O material, cuja tradução publicamos hoje, se concentrará no que fazer em uma situação em que os dados recebidos do servidor não pareçam com as necessidades do cliente. Nomeadamente, inicialmente consideraremos um problema típico desse tipo e, depois, analisaremos várias maneiras de resolvê-lo.

O problema da API do servidor com falha
Vamos considerar um exemplo condicional com base em vários projetos reais. Suponha que estamos desenvolvendo um novo site para uma organização que já existe há algum tempo. Ela já possui pontos de extremidade REST, mas eles não foram totalmente projetados para o que vamos criar. Aqui, precisamos acessar o servidor apenas para autenticar o usuário, obter informações sobre ele e baixar uma lista de notificações não visualizadas desse usuário. Como resultado, estamos interessados nos seguintes pontos de extremidade da API do servidor:
/auth : autoriza o usuário e retorna um token de acesso./profile : retorna informações básicas do usuário./notifications : permite receber notificações de usuários não lidas.
Imagine que nosso aplicativo sempre precise receber todos esses dados em uma única unidade, ou seja, idealmente seria bom se, em vez de três pontos de extremidade, tivéssemos apenas um.
No entanto, somos confrontados com muito mais problemas do que muitos pontos de extremidade. Em particular, estamos falando sobre o fato de que os dados que recebemos não parecem da melhor maneira.
Por exemplo, o nó de extremidade
/profile foi criado nos tempos antigos, não foi escrito em JavaScript; como resultado, os nomes das propriedades nos dados retornados parecem incomuns para um aplicativo JS:
{ "Profiles": [ { "id": 1234, "Christian_Name": "David", "Surname": "Gilbertson", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/david.png" ] } ], "Last_Login": "2018-01-01" } ] }
Em geral - nada de bom.
É verdade que, se você observar o que o ponto de extremidade
/notifications produz, os dados acima de
/profile parecerão bastante agradáveis:
{ "data": { "msg-1234": { "timestamp": "1529739612", "user": { "Christian_Name": "Alice", "Surname": "Guthbertson", "Enhanced": "True", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/alice.png" ] } ] }, "message_summary": "Hey I like your hair, it re", "message": "Hey I like your hair, it really goes nice with your eyes" }, "msg-5678": { "timestamp": "1529731234", "user": { "Christian_Name": "Bob", "Surname": "Smelthsen", "Photographs": [ { "Size": "Medium", "URLS": [ "/images/smelth.png" ] } ] }, "message_summary": "I'm launching my own cryptocu", "message": "I'm launching my own cryptocurrency soon and many thanks for you to look at and talk about" } } }
Aqui a lista de mensagens é um objeto, não uma matriz. Além disso, existem dados do usuário aqui, que são tão desconfortavelmente organizados quanto no caso do terminal
/profile . E - eis uma surpresa - a propriedade
timestamp contém o número de segundos desde o início de 1970.
Se eu tivesse que desenhar um diagrama da arquitetura daquele sistema infernalmente inconveniente sobre o qual acabamos de falar, seria semelhante ao mostrado na figura abaixo. A cor vermelha é usada para as partes deste circuito que correspondem a dados mal preparados para trabalhos futuros.
