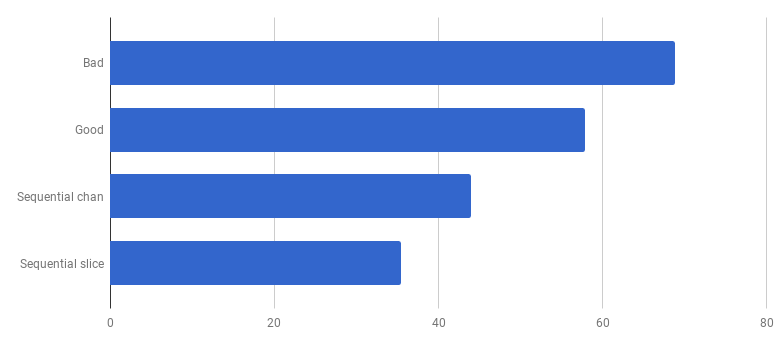 μs por chamada (menos é melhor)
μs por chamada (menos é melhor)Obtivemos cerca de 40% de aceleração em relação à versão “boa”, simplificando o código e removendo a concorrência (
diff ).
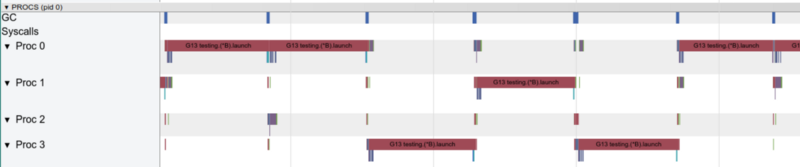 Com uma goroutine, apenas um núcleo funciona por vez
Com uma goroutine, apenas um núcleo funciona por vezVamos agora ver as funções importantes no gráfico pprof:
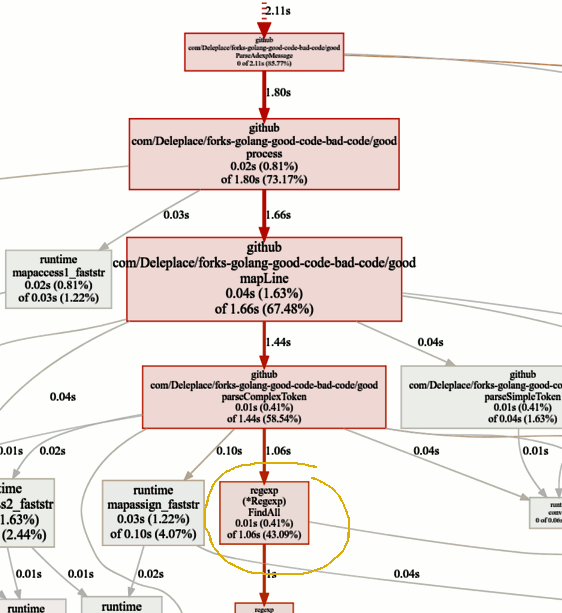 Procurando gargalos
Procurando gargalosA referência da versão atual (operação sequencial, fatias) gasta 86% do tempo analisando as mensagens, e isso é normal. Mas notamos rapidamente que 43% do tempo é gasto no uso de expressões regulares e da função
(* Regexp) .FindAll .
Apesar de as expressões regulares serem uma maneira conveniente e flexível de obter dados de texto sem formatação, elas têm desvantagens, incluindo o uso de um grande número de recursos, processador e memória. Eles são uma ferramenta poderosa, mas geralmente seu uso é desnecessário.
