 Esta é uma história real. Os eventos descritos no post ocorreram em um país quente no século XXI. Por precaução, os nomes dos personagens foram alterados. Por respeito à profissão, tudo é contado como realmente era.
Esta é uma história real. Os eventos descritos no post ocorreram em um país quente no século XXI. Por precaução, os nomes dos personagens foram alterados. Por respeito à profissão, tudo é contado como realmente era.
Oi Habr. Neste post, falaremos sobre o notório teste A / B, infelizmente, mesmo no século 21, ele não pode ser evitado. Opções alternativas de teste existem e florescem online há muito tempo, enquanto as offline precisam se adaptar de acordo com a situação. Falaremos sobre uma dessas adaptações no varejo off-line em massa, experimentando a experiência de trabalhar com um dos principais consultores, em geral, sob o comando cat.
Desafio
 No passado, trabalhei em um projeto em uma grande empresa que possui uma rede de supermercados, mais de 500 lojas. Receio não nomear a empresa, chamaremos esta organização de Empresa. A linha inferior é que as lojas são de tamanhos diferentes, podem variar de tamanho dezenas de vezes; lojas podem estar em diferentes cidades, vilas e aldeias; as lojas podem estar em diferentes áreas da cidade com seus próprios dados demográficos. Aqui, em geral, eu tendem ao fato de que, se você precisar testar alguma hipótese, no paradigma de teste A / B, é quase impossível fazer isso sem causar danos significativos aos negócios. Vamos considerar tudo isso com o exemplo da cerveja. Quando o escritório de consultoria chega à empresa, eles são do alto escalão e dizem: “Mas você sabe, querida, você tem cerveja aqui que não é da marca correta nas vitrines e, geralmente, não na ordem que você precisa, envie-nos um par de ouro Kamaz e informaremos de quais marcas você precisa e como dobrá-las, de acordo com nossas estimativas, isso renderá um bilhão de dólares canadenses no primeiro ano após o piloto ". O escritório é respeitado, portanto não há dúvida de um bilhão. Além disso, os métodos do Instituto não podem ser questionados, pois não podem mentir. Apenas nós não. Em geral, o autor dessas linhas apresenta uma tarefa da forma "bem, veja como eles fazem o piloto, ajude se precisarem de alguma coisa".
No passado, trabalhei em um projeto em uma grande empresa que possui uma rede de supermercados, mais de 500 lojas. Receio não nomear a empresa, chamaremos esta organização de Empresa. A linha inferior é que as lojas são de tamanhos diferentes, podem variar de tamanho dezenas de vezes; lojas podem estar em diferentes cidades, vilas e aldeias; as lojas podem estar em diferentes áreas da cidade com seus próprios dados demográficos. Aqui, em geral, eu tendem ao fato de que, se você precisar testar alguma hipótese, no paradigma de teste A / B, é quase impossível fazer isso sem causar danos significativos aos negócios. Vamos considerar tudo isso com o exemplo da cerveja. Quando o escritório de consultoria chega à empresa, eles são do alto escalão e dizem: “Mas você sabe, querida, você tem cerveja aqui que não é da marca correta nas vitrines e, geralmente, não na ordem que você precisa, envie-nos um par de ouro Kamaz e informaremos de quais marcas você precisa e como dobrá-las, de acordo com nossas estimativas, isso renderá um bilhão de dólares canadenses no primeiro ano após o piloto ". O escritório é respeitado, portanto não há dúvida de um bilhão. Além disso, os métodos do Instituto não podem ser questionados, pois não podem mentir. Apenas nós não. Em geral, o autor dessas linhas apresenta uma tarefa da forma "bem, veja como eles fazem o piloto, ajude se precisarem de alguma coisa".
