Oi Neste artigo, falarei sobre o classificador bayesiano como uma das opções para filtrar emails de spam. Vamos analisar a teoria, corrigi-la com a prática e, no final, darei meu esboço do código na minha amada linguagem R. Vou tentar expor o mais levemente possível com expressões e formulações. Vamos começar!

Nenhuma fórmula em lugar algum, bem, uma breve teoria
O classificador bayesiano pertence à categoria de aprendizado de máquina. O ponto principal é o seguinte: o sistema que enfrenta a tarefa de determinar se a próxima letra é spam foi treinado previamente por um certo número de letras que sabem exatamente onde "spam" e "onde não é spam". Já ficou claro que isso é ensinar com um professor, onde desempenhamos o papel de professor. O classificador bayesiano apresenta um documento (no nosso caso, uma carta) na forma de um conjunto de palavras que supostamente não dependem uma da outra (e essa ingenuidade se segue daqui).
É necessário calcular a nota de cada turma (spam / não spam) e escolher a que for máxima. Para fazer isso, use a seguinte fórmula:
arg max[P(Qk) prodni=1P(xi|Qk)]
- ocorrência de palavras
no documento da classe
(com suavização) *
- o número de palavras incluídas no documento da turma
M - o número de palavras do conjunto de treinamento
- o número de ocorrências da palavra
no documento da classe
- parâmetro para suavização
Quando o volume do texto é muito grande, você precisa trabalhar com números muito pequenos. Para evitar isso, você pode converter a fórmula de acordo com a propriedade logaritmo **:
Substitua e obtenha:
* Durante os cálculos, você pode encontrar uma palavra que não estava no estágio de treinamento do sistema. Isso pode levar a avaliação a zero e o documento não pode ser atribuído a nenhuma das categorias (spam / não spam). Não importa como você queira, você não ensina ao seu sistema todas as palavras possíveis. Para fazer isso, é necessário aplicar suavização, ou melhor, fazer pequenas correções em todas as probabilidades de entrada de palavras no documento. O parâmetro 0 <α≤1 é selecionado (se α = 1, então isso é suavização de Laplace)
** O logaritmo é uma função monotonicamente crescente. Como pode ser visto na primeira fórmula - estamos procurando o máximo. O logaritmo da função atingirá o pico no mesmo ponto (abscissa) que a própria função. Isso simplifica o cálculo, porque apenas o valor numérico é alterado.
Da teoria à prática
Deixe nosso sistema aprender com as seguintes cartas, conhecidas antecipadamente onde "spam" e "onde não é spam" (exemplo de treinamento):
Spam- “Cupons a um preço baixo”
- “Promoção! Compre uma barra de chocolate e ganhe um telefone de presente »
Não é spam:- "A reunião será realizada amanhã"
- "Compre um quilo de maçãs e uma barra de chocolate"
Atribuição: determine a qual categoria a seguinte letra pertence:
- “A loja tem uma montanha de maçãs. Compre sete quilos e uma barra de chocolate ”
Solução:Nós fazemos uma mesa. Removemos todas as “palavras de parada”, calculamos as probabilidades, tomamos o parâmetro para suavização como um.
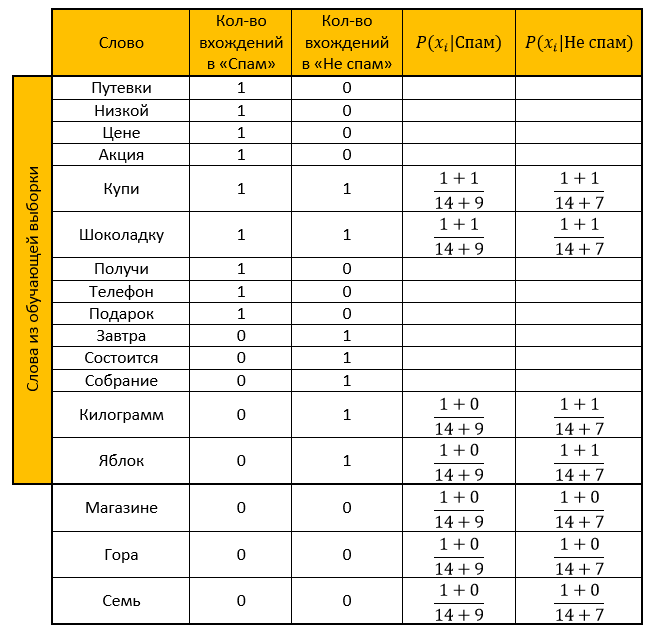
Classificação para a categoria Spam:
Classificação para a categoria "Não spam":
Resposta: a classificação "Não é spam" é mais do que a classificação "Spam". Portanto, a carta de verificação não é spam!