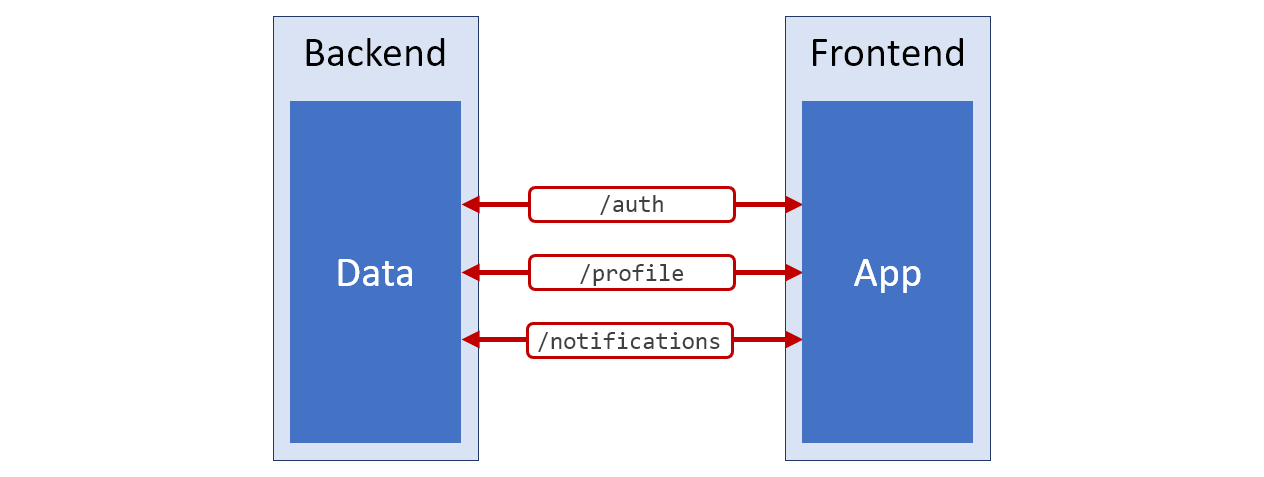 Diagrama do sistema
Diagrama do sistemaNessas circunstâncias, não podemos nos esforçar para corrigir a arquitetura deste sistema. Você pode simplesmente carregar dados dessas três APIs e usar esses dados no aplicativo. Por exemplo, se você precisar exibir o nome de usuário completo na página, precisaremos combinar as propriedades
Christian_Name e
Surname .
Aqui eu gostaria de fazer uma observação sobre nomes. A ideia de dividir o nome completo de uma pessoa em um nome e sobrenome pessoais é característica dos países ocidentais. Se você estiver desenvolvendo algo projetado para uso internacional, tente considerar o nome completo da pessoa como uma sequência indivisível e não faça suposições sobre como dividir essa sequência em partes menores para usar o que aconteceu em locais onde precisa de brevidade ou deseja apelar para o usuário em um estilo informal.
De volta às nossas estruturas de dados imperfeitas. O primeiro problema óbvio que pode ser visto aqui é expresso na necessidade de combinar dados diferentes no código da interface do usuário. Consiste no fato de que talvez seja necessário repetir essa ação em vários lugares. Se você precisar fazer isso apenas ocasionalmente, o problema não será tão sério, mas se você precisar disso com frequência, será muito pior. Como resultado, existem fenômenos indesejáveis causados pela incompatibilidade de como os dados recebidos do servidor são organizados e como eles são usados no aplicativo.
O segundo problema é a complexidade do código usado para formar a interface do usuário. Eu acredito que esse código deve ser, em primeiro lugar, o mais simples possível e, em segundo lugar - o mais claro possível. Quanto mais transformações internas de dados você precisar fazer no cliente, maior será sua complexidade e o código complexo será o local onde os erros geralmente se ocultam.
A terceira questão diz respeito aos tipos de dados. Nos trechos de código acima, você pode ver que, por exemplo, identificadores de mensagens são cadeias de caracteres e identificadores de usuários são números. Do ponto de vista técnico, está tudo bem, mas essas coisas podem confundir o programador. Além disso, veja a apresentação das datas! Mas e a bagunça na parte dos dados relacionada à imagem do perfil? Afinal, tudo o que precisamos é de uma URL que leve ao arquivo correspondente, e não algo a partir do qual teremos que criar essa URL, percorrendo a selva de estruturas de dados aninhadas.
Se processarmos esses dados, passando-os para o código da interface do usuário e analisando os módulos, não poderemos entender imediatamente exatamente com o que estamos trabalhando lá. A conversão da estrutura de dados interna e seu tipo ao trabalhar com eles cria uma carga adicional para o programador. Mas sem todas essas dificuldades, é bem possível fazer isso.
De fato, como opção, seria possível implementar um sistema de tipo estático para resolver esse problema, mas a digitação estrita não é capaz, apenas pelo fato de sua presença, de tornar bons códigos ruins.
Agora que você pode ver a seriedade do problema que estamos enfrentando, vamos falar sobre maneiras de resolvê-lo.
Solução 1: alterando a API do servidor
Se o dispositivo inconveniente da API existente não for ditado por alguns motivos importantes, nada o impedirá de criar uma nova versão que melhor atenda às necessidades do projeto e de localizar essa nova versão, digamos, em
/v2 . Talvez essa abordagem possa ser chamada de solução mais bem-sucedida para os problemas acima. O esquema desse sistema é apresentado na figura abaixo; a estrutura de dados que corresponde perfeitamente às necessidades do cliente é destacada em verde.