Depois de ouvir uma breve palestra sobre como funciona sua metodologia para gerar a exibição de mercadorias em uma vitrine, o desejo de entrar nos detalhes do algoritmo desapareceu completamente. Decidi me concentrar na medição da qualidade, o que é muito mais interessante do ponto de vista da teoria. Também permite que a Companhia não invista em projetos deliberadamente não lucrativos. Tendo acesso a universos paralelos, seria possível realizar um teste A / B, onde no universo A tudo está acontecendo como antes, e no universo B o layout das mercadorias mudou. O teste A / B é um tipo de experimento controlado em que os usuários são divididos aleatoriamente em grupos de controle e teste. Uma intervenção é feita no grupo de teste, aguarda um certo tempo, o efeito de tal intervenção nos indicadores-alvo é medido e, finalmente, os indicadores dos dois grupos são comparados. Seria desejável minimizar o viés entre os grupos controle e teste em relação um ao outro. Por exemplo, para que não exista algo que no grupo A existam apenas cidades e no grupo B apenas aldeias. Nos sites, parece que o problema do deslocamento é facilmente resolvido: mostre aos usuários uma versão par com uma identificação e, com uma identificação ímpar, outra versão do site. Em uma situação com uma cadeia de lojas, nem tudo é tão simples, não importa como você quebra usuários ou lojas, sempre acontece que os grupos A e B não são iguais. Esse grupo A chega à loja durante o dia e B à noite. Alinhando o tempo, verifica-se que A aparece nos fins de semana com mais frequência do que B. Alinhando todos esses detalhes, verifica-se que, para resultados estatisticamente significativos, você terá que esperar meio ano e cancelar todas as empresas de marketing. Se você atinge as cidades, acontece que Moscou está presente em um grupo e ausente em outro. Em geral, sempre há uma mudança em um grupo em relação a outro. Várias campanhas de marketing global e local, feriados e circunstâncias imprevistas na forma de reparo de estacionamento são sobrepostas a isso.
Você se lembra que o escritório é do topo dos escritórios mundiais e, naturalmente, tem uma solução para o problema de teste. Considere a metodologia deles, com um nome de marketing alto - a metodologia da diferença tripla.
Metodologia de diferença tripla
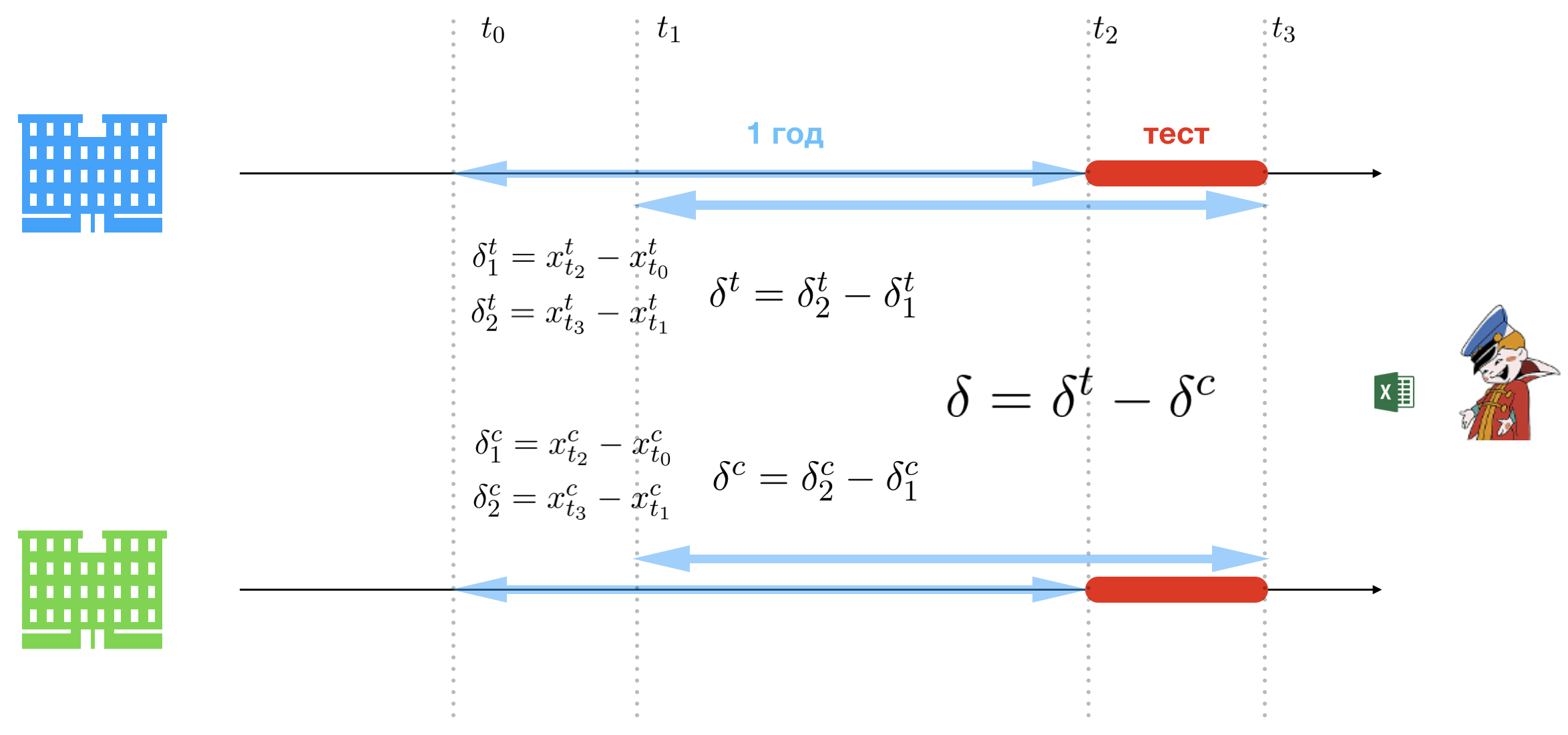
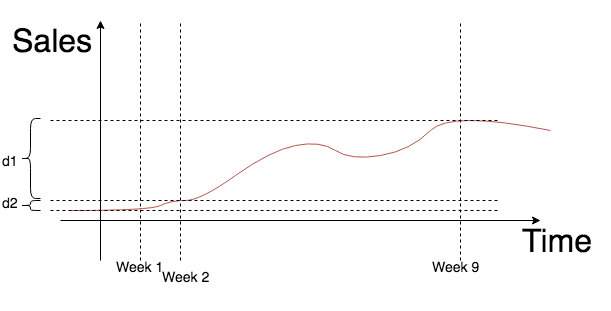
A essência da metodologia da diferença tripla é a simplicidade. E para que os altos da empresa não se esforcem ao ouvir a apresentação, essa apresentação será conduzida por uma dama de aparência ruim. A simplicidade é alcançada relaxando as limitações do teste A / B. A única dificuldade que permanece no caminho do Escritório é a escolha de um grupo de controle e teste, mas omitiremos essa parte do processo, pois não há nada de interessante, exceto um grande conjunto de suposições duvidosas. Portanto, como resultado de uma análise completa da cadeia de lojas existente, o Office seleciona duas: uma para o grupo de controle (verde) e outra para o grupo de teste (azul).
