Hoje falaremos sobre o Kubernetes, sobre o rake que pode ser coletado em seu uso prático e sobre os desenvolvimentos que ajudaram o autor e que também devem ajudá-lo. Vamos tentar provar isso sem k8s no mundo moderno em qualquer lugar. Para os oponentes dos k8s, também fornecemos excelentes razões pelas quais você não deve mudar para ele. Ou seja, na história, não apenas defenderemos Kubernetes, mas também o repreenderemos. Daqui em nome veio isso
[não] .
Este artigo é baseado em uma
apresentação de Ivan Glushkov (
gli ) na conferência do DevOops 2017. Os dois últimos locais de trabalho de Ivan estavam de alguma forma relacionados ao Kubernetes: ele trabalhou em infracommands nos Postmates e na Machine Zone, e eles afetam Kubernetes com muita força. Além disso, condutas Ivan Podcast
DevZen . Apresentação adicional será em nome de Ivan.

Primeiro, vou abordar brevemente a área por que é útil e importante para muitos, por que esse hype surge. Então, vou falar sobre a nossa experiência no uso da tecnologia. Bem, então as conclusões.
Neste artigo, todos os slides são inseridos como imagens, mas às vezes você deseja copiar algo. Por exemplo, haverá exemplos com configurações. Os slides em PDF podem ser baixados
aqui .
Não direi estritamente a todos: não deixe de usar o Kubernetes. Existem prós e contras, portanto, se você procurar por contras, encontrará-os. Você tem uma escolha, olha apenas para os profissionais, apenas contras e geralmente olha tudo junto.
Simon Cat me ajudará com os profissionais, e o gato preto atravessará a rua quando houver um sinal de menos.

Então, por que esse hype aconteceu, por que a tecnologia X é melhor que a Y. Kubernetes é exatamente o mesmo sistema e há muito mais que um. Há Puppet, Chef, Ansible, Bash + SSH, Terraform. Meu SSH favorito está me ajudando agora, por que devo ir a algum lugar. Acredito que existem muitos critérios, mas destaquei os mais importantes.
O tempo entre o commit e o lançamento é muito bom, e os caras do Express 42 são grandes especialistas nisso. Automação de montagem, automação de todo o pipeline é uma coisa muito boa, você não pode elogiá-lo, ele realmente ajuda. Integração Contínua, Implantação Contínua. E, claro, quanto esforço você gastará em fazer tudo. Tudo pode ser escrito no Assembler, como eu disse, também um sistema de implantação, mas não adiciona conveniência.

Não vou contar uma breve introdução ao Kubernetes, você sabe o que é. Vou tocar nessas áreas um pouco mais.
Por que tudo isso é tão importante para os desenvolvedores? A repetibilidade é importante para eles, isto é, se eles escreverem algum tipo de aplicativo, executarem um teste, funcionará para você, para o seu vizinho e para a produção.
O segundo é um ambiente padronizado: se você estudou o Kubernetes e foi a uma empresa vizinha onde o Kubernetes está, tudo será o mesmo. A simplificação do procedimento de teste e a Integração Contínua não é um resultado direto do uso do Kubernetes, mas ainda simplifica a tarefa, tornando tudo mais conveniente.

Para desenvolvedores de versões, há muitas outras vantagens. Em primeiro lugar, é uma infraestrutura imutável.
Em segundo lugar, a infraestrutura é como um código armazenado em algum lugar. Em terceiro lugar, idempotência, a capacidade de adicionar um release com um botão. As reversões de liberação ocorrem muito rapidamente e a introspecção do sistema é bastante conveniente. Obviamente, tudo isso pode ser feito no seu sistema, escrito no joelho, mas você nem sempre pode fazer isso corretamente, e o Kubernetes já o implementou.
O que o Kubernetes não é e o que não permite fazer? Existem muitos conceitos errados a esse respeito. Vamos começar com os contêineres. Kubernetes corre em cima deles. Os contêineres não são máquinas virtuais leves, mas uma entidade completamente diferente. Eles são fáceis de explicar com a ajuda desse conceito, mas na verdade estão errados. O conceito é completamente diferente, deve ser entendido e aceito.
Em segundo lugar, o Kubernetes não torna o aplicativo mais seguro. Não o torna escalonável automaticamente.
Você precisa se esforçar para iniciar o Kubernetes, não será para que "pressione um botão e tudo funcione automaticamente". Vai doer.

Nossa experiência. Queremos que você e todos os outros não quebrem nada. Para fazer isso, você precisa procurar mais ao redor - e aqui está o nosso lado.