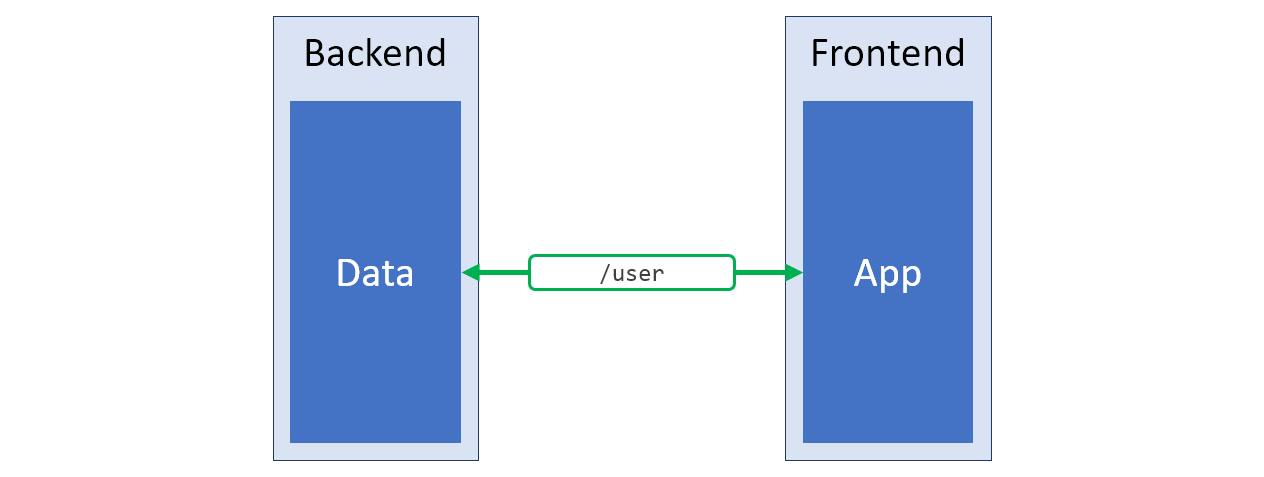 A nova API do servidor que produz exatamente o que o lado do cliente do sistema precisa
A nova API do servidor que produz exatamente o que o lado do cliente do sistema precisaComeçando a desenvolver um novo projeto, cuja API deixa muito a desejar, estou sempre interessado na possibilidade de implementar a abordagem descrita. No entanto, algumas vezes o dispositivo da API, embora inconveniente, tem alguns objetivos importantes, ou alterar a API do servidor simplesmente não é possível. Nesse caso, recorro à seguinte abordagem.
Solução # 2: Padrão BFF
Esse é um bom e velho padrão de BFF (
back-end para o front-end ). Usando esse padrão, você pode abstrair dos intricados pontos de extremidade REST universais e fornecer ao front end exatamente o que ele precisa. Aqui está uma representação esquemática de uma solução desse tipo.
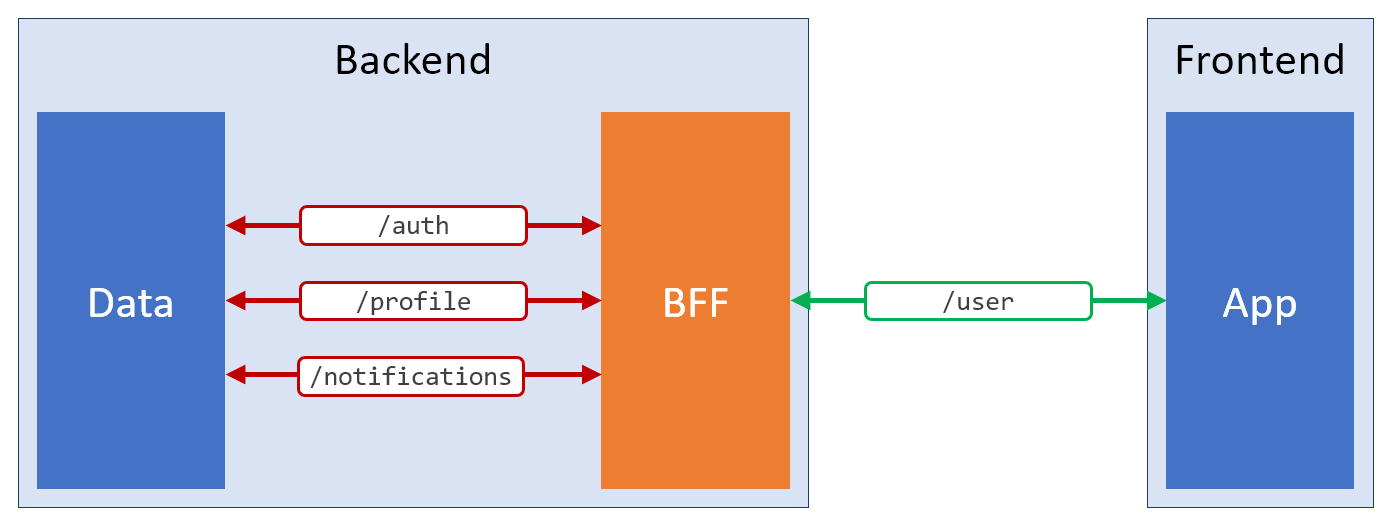 Aplicando o padrão BFF
Aplicando o padrão BFFO significado da existência da camada BFF é satisfazer as necessidades do frontend. Talvez ele use pontos de extremidade REST adicionais, serviços GraphQL, soquetes da Web ou qualquer outra coisa. Seu principal objetivo é fazer todo o possível para a conveniência do lado do cliente do aplicativo.