Introduzimos a seguinte notação:
- : data de início do piloto;
- : data final do piloto;
- : data correspondente à data em que o piloto começou no ano passado;
- : data correspondente ao último ano do piloto.
Assim, temos dois períodos de tempo:
- : período do piloto (período do experimento);
- : período correspondente ao período do piloto no ano passado.
Propõe-se comparar a renda da loja de teste e o período de controle entre os períodos do piloto e um ano atrás. Para fazer isso, você precisa contar três grupos de diferenças. Indicar vendas por dia na loja de teste para e - no controle. O primeiro grupo define a linha de base a partir da qual o crescimento ou declínio das vendas no período piloto será medido:
- : a diferença nas vendas entre o início do piloto e a mesma data de um ano atrás na loja de teste;
- : diferença nas vendas entre o final do piloto e a mesma data de um ano atrás na loja de teste;
- : a diferença nas vendas entre o início do piloto e a mesma data de um ano atrás na loja de controle;
- : a diferença nas vendas entre o final do piloto e a mesma data de um ano atrás na loja de controle.
O segundo grupo de diferenças define o crescimento ou declínio nas vendas no período piloto:
- : diferença nas vendas entre o final do piloto e o início do piloto na loja de teste (ajustado para as datas de um ano atrás);
- : diferença nas vendas entre o final do piloto e o início do piloto na loja de controle (ajustado para as datas de um ano atrás).
E, finalmente, a diferença decisiva determina qual loja funcionou melhor no período piloto:
Bem, a decisão de implementar um projeto com o custo do ouro KAMAZ é muito simples se - significa que a loja de teste vendeu mais cerveja; portanto, a metodologia do Office funciona e produz um efeito positivo; portanto, ela precisa ser introduzida. Só isso.
Teste A / B com linha de base ML
Depois de estudar a metodologia da diferença tripla e descobrir que as autoridades já aprovaram esse método de medição e o piloto começou a planejar, minha mão me bateu dolorosamente na cara. Acontece que o escritório nos oferece o investimento de ouro KAMAZ no projeto, mesmo que a metodologia não funcione, e a diferença nas vendas foi de 1 rublo, por acaso. Era urgente desenvolver algo que desse ao menos alguma confiança na eficácia da nova maneira de colocar cerveja na prateleira. Como você se lembra, uma das maneiras de realizar um teste A / B honesto offline é a existência de universos paralelos; em um, podemos introduzir a metodologia de cálculo da cerveja; no segundo, deixamos tudo como está, espere um pouco e compare os resultados. Mas e se simularmos universos paralelos com aprendizado de máquina?