Em nosso programa, um modelo
patternSubfield = "-.[^-]*"
Destina-se principalmente a destacar comandos começando com um traço (-), e pode haver vários na linha. Depois de
extrair um pequeno código, isso pode ser feito usando
bytes.Split . Vamos adaptar o código (
confirmar ,
confirmar ) para alterar as expressões regulares para Split:
 μs por chamada (menos
μs por chamada (menos é
melhor)Uau! Código 40% mais produtivo! O gráfico de consumo da CPU agora fica assim:
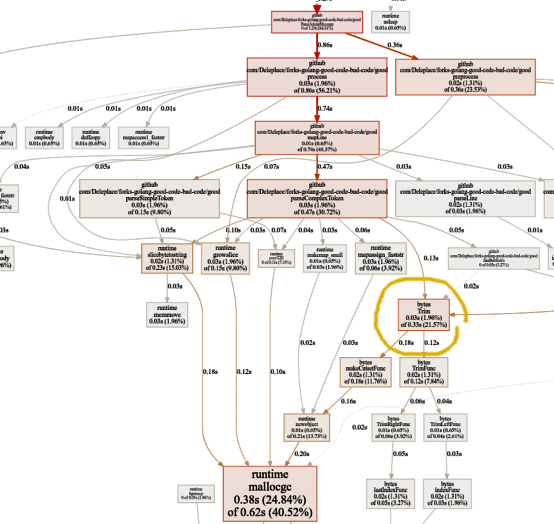
Não há mais tempo perdido em expressões regulares. Uma parte significativa (40%) vai para a alocação de memória de cinco funções diferentes. Curiosamente, agora 21% do tempo é gasto na função
bytes.Trim :
 Esse recurso me intriga. O que podemos fazer aqui?
Esse recurso me intriga. O que podemos fazer aqui?
bytes.Trim espera uma string com caracteres que "corta" como argumento, mas como essa string passamos uma string com apenas um caractere - um espaço. Este é apenas um exemplo de como você pode obter aceleração devido à complexidade: vamos criar nossa função de apara em vez da função padrão. Nossa função de
ajuste personalizado funcionará com um único byte em vez de uma linha inteira:

 μs por chamada (menos é melhor)
μs por chamada (menos é melhor)Viva, mais 20% de desconto! A versão atual é quatro vezes mais rápida que a original “ruim” e, ao mesmo tempo, usa apenas um núcleo. Nada mal!
Anteriormente, abandonamos a competitividade no nível de processamento de linha, mas eu argumento que a aceleração pode ser alcançada usando a competitividade em um nível superior. Por exemplo, o processamento de 6.000 arquivos (6.000 mensagens) é mais rápido no meu computador se cada arquivo for processado em sua própria goroutine:
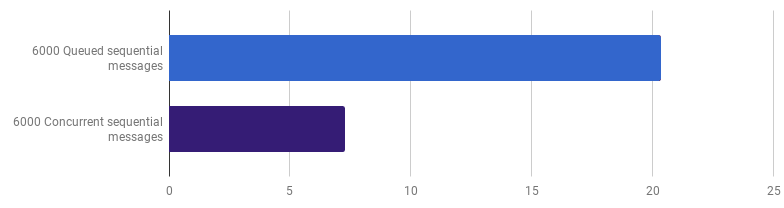 μs por chamada (menos é melhor; roxo é uma solução competitiva)
μs por chamada (menos é melhor; roxo é uma solução competitiva)O ganho é de 66% (ou seja, aceleração três vezes). Isso é bom, mas não muito, considerando que todos os 12 núcleos de processador que tenho são usados. Isso pode significar que o novo código otimizado que processa o arquivo inteiro ainda é uma "pequena tarefa", para a qual a sobrecarga para a criação de goroutines e o custo da sincronização não são insignificantes. Curiosamente, aumentar o número de mensagens de 6.000 para 120.000 não afeta a versão de thread único e reduz o desempenho na versão "uma goroutine por mensagem". Isso ocorre porque, apesar de criar uma quantidade tão grande de goroutines ser possível e às vezes útil, ele traz sua própria sobrecarga na
área do programador de tempo de
execução .
