 Como a tradução de IA pode aprender a gerar imagens de gatos
Como a tradução de IA pode aprender a gerar imagens de gatos .
A pesquisa sobre redes adversas generativas (GAN), publicada em 2014, foi uma inovação no campo dos modelos generativos. O pesquisador principal, Yann Lekun, chamou as redes adversárias de "a melhor idéia em aprendizado de máquina nos últimos vinte anos". Hoje, graças a essa arquitetura, podemos criar uma IA que gera imagens realistas de gatos. Legal!
 DCGAN durante o treinamento
DCGAN durante o treinamentoTodo o código de trabalho está no
repositório do
Github . Será útil se você tiver alguma experiência em programação em Python, aprendizado profundo, trabalho com Tensorflow e redes neurais convolucionais.
E se você é novo no aprendizado profundo, recomendo que você se familiarize com a excelente série de artigos
Machine Learning is Fun!O que é o DCGAN?
As redes adversas generativas convolucionais profundas (DCGAN) são uma arquitetura de aprendizado profundo que gera dados semelhantes aos dados do conjunto de treinamento.
Este modelo substitui por camadas convolucionais as camadas totalmente conectadas da rede adversária generativa. Para entender como o DCGAN funciona, usamos a metáfora do confronto entre um crítico de arte especialista e um falsificador.
O falsificador ("gerador") está tentando criar uma imagem falsa de Van Gogh e transmiti-la como uma imagem real.
Um crítico de arte ("discriminador") está tentando condenar um falsificador, usando seu conhecimento das telas reais de Van Gogh.
Com o tempo, o crítico de arte está cada vez mais definindo falsificações, e o falsificador as torna mais perfeitas.
 Como você pode ver, os DCGANs são compostos por duas redes neurais de aprendizado profundo separadas que competem entre si.
Como você pode ver, os DCGANs são compostos por duas redes neurais de aprendizado profundo separadas que competem entre si.- O gerador está tentando criar dados confiáveis. Ele não sabe quais são os dados reais, mas aprende com as respostas da rede neural inimiga, alterando os resultados de seu trabalho a cada iteração.