Suponha que tenhamos uma série temporal de vendas diárias para cada loja. A linha sólida cinza divide os períodos
antes e
depois do piloto . A área entre a linha cinza sólida e a linha cinza tracejada é o período em que os compradores se adaptam ao novo mix de produtos e às novas marcas. Nesse período, os dados de vendas não afetam o resultado do teste e são simplesmente ignorados. Vermelho sólido é a venda real de qualquer loja no período anterior ao piloto. No lado direito, há uma combinação de lojas de teste e controle. A linha tracejada verde é a previsão de vendas de qualquer loja, usando apenas os dados disponíveis no período anterior ao início do piloto.
- A linha vermelha é a venda real da loja de controle no período após o lançamento do piloto. Para lojas do grupo controle, no período após o início do piloto, observamos apenas a previsão de vendas (verde intermitente) e as vendas reais (vermelho intermitente).
- Azul sólido são as vendas reais da loja do grupo de teste no período após o lançamento do piloto. Nas lojas de teste, observamos apenas a previsão de vendas (verde intermitente) e as vendas reais (azul sólido).
A linha tracejada verde é a linha base do aprendizado de máquina.
Se o piloto tiver êxito, ou seja, Como a intervenção de teste na forma de um sortimento atualizado e um novo layout tem um efeito positivo nas vendas diárias, as vendas reais nas lojas de teste (azul sólido) serão mais altas, em média, do que as vendas reais nas lojas de controle (vermelho intermitente).
Vamos ver o que isso significa, em média. Para isso, temos que fazer uma suposição, assumimos que os erros de previsão do modelo têm uma distribuição normal:
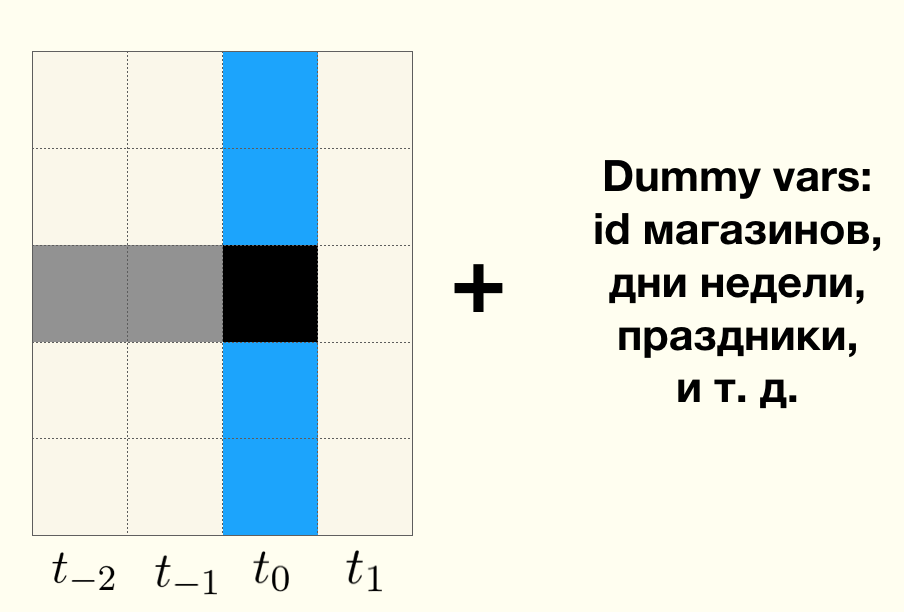 Vamos adicionar mais uma suposição ousada, digamos que as vendas na categoria em que estamos interessados hoje dependem linearmente das vendas em categorias relacionadas hoje e das vendas na categoria em que estamos interessados ontem e no passado recente, e você também pode atribuir vários metadados da loja a isso para levar em conta preconceitos na demografia e outros atributos.
Vamos adicionar mais uma suposição ousada, digamos que as vendas na categoria em que estamos interessados hoje dependem linearmente das vendas em categorias relacionadas hoje e das vendas na categoria em que estamos interessados ontem e no passado recente, e você também pode atribuir vários metadados da loja a isso para levar em conta preconceitos na demografia e outros atributos.
Acontece que é um modelo muito familiar . Vale ressaltar que a escolha do modelo não é particularmente significativa aqui, é importante que os erros tenham uma distribuição normal, ou outra conhecida, para realizar um teste estatístico da igualdade dos valores médios. Com essas declarações do problema, sempre é possível realizar um teste de normalidade na fase de construção do modelo e, em quase todos os modelos, a distribuição será normal, de acordo com a versão do teste de norma , ela é verificada.