Podemos reduzir ainda mais o tempo de execução (não em 12 vezes, mas ainda assim) criando apenas alguns trabalhadores. Por exemplo, 12 goroutines de longa duração, cada uma das quais processará parte das mensagens:
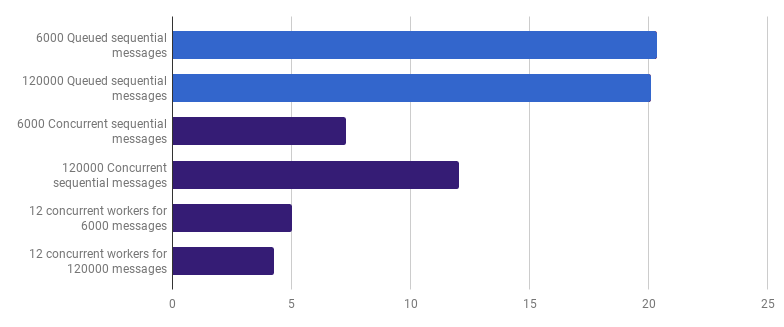 μs por chamada (menos é melhor; roxo é uma solução competitiva)
μs por chamada (menos é melhor; roxo é uma solução competitiva)Esta opção reduz o tempo de execução em 79% em comparação com a versão de thread único. Observe que essa estratégia só faz sentido se você tiver muitos arquivos para processar.
O uso ideal de todos os núcleos do processador é usar várias goroutines, cada uma das quais processa uma quantidade significativa de dados sem nenhuma interação ou sincronização antes que o trabalho seja concluído.
Geralmente eles levam tantos processos (goroutine) quanto os núcleos do processador, mas essa nem sempre é a melhor opção: tudo depende da tarefa específica. Por exemplo, se você estiver lendo algo do sistema de arquivos ou fazendo muitas chamadas de rede, para obter mais desempenho, use mais goroutines que seus núcleos.
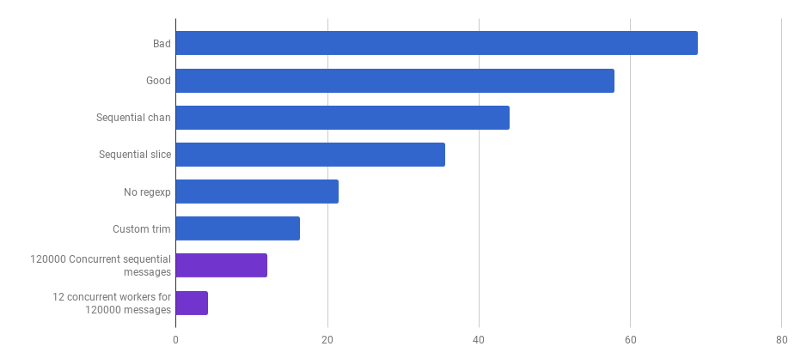 μs por chamada (menos é melhor; roxo é uma solução competitiva)
μs por chamada (menos é melhor; roxo é uma solução competitiva)Chegamos ao ponto em que é difícil aumentar o desempenho da análise com algumas alterações localizadas. O tempo de execução é dominado pelo tempo para alocação de memória e coleta de lixo. Isso parece lógico, pois as funções de gerenciamento de memória são bastante lentas. Uma otimização adicional dos processos associados às alocações permanece como uma lição de casa para os leitores.
O uso de outros algoritmos também pode levar a um grande ganho de desempenho.
Aqui eu fui inspirado por uma palestra da Lexical Scanning em Go from Rob Pike,
para criar um lexer personalizado (
origem ) e um analisador personalizado (
origem ). Esse código ainda não está pronto (não processo muitos casos de canto), é menos claro que o algoritmo original e, às vezes, é difícil escrever o tratamento de erros correto. Mas é pequeno e 30% mais rápido que a versão mais otimizada.