Minha arquitetura favorita é o NodeJS BFF, usando quais desenvolvedores front-end podem fazer o que precisam, criando ótimas APIs para os aplicativos clientes que desenvolvem. Idealmente, o código correspondente está no mesmo repositório que o código do front-end, o que simplifica o compartilhamento de código, por exemplo, para verificar os dados enviados, tanto no cliente quanto no servidor.
Além disso, isso significa que as tarefas que requerem alterações na parte do cliente do aplicativo e na API do servidor são executadas em um repositório. Um pouco, como eles dizem, mas legal.
No entanto, o BFF nem sempre pode ser usado. E esse fato nos leva a outra solução para o problema do uso conveniente de APIs ruins de servidor.
Solução 3: Padrão BIF
O padrão BIF (back-end no front-end) usa a mesma lógica que pode ser aplicada usando o BFF (combinando várias APIs e limpeza de dados), mas essa lógica se move para o lado do cliente. Na verdade, essa ideia não é nova, poderia ter sido vista vinte anos atrás, mas essa abordagem pode ajudar no trabalho com APIs de servidor mal organizadas, é por isso que estamos falando sobre isso. Aqui está como fica.
 Aplicando o padrão BIF
Aplicando o padrão BIF▍ O que é um BIF?
Como pode ser visto na seção anterior, o BIF é um padrão, isto é, uma abordagem para entender o código e sua organização. Seu uso não leva à necessidade de remover nenhuma lógica do projeto. Apenas separa a lógica de um tipo (modificação de estruturas de dados) da lógica de outro tipo (a formação da interface do usuário). Isso é semelhante à idéia de uma "separação de responsabilidades", que todo mundo está ouvindo.
Aqui eu gostaria de observar que, embora isso não possa ser chamado de desastre, muitas vezes eu tinha que ver implementações analfabetas de BIF. Portanto, parece-me que muitos estarão interessados em ouvir uma história sobre como implementar corretamente esse padrão.
O código BIF deve ser considerado como um código que pode ser usado e transferido para o servidor Node.js. Depois disso, tudo funcionará da mesma maneira que antes. Ou até mesmo transfira-o para um pacote NPM privado, que será usado em vários projetos front-end dentro da estrutura de uma empresa, o que é simplesmente incrível.
Lembre-se de que discutimos acima os principais problemas que surgem ao trabalhar com uma API do servidor com falha. Entre eles, há uma chamada muito frequente para a API e o fato de os dados retornados por eles não atenderem às necessidades do front-end.
Dividiremos a solução de cada um desses problemas em blocos de código separados, cada um dos quais será colocado em seu próprio arquivo. Como resultado, a camada BIF da parte do cliente do aplicativo consistirá em dois arquivos. Além disso, um arquivo de teste será anexado a eles.
▍ Combinando chamadas de API
Fazer muitas chamadas para as APIs do servidor em nosso código de cliente não é um problema tão sério. No entanto, gostaria de abstraí-lo, para possibilitar o atendimento de uma única “solicitação” (do código do aplicativo à camada BIF) e obter exatamente o que é necessário em resposta.
