
O design acadêmico do data warehouse recomenda manter tudo em uma forma normalizada, com conexões entre eles. Em seguida, a reversão de alterações na matemática relacional fornecerá um repositório confiável com suporte a transações. Atomicidade, consistência, isolamento, durabilidade - isso é tudo. Em outras palavras, o repositório é especialmente desenvolvido para atualizar dados com segurança. Mas não é ideal para pesquisa, especialmente com um amplo gesto entre tabelas e campos. Precisa de índices, muitos índices. Os volumes crescem, a gravação diminui. O SQL LIKE não está indexado e JOIN GROUP BY envia-o para o planejador de consultas para meditar.
A carga crescente em uma máquina força a expansão, verticalmente no teto ou horizontalmente, comprando mais alguns nós. Os requisitos de failover distribuem os dados por vários nós. E o requisito de recuperação imediata após uma falha, sem negação de serviço, obriga a configurar o cluster de máquinas para que, a qualquer momento, qualquer uma delas possa executar gravação e leitura. Ou seja, já ser um mestre ou se tornar ele automaticamente e imediatamente.
O problema da pesquisa rápida foi resolvido com a instalação de um segundo repositório otimizado para indexação nas proximidades. Pesquisa de texto completo, facetada, com stemming e blackjack . O segundo armazenamento aceita entradas das tabelas do primeiro como entrada, analisa e cria o índice. Assim, o cluster de armazenamento de dados foi complementado por outro cluster para sua pesquisa. Com uma configuração principal semelhante para corresponder ao SLA geral. Está tudo bem, os negócios estão satisfeitos, os administradores dormem à noite ... até que haja mais de três máquinas no cluster mestre-mestre.
Elástico
O movimento NoSQL expandiu bastante o horizonte de escala para dados pequenos e grandes. Os nós NoSQL do cluster podem distribuir dados entre si para que a falha de um ou mais deles não leve a uma negação de serviço para todo o cluster. O pagamento pela alta disponibilidade dos dados distribuídos foi a incapacidade de garantir sua consistência completa para gravação a qualquer momento. Em vez disso, o NoSQL fala de consistência eventual . Ou seja, acredita-se que um dia todos os dados sejam dispersos para os nós do cluster e eles se tornarão consistentes a longo prazo.
Portanto, o modelo relacional foi complementado pelo modelo não relacional e gerou muitos mecanismos de banco de dados que resolvem os problemas do triângulo da CAP com algum sucesso. Os desenvolvedores chegaram a suas mãos ferramentas modernas para criar sua própria camada de persistência ideal - para todos os gostos, orçamentos e perfis de carga.
O ElasticSearch é um representante do NoSQL agrupado com uma API JSON RESTful no mecanismo Lucene, de código aberto em Java, capaz não apenas de criar um índice de pesquisa, mas também de armazenar o documento original. Essa simulação ajuda a repensar o papel de um DBMS separado para armazenar originais ou até mesmo abandoná-lo. O fim da introdução.
Mapeamento
O mapeamento no ElasticSearch é algo como um esquema (estrutura da tabela, em termos de SQL) que informa exatamente como indexar documentos recebidos (registros, em termos de SQL). O mapeamento pode ser estático, dinâmico ou ausente. O mapeamento estático não permite ser alterado. Dinâmico permite adicionar novos campos. Se o mapeamento não for especificado, o ElasticSearch fará isso sozinho, tendo recebido o primeiro documento para gravação. Ele analisará a estrutura dos campos, fará algumas suposições sobre os tipos de dados neles, pulará as configurações padrão e as anotará. Esse comportamento sem circuito, à primeira vista, parece muito conveniente. Mas, de fato, é mais adequado para experimentação do que para surpresas na produção.
Portanto, os dados são indexados e esse é um processo unidirecional. Uma vez criado, o mapeamento não pode ser alterado dinamicamente como ALTER TABLE no SQL. Como a tabela SQL armazena o documento original no qual você pode fixar o índice de pesquisa. Mas no ElasticSearch o oposto. Ele próprio é o índice de pesquisa no qual você pode fixar o documento original. É por isso que o esquema do índice é estático. Teoricamente, pode-se criar um campo no mapeamento ou excluí-lo. Na prática, o ElasticSearch permite apenas adicionar campos. Uma tentativa de excluir um campo não leva a nada.
Alias
Alias - este é um nome adicional para o índice ElasticSearch. Pode haver vários aliases para um índice. Ou um alias para vários índices. Então os índices são combinados logicamente como se fossem de fora e pareçam um. O alias é muito conveniente para serviços que se comunicam com o índice ao longo de sua vida. Por exemplo, os produtos alternativos podem ocultar products_v2 e products_v25 , sem precisar alterar os nomes no serviço. O alias é indispensável para a migração de dados, quando eles já são transferidos do esquema antigo para o novo, e você precisa mudar o aplicativo para trabalhar com o novo índice. Alternar um alias de índice para índice é uma operação atômica. Ou seja, é realizado em uma etapa sem perda.
