No artigo, falaremos sobre o uso de redes neurais convolucionais para resolver uma tarefa prática de negócios de restaurar um realograma a partir de fotografias de prateleiras com mercadorias. Usando a API de detecção de objetos do Tensorflow, treinaremos o modelo de pesquisa / localização. Melhoraremos a qualidade da pesquisa de pequenos produtos em fotografias de alta resolução usando uma janela flutuante e um algoritmo de supressão não máximo. Na Keras, estamos implementando um classificador de produtos por marca. Paralelamente, compararemos abordagens e resultados com decisões de quatro anos atrás. Todos os dados usados no artigo estão disponíveis para download e o código totalmente funcional está no
GitHub e foi desenvolvido como um tutorial.

1. Introdução
O que é um planograma? O diagrama de layout da exibição de mercadorias no equipamento comercial de concreto da loja.
O que é um realograma? O layout das mercadorias em um equipamento comercial específico existente na loja aqui e agora.
Planograma - como deveria, realograma - o que temos.

Até agora, em muitas lojas, gerenciar o restante dos produtos em prateleiras, prateleiras, balcões e prateleiras é exclusivamente trabalho manual. Milhares de funcionários verificam a disponibilidade dos produtos manualmente, calculam o saldo, verificam a localização com os requisitos. É caro, e os erros são muito prováveis. A exibição incorreta ou a falta de mercadorias levam a vendas mais baixas.
Além disso, muitos fabricantes celebram acordos com varejistas para exibir seus produtos. E como existem muitos fabricantes, entre eles começa a luta pelo melhor lugar na prateleira. Todo mundo quer que seu produto esteja no centro oposto aos olhos do comprador e ocupe a maior área possível. Há necessidade de auditoria contínua.
Milhares de comerciantes se deslocam de loja em loja para garantir que os produtos de sua empresa estejam na prateleira e apresentados de acordo com o contrato. Às vezes são preguiçosos: é muito mais agradável compilar um relatório sem sair de casa do que ir a um ponto de venda. É necessário uma auditoria permanente dos auditores.
Naturalmente, a tarefa de automação e simplificação desse processo foi resolvida por um longo tempo. Uma das partes mais difíceis foi o processamento de imagens: encontrar e reconhecer produtos. E apenas recentemente, essa tarefa foi simplificada tanto que, para um caso específico e de forma simplificada, sua solução completa pode ser descrita em um artigo. É isso que faremos.
O artigo contém um mínimo de código (apenas nos casos em que o código é mais claro que o texto). A solução completa está disponível como um tutorial ilustrado em
notebooks jupyter . O artigo não contém uma descrição da arquitetura das redes neurais, os princípios dos neurônios, as fórmulas matemáticas. No artigo, nós os usamos como uma ferramenta de engenharia, sem entrar muito nos detalhes do seu dispositivo.
Dados e Abordagem
Como em qualquer abordagem orientada a dados, as soluções de redes neurais exigem dados. Você também pode montá-los manualmente: para capturar várias centenas de contadores e marcá-los usando, por exemplo,
LabelImg . Você pode solicitar a marcação, por exemplo, no Yandex.Tolok.
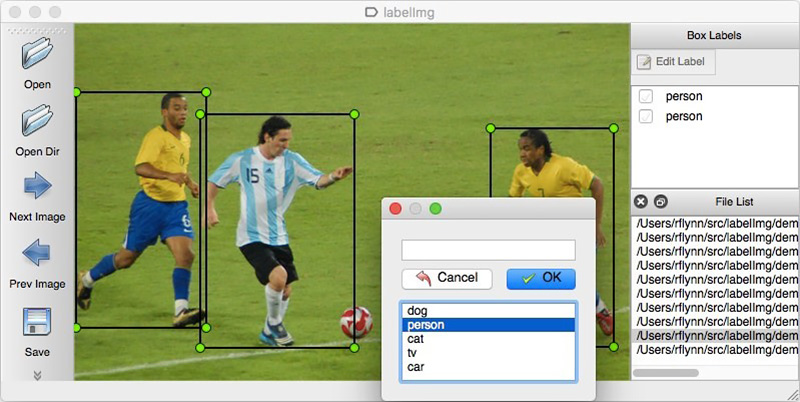
Não podemos divulgar os detalhes de um projeto real; portanto, explicaremos a tecnologia em dados abertos. Fazer compras e tirar fotos era muito preguiçoso (e não teríamos sido compreendidos por lá), e o desejo de fazer a marcação das fotos encontradas na Internet por nós mesmos terminou após o centésimo objeto classificado. Felizmente, por acaso me deparei com o arquivo
Grocery Dataset .
Em 2014, os funcionários da Idea Teknoloji, Istambul, Turquia carregaram 354 fotos de 40 lojas feitas em 4 câmeras. Em cada uma dessas fotografias, destacaram com retângulos um total de vários milhares de objetos, alguns dos quais foram classificados em 10 categorias.
São fotos de maços de cigarro. Não promovemos ou promovemos o tabagismo. Simplesmente não havia nada mais neutro. Prometemos que em todo o artigo, onde a situação permitir, usaremos fotografias de gatos.