Assim, como modelo preditivo, usei regressão linear, embora esse não seja um requisito obrigatório, e fui guiado pela simplicidade do modelo e pela interpretabilidade. Vale a pena notar que o modelo é preditivo, mas eu o chamaria de explicativo. Como não previmos o futuro, usamos as vendas de categorias relacionadas no mesmo dia, o que é essencialmente um datalik. Em vez disso, estamos tentando explicar as vendas de cerveja hoje pelas vendas na loja como um todo. Isso cria um novo problema para nós - é necessário selecionar cuidadosamente os recursos usados no modelo. Os recursos relacionados às categorias de produtos relacionados podem ser divididos em três grupos:
- um grupo de bens de seu interesse (cerveja light, cerveja escura, zero de cerveja, kvass, talvez até uma baleia amarela), alguns desses sinais formam a variável alvo e outros são completamente excluídos do modelo;
- grupos de mercadorias que provavelmente estão um pouco correlacionados com o grupo-alvo, por exemplo, a história de que as vendas de fraldas e cerveja têm um alto coeficiente de correlação positivo;
- grupos de produtos, que certamente não têm uma correlação significativa com os grupos-alvo, esse é um método de regularização antes mesmo da criação do modelo, e haverá uma grande tentação de adicionar tudo ao segundo grupo, por precaução.
Como variáveis explicativas, adicionamos características do segundo grupo ao modelo. A idéia é que assumimos que as mudanças nas vendas no segundo grupo como um todo tenham um efeito significativo no primeiro e as mudanças nas vendas no primeiro grupo não tenham um efeito especial no segundo como um todo (o segundo é muito maior e mais variado).
Uma pergunta popular durante a apresentação do método foi a seguinte: e se na loja de teste / controle houver um reparo no estacionamento, o teste será interrompido? A resposta é não. O estacionamento afetará as vendas da loja como um todo, e não especificamente a cerveja, e as vendas de cerveja em nosso país dependem das vendas em outras categorias e, consequentemente, serão gastas junto com todos. Você pode realizar de forma convincente algumas simulações em um retrodat.
Também é importante notar que não testamos o cálculo pelo método A em relação ao cálculo pelo método B, mas testamos o novo comportamento em relação ao antigo . Isso significa que as lojas e o grupo como um todo não devem cancelar nenhuma campanha de marketing planejada usada anteriormente. Por exemplo, se você reduziu o preço da cerveja forte em 2 vezes nos últimos 6 meses, mesmo semanas, continue fazendo isso; se você parar de fazer isso, o comportamento será diferente. Evite apenas realizar novas experiências em lojas selecionadas.