- O discriminador tenta determinar os dados falsos (comparando com os reais), evitando o máximo possível de falsos positivos em relação aos dados reais. O resultado desse modelo é o feedback para o gerador.
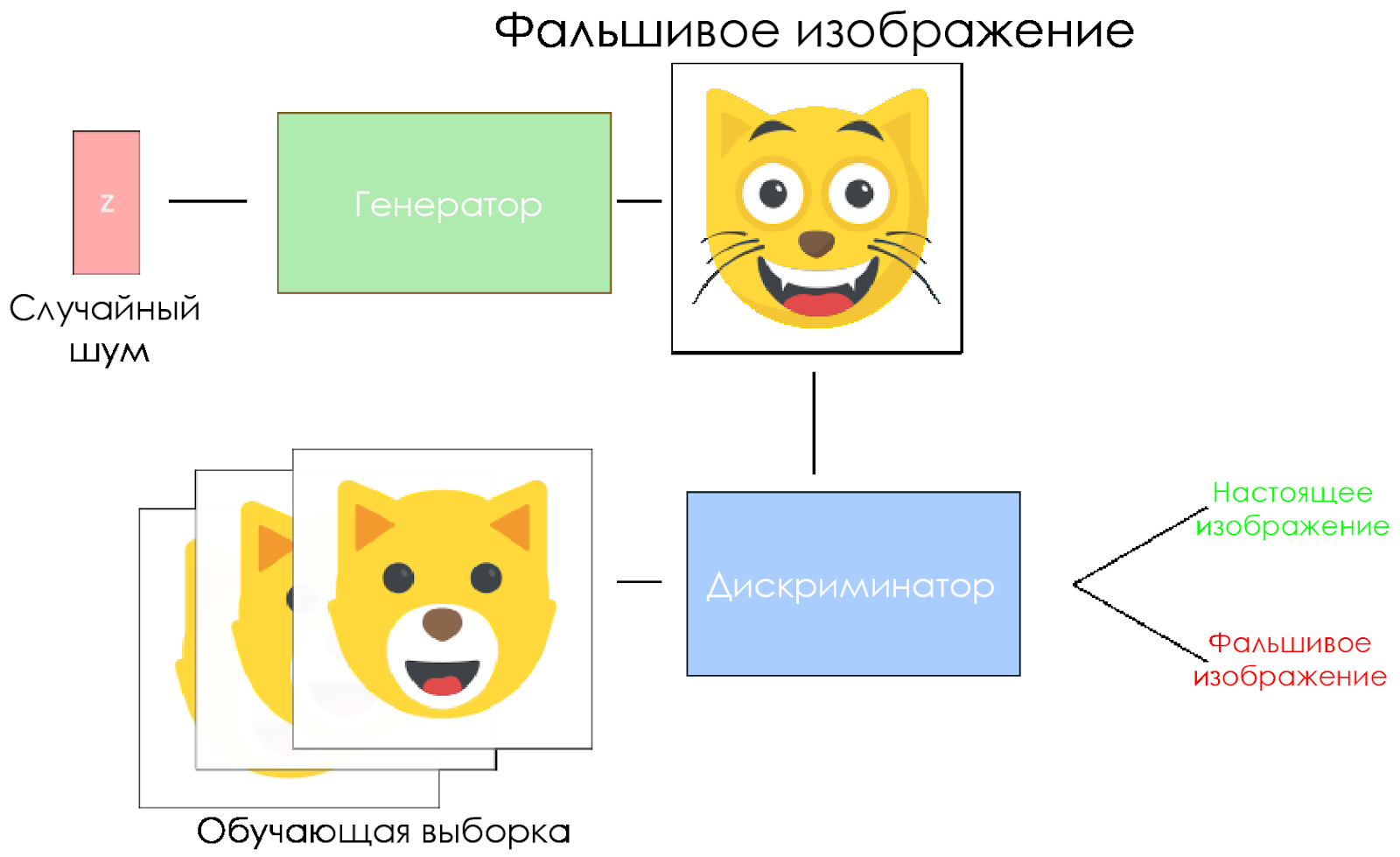 Esquema DCGAN.
Esquema DCGAN.- O gerador pega um vetor de ruído aleatório e gera uma imagem.
- A imagem é dada ao discriminador, ele a compara com a amostra de treinamento.
- O discriminador retorna um número - 0 (falso) ou 1 (imagem real).
Vamos criar um DCGAN!
Agora estamos prontos para criar nossa própria IA.
Nesta parte, focaremos nos principais componentes do nosso modelo. Se você quiser ver o código inteiro, clique
aqui .
Dados de entrada
Crie stubs para a entrada:
inputs_real para o discriminador e
inputs_z para o gerador. Observe que teremos duas taxas de aprendizado, separadamente para o gerador e o discriminador.
Os DCGANs são muito sensíveis aos hiperparâmetros, por isso é muito importante ajustá-los.
def model_inputs(real_dim, z_dim): """ Create the model inputs :param real_dim: tuple containing width, height and channels :param z_dim: The dimension of Z :return: Tuple of (tensor of real input images, tensor of z data, learning rate G, learning rate D) """
Discriminador e gerador
Usamos
tf.variable_scope por dois motivos.
Primeiro, verifique se todos os nomes de variáveis começam com gerador / discriminador. Mais tarde, isso nos ajudará a treinar duas redes neurais.
Em segundo lugar, reutilizaremos essas redes com diferentes dados de entrada:
- Treinaremos o gerador e, em seguida, coletaremos uma amostra das imagens geradas por ele.
- No discriminador, compartilharemos variáveis para imagens de entrada falsas e reais.

Vamos criar um discriminador. Lembre-se de que, como entrada, obtém uma imagem real ou falsa e retorna 0 ou 1 em resposta.
Algumas notas:
- Precisamos dobrar o tamanho do filtro em cada camada convolucional.