Além das fotos marcadas das prateleiras, eles escreveram um artigo
Em direção ao reconhecimento de produtos de varejo nas prateleiras dos supermercados, com uma solução para o problema de localização e classificação. Isso definiu um tipo de ponto de referência: nossa solução, usando novas abordagens, deve se tornar mais simples e precisa, caso contrário, não é interessante. Sua abordagem consiste em uma combinação de algoritmos:
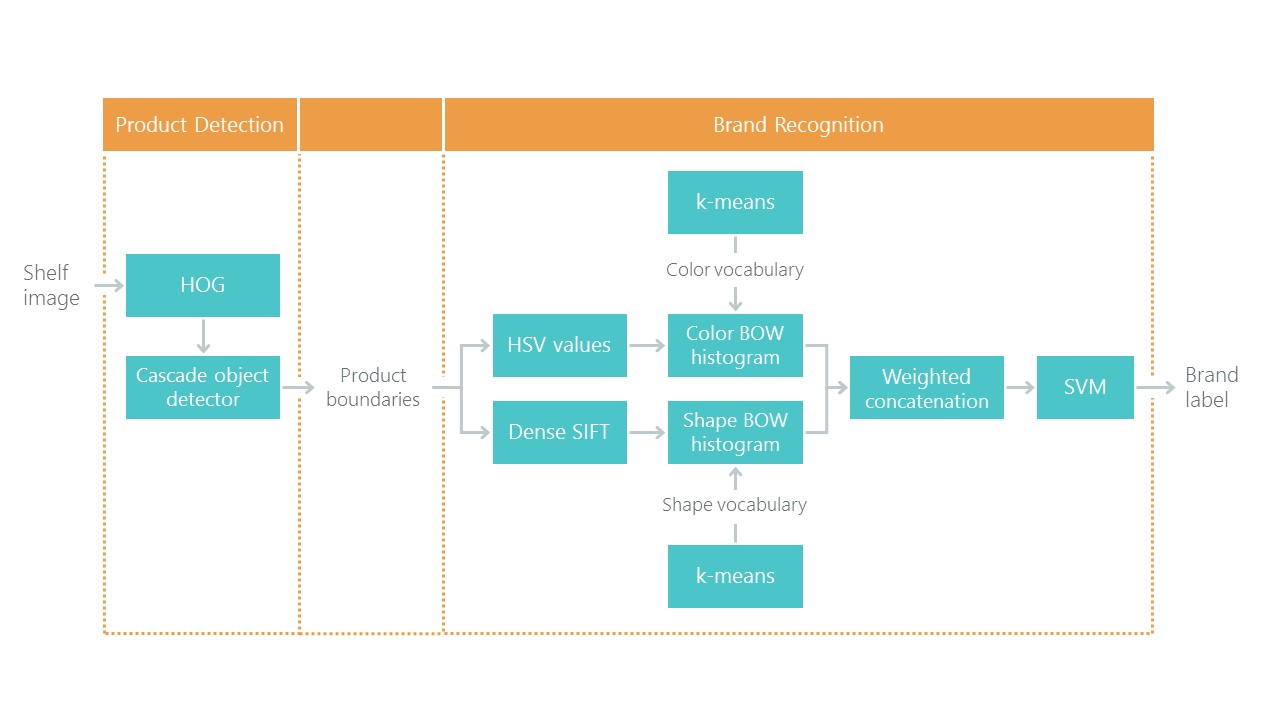
Recentemente, as redes neurais convolucionais (CNNs) revolucionaram o campo da visão computacional e mudaram completamente a abordagem para resolver esses problemas. Nos últimos anos, essas tecnologias tornaram-se disponíveis para uma ampla gama de desenvolvedores, e APIs de alto nível como Keras reduziram significativamente seu limite de entrada. Agora, quase todo desenvolvedor pode usar todo o poder das redes neurais convolucionais após apenas alguns dias de namoro. O artigo descreve o uso dessas tecnologias usando um exemplo, mostrando como uma cascata inteira de algoritmos pode ser facilmente substituída por apenas duas redes neurais sem perda de precisão.
Vamos resolver o problema em etapas:
- Preparação de dados. Nós extraímos os arquivos e o transformamos em uma visualização conveniente para o trabalho.
- Classificação da marca. Resolvemos o problema de classificação usando uma rede neural.
- Pesquise produtos na foto. Treinamos a rede neural para procurar mercadorias.
- Pesquisa de implementação. Melhoraremos a qualidade da detecção usando uma janela flutuante e um algoritmo para suprimir valores não máximos.
- Conclusão Explique brevemente por que a vida real é muito mais complicada do que este exemplo.
Tecnologia
As principais tecnologias que usaremos: Tensorflow, Keras, API de detecção de objetos de Tensorflow, OpenCV. Embora o Windows e o Mac OS sejam adequados para trabalhar com o Tensorflow, ainda recomendamos o uso do Ubuntu. Mesmo que você nunca tenha trabalhado com este sistema operacional antes, usá-lo economizará muito tempo. Instalar o Tensorflow para funcionar com a GPU é um tópico que merece um artigo separado. Felizmente, esses artigos já existem. Por exemplo,
Instalando o TensorFlow no Ubuntu 16.04 com uma GPU Nvidia . Algumas instruções podem estar desatualizadas.
Etapa 1. Preparando os dados ( link do github )Esta etapa, via de regra, leva muito mais tempo do que a simulação em si. Felizmente, usamos dados prontos, que convertemos para o formulário que precisamos.
Você pode baixar e descompactar desta maneira:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Temos a seguinte estrutura de pastas:
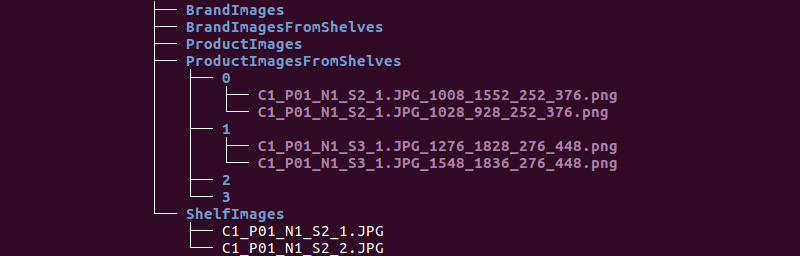
Usaremos as informações dos diretórios ShelfImages e ProductImagesFromShelves.
ShelfImages contém imagens das próprias prateleiras. No nome, o identificador do rack com o identificador da imagem é codificado. Pode haver várias fotos de um rack. Por exemplo, uma fotografia na sua totalidade e 5 fotografias em partes com interseções.
Arquivo C1_P01_N1_S2_2.JPG (rack C1_P01, instantâneo N1_S2_2):