O estágio de construção do modelo também não pode prescindir de armadilhas. Os grupos de teste e controle podem incluir lojas completamente diferentes, e a tarefa do nosso modelo é alinhar todas as lojas, de modo que, para qualquer loja, um erro de previsão aleatória seja centrado em zero (ou igualmente compensado em zero). No início, eu esperava que tivesse que resolver todos os tipos de hiperparâmetros na validação até que o resultado desejado fosse obtido. Porém, com um conjunto suficiente de recursos, isso é alcançado pela primeira vez, o que é interessante, e a variação do erro aleatório também não difere muito de loja para loja. Essa é provavelmente uma das fraquezas do método, pois não há garantia de que essas condições sejam atendidas.  Uma revisão da literatura também não deu nenhum resultado, parece que muitas pessoas usam uma linha de base no aprendizado de máquina, mas em nenhum lugar há algo sobre garantias teóricas. Em geral, após todas essas fraudes, obtemos um modelo treinado em todos os dados em sua totalidade e podemos fazer previsões diárias de vendas para qualquer loja selecionada . E não estamos particularmente preocupados com a precisão, mas apenas se a distribuição de erros para todas as lojas for igualmente tendenciosa (mais agradável, é claro, se não for tendenciosa em relação a zero). E o fato de a variação ser grande, isso afetará apenas o tamanho do conjunto de dados necessário para a significância estatística do resultado do teste (o que significa que, para uma significância estatística a priori e poder estatístico do teste, o número de observações. O necessário para obter esses resultados depende da variação )
Uma revisão da literatura também não deu nenhum resultado, parece que muitas pessoas usam uma linha de base no aprendizado de máquina, mas em nenhum lugar há algo sobre garantias teóricas. Em geral, após todas essas fraudes, obtemos um modelo treinado em todos os dados em sua totalidade e podemos fazer previsões diárias de vendas para qualquer loja selecionada . E não estamos particularmente preocupados com a precisão, mas apenas se a distribuição de erros para todas as lojas for igualmente tendenciosa (mais agradável, é claro, se não for tendenciosa em relação a zero). E o fato de a variação ser grande, isso afetará apenas o tamanho do conjunto de dados necessário para a significância estatística do resultado do teste (o que significa que, para uma significância estatística a priori e poder estatístico do teste, o número de observações. O necessário para obter esses resultados depende da variação )
