Oi Abaixo está uma transcrição do vídeo do discurso no comício da comunidade Apache Ignite em São Petersburgo, em 20 de junho. Você pode baixar os slides aqui .
Há toda uma classe de problemas que os usuários iniciantes enfrentam. Eles acabaram de baixar o Apache Ignite, executam as duas, três, dez primeiras e chegam até nós com perguntas que são resolvidas de maneira semelhante. Portanto, proponho a criação de uma lista de verificação que poupará muito tempo e nervos quando você criar seus primeiros aplicativos Apache Ignite. Falaremos sobre os preparativos para o lançamento; como fazer o cluster montar; como iniciar alguns cálculos na grade de computação; Como preparar um modelo e código de dados para que você possa gravar seus dados no Ignite e depois lê-los com sucesso. E o mais importante: como não quebrar nada desde o início.
Preparação para o lançamento - configurar o log
Precisamos de logs. Se você já fez uma pergunta na lista de correspondência do Apache Ignite ou no StackOverflow, como "por que tudo desligou", provavelmente a primeira coisa que você foi solicitado a enviar foi todos os logs de todos os nós.
Naturalmente, o registro do Apache Ignite é ativado por padrão. Mas existem nuances. Primeiro, o Apache Ignite escreve um pouco no stdout . Por padrão, ele inicia no chamado modo silencioso. No stdout você verá apenas os erros mais terríveis e tudo o mais será salvo em um arquivo, o caminho no qual o Apache Ignite exibe no início (por padrão - ${IGNITE_HOME}/work/log ). Você não apaga e mantém os logs mais longos, pode ser muito útil.
stdout inflama na inicialização padrão
Para facilitar a descoberta de problemas sem entrar em arquivos separados e configurar o monitoramento separado para o Apache Ignite, você pode executá-lo no modo detalhado com o comando
ignite.sh -v
e o sistema começará a escrever sobre todos os eventos no stdout junto com o restante do log do aplicativo.
Verifique os logs! Muitas vezes, você pode encontrar soluções para seus problemas. Se o cluster entrou em colapso, muitas vezes no log, você pode ver mensagens como “Aumente esse tempo limite em tal configuração. Caímos por causa dele. Ele é muito pequeno. A rede não é boa o suficiente. ”
Montagem de cluster
Convidados não convidados
O primeiro problema que muitos enfrentam são os convidados não convidados no seu cluster. Ou você acaba sendo um convidado não convidado: inicie um novo cluster e, de repente, verá que, na primeira captura instantânea de topologia, em vez de um nó, você tem dois servidores desde o início. Como assim? Você lançou apenas um.
Uma mensagem indicando que o cluster possui dois nós

O fato é que, por padrão, o Apache Ignite usa Multicast e, na inicialização, ele procura todos os outros Apache Ignite que estão na mesma sub-rede, no mesmo grupo Multicast. E se isso acontecer, ele tentará se conectar. E, no caso de uma conexão malsucedida, ela não será iniciada. Portanto, no cluster do meu laptop de trabalho, nós extras do cluster no laptop do colega aparecem regularmente regularmente, o que obviamente não é muito conveniente.
Como se proteger disso? A maneira mais fácil de configurar o IP estático. Em vez de TcpDiscoveryMulticastIpFinder , que é usado por padrão, existe TcpDiscoveryVmIpFinder . Lá, anote todos os IP e portas às quais você está se conectando. Isso é muito mais conveniente e o protegerá de um grande número de problemas, especialmente em ambientes de desenvolvimento e teste.
Muitos endereços
O próximo problema. Você desabilitou o Multicast, inicia o cluster, em uma única configuração, define uma quantidade decente de IP de diferentes ambientes. E acontece que você inicia o primeiro nó em um cluster novo por 5 a 10 minutos, embora todos os subseqüentes se conectem a ele em 5 a 10 segundos.
Faça uma lista de três endereços IP. Para cada um, prescrevemos intervalos de 10 portas. No total, 30 endereços TCP são obtidos. Como o Apache Ignite deve tentar se conectar a um cluster existente antes de criar um novo cluster, ele verificará cada IP sucessivamente. Pode não causar danos ao seu laptop, mas a proteção de varredura de portas geralmente está incluída em alguns ambientes nublados. Ou seja, ao acessar uma porta privada em algum endereço IP, você não receberá nenhuma resposta até que o tempo limite termine. Por padrão, são 10 segundos. E se você tiver 3 endereços de 10 portas, terá 3 * 10 * 10 = 300 segundos de espera - os mesmos 5 minutos para se conectar.