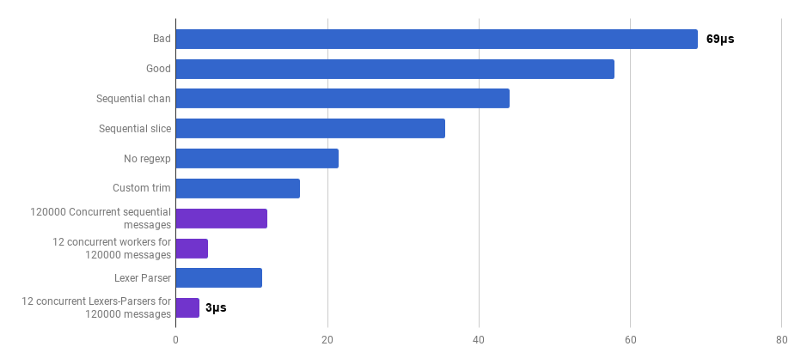 μs por chamada (menos é melhor; roxo é uma solução competitiva)
μs por chamada (menos é melhor; roxo é uma solução competitiva)Sim Como resultado, obtivemos uma aceleração de 23 vezes em comparação com o código fonte.
Isso é tudo por hoje. Espero que você tenha gostado dessa aventura. Aqui estão algumas notas e conclusões:
- A produtividade pode ser melhorada em vários níveis de abstração, usando diferentes técnicas, e o ganho é frequentemente aumentado.
- O ajuste precisa começar com abstrações de alto nível: estruturas de dados, algoritmos, o desacoplamento correto dos módulos. Adote abstrações de baixo nível mais tarde: E / S, lotes, competitividade, usando a biblioteca padrão, trabalhando com memória, alocando memória.
- A análise do Big O é muito importante, mas geralmente não é a ferramenta mais adequada para acelerar um programa.
- Escrever benchmarks é um trabalho árduo. Use perfis e referências para encontrar gargalos e obter uma compreensão mais ampla do que está acontecendo no programa. Lembre-se de que os resultados de referência não são os mesmos que os usuários experimentarão no trabalho da vida real.
- Felizmente, um conjunto de ferramentas ( Bench , pprof , trace , Race Detector , Cover ) torna a pesquisa sobre o desempenho do código acessível e interessante.
- Escrever testes bons e relevantes não é uma tarefa trivial. Mas eles são extremamente importantes para não se aventurar na natureza. Você pode refatorar, certificando-se de que o código permaneça correto.
- Pare e pergunte-se o quão rápido é "rápido o suficiente". Não perca seu tempo otimizando alguns scripts únicos. Não se esqueça que a otimização não é gratuita: tempo, complexidade, erros e dívida técnica do engenheiro.
- Pense duas vezes antes de complicar o código.
- Algoritmos com complexidade Ω (n²) e acima geralmente são muito caros.
- Algoritmos com complexidade O (n) ou O (n log n) e abaixo geralmente estão ok.
- Vários fatores ocultos não podem ser ignorados. Por exemplo, todas as melhorias no artigo foram feitas reduzindo esses fatores e não alterando a classe de complexidade do algoritmo.
- A E / S geralmente é um gargalo: consultas de rede, consultas de banco de dados, sistema de arquivos.
- Expressões regulares geralmente são muito caras e desnecessárias.
- As alocações de memória são mais caras que os cálculos.
- Um objeto alocado na pilha é mais barato que um objeto alocado no heap.
- As fatias são úteis como uma alternativa às movimentações caras de memória.
- As seqüências de caracteres são eficazes quando somente leitura (incluindo nova segmentação). Em todos os outros casos, [] byte são mais eficazes.
- É muito importante que os dados que você processa estejam próximos (caches do processador).
- Competitividade e paralelismo são muito úteis, mas difíceis de preparar.
- Ao cavar fundo e fundo, lembre-se do "piso de vidro" que você não deseja invadir o Go. Se suas mãos estão ansiosas para tentar instruções de montagem, instruções SIMD, pode ser necessário usar o Go apenas para prototipagem e depois mudar para um idioma de nível inferior para obter o controle total do hardware e a cada nanossegundo!