Calculamos o mesmo com a ajuda de uma função transformada pela propriedade do logaritmo:
Classificação para a categoria Spam:
Classificação para a categoria "Não spam":
Resposta: semelhante à resposta anterior. E-mail de verificação - sem spam!
Implementação da linguagem de programação R
Ele comentou quase todas as ações, porque sei quantas vezes não quero entender o código de outra pessoa, por isso espero que a leitura da minha não lhe cause dificuldades. (oh como eu espero)
E aqui, de fato, o próprio códigolibrary("tm") # stopwords library("stringr") # # : spam <- c( ' ', '! ' ) # : not_spam <- c( ' ', ' ' ) # test_letter <- " . " #---------------- -------------------- # spam <- str_replace_all(spam, "[[:punct:]]", "") # spam <- tolower(spam) # spam_words <- unlist(strsplit(spam, " ")) # , stopwords spam_words <- spam_words[! spam_words %in% stopwords("ru")] # unique_words <- table(spam_words) # data frame main_table <- data.frame(u_words=unique_words) # names(main_table) <- c("","") #--------------- ------------------ not_spam <- str_replace_all(not_spam, "[[:punct:]]", "") not_spam <- tolower(not_spam) not_spam_words <- unlist(strsplit(not_spam, " ")) not_spam_words <- not_spam_words[! not_spam_words %in% stopwords("ru")] #--------------- ------------------ test_letter <- str_replace_all(test_letter, "[[:punct:]]", "") test_letter <- tolower(test_letter) test_letter <- unlist(strsplit(test_letter, " ")) test_letter <- test_letter[! test_letter %in% stopwords("ru")] #--------------------------------------------- # main_table$_ <- 0 for(i in 1:length(not_spam_words)){ # need_word <- TRUE for(j in 1:(nrow(main_table))){ # " " , +1 if(not_spam_words[i]==main_table[j,1]) { main_table$_[j] <- main_table$_[j]+1 need_word <- FALSE } } # , data frame if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=not_spam_words[i],=0,_=1)) } } #------------- # , - main_table$_ <- NA # , - main_table$__ <- NA #------------- # Xi Qk formula_1 <- function(N_ik,M,N_k) { (1+N_ik)/(M+N_k) } #------------- # quantity <- nrow(main_table) for(i in 1:length(test_letter)) { # , need_word <- TRUE for(j in 1:nrow(main_table)) { # if(test_letter[i]==main_table$[j]) { main_table$_[j] <- formula_1(main_table$[j],quantity,sum(main_table$)) main_table$__[j] <- formula_1(main_table$_[j],quantity,sum(main_table$_)) need_word <- FALSE } } # , data frame, / if(need_word==TRUE) { main_table <- rbind(main_table,data.frame(=test_letter[i],=0,_=0,_=NA,__=NA)) main_table$_[nrow(main_table)] <- formula_1(main_table$[nrow(main_table)],quantity,sum(main_table$)) main_table$__[nrow(main_table)] <- formula_1(main_table$_[nrow(main_table)],quantity,sum(main_table$_)) } } # "" probability_spam <- 1 # " " probability_not_spam <- 1 for(i in 1:nrow(main_table)) { if(!is.na(main_table$_[i])) { # 1.1 , - probability_spam <- probability_spam * main_table$_[i] } if(!is.na(main_table$__[i])) { # 1.2 , - probability_not_spam <- probability_not_spam * main_table$__[i] } } # 2.1 , - probability_spam <- (length(spam)/(length(spam)+length(not_spam)))*probability_spam # 2.2 , - probability_not_spam <- (length(not_spam)/(length(spam)+length(not_spam)))*probability_not_spam # - ifelse(probability_spam>probability_not_spam," - !"," - !")
Muito obrigado pelo seu tempo lendo meu artigo. Espero que você tenha aprendido algo novo para si mesmo ou simplesmente tenha esclarecido momentos que não estão claros para você. Boa sorte
Fontes:- Um artigo muito bom sobre o classificador ingênuo de Bayes
- Conhecimento derivado do Wiki: aqui , aqui e aqui
- Palestras sobre Data Mining Chubukova I.A.