Vamos voltar ao gráfico acima com linhas vermelhas, verdes e azuis e, finalmente, introduzir o conceito de uma média mais alta ou mais baixa. Para lojas de controle, podemos subtrair das vendas diárias reais (linha tracejada vermelha) as vendas diárias previstas pelo modelo (linha tracejada verde). Como resultado, obtemos uma distribuição normal de erros centrada em zero, portanto nada mudou neles e o modelo, em média, coincide com a realidade. Para lojas do grupo de teste, também subtraímos as vendas diárias reais (linha sólida azul), o modelo de vendas diárias (verde intermitente) e também obtemos uma distribuição normal. Então, se nada mudou, o centro estará em torno de zero; se as vendas tiverem melhorado, elas serão deslocadas para a direita; se pioraram, para a esquerda. É assim que parece nos dados simulados.

E aqui nos encontramos nas condições do teste estatístico usual para a igualdade da média de duas distribuições, e nada nos impede de realizar esse teste. Para o teste estatístico, precisamos saber o seguinte:
- e : escolha a si mesmo ou, se tiver sorte e pessoas instruídas estiverem no marketing, escolhemos junto com elas;
- dispersão: retirada de um retrodat;
- elevador: necessário para testar não apenas a igualdade, mas que o crescimento das vendas no grupo de teste não seja menor que uma certa quantia de dólares canadenses condicionais; não queremos implementar um projeto que valha ouro kamaz, mas, para que seja econômico e não se pague em cem anos, não estamos construindo uma ponte para a Crimeia.
Esses dados serão suficientes para calcular o número de dias necessário para o piloto. Outro bônus para essa abordagem é a escalabilidade. No nosso caso, o teste deu 60 dias, ou seja, precisamos de observações de 60 dias para o teste e de 60 dias para o grupo controle para obter resultados estatisticamente significativos. Podemos escolher uma loja em cada grupo e esperar 2 meses, ou duas em cada grupo, esperar 1 mês e assim por diante. Naturalmente, o orçamento do experimento depende da adição de novas lojas ao grupo de teste, mas esta é sua tarefa de escolher esse equilíbrio. Eu recomendo que você estude este material para entender a metodologia para calcular o número necessário de observações.
Dados reais
Considere duas imagens com vendas reais, o modelo é treinado em vários anos de retro-venda. Loja número um:
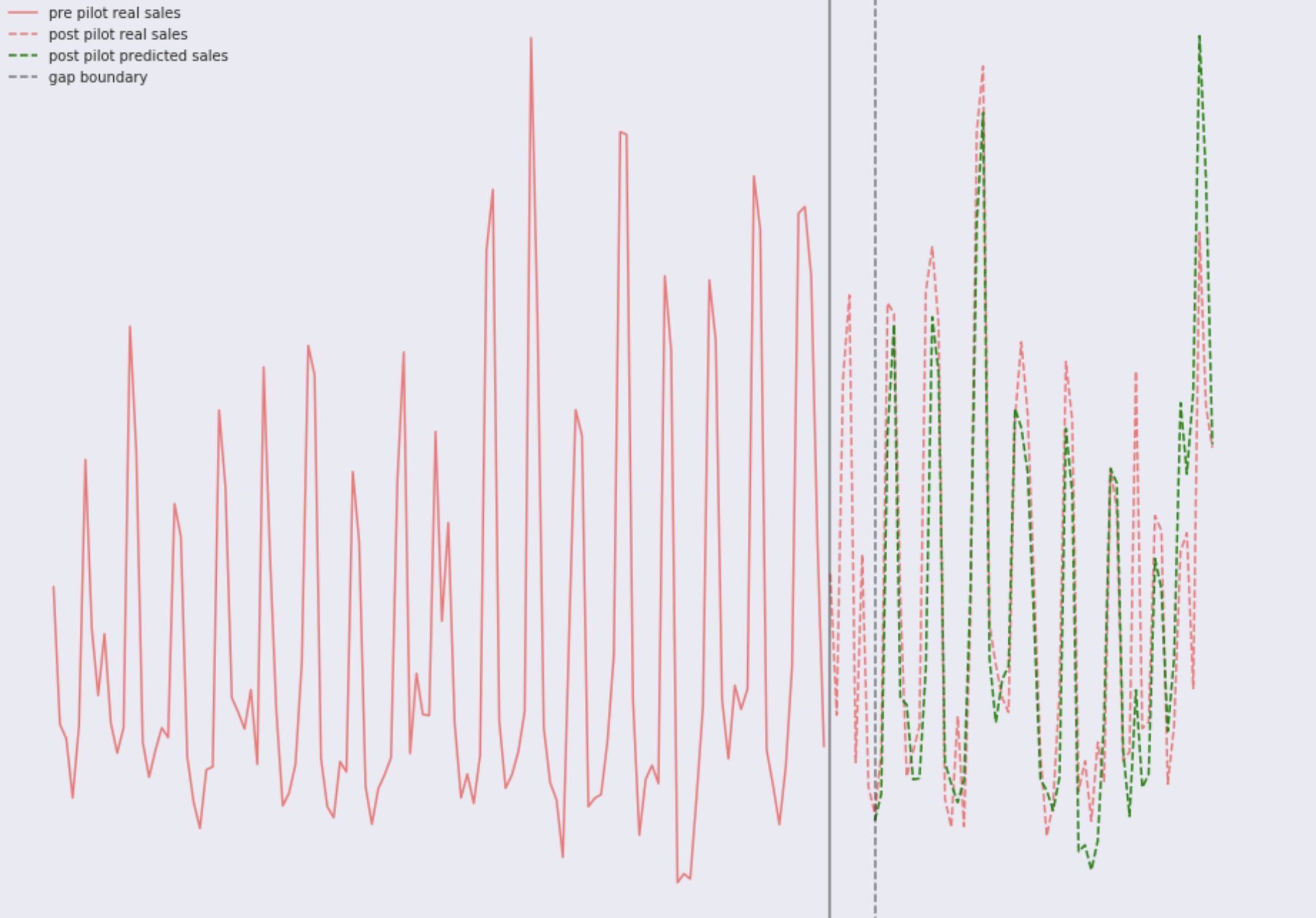
E armazene o número dois:

Como você pode ver
, tudo está muito bem