Primeiro, o Kubernetes não vai sozinho. Ao criar uma estrutura que gerencie totalmente as liberações e implantações, você deve entender que o Kubernetes é um dado e devem existir 100. Para criar tudo isso, você precisa estudar muito. Os iniciantes que entrarão no seu sistema também estudarão essa pilha, uma enorme quantidade de informações.
Kubernetes não é o único bloco importante, existem muitos outros blocos importantes, sem os quais o sistema não funcionará. Ou seja, você precisa se preocupar muito com a tolerância a falhas.

Por isso, Kubernetes é um sinal de menos. O sistema é complexo, você precisa cuidar de muito.

Mas há vantagens. Se uma pessoa estudou Kubernetes em uma empresa, em outra, seu cabelo não fica arrepiado devido ao sistema de liberação. Com o tempo, quando o Kubernetes ocupar mais espaço, a transição de pessoas e treinamento será mais fácil. E para isso - uma vantagem.


Nós usamos Helm. Este sistema, construído sobre o Kubernetes, se assemelha a um gerenciador de pacotes. Você pode clicar no botão, dizer que deseja instalar o * Wine * no seu sistema. Pode ser instalado no Kubernetes. Funciona, baixa automaticamente, inicia e tudo funcionará. Ele permite que você trabalhe com plug-ins, arquitetura cliente-servidor. Se você trabalha com ele, recomendamos que você execute um Tiller no espaço para nome. Isso isola o espaço para nome um do outro e quebrar um não quebra o outro.

De fato, o sistema é muito complexo. Um sistema, que deve ser uma abstração de um nível superior, mais simples e mais compreensível, não facilita muito o entendimento. Por este menos.

Vamos comparar as configurações. Provavelmente, você também terá algumas configurações se executar o sistema em produção. Nós temos nosso próprio sistema chamado BOOMer. Não sei por que a chamamos assim. É composto por Puppet, Chef, Ansible, Terraform e tudo mais, há uma garrafa grande.

Vamos ver como isso funciona. Aqui está um exemplo de uma configuração real que está atualmente trabalhando na produção. O que vemos aqui?
Primeiro, vemos onde iniciar o aplicativo, em segundo lugar, o que precisa ser iniciado e, em terceiro lugar, como ele deve ser preparado para o lançamento. Em uma garrafa, os conceitos já estão misturados.

Se olharmos mais adiante, porque adicionamos herança para fazer configurações mais complexas, devemos examinar o que está na configuração comum a que estamos nos referindo. Além disso, adicionamos configuração de rede, direitos de acesso, planejamento de carga. Tudo isso em uma configuração necessária para executar uma aplicação real na produção, misturamos vários conceitos em um só lugar.
Isso é muito difícil, é muito errado e é uma grande vantagem para o Kubernetes, porque nele você simplesmente determina o que executar. A configuração da rede foi realizada durante a instalação do Kubernetes, todo o provisionamento foi resolvido usando a janela de encaixe - você tinha encapsulamento, todos os problemas foram de alguma forma separados e, nesse caso, a configuração possui apenas o seu aplicativo e há uma vantagem para isso.

Vamos dar uma olhada. Aqui temos apenas uma aplicação. Para que a implantação funcione, você precisa de muito mais para trabalhar. Primeiro, você precisa definir serviços. Como os segredos, ConfigMap, acesso ao Load Balancer nos chegam.

Não esqueça que você possui vários ambientes. Há Stage / Prod / Dev. Tudo isso junto não é um pequeno pedaço que mostrei, mas um enorme conjunto de configurações, o que é realmente difícil. Por este menos.

Modelo de leme para comparação. Ele repete completamente os modelos do Kubernetes; se houver algum arquivo no Kubernetes com a definição de implantação, o mesmo estará no Helm. Em vez de valores específicos para o ambiente, você tem modelos que são substituídos por valores.
Você tem um modelo separado, valores separados que devem ser substituídos neste modelo.
Obviamente, você precisa definir adicionalmente a infraestrutura diferente do Helm, apesar de ter muitos arquivos de configuração no Kubernetes e arrastá-lo e soltá-lo no Helm. Tudo isso é muito difícil, pelo qual um sinal de menos.
Um sistema que deveria simplificar realmente complica. Para mim, este é um sinal de menos. Precisa adicionar outra coisa ou não usar
Vamos aprofundar, não somos suficientemente profundos.

Primeiro, como trabalhamos com clusters. Li o artigo do Google
"Borg, Omega e Kubernetes", que defende fortemente o conceito de que você precisa ter um cluster grande. Também fui a favor dessa ideia, mas, no final, a deixamos. Como resultado de nossas disputas, usamos quatro grupos diferentes.
O primeiro cluster e2e a testar o próprio Kubernetes e testar scripts que implementam o ambiente, plug-ins etc. O segundo, é claro, prod e palco. Estes são conceitos padrão. Em terceiro lugar, este é o administrador, no qual todo o resto é carregado - em particular, temos CI lá, e parece que, por causa disso, esse cluster sempre será o maior.
Existem muitos testes: por commit, por mesclagem, todo mundo faz um monte de commit, então os clusters são enormes.