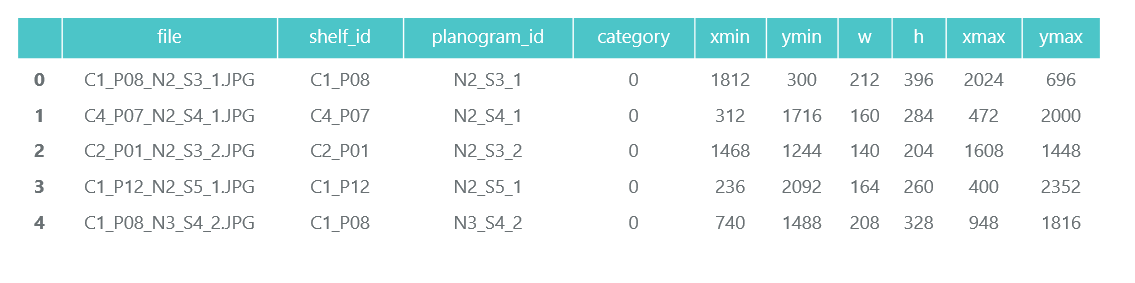
Examinamos todos os arquivos e coletamos informações no quadro de dados do pandas photos_df:
ProductImagesFromShelves contém fotos recortadas de mercadorias das prateleiras em 11 subdiretórios: 0 - não classificado, 1 - Marlboro, 2 - Kent, etc. Para não divulgá-los, usaremos apenas números de categoria sem especificar nomes. Os arquivos nos nomes contêm informações sobre o rack, a posição e o tamanho da embalagem.
Arquivo C1_P01_N1_S3_1.JPG_1276_1828_276_448.png do diretório 1 (categoria 1, rack C1_P01, imagem N1_S3_1, coordenadas do canto superior esquerdo (1276, 1828), largura 276, altura 448):
Não precisamos das fotografias dos pacotes individuais (iremos cortá-los das fotos das prateleiras) e coletamos informações sobre sua categoria e posição no quadro de dados do pandas products_df:
Na mesma etapa, dividimos todas as nossas informações em duas seções: treinamento para treinamento e validação para o monitoramento do treinamento. Claro, isso não vale a pena fazer em projetos reais. E também não confie em quem faz isso. Você deve pelo menos alocar outro teste para o teste final. Mas mesmo com essa abordagem não muito honesta, é importante não nos enganarmos muito.
Como já observamos, pode haver várias fotos de um rack. Consequentemente, o mesmo pacote pode cair em várias fotos. Portanto, recomendamos que você divida não por fotos e, mais ainda, por pacotes, mas por racks. Isso é necessário para que não aconteça que o mesmo objeto, retirado de ângulos diferentes, acabe no trem e na validação.
Fazemos uma divisão 70/30 (30% dos racks são validados e o restante para treinamento):
Garantiremos que, ao nos separarmos, haja representantes suficientes de cada classe para treinamento e validação:

A cor azul mostra o número de produtos na categoria para validação e laranja para treinamento. A situação não é muito boa com a categoria 3 para validação, mas em princípio existem poucos de seus representantes.
Na fase de preparação dos dados, é importante não cometer erros, pois todo o trabalho posterior se baseia em seus resultados. Ainda cometemos um erro e passamos muitas horas felizes tentando entender por que a qualidade dos modelos é muito medíocre. Já parecia um perdedor das tecnologias da “velha escola”, até que você acidentalmente notou que algumas das fotos originais foram giradas 90 graus e outras foram feitas de cabeça para baixo.
Ao mesmo tempo, a marcação é feita como se as fotos fossem orientadas corretamente. Depois de uma solução rápida, as coisas ficaram muito mais divertidas.
Salvaremos nossos dados em arquivos pkl para uso nas etapas a seguir. Total, temos:
- Um diretório de fotografias de racks e suas peças com feixes,
- Um quadro de dados com uma descrição de cada rack com uma nota sobre se ele se destina ao treinamento,
- Um quadro de dados com informações sobre todos os produtos nas prateleiras, indicando sua posição, tamanho, categoria e marcando se são destinados ao treinamento.
Para verificação, exibimos um rack de acordo com nossos dados:
 Etapa 2. Classificação por marca ( link no github )
Etapa 2. Classificação por marca ( link no github )A classificação de imagens é a principal tarefa no campo da visão computacional. O problema é a “lacuna semântica”: a fotografia é apenas uma grande matriz de números [0, 255]. Por exemplo, 800x600x3 (3 canais RGB).

Por que essa tarefa é difícil:

Como já dissemos, os autores dos dados que usamos identificaram 10 marcas. Essa é uma tarefa extremamente simplificada, pois há muito mais marcas de cigarros nas prateleiras. Mas tudo o que não se enquadra nessas 10 categorias foi enviado para 0 - não classificado:

"
O artigo deles oferece um algoritmo de classificação com uma precisão total de 92%:

O que faremos:
- Vamos preparar os dados para treinamento,
- Treinamos uma rede neural convolucional com a arquitetura ResNet v1,
- Verifique as fotos para validação.
Parece "volumoso", mas apenas usamos o exemplo de Keras "
Treina um ResNet no conjunto de dados CIFAR10 ", retirando dele a função de criar o ResNet v1.
Para iniciar o processo de treinamento, você precisa preparar duas matrizes: x - fotos de pacotes com uma dimensão (número de pacotes, altura, largura, 3) e y - suas categorias com uma dimensão (número de pacotes, 10). A matriz y contém os chamados vetores 1-quentes. Se a categoria de um pacote de treinamento tiver o número 2 (de 0 a 9), isso corresponderá ao vetor [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Uma questão importante é o que fazer com a largura e a altura, porque todas as fotos foram tiradas com diferentes resoluções e distâncias diferentes. Precisamos escolher um tamanho fixo, para o qual possamos trazer todas as nossas fotos dos pacotes. Esse tamanho fixo é um meta-parâmetro que determina como nossa rede neural treinará e funcionará.
Por um lado, quero aumentar esse tamanho o máximo possível para que nem um único detalhe da imagem passe despercebido. Por outro lado, com nossa escassa quantidade de dados de treinamento, isso pode levar a um novo treinamento rápido: o modelo funcionará perfeitamente nos dados de treinamento, mas mal nos dados de validação. Escolhemos o tamanho 120x80, talvez em um tamanho diferente tenhamos um resultado melhor. Função de zoom:
Escale e exiba um pacote para verificação. O nome da marca é difícil de ser lido por uma pessoa, vamos ver como a rede neural lidará com a tarefa de classificação:

