Em um artigo anterior, descrevi o uso da análise de coorte para determinar os motivos da dinâmica da base de clientes. Hoje é hora de falar sobre truques de preparação de dados para análise de coorte.
É fácil desenhar figuras, mas para que sejam lidas e exibidas corretamente "por baixo do capô", é preciso muito trabalho. Neste artigo, falaremos sobre como implementar a análise de coorte. Vou falar sobre implementação usando o Excel e em outro artigo usando R.
Gostemos ou não, mas de fato o Excel é uma ferramenta de análise de dados. Analistas mais “arrogantes” acreditarão que esta é uma ferramenta fraca e não conveniente. Por outro lado, de fato, centenas de milhares de pessoas fazem análise de dados no Excel e, a esse respeito, vencem facilmente o R / python. Obviamente, quando falamos sobre análise avançada e aprendizado de máquina, trabalharemos em R / python. E eu gostaria que a maioria das análises fosse feita apenas com essas ferramentas. Mas vale a pena reconhecer os fatos, a grande maioria das empresas processa e apresenta dados no Excel, e essa é a ferramenta que analistas comuns, gerentes e proprietários de produtos usam. Além disso, é difícil derrotar o Excel em termos de simplicidade e clareza do processo, porque você domina seus cálculos e modelos literalmente com as mãos.
E assim, como fazemos a análise de coorte no Excel? Para resolver esses problemas, você precisa determinar duas coisas:
Que dados temos no início do processo
Como devem ser nossos dados no final do processo.
Para coletar uma análise de coorte, não precisaremos apenas de dados de volta em datas e divisões. Precisamos de dados no nível do cliente individual. No início do processo, precisamos:
Data do calendário
ID do cliente
Data de registro do cliente
Volume de vendas deste cliente nesta data do calendário
A primeira dificuldade a ser superada é obter esses dados. Se você possui o armazenamento correto, já deve tê-los. Por outro lado, se até agora você implementou apenas o registro de dados sobre o total de vendas por dia, então você só tem dados de clientes em "prod". Para análise de coorte, você precisará implementar o ETL e colocar os dados no contexto dos clientes em seu armazenamento, caso contrário, não terá êxito. E o melhor de tudo, se você separar "prod" e analytics em diferentes bancos de dados, porque As tarefas analíticas e as tarefas de funcionamento do seu produto têm objetivos diferentes: competição por recursos. Os analistas precisam de agregados e cálculos rápidos para muitos usuários; o produto precisa atender rapidamente a um usuário específico. Escreverei um artigo separado sobre organização de armazenamento.
Então você tem dados iniciais:

A primeira coisa que precisamos fazer é transformá-los em "escadas". Para fazer isso, você precisa criar uma tabela dinâmica acima dessa tabela, nas linhas - a data do registro, nas colunas - a data do calendário, como valores - o número de identificação do cliente. Se você extraiu os dados corretamente, deverá obter um triângulo / escada:
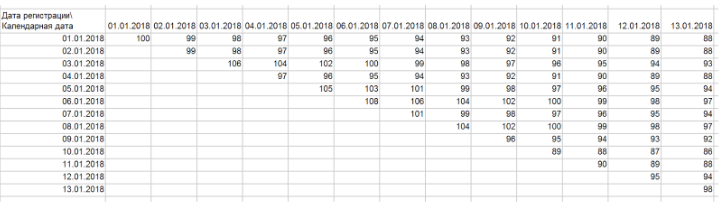
Em geral, uma escada é nosso gráfico de coortes, no qual cada linha exibe a dinâmica de uma coorte separada. Os clientes nesse período movem-se apenas dentro de uma linha. Assim, a dinâmica da coorte reflete o desenvolvimento de relações com um grupo de clientes que chegou em um período de tempo. Freqüentemente, por conveniência e sem perda de qualidade, você pode combinar coortes em "blocos" de linhas. Por exemplo, você pode agrupá-los por semana e mês. Da mesma maneira, você pode agrupar uma coluna também. Talvez o seu ritmo de desenvolvimento de produtos não exija detalhes até dias.
Com base nessa escada, você pode criar um gráfico a partir do meu artigo (eu realmente apontei que havia agrupado várias linhas em uma para que a coorte fosse menor):
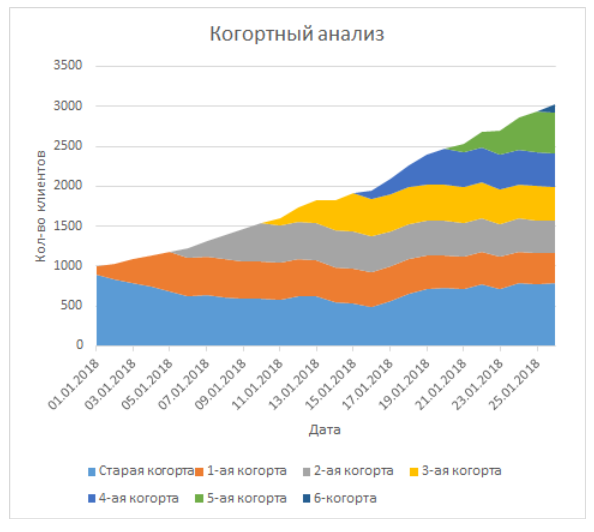
Este é um gráfico com áreas cumulativas em que cada linha é uma linha, horizontalmente de uma data.