Tentamos examinar o CoreOS, mas não o usamos. Eles têm TF ou CloudFormation dentro, e ambos muito mal nos permitem entender o que está dentro do estado. Por esse motivo, há problemas durante a atualização. Quando você deseja atualizar as configurações do seu Kubernetes, por exemplo, sua versão, você pode encontrar o fato de que a atualização não funciona dessa maneira, na seqüência errada. Este é um grande problema de estabilidade. Este é um sinal de menos.

Em segundo lugar, quando você usa o Kubernetes, precisa baixar imagens de algum lugar. Pode ser uma fonte interna, repositório ou externo. Se interno, há problemas. Eu recomendo usar o Docker Distribution porque é estável, foi feito pelo Docker. Mas o preço do suporte ainda é alto. Para que ele funcione, você precisa torná-lo tolerante a falhas, porque este é o único local em que seus aplicativos obtêm dados para trabalhar.

Imagine que, no momento crucial, quando você encontrou um bug na produção, seu repositório caiu - você não pode atualizar o aplicativo. Você deve torná-lo tolerante a falhas e com todos os possíveis problemas que podem ser apenas.
Em segundo lugar, se a massa de equipes, cada uma com sua própria imagem, elas se acumulam muito e muito rapidamente. Você pode matar sua distribuição do Docker. É necessário fazer a limpeza, excluir imagens, criar informações para os usuários, quando e o que você limpará.
Em terceiro lugar, com imagens grandes, digamos, se você tiver um monólito, o tamanho da imagem será muito grande. Imagine que você precisa liberar 30 nós. 2 gigabytes por 30 nós - calcule qual fluxo, com que velocidade é baixado para todos os nós. Gostaria que ele pressionasse um botão e imediatamente se tornasse verde. Mas não, você deve primeiro esperar até que seja baixado. É necessário, de alguma forma, acelerar esse download, e tudo funciona a partir de um ponto.

Com repositórios externos, há os mesmos problemas com o coletor de lixo, mas na maioria das vezes isso é feito automaticamente. Nós usamos o Quay. No caso de repositórios externos, esses são serviços de terceiros nos quais a maioria das imagens é pública. Para que não houvesse imagens públicas, é necessário fornecer acesso. Precisamos de segredos, direitos de acesso a imagens, tudo isso é especialmente configurado. Obviamente, isso pode ser automatizado, mas no caso de um lançamento local de Cuba no seu sistema, você ainda precisa configurá-lo.

Para instalar o Kubernetes, usamos o kops. Este é um sistema muito bom, somos usuários iniciais do momento em que ainda não haviam gravado no blog. Ele não suporta totalmente o CoreOS, funciona bem com o Debian, sabe como configurar automaticamente os nós mestres do Kubernetes, trabalha com complementos e tem a capacidade de fazer zero tempo de inatividade durante as atualizações do Kubernetes.
Todos esses recursos estão prontos para o uso, para os quais uma vantagem grande e ousada. Ótimo sistema!


Nos links, você pode encontrar muitas opções para configurar uma rede no Kubernetes. Existem realmente muitos deles, todos têm suas próprias vantagens e desvantagens. O Kops suporta apenas parte dessas opções. É claro que você pode configurá-lo para funcionar através da CNI, mas é melhor usar os mais populares e padrão. Eles são testados pela comunidade e provavelmente são estáveis.

Decidimos usar o Calico. Funcionou bem do zero, sem muitos problemas, usa BGP, encapsulamento mais rápido, suporta IP-in-IP, permite trabalhar com várias nuvens, para nós isso é uma grande vantagem.
A boa integração com o Kubernetes, usando rótulos, delimita o tráfego. Pois isso é uma vantagem.
Eu não esperava que o Calico chegasse ao estado quando estava ligado, e tudo funciona sem problemas.

Alta disponibilidade, como eu disse, fazemos através do kops, você pode usar 5-7-9 nós, usamos três. Estamos no etcd v2, por causa de um bug, eles não foram atualizados na v3. Teoricamente, isso acelerará alguns processos. Não sei, duvido.

Um momento complicado, temos um cluster especial para experimentar scripts, rolando automaticamente pelo IC. Acreditamos que temos proteção contra ações completamente erradas, mas para algumas versões especiais e complexas, no caso de tirarmos instantâneos de todos os discos, não fazemos backups todos os dias.