A solução é óbvia: não registre portas desnecessárias. Se você possui três IPs, dificilmente precisará de um intervalo padrão de 10 portas. Isso é conveniente quando você testa algo na máquina local e executa 10 nós. Mas em sistemas reais, uma única porta geralmente é suficiente. Ou desative a proteção contra a varredura de portas na rede interna, se você tiver essa oportunidade.
O terceiro problema comum é o IPv6. Você pode ver mensagens de erro de rede estranhas: não foi possível conectar, não foi possível enviar uma mensagem, nó segmentado. Isso significa que você caiu do cluster. Muitas vezes, esses problemas são causados por ambientes mistos do IPv4 e IPv6. Isso não quer dizer que o Apache Ignite não suporte IPv6, mas no momento existem alguns problemas.
A solução mais fácil é passar a opção para a máquina Java
-Djava.net.preferIPv4Stack=true
O Java e o Apache Ignite não usarão o IPv6. Isso resolve uma parte significativa dos problemas com agrupamentos em colapso.
Preparação da base de código - serializamos corretamente
O cluster se reuniu, é necessário iniciar algo nele. Um dos elementos mais importantes na interação do seu código com o código Apache Ignite é o Marshaller, ou serialização. Para escrever algo na memória, persistência e enviar pela rede, o Apache Ignite primeiro serializa seus objetos. Você pode ver as mensagens que começam com as palavras: "não pode ser escrito em formato binário" ou "não pode ser serializado usando o BinaryMarshaller". Haverá apenas um aviso no log, mas perceptível. Isso significa que você precisa ajustar um pouco mais o seu código para fazer amizade com o Apache Ignite.
O Apache Ignite usa três mecanismos para serialização:
JdkMarshaller - serialização Java regular;OptimizedMarshaller - serialização Java ligeiramente otimizada, mas os mecanismos são os mesmos;BinaryMarshaller é uma serialização escrita especificamente para o Apache Ignite, usada em todos os lugares. Ela tem várias vantagens. Em algum lugar, podemos evitar serialização e desserialização adicionais e, em algum lugar, podemos até obter um objeto não desserializado na API, trabalhar com ele diretamente em formato binário, como em algo como JSON.
BinaryMarshaller poderá serializar e desserializar seus POJOs que não possuem nada além de campos e métodos simples. Mas se você tiver serialização personalizada via readObject() e writeObject() , se você usar Externalizable , o BinaryMarshaller não suportará. Ele verá que seu objeto não pode ser serializado pela gravação usual de campos não transitórios e desistirá - ele reverterá para o OptimizedMarshaller .
Para fazer amizade com esses objetos com o Apache Ignite, você precisa implementar a interface Binarylizable . Ele é muito simples.
Por exemplo, existe um TreeMap padrão de Java. Possui serialização e desserialização personalizadas via objeto de leitura e gravação. Primeiro descreve alguns campos e, em seguida, grava o comprimento e os próprios dados no OutputStream .
Implementação de TreeMap.writeObject()
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
writeBinary() e readBinary() de Binarylizable funcionam exatamente da mesma maneira: BinaryTreeMap envolve em um BinaryTreeMap regular e grava-o em OutputStream . Esse método é fácil de escrever e aumentará bastante a produtividade.
BinaryTreeMap.writeBinary()
public void writeBinary(BinaryWriter writer) throws BinaryObjectException { BinaryRawWriter rewriter = writer. rewrite (); rawWriter.writeObject(map.comparator()); int size = map.size(); rawWriter.writeInt(size); for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) { rawWriter.writeObject(entry.getKey()); rawWriter.writeObject(entry.getValue()); } }
Iniciar na grade de computação
O Ignite não apenas permite armazenar dados, mas também executar computação distribuída. Como executamos algum tipo de lambda para dispersar todos os servidores e executar?
Para iniciantes, qual é o problema com esses exemplos de código?
Qual é o problema?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast( () -> doStuffWithFooAndBar(foo, bar) );
E se sim?
Foo foo = …; Bar bar = ...; ignite.compute().broadcast(new IgniteRunnable() { @Override public void run() { doStuffWithFooAndBar(foo, bar); } });
Como você pode imaginar, muitos familiarizados com as armadilhas de lambdas e classes anônimas, o problema está em capturar variáveis de fora. Por exemplo, enviamos lambda. Ele usa algumas variáveis declaradas fora do lambda. Isso significa que essas variáveis viajam com ela e voam pela rede para todos os servidores. E então surgem as mesmas perguntas: esses objetos são amigáveis com o BinaryMarshaller ? Qual o tamanho deles? Em geral, queremos que eles sejam transferidos para algum lugar ou esses objetos são tão grandes que é melhor passar algum tipo de ID e recriar os objetos dentro do lambda que já estão do outro lado?