Obviamente, no nosso caso, não há como fazer três solicitações HTTP para o servidor, mas o aplicativo não precisa saber sobre isso.
A API da minha camada BIF é representada como funções. Portanto, quando o aplicativo precisar de alguns dados sobre o usuário, ele chamará a função
getUser() , que retornará esses dados para ele. Aqui está a aparência dessa função:
import parseUserData from './parseUserData'; import fetchJson from './fetchJson'; export const getUser = async () => { const auth = await fetchJson('/auth'); const [ profile, notifications ] = await Promise.all([ fetchJson(`/profile/${auth.userId}`, auth.jwt), fetchJson(`/notifications/${auth.userId}`, auth.jwt), ]); return parseUserData(auth, profile, notifications); };
Aqui, primeiro, é feita uma solicitação ao serviço de autenticação para obter um token, que pode ser usado para autorizar o usuário (não falaremos sobre mecanismos de autenticação aqui, mas nosso principal objetivo é o BIF).
Após receber o token, você pode executar simultaneamente duas solicitações que recebem dados e informações do perfil do usuário sobre notificações não lidas.
A propósito, observe como a construção
async/await é bonita ao trabalhar com ela usando
Promise.all e usando atribuição destrutiva.
Portanto, este foi o primeiro passo, aqui abstraímos o fato de que o acesso ao servidor inclui três solicitações. No entanto, o caso ainda não foi concluído. Ou seja, preste atenção na chamada para a função
parseUserData() , que, como você pode julgar pelo nome, organiza os dados recebidos do servidor. Vamos conversar sobre ela.
▍ Limpeza de dados
Quero dar imediatamente uma recomendação que, acredito, pode afetar seriamente um projeto que anteriormente não possuía uma camada BIF, em particular um novo projeto. Tente não pensar no que você recebe do servidor por um tempo. Em vez disso, concentre-se em quais dados seu aplicativo precisa.
Além disso, é melhor não tentar, ao projetar o aplicativo, levar em consideração suas possíveis necessidades futuras, digamos, relacionadas a 2021. Apenas tente fazer o aplicativo funcionar exatamente como deveria hoje. O fato é que o entusiasmo excessivo pelo planejamento e as tentativas de prever o futuro é o principal motivo da complicação injustificada dos projetos de software.
Então, voltando ao nosso negócio. Agora sabemos como são os dados recebidos das três APIs do servidor e sabemos em que eles devem se transformar após a análise.
Parece que este é um daqueles casos raros em que o uso do TDD realmente faz sentido. Portanto, escreveremos um grande teste longo para a função
parseUserData() :
import parseUserData from './parseUserData'; it('should parse the data', () => { const authApiData = { userId: 1234, jwt: 'the jwt', }; const profileApiData = { Profiles: [ { id: 1234, Christian_Name: 'David', Surname: 'Gilbertson', Photographs: [ { Size: 'Medium', URLS: [ '/images/david.png', ], }, ], Last_Login: '2018-01-01' }, ], }; const notificationsApiData = { data: { 'msg-1234': { timestamp: '1529739612', user: { Christian_Name: 'Alice', Surname: 'Guthbertson', Enhanced: 'True', Photographs: [ { Size: 'Medium', URLS: [ '/images/alice.png' ] } ] }, message_summary: 'Hey I like your hair, it re', message: 'Hey I like your hair, it really goes nice with your eyes' }, 'msg-5678': { timestamp: '1529731234', user: { Christian_Name: 'Bob', Surname: 'Smelthsen', }, message_summary: 'I\'m launching my own cryptocu', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, }, }; const parsedData = parseUserData(authApiData, profileApiData, notificationsApiData); expect(parsedData).toEqual({ jwt: 'the jwt', id: '1234', name: 'David Gilbertson', photoUrl: '/images/david.png', notifications: [ { id: 'msg-1234', dateTime: expect.any(Date), name: 'Alice Guthbertson', premiumMember: true, photoUrl: '/images/alice.png', message: 'Hey I like your hair, it really goes nice with your eyes' }, { id: 'msg-5678', dateTime: expect.any(Date), name: 'Bob Smelthsen', premiumMember: false, photoUrl: '/images/placeholder.jpg', message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about' }, ], }); });
E aqui está o código da própria função:
const getPhotoFromProfile = profile => { try { return profile.Photographs[0].URLS[0]; } catch (err) { return '/images/placeholder.jpg'; // } }; const getFullNameFromProfile = profile => `${profile.Christian_Name} ${profile.Surname}`; export default function parseUserData(authApiData, profileApiData, notificationsApiData) { const profile = profileApiData.Profiles[0]; const result = { jwt: authApiData.jwt, id: authApiData.userId.toString(), // ID name: getFullNameFromProfile(profile), photoUrl: getPhotoFromProfile(profile), notifications: [], // , }; Object.entries(notificationsApiData.data).forEach(([id, notification]) => { result.notifications.push({ id, dateTime: new Date(Number(notification.timestamp) * 1000), // , , , Unix, name: getFullNameFromProfile(notification.user), photoUrl: getPhotoFromProfile(notification.user), message: notification.message, premiumMember: notification.user.Enhanced === 'True', }) }); return result; }
Gostaria de observar que, quando é possível coletar em um local duzentas linhas de código responsáveis pela modificação dos dados espalhados antes disso por todo o aplicativo, isso causa uma sensação maravilhosa. Agora, tudo isso está em um arquivo, testes de unidade são escritos para esse código e todos os momentos ambíguos são fornecidos com comentários.