Reindexar API
O layout dos dados, mapeamento, tende a mudar de tempos em tempos. Novos campos são adicionados, desnecessários são excluídos. Se o ElasticSearch desempenhar o papel de único repositório, você precisará de algum tipo de ferramenta para alterar o mapeamento em tempo real. Para fazer isso, existe um comando especial para transferir dados de um índice para outro, a chamada API _reindex . Ele trabalha com o mapeamento pronto ou vazio do índice de destinatários, no lado do servidor, indexando rapidamente em lotes de 1000 documentos por vez.
A reindexação pode fazer uma simples conversão de tipo de campo. Por exemplo, texto longo e retorno longo , ou booleano em texto e retorno booleano . Mas -9,99 em booleano não sabe mais como, não é PHP para você . Por outro lado, a conversão de tipo não é segura. Um serviço escrito em um idioma com digitação dinâmica pode ser perdoado por esse pecado. Mas se o reindex não puder converter o tipo, o documento simplesmente não será escrito. Em geral, a migração de dados deve ocorrer em três etapas: adicione um novo campo, libere um serviço com ele, limpe o antigo.
Um campo é adicionado assim. O esquema do índice de origem é adotado, uma nova propriedade é inserida, um índice vazio é criado. Então a reindexação começa:
{ "source": { "index": "test" }, "dest": { "index": "test_clone" } }
O campo é excluído de maneira semelhante. O esquema do índice de origem é utilizado, o campo é removido, um índice vazio é criado. Em seguida, a reindexação é iniciada com uma lista dos campos a serem copiados:
{ "source": { "index": "test", "_source": ["field1", "field3"] }, "dest": { "index": "test_clone" } }
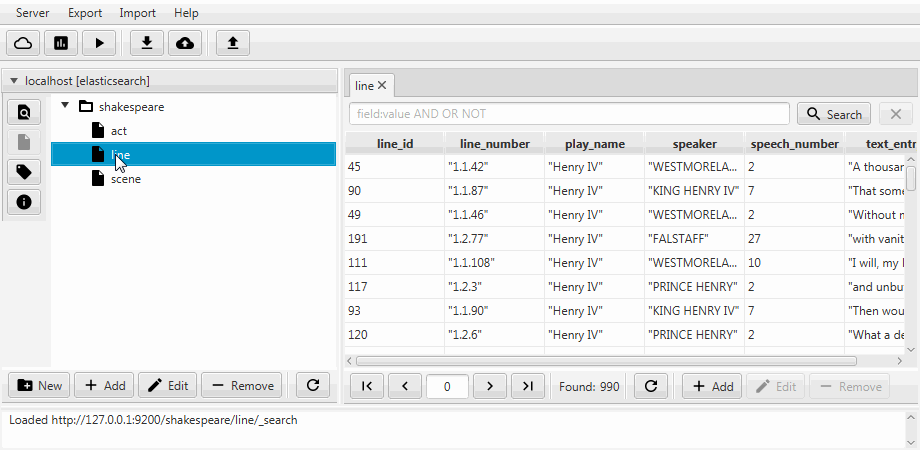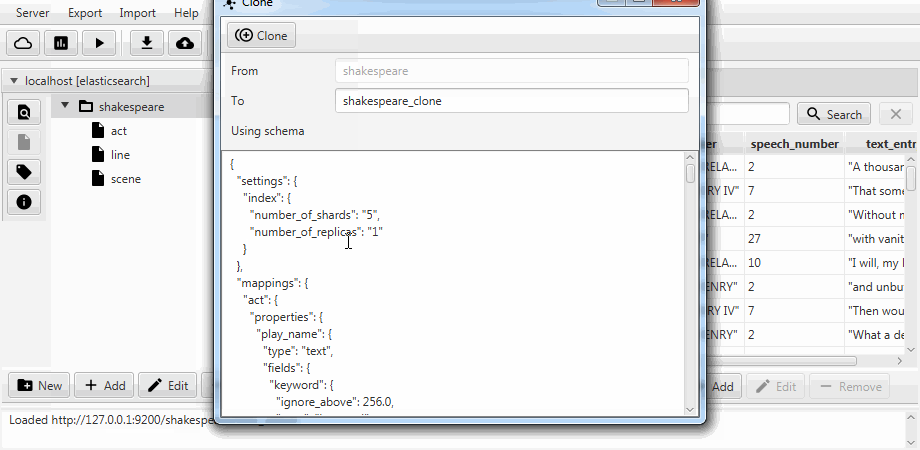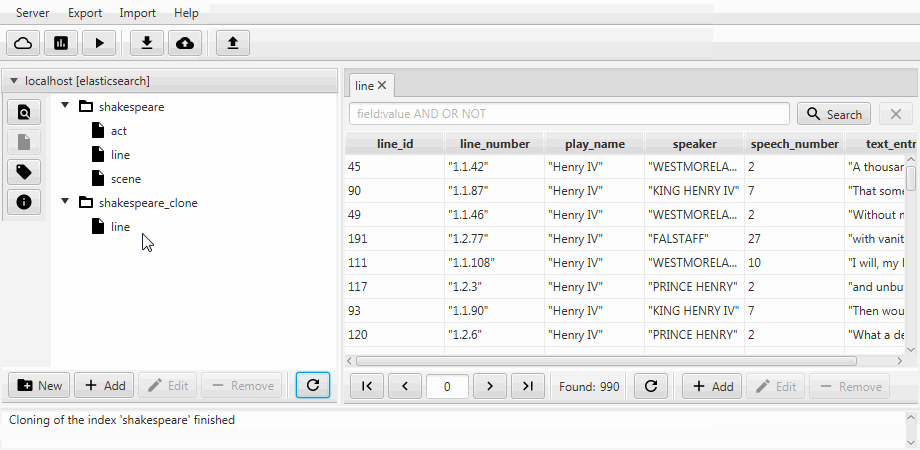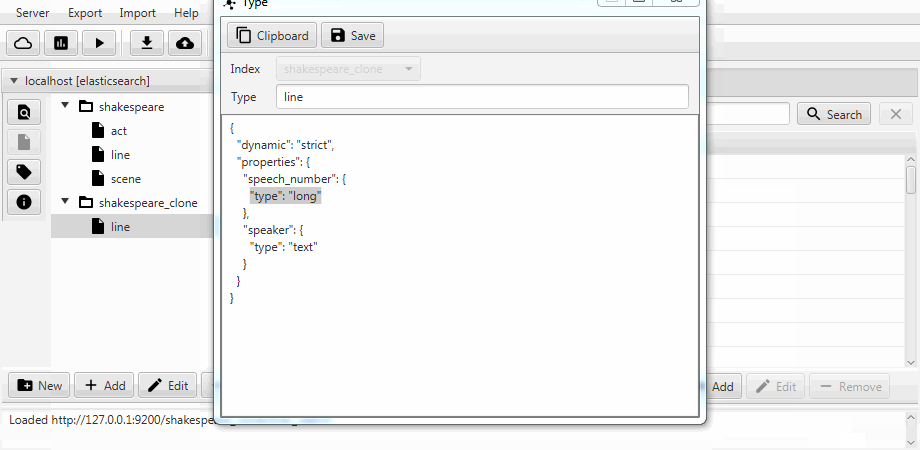