A classe anônima é ainda pior. Se o lambda não puder levar isso com você, jogue-o fora, se não for usado, a classe anônima o levará com certeza, e isso geralmente não leva a nada de bom.
O exemplo a seguir. Lambda novamente, mas que usa a API Apache Ignite um pouco.
Usar ignição no fechamento da computação está errado
ignite.compute().broadcast(() -> { IgniteCache foo = ignite.cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
Na versão original, ele pega o cache e faz localmente algum tipo de consulta SQL. Esse é um padrão quando você precisa enviar uma tarefa que funciona apenas com dados locais em nós remotos.
Qual é o problema aqui? O lambda novamente captura o link, mas agora não para o objeto, mas para o Ignite local no nó com o qual o enviamos. E até funciona, porque o objeto Ignite possui um método readResolve() , que permite que a desserialização substitua o Ignite que veio pela rede pelo local no nó para onde o enviamos. Mas isso também às vezes leva a consequências indesejáveis.
Basicamente, você está simplesmente transferindo mais dados pela rede do que gostaria. Se você precisar obter algum código que não controla a inicialização no Apache Ignite ou algumas de suas interfaces, o mais simples é usar o método Ignintion.localIgnite() . Você pode chamá-lo a partir de qualquer thread que o Apache Ignite criou e obter um link para um objeto local. Se você tem lambdas, serviços, qualquer coisa e entende que precisa do Ignite aqui, recomendo este método.
Usamos Ignite corretamente no fechamento da computação - através de localIgnite()
ignite.compute().broadcast(() -> { IgniteCache foo = Ignition.localIgnite().cache("foo"); String sql = "where id = 42"; SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true); return foo.query(qry); });
E o último exemplo nesta parte. O Apache Ignite possui uma Service Grid que pode ser usada para implantar microsserviços diretamente em um cluster, e o Apache Ignite ajudará a manter on-line o número certo de instâncias. Digamos que neste serviço também precisamos de um link para o Apache Ignite. Como conseguir isso? Poderíamos usar localIgnite() , mas esse link deverá ser salvo manualmente no campo.
O serviço armazena Ignite em um campo incorretamente - leva isso como argumento para o construtor
MyService s = new MyService(ignite) ignite.services().deployClusterSingleton("svc", s); ... public class MyService implements Service { private Ignite ignite; public MyService(Ignite ignite) { this.ignite = ignite; } ... }
Existe uma maneira mais simples. Ainda temos classes completas, e não lambda, para que possamos anotar o campo como @IgniteInstanceResource . Quando o serviço é criado, o Apache Ignite se coloca lá e você pode usá-lo com segurança. Eu recomendo fortemente que você faça exatamente isso, e não tente passar o Apache Ignite e seus filhos para o construtor.
O serviço usa @IgniteInstanceResource
public class MyService implements Service { @IgniteInstanceResource private Ignite ignite; public MyService() { } ... }
Escrevendo e lendo dados
Observando a linha de base
Agora temos um cluster Apache Ignite e um código preparado.
Vamos imaginar este cenário:
- Um cache
REPLICATED - cópias de dados estão disponíveis em todos os nós; - A persistência nativa está ativada - escreve no disco.
Começamos um nó. Como a persistência nativa está ativada, precisamos ativar o cluster antes de trabalhar com ele. Ative. Em seguida, lançamos mais alguns nós.
Tudo parece estar funcionando: escrever e ler estão bem. Todos os nós têm cópias dos dados; você pode parar com segurança um nó. Mas se você parar o primeiro nó a partir do qual você iniciou o lançamento, tudo será interrompido: os dados desaparecem e as operações param de passar.
O motivo disso é a topologia de linha de base - os muitos nós que armazenam dados de persistência neles. Todos os outros nós não terão dados persistentes.
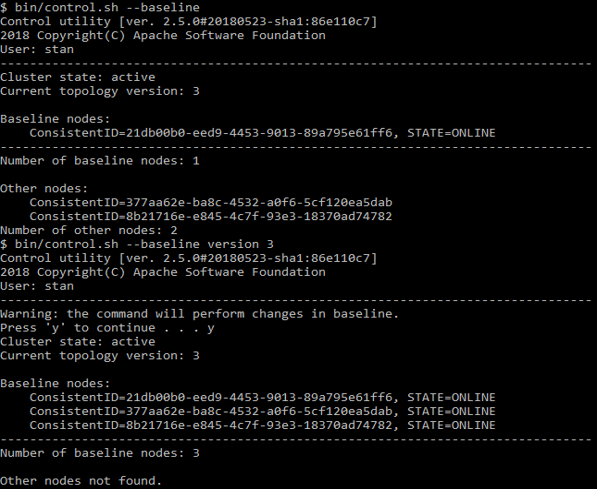
Este conjunto de nós pela primeira vez é determinado no momento da ativação. E os nós que você adicionou posteriormente não são mais incluídos no número de nós da linha de base. Ou seja, muita topologia de linha de base consiste em apenas um, o primeiro nó, quando para, tudo quebra. Para impedir que isso aconteça, inicie todos os nós primeiro e, em seguida, ative o cluster. Se você precisar adicionar ou remover um nó usando o comando
control.sh --baseline
Você pode ver quais nós estão listados lá. O mesmo script pode atualizar a linha de base para seu estado atual.