nos olhos . Você perceberá facilmente padrões semanais, bem como algo claramente aconteceu recentemente em uma das lojas, a dinâmica mudou. Se você observar com atenção, poderá ver que o modelo nas duas lojas várias vezes comete um erro significativo. Nesse caso, existem duas opções:
:
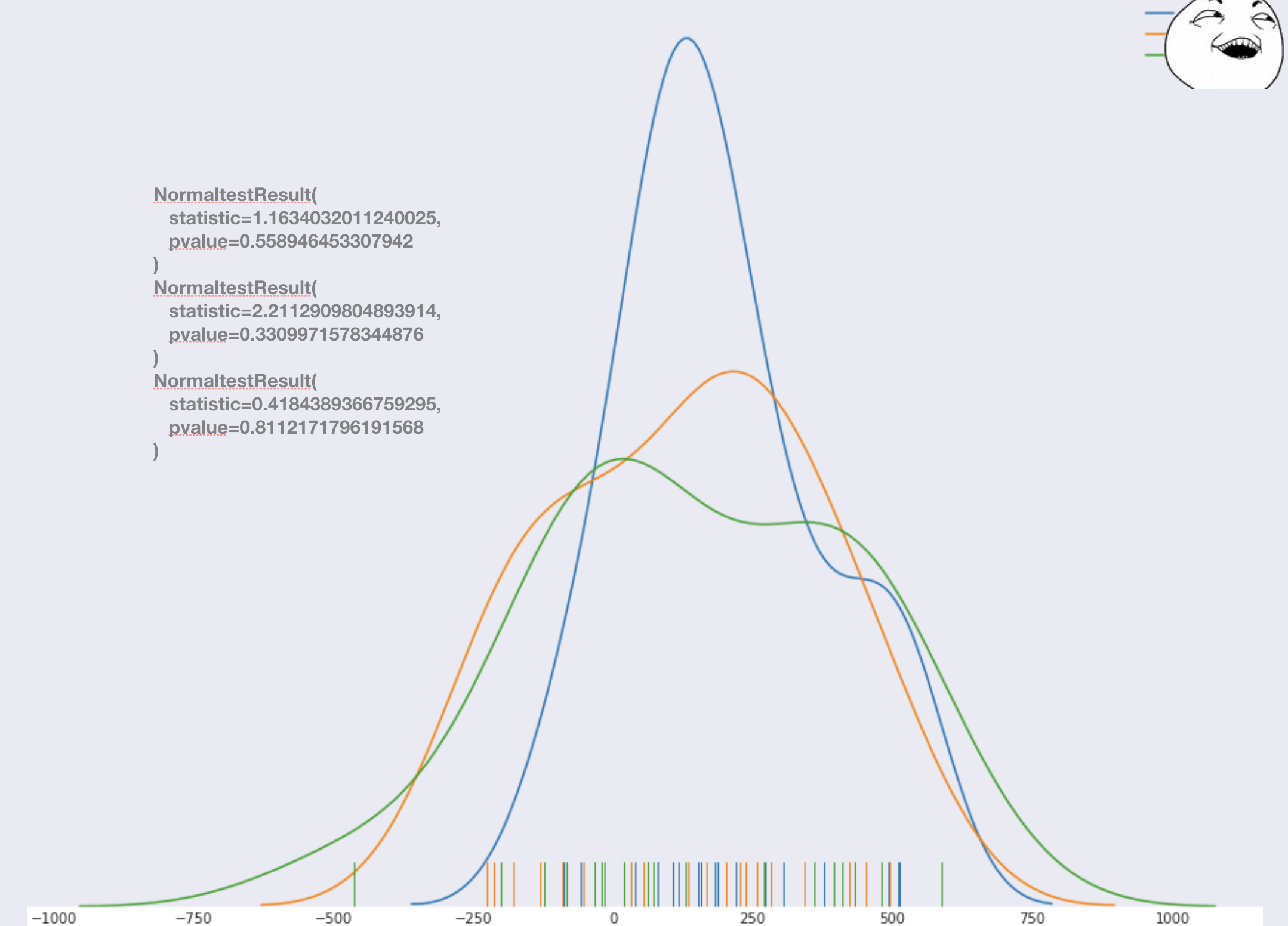 Parece bom . Para obter credibilidade, você pode realizar um teste de normalidade e garantir que está tudo bem . Se algum teste produzir resultados anormais, marque ou reverta para o ponto de seleção do recurso. Nesse caso, não precisamos reiniciar o piloto, mas apenas reconstruir o modelo e recontar os números (com antecedência, você poderá incluir um pouco mais de dias no período de teste do que a primeira versão do modelo). No nosso caso, tudo estava como deveria.
Parece bom . Para obter credibilidade, você pode realizar um teste de normalidade e garantir que está tudo bem . Se algum teste produzir resultados anormais, marque ou reverta para o ponto de seleção do recurso. Nesse caso, não precisamos reiniciar o piloto, mas apenas reconstruir o modelo e recontar os números (com antecedência, você poderá incluir um pouco mais de dias no período de teste do que a primeira versão do modelo). No nosso caso, tudo estava como deveria.Em seguida, combinamos todas as lojas do grupo de teste em um grupo e todas as lojas do controle em um grupo, para que possamos fazê-lo, e assumimos acima que o erro do modelo é igualmente tendencioso para qualquer loja. Temos duas distribuições e realizamos um teste estatístico.
 Como você deve ter adivinhado, de acordo com meu ceticismo desde o início, a nova metodologia exclusiva para exibição de produtos e seleção de marcas não teve efeito estatisticamente significativo nas vendas. Isso, em princípio, era esperado, desde que vi a metodologia para escolher novas marcas e a maneira como elas são exibidas. Receio não poder falar sobre essas técnicas únicas, mas um dos fotógrafos que foi aos concorrentes para tirar uma foto de uma vitrine com uma cerveja recebida ... foi rudemente expulso das instalações.
Como você deve ter adivinhado, de acordo com meu ceticismo desde o início, a nova metodologia exclusiva para exibição de produtos e seleção de marcas não teve efeito estatisticamente significativo nas vendas. Isso, em princípio, era esperado, desde que vi a metodologia para escolher novas marcas e a maneira como elas são exibidas. Receio não poder falar sobre essas técnicas únicas, mas um dos fotógrafos que foi aos concorrentes para tirar uma foto de uma vitrine com uma cerveja recebida ... foi rudemente expulso das instalações.Conclusão
— ? , , 1-2 . - , — . , , , , . :
, - , . , , , , . , , , , .
? , , . -, . , .
, , , , . , .