Lógica um pouco mais complicada para implementar a programação de "fluxos". Para threads, precisamos fazer alguns cálculos extras. Na lógica do encadeamento, cada cliente chega em diferentes estados:
- Novo - qualquer cliente que tenha uma diferença entre a data de registro e a data do calendário <7 dias
- Reativado - qualquer cliente que não seja mais novo, mas no último mês não gerou receita
- Válido - qualquer cliente que não seja novo, mas tenha gerado receita no mês
- Partiu - qualquer cliente que não gera receita por 2 meses consecutivos
Antes de tudo, você deve corrigir essas definições na empresa para poder implementar corretamente essa lógica e calcular automaticamente os estados. Essas 4 definições têm implicações de longo alcance para o marketing em geral. Suas estratégias para atrair, reter e retornar serão baseadas no estado em que você acha que o cliente está. E se você começar a implementar modelos de aprendizado de máquina na previsão de saídas de clientes, as definições se tornarão sua pedra angular para o sucesso desses modelos. Em geral, escreverei um artigo separado sobre a organização do trabalho e a importância da metodologia analítica. Acima, dei apenas um exemplo do que essas definições podem ser.
No Excel, você precisa criar uma coluna adicional para inserir a lógica descrita acima. No nosso caso, temos que "suar". Temos dois tipos de critérios:
- A diferença entre a data de registro e a data do calendário - cada linha possui esses dados e você só precisa calculá-los (subtrair datas no Excel apenas indica a diferença em dias)
- Dados de receita para o mês atual e o último. Esses dados não estão disponíveis para nós na linha. Além disso, levando em consideração o fato de que o pedido não é garantido em nossa tabela, você não pode dizer exatamente onde possui dados em outros dias do mês para esse cliente.
Existem 2 maneiras de resolver o problema de 2 tipos de critérios:
- Peça para fazer isso no banco de dados. O SQL permite usar a função analítica para calcular para cada cliente o valor da receita para o mês atual e o último (para o mês atual SUM (receita) OVER (PARTITION BY client_id, calendar_month e, em seguida, LAG para obter a compensação do último mês):
- No Excel, você deve implementá-lo assim:
- Para o mês atual: SUMMES (), os critérios serão o ID do cliente e o mês da célula do dia do calendário
- No último mês: SUMMES (), os critérios serão o ID do cliente e o mês da célula do dia do calendário menos exatamente 1 mês do calendário. Nesse caso, chamo a atenção para o fato de que você deve subtrair o mês, e não 30 dias. Caso contrário, você corre o risco de obter uma imagem borrada devido ao número desigual de dias nos meses. Use também a função SE ERRO para substituir valores errados para clientes que não tiveram o mês passado.
Ao adicionar as colunas de receita do mês atual do último mês, você pode criar uma condição incorporada se considerar todos os fatores (a diferença de datas e o valor da receita no mês atual / último mês):
IF (diferença de data <7; "novo";
IF (AND (receita do mês passado = 0; receita do mês atual> 0); "reativação";
IF (AND (receita do último mês> 0; receita do mês atual> 0); "atual"
IF (AND (receita do mês passado = 0; receita do mês atual = 0); "partiu"; "erro"))))
Aqui é necessário "Erro" apenas para controlar que você não se enganou na gravação. A lógica dos critérios de estado do MECE ( https://en.wikipedia.org/wiki/MECE_principle ), ou seja, Se tudo for feito corretamente, cada um deles será afixado em um estado de 4
Você deve obtê-lo assim:

Agora, essa tabela pode ser reconstruída usando uma tabela dinâmica em uma tabela para plotagem. Você precisa transformá-lo em uma tabela:
Data do calendário (colunas)
Estado (linhas)
Número de identificação de clientes (valores em células)
Em seguida, basta criar um diagrama de gráfico de barras com base em dados, com acumulações, no eixo X da data do calendário, linhas são estados, número de clientes é a altura da coluna. Você pode alterar a ordem dos estados no gráfico alterando a ordem das linhas no menu "selecionar dados". Como resultado, obtemos a seguinte imagem:
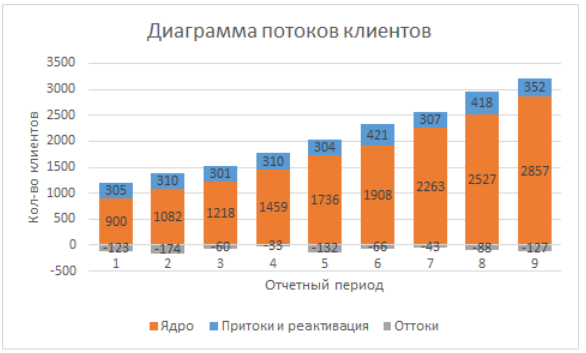
Agora podemos começar a interpretar e analisar.