Depois de preparar de acordo com a flag obtida na etapa anterior, dividimos as matrizes xey em x_train / x_validation e y_train / y_validation, obtemos:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Os dados são preparados, copiamos a função do construtor de redes neurais da arquitetura ResNet v1 do exemplo de Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
Construímos um modelo:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
Temos um conjunto de dados bastante limitado. Portanto, para impedir que o modelo veja a mesma foto todas as vezes durante o treinamento, usamos o aumento: mude a imagem aleatoriamente e gire-a um pouco. Keras fornece este conjunto de opções para isso:
Iniciamos o processo de treinamento.
Após o treinamento e a avaliação, obtemos precisão na região de 92%. Você pode ter uma precisão diferente: há muito poucos dados; portanto, a precisão depende muito do sucesso da partição. Nesta partição, não obtivemos precisão significativamente maior do que a indicada no artigo, mas praticamente não fizemos nada e escrevemos pouco código. Além disso, podemos adicionar facilmente uma nova categoria, e a precisão deve (em teoria) aumentar significativamente se prepararmos mais dados.
Por interesse, compare matrizes de confusão:
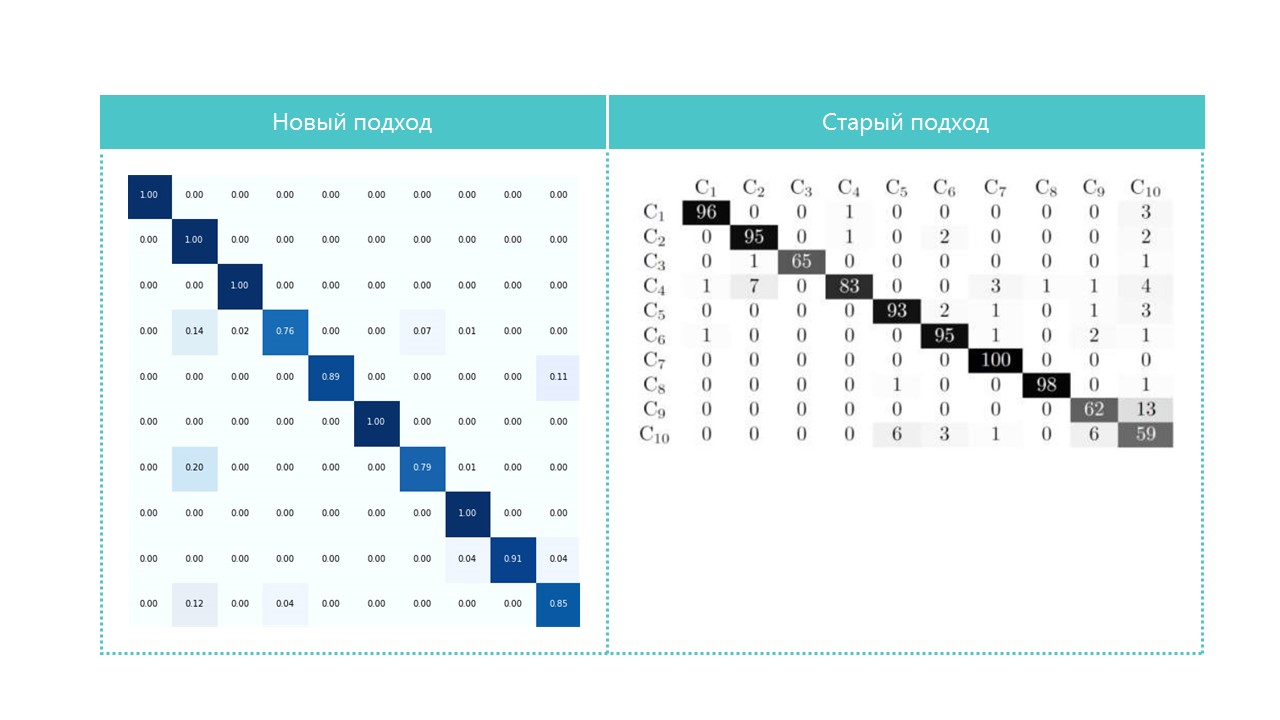
Quase todas as categorias que nossa rede neural define melhor, exceto as categorias 4 e 7. Também é útil observar os representantes mais brilhantes de cada célula da matriz de confusão:
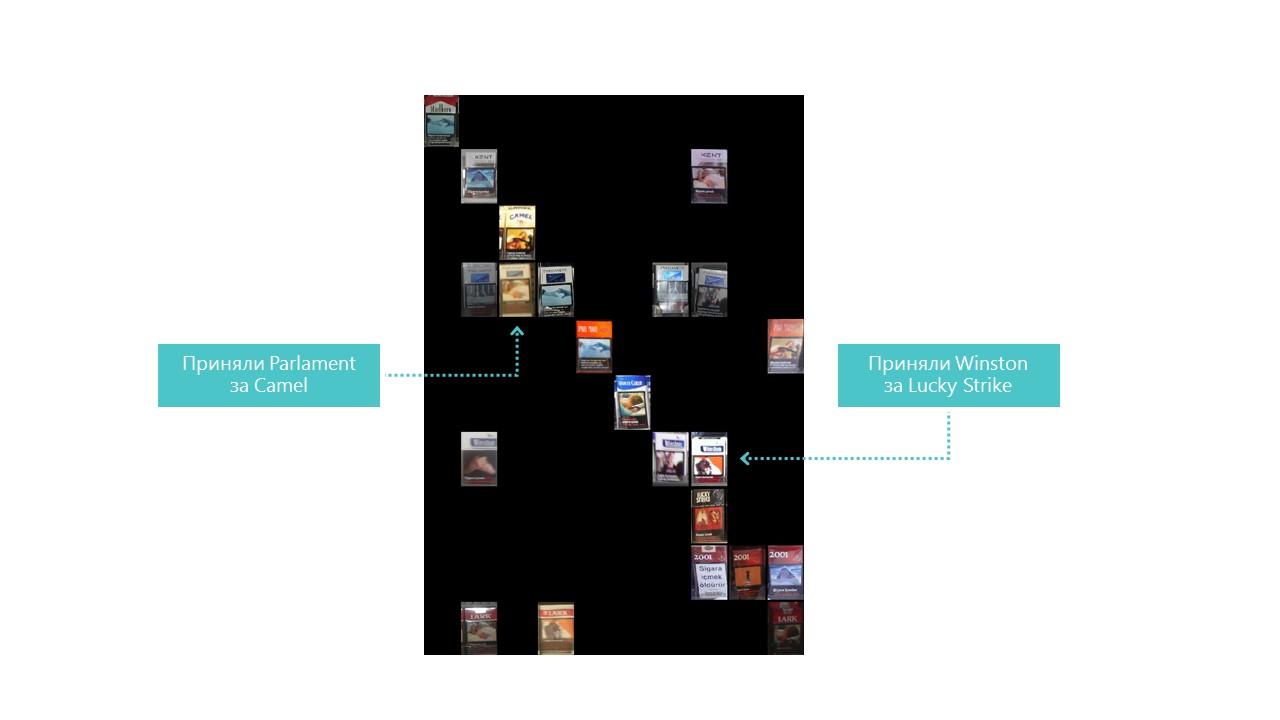
Você também pode entender por que o Parlamento foi confundido com Camel, mas por que Winston foi confundido com Lucky Strike é completamente incompreensível, mas eles não têm nada em comum. Esse é o principal problema das redes neurais - a total opacidade do que está acontecendo lá dentro. É claro que você pode visualizar algumas camadas, mas para nós essa visualização é assim:

Uma oportunidade óbvia para melhorar a qualidade do reconhecimento em nossas condições é adicionar mais fotos.
Então, o classificador está pronto. Vá para o detector.
Etapa 3. Pesquise produtos na foto ( link no github )As seguintes tarefas importantes no campo da visão por computador são segmentação semântica, localização, pesquisa de objeto e segmentação de instância.
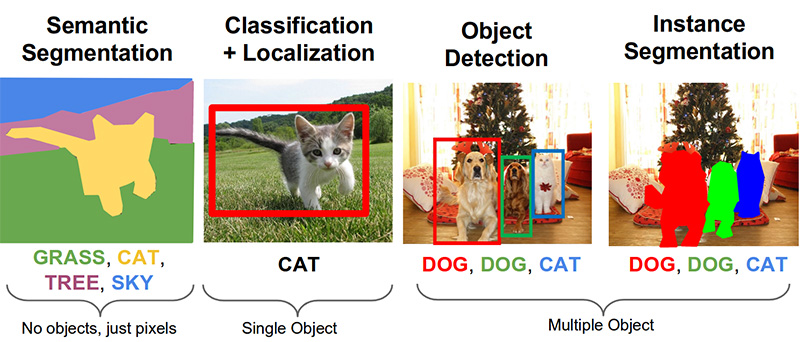
Nossa tarefa precisa de detecção de objetos. O artigo de 2014 oferece uma abordagem baseada no método Viola-Jones e HOG com precisão visual:

Graças ao uso de restrições estatísticas adicionais, sua precisão é muito boa:

Agora, a tarefa de reconhecimento de objetos é resolvida com sucesso com a ajuda de redes neurais. Usaremos o sistema API Tensorflow Object Detection e treinaremos uma rede neural com a arquitetura SSD Mobilenet V1. O treinamento desse modelo a partir do zero requer muitos dados e pode levar dias. Portanto, usamos um modelo treinado em dados COCO de acordo com o princípio da transferência de aprendizado.
O conceito chave dessa abordagem é esse. Por que uma criança não precisa mostrar milhões de objetos para aprender a encontrar e distinguir uma bola de um cubo? Porque a criança tem 500 milhões de anos de desenvolvimento do córtex visual. A evolução fez da visão o maior sistema sensorial. Quase 50% (mas isso não é exato) dos neurônios do cérebro humano são responsáveis pelo processamento da imagem. Os pais só podem mostrar a bola e o cubo e, em seguida, corrigir a criança várias vezes, para que ela encontre e distinga perfeitamente uma da outra.
Do ponto de vista filosófico (com diferenças técnicas mais que gerais), a transferência de aprendizado em redes neurais funciona de maneira semelhante. As redes neurais convolucionais consistem em níveis, cada um dos quais define formas cada vez mais complexas: identifica pontos-chave, combina-os em linhas, que por sua vez se combinam em figuras. E somente no último nível da totalidade dos sinais encontrados determina o objeto.
Objetos do mundo real têm muito em comum. Ao transferir o aprendizado, usamos os níveis de definição de recursos básicos já treinados e treinamos apenas as camadas responsáveis pela identificação dos objetos. Para fazer isso, bastam algumas centenas de fotos e algumas horas de operação de uma GPU comum. A rede foi treinada originalmente no conjunto de dados COCO (Microsoft Common Objects in Context), que possui 91 categorias e 2.500.000 imagens! Muitos, embora não 500 milhões de anos de evolução.
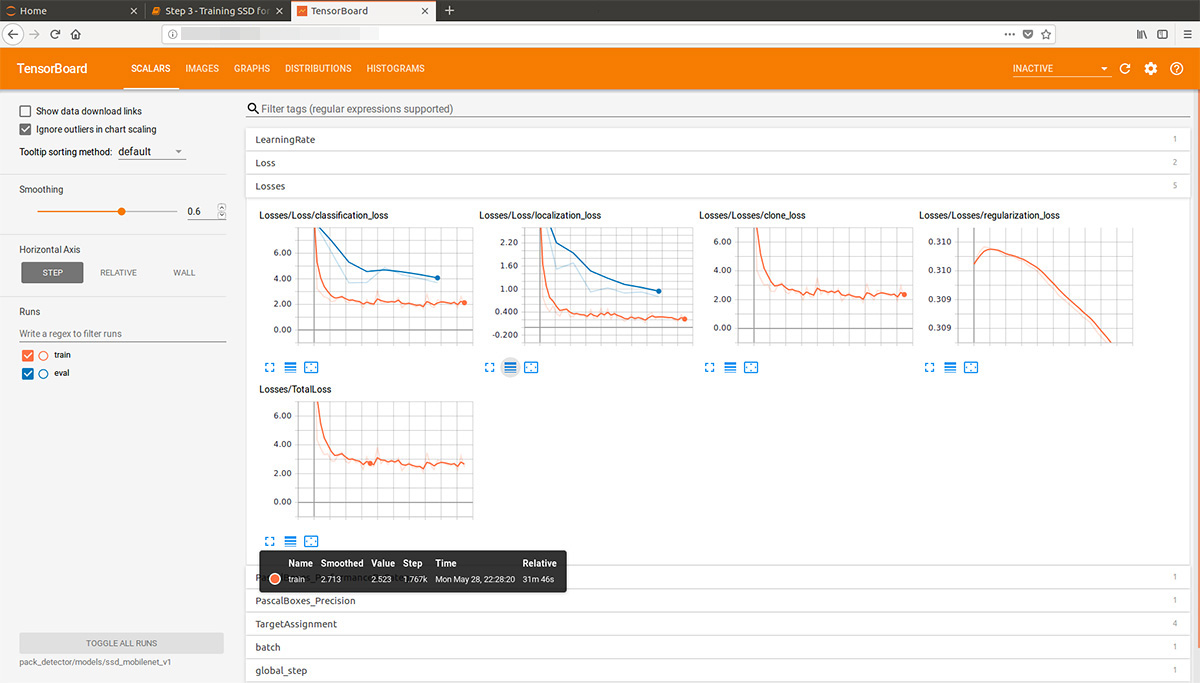
Olhando um pouco à frente, essa animação gif (um pouco lenta, não rola imediatamente) do tensorboard visualiza o processo de aprendizado. Como você pode ver, o modelo começa a produzir um resultado completamente de alta qualidade quase que imediatamente e depois vem a retificação:

O "treinador" do sistema API do Tensorflow Object Detection pode executar aprimoramentos de forma independente, cortar partes aleatórias das imagens para treinamento e selecionar exemplos "negativos" (seções de fotos que não contêm nenhum objeto). Em teoria, não é necessário pré-processamento de fotos. No entanto, em um computador doméstico com um HDD e uma pequena quantidade de RAM, ele se recusou a trabalhar com imagens de alta resolução: no início, ele ficou pendurado por um longo tempo, mexeu em um disco e depois voou para fora.
Como resultado, compactamos as fotos em um tamanho de 1000x1000 pixels, mantendo a proporção. Porém, como ao compactar uma foto grande, muitos sinais são perdidos, primeiro vários quadrados de tamanho aleatório foram cortados de cada foto do rack e compactados em 1000x1000. Como resultado, pacotes em alta resolução (mas não o suficiente) e em pequenos (mas muitos) caíram nos dados de treinamento. Repetimos: esse passo é forçado e, muito provavelmente, completamente desnecessário e possivelmente prejudicial.
As fotos preparadas e compactadas são salvas em diretórios separados (eval e train), e sua descrição (com os pacotes contidos neles) é formada na forma de dois quadros de dados do pandas (train_df e eval_df):
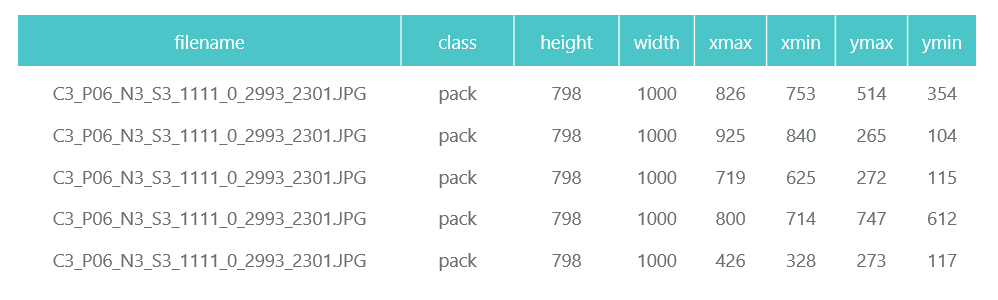
O sistema API do Tensorflow Object Detection exige que a entrada seja apresentada como arquivos tfrecord. Você pode formá-los usando o utilitário, mas vamos torná-lo um código:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Resta preparar um diretório especial e iniciar os processos:
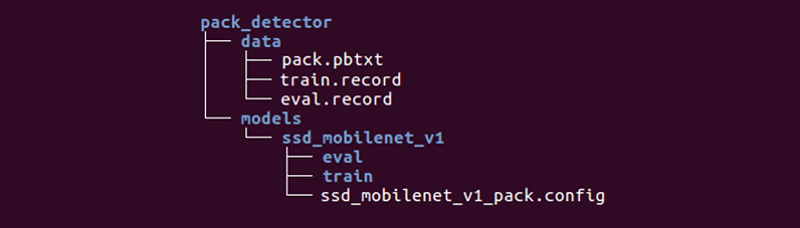
A estrutura pode ser diferente, mas achamos muito conveniente.
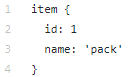
O diretório de dados contém os arquivos que criamos com tfrecords (train.record e eval.record), bem como pack.pbtxt com os tipos de objetos para os quais iremos treinar a rede neural. Como temos apenas um tipo de objeto para definir, o arquivo é muito curto:
O diretório de modelos (pode haver muitos modelos para resolver um problema) no diretório filho ssd_mobilenet_v1 contém as configurações de treinamento no arquivo .config, além de dois diretórios vazios: train e eval. No treinamento, o "treinador" salvará os pontos de controle do modelo, o "avaliador" os buscará, executará os dados para avaliação e os colocará no diretório eval. O Tensorboard acompanhará esses dois diretórios e exibirá as informações do processo.
Descrição detalhada da estrutura dos arquivos de configuração, etc. pode ser encontrado
aqui e
aqui . As instruções de instalação da API de detecção de objetos do Tensorflow podem ser encontradas
aqui .
Entramos no diretório models / research / object_detection e esvaziamos o modelo pré-treinado:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Copiamos o diretório pack_detector preparado por nós lá.
Primeiro, inicie o processo de treinamento:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Iniciamos o processo de avaliação. Como não temos uma segunda placa de vídeo, a inicializamos no processador (usando a instrução CUDA_VISIBLE_DEVICES = ""). Por isso, ele se atrasará no processo de treinamento, mas isso não é tão ruim:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
Iniciamos o processo do tensorboard:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
Depois disso, podemos ver belos gráficos, bem como o trabalho real do modelo nos dados estimados (gif no início):
O processo de treinamento pode ser interrompido e retomado a qualquer momento. Quando acreditamos que o modelo é bom o suficiente, salvamos o ponto de verificação na forma de um gráfico de inferência:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
Portanto, nesta etapa, obtivemos um gráfico de inferência, que podemos usar para procurar objetos de pacote. Passamos ao seu uso.
Etapa 4. Implementando a pesquisa ( link do github )O código de carregamento e inicialização do gráfico de inferência está no link acima. Principais recursos de pesquisa:
A função encontra caixas delimitadas para pacotes não na foto inteira, mas em sua parte. A função também filtra os retângulos encontrados com uma baixa pontuação de detecção especificada no parâmetro de corte.
Isso acaba sendo um dilema. Por um lado, com um ponto de corte alto, perdemos muitos objetos; por outro lado, com um ponto de corte baixo, começamos a encontrar muitos objetos que não são feixes. Ao mesmo tempo, ainda não encontramos tudo e não o ideal:

No entanto, observe que, se executarmos a função para um pequeno pedaço da foto, o reconhecimento será quase perfeito com ponto de corte = 0,9:

Isso ocorre pelo fato de o modelo SSD do MobileNet V1 aceitar fotos de 300x300 como entrada. Naturalmente, com essa compressão, muitos sinais são perdidos.
Mas esses sinais persistem se recortarmos um pequeno quadrado contendo vários pacotes. Isso sugere a idéia de usar uma janela flutuante: percorremos um pequeno retângulo em uma fotografia e lembramos tudo o que encontramos.

: , . . : (detection score), , , overlapTresh ( ):
:

:

, , .
Conclusão
«»: , . , , .. .
, , :
- 150 , , ,
- 3-7 ,
- 100 ,
- ,
- (),
- (, ),
- , «»,
- , , (SSD ),
- , ,
- .
, , .