Eu disse anteriormente que o BFF é minha abordagem favorita para combinar e limpar dados, mas existe uma área em que o BIF é superior ao BFF. Ou seja, os dados recebidos do servidor podem incluir objetos JavaScript que não suportam JSON, como objetos
Date ou
Map (talvez esse seja um dos recursos JavaScript mais subutilizados). Por exemplo, no nosso caso, temos que converter a data que veio do servidor (expressa em segundos, não em milissegundos) em um objeto JS do tipo
Date .
Sumário
Se você acha que seu projeto tem algo em comum com aquele em que examinamos os problemas de APIs malsucedidas, analise seu código fazendo as seguintes perguntas sobre o uso de dados do servidor no cliente:
- Você precisa combinar propriedades que nunca são usadas separadamente (por exemplo, nome e sobrenome do usuário)?
- O código JS precisa trabalhar com nomes de propriedades formados de uma maneira que não seja aceita em JS (algo como PascalCase)?
- Quais são os tipos de dados dos vários identificadores? Talvez às vezes sejam cordas, às vezes números?
- Como as datas são apresentadas no seu projeto? Talvez, às vezes, esses sejam objetos
Date JS prontos para uso na interface e, às vezes, números ou até strings? - Você geralmente precisa verificar as propriedades quanto à existência delas ou se uma entidade é uma matriz antes de começar a enumerar os elementos dessa entidade para formar algum fragmento da interface do usuário com base? Será que essa entidade não será uma matriz, mesmo que vazia?
- Você precisa classificar ou filtrar matrizes ao formar a interface, que, idealmente, já deve ser classificada e filtrada corretamente?
- Se acontecer que, ao verificar as propriedades quanto à sua existência, não há propriedades procuradas, é necessário mudar para usar alguns valores padrão (por exemplo, use a imagem padrão quando não houver foto do usuário nos dados recebidos do servidor)?
- As propriedades são nomeadas de maneira uniforme? Ocorre que a mesma entidade pode ter nomes diferentes, o que é possivelmente causado pelo uso conjunto de APIs de servidor “antigas” e “novas”, relativamente falando?
- Você precisa, juntamente com dados úteis, transferir para algum lugar os dados que nunca são usados, fazendo isso apenas porque são provenientes da API do servidor? Esses dados não utilizados interferem na depuração?
Se você puder responder positivamente a uma ou duas perguntas dessa lista, talvez não deva reparar algo que já funcione corretamente.
No entanto, se você, lendo essas perguntas, descobrir em cada uma delas os problemas do seu projeto, se o dispositivo do seu código é desnecessariamente complicado por causa de tudo isso, se for difícil de perceber e testar, se houver erros difíceis de detectar, dê uma olhada no padrão BIF.
No final, quero dizer que, ao introduzir a camada BIF em aplicativos existentes, as coisas ficam mais fáceis devido ao fato de que isso pode ser feito em etapas, em pequenas etapas. Digamos que a primeira versão da função para a preparação de dados, vamos chamá-la de
parseData() , pode simplesmente, sem alterações, retornar o que vem à sua entrada. Em seguida, você pode mover gradualmente a lógica do código responsável pela criação da interface do usuário para esta função.
Caros leitores! Você encontrou problemas para os quais o autor deste material sugere o uso do padrão BIF?