- O uso de downsampling não é recomendado. Em vez disso, apenas as camadas convolucionais removidas são aplicáveis.
- Em cada camada, usamos a normalização em lote (com exceção da camada de entrada), pois isso reduz a mudança de covariância. Leia mais neste maravilhoso artigo .
- Usaremos o Leaky ReLU como uma função de ativação, o que ajudará a evitar o efeito do gradiente “desaparecendo”.
def discriminator(x, is_reuse=False, alpha = 0.2): ''' Build the discriminator network. Arguments --------- x : Input tensor for the discriminator n_units: Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out, logits: ''' with tf.variable_scope("discriminator", reuse = is_reuse):
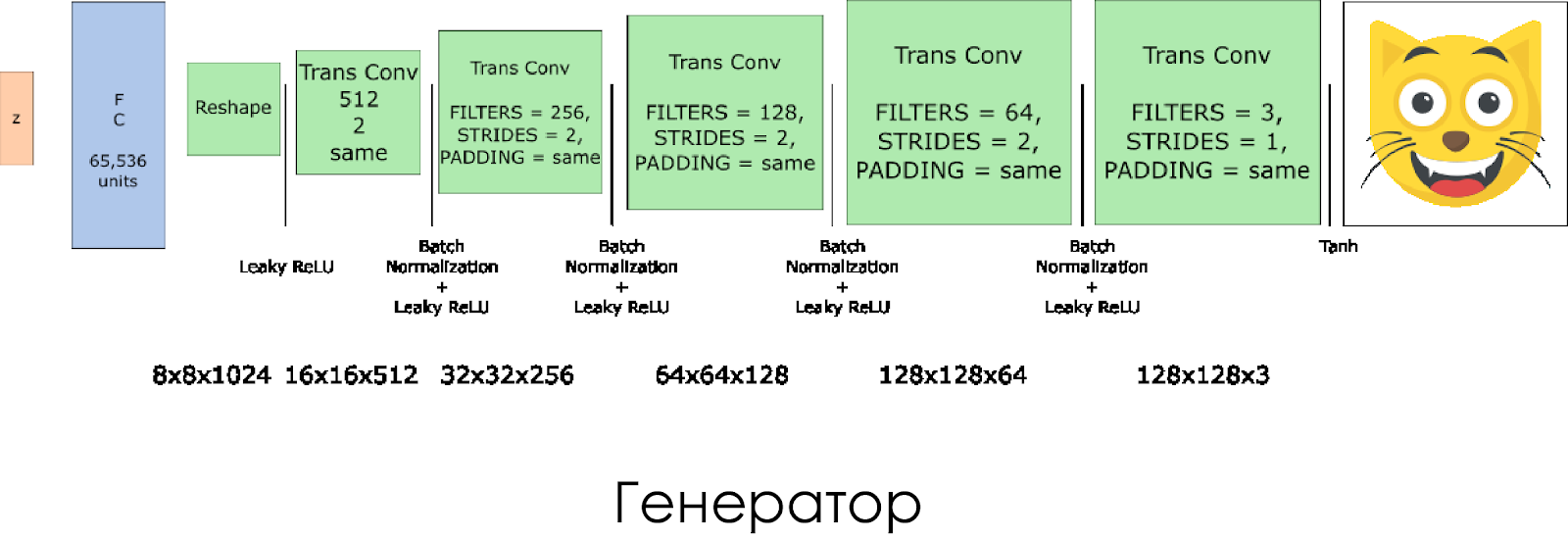
Nós criamos um gerador. Lembre-se de que ele recebe o vetor de ruído (z) como entrada e, graças às camadas de convolução transpostas, cria uma imagem falsa.
Em cada camada, reduzimos pela metade o tamanho do filtro e também dobramos o tamanho da imagem.