Por conveniência, os dois casos são combinados em uma função de clonagem no Kaizen, um cliente de desktop do ElasticSearch. A clonagem pode se adaptar ao mapeamento do índice de destino. O exemplo abaixo demonstra como fazer um clone parcial de um índice com três coleções (tipos, em termos de ElasticSearch) agir , linha , cena . Somente a linha com dois campos permanece nela, o mapeamento estático é ativado e o campo speech_number do texto se torna longo .
A migração
A API reindex tem um recurso desagradável - não sabe como monitorar alterações no índice de origem. Se algo mudar lá após o início da reindexação, as alterações não serão refletidas no índice de destinatários. Para resolver esse problema, o ElasticSearch FollowUp Plugin foi desenvolvido, o que adiciona comandos de log. O plug-in pode monitorar o índice, retornando no formato JSON as ações executadas nos documentos em ordem cronológica. O índice, tipo, identificador de documento e operação nele - INDEX ou DELETE são lembrados. O Plug-in do FollowUp é publicado no GitHub e compilado para quase todas as versões do ElasticSearch.
Portanto, para a migração sem perda de dados, você precisará do FollowUp instalado no nó em que a reindexação será iniciada. Supõe-se que o índice já tenha um alias e todos os aplicativos funcionem com ele. Antes de reindexar, o plug-in está ativado. Quando a reindexação é concluída, o plug-in é encerrado e o alias é invertido para o novo índice. Em seguida, as ações gravadas são reproduzidas no índice de destinatários, alcançando seu estado. Apesar da alta velocidade de reindexação, dois tipos de colisões podem ocorrer durante a reprodução:
- não há mais um documento com esse _id no novo índice. Eles conseguiram excluir o documento depois de mudar o alias para o novo índice.
- no novo índice, existe um documento com esse _id , mas com um número de versão maior que o índice de origem. Eles conseguiram atualizar o documento depois de mudar o alias para o novo índice.
Nesses casos, a ação não deve ser reproduzida no índice de destino. Outras alterações são reproduzidas.
Feliz codificação!