Exemplo control.sh
Colocação de dados
Agora sabemos que os dados são salvos, tente lê-los. Temos suporte SQL, você pode fazer o SELECT - quase como no Oracle. Mas, ao mesmo tempo, podemos escalar e executar em qualquer número de nós, os dados são armazenados de maneira distribuída. Vejamos esse modelo:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Pedido
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
não retornará todos os dados. O que está errado?
Pessoa ( Person ) refere-se à organização ( Organization ) por ID. Esta é uma chave estrangeira clássica. Mas se tentarmos combinar as duas tabelas e enviar essa consulta SQL, com vários nós no cluster, não receberemos todos os dados.
O fato é que, por padrão, o SQL JOIN funciona apenas em um único nó. Se o SQL constantemente percorresse todo o cluster para coletar dados e retornar o resultado completo, seria incrivelmente lento. Perderíamos todos os benefícios de um sistema distribuído. Portanto, o Apache Ignite analisa apenas os dados locais.
Para obter os resultados corretos, precisamos colocar os dados juntos (colocation). Ou seja, para a combinação correta de Pessoa e Organização, os dados de ambas as tabelas devem ser armazenados no mesmo nó.
Como fazer isso? A solução mais fácil é declarar uma chave de afinidade. Este é um valor que determina em qual nó, em qual partição, em qual grupo de registros esse ou aquele valor será localizado. Se declararmos o ID da organização em Person como uma chave de afinidade, isso significa que as pessoas com esse ID da organização devem estar no mesmo nó que a organização com o mesmo ID.
Se, por algum motivo, você não puder fazer isso, existe outra solução menos eficaz - habilite as junções distribuídas. Isso é feito por meio da API e o procedimento depende do que você usa - Java, JDBC ou qualquer outra coisa. JOIN serão executados mais lentamente, mas retornarão os resultados corretos.
Vamos considerar como trabalhar com chaves de afinidade. Como entendemos que tal e tal ID, tal e tal campo são adequados para determinar a afinidade? Se dissermos que todas as pessoas com o mesmo orgId serão armazenadas juntas, o orgId é um grupo indivisível. Não podemos distribuí-lo entre vários nós. Se o banco de dados contiver 10 organizações, haverá 10 grupos indivisíveis que podem ser colocados em 10 nós. Se houver mais nós no cluster, todos os nós "extras" permanecerão sem grupos. Isso é muito difícil de definir em tempo de execução, então pense nisso antes.
Se você tem uma organização grande e 9 pequenas, o tamanho dos grupos será diferente. Mas o Apache Ignite não analisa o número de registros nos grupos de afinidade quando os distribui pelos nós. Portanto, ele não colocará um grupo em um nó, mas outros 9 em outro para, de alguma forma, nivelar a distribuição. Em vez disso, ele os colocará 5 e 5 (ou 6 e 4, ou mesmo 7 e 3).
Como tornar os dados distribuídos uniformemente? Que possamos ter
- Teclas K;
- Uma variedade de chaves de afinidade;
- Partições P, ou seja, grandes grupos de dados que o Apache Ignite distribuirá entre nós;
- N nós.
Então é necessário que a condição
K >> A >> P >> N
onde >> é "muito mais" e os dados serão distribuídos de maneira relativamente uniforme.
A propósito, o padrão é P = 1024.
Muito provavelmente você não terá sucesso em uma distribuição uniforme. Este foi o caso no Apache Ignite 1.x a 1.9. Isso foi chamado FairAffinityFunction e não funcionou muito bem - resultou em muito tráfego entre os nós. Agora, o algoritmo é chamado RendezvousAffinityFunction . Ele não fornece uma distribuição absolutamente honesta, o erro entre os nós será mais ou menos 5-10%.
Lista de verificação para novos usuários do Apache Ignite
- Configurar, ler, armazenar logs
- Desative o multicast, anote apenas os endereços e portas que você usa
- Desativar IPv6
- Prepare suas aulas para o
BinaryMarshaller - Acompanhe sua linha de base
- Configurar disposição de afinidade