O gerador funciona melhor ao usar
tanh como função de ativação de saída.
def generator(z, output_channel_dim, is_train=True): ''' Build the generator network. Arguments --------- z : Input tensor for the generator output_channel_dim : Shape of the generator output n_units : Number of units in hidden layer reuse : Reuse the variables with tf.variable_scope alpha : leak parameter for leaky ReLU Returns ------- out: ''' with tf.variable_scope("generator", reuse= not is_train):
Perdas no discriminador e gerador
Como treinamos o gerador e o discriminador, precisamos calcular as perdas para as duas redes neurais. O discriminador deve dar 1 quando "considerar" a imagem como real e 0 se a imagem for falsa. De acordo com isso e você precisa configurar a perda. A perda discriminadora é calculada como a soma das perdas para a imagem real e falsa:
d_loss = d_loss_real + d_loss_fakeonde
d_loss_real é a perda quando o discriminador considera a imagem falsa, mas na verdade é real. É calculado da seguinte forma:
- Usamos
d_logits_real , todos os rótulos são iguais a 1 (porque todos os dados são reais). labels = tf.ones_like(tensor) * (1 - smooth) . Vamos usar a suavização de etiqueta: abaixe os valores da etiqueta de 1,0 para 0,9 para ajudar o discriminador a generalizar melhor.
d_loss_fake é uma perda quando o discriminador considera a imagem real, mas na verdade é falsa.
- Usamos
d_logits_fake , todos os rótulos são 0.
Para perder o gerador, é usado o
d_logits_fake do discriminador. Desta vez, todos os rótulos são 1, porque o gerador deseja enganar o discriminador.
def model_loss(input_real, input_z, output_channel_dim, alpha): """ Get the loss for the discriminator and generator :param input_real: Images from the real dataset :param input_z: Z input :param out_channel_dim: The number of channels in the output image :return: A tuple of (discriminator loss, generator loss) """
Optimizers
Após o cálculo das perdas, o gerador e o discriminador devem ser atualizados individualmente. Para fazer isso, use
tf.trainable_variables() criar uma lista de todas as variáveis definidas em nosso gráfico.
def model_optimizers(d_loss, g_loss, lr_D, lr_G, beta1): """ Get optimization operations :param d_loss: Discriminator loss Tensor :param g_loss: Generator loss Tensor :param learning_rate: Learning Rate Placeholder :param beta1: The exponential decay rate for the 1st moment in the optimizer :return: A tuple of (discriminator training operation, generator training operation) """
Treinamento
Agora implementamos a função de treinamento. A ideia é bem simples:
- Salvamos nosso modelo a cada cinco períodos (época).
- Nós salvamos a imagem na pasta com imagens a cada 10 lotes treinados.
- A cada 15 períodos, exibimos
g_loss , d_loss e a imagem gerada. Isso ocorre porque o notebook Jupyter pode falhar ao exibir muitas fotos. - Ou podemos gerar diretamente imagens reais carregando um modelo salvo (isso economizará 20 horas de treinamento).
def train(epoch_count, batch_size, z_dim, learning_rate_D, learning_rate_G, beta1, get_batches, data_shape, data_image_mode, alpha): """ Train the GAN :param epoch_count: Number of epochs :param batch_size: Batch Size :param z_dim: Z dimension :param learning_rate: Learning Rate :param beta1: The exponential decay rate for the 1st moment in the optimizer :param get_batches: Function to get batches :param data_shape: Shape of the data :param data_image_mode: The image mode to use for images ("RGB" or "L") """
Como executar
Tudo isso pode ser executado diretamente no seu computador, se você estiver pronto para aguardar 10 anos, por isso é melhor usar serviços de GPU baseados em nuvem como AWS ou FloydHub. Pessoalmente, treinei esse DCGAN por 20 horas no Microsoft Azure e na
Máquina Virtual de Aprendizado Profundo . Não tenho um relacionamento comercial com o Azure, apenas gosto do serviço ao cliente.
Se você tiver alguma dificuldade em executar em uma máquina virtual, consulte este maravilhoso
artigo .
Se você melhorar o modelo, sinta-se à vontade para fazer uma solicitação de recebimento.