Autorização é uma questão eterna. Nós da Kubernetes usamos RBAC, acesso baseado em função. É muito melhor que o ABAC e, se você o configurou, entendeu o que quero dizer. Veja as configurações - surpreenda-se.
Usamos o Dex, um provedor OpenID que bombeia todas as informações de alguma fonte de dados.
E para fazer login no Kubernetes, existem duas maneiras. É necessário registrar-se de alguma forma no .kube / config para onde ir e o que ele pode fazer. É necessário obter de alguma forma essa configuração. Ou o usuário acessa a interface do usuário, onde faz login, recebe configurações, copia-as para / config e funciona. Isso não é muito conveniente. Passamos gradualmente ao fato de que uma pessoa entra no console, clica no botão, efetua login, as configurações são geradas automaticamente a partir dele e empilhadas no lugar certo. Muito mais conveniente, decidimos agir dessa maneira.

Como fonte de dados, usamos o Active Directory. O Kubernetes permite enviar informações sobre o grupo por toda a estrutura de autorização, que se traduz em namespace e funções. Assim, distinguimos imediatamente entre onde uma pessoa pode ir, onde ela não tem o direito de ir e o que ela pode liberar.

Na maioria das vezes, as pessoas precisam acessar a AWS. Se você não possui o Kubernetes, há uma máquina executando o aplicativo. Parece que tudo que você precisa é obter os logs, vê-los e é isso. Isso é conveniente quando uma pessoa pode ir ao seu carro e ver como o aplicativo funciona. Do ponto de vista do Kubernetes, tudo funciona em contêineres. Existe um comando `kubectl exec` - entre no contêiner no aplicativo e veja o que acontece lá. Portanto, não há necessidade de ir para instâncias da AWS. Negamos o acesso a todos, exceto o infracommand.
Além disso, proibimos as chaves de administrador de longa duração, a entrada através de funções. Se é possível usar o papel de administrador - eu sou o administrador. Além disso, adicionamos rotação de teclas. É conveniente configurá-lo através do comando awsudo, este é um projeto no github, eu recomendo, pois permite que você trabalhe como em uma equipe do sudo.



Quotas. Uma coisa muito boa no Kubernetes, trabalhar imediatamente. Você limita qualquer espaço de nome, digamos, pelo número de objetos, memória ou CPU que você pode consumir. Eu acredito que isso é importante e útil para todos. Ainda não atingimos a memória e a CPU, usamos apenas o número de objetos, mas adicionaremos tudo isso.
Grande e gordo, permite que você faça muitas coisas complicadas.


Dimensionamento. Você não pode misturar a escala dentro do Kubernetes e fora do Kubernetes. Dentro do Kubernetes, o próprio dimensionamento é feito. Pode aumentar os pods automaticamente quando há uma grande carga.
Aqui estou falando sobre o dimensionamento de instâncias do Kubernetes. Isso pode ser feito usando o AWS Autoscaler, este é um projeto do github. Quando você adiciona um novo pod e ele não pode ser iniciado porque carece de recursos em todas as instâncias, o AWS Autoscaler pode adicionar nós automaticamente. Ele permite que você trabalhe em instâncias Spot, ainda não o adicionamos, mas faremos isso, permite economizar muito.


Quando você tem muitos usuários e aplicativos, precisa monitorá-los de alguma forma. Geralmente isso é telemetria, logs, alguns gráficos bonitos.

Por razões históricas, tínhamos o Sensu, que não era muito adequado para o Kubernetes. Era necessário um projeto mais orientado à métrica. Analisamos toda a pilha TICK, especialmente o InfluxDB. Boa interface do usuário, linguagem semelhante ao SQL, mas não há recursos suficientes. Mudamos para Prometeu.
Ele é bom Boa linguagem de consulta, bons alertas e tudo pronto para uso.

Para enviar telemetria, usamos o Cernan. Este é o nosso próprio projeto escrito em Rust. Este é o único projeto da Rust que trabalha em nossa produção há um ano. Possui vários conceitos: existe um conceito de fonte de dados, você configura várias fontes. Você configura onde os dados serão mesclados. Temos uma configuração de filtros, ou seja, os dados em fluxo podem ser processados de alguma forma. Você pode converter logs em métricas, métricas em logs, o que quiser.
Apesar de você ter várias entradas, várias conclusões e mostrar que para onde vai, existe algo como um grande sistema gráfico, é bastante conveniente.

Agora estamos migrando da pilha atual Statsd / Cernan / Wavefront para o Kubernetes. Teoricamente, o Prometheus deseja coletar dados dos aplicativos por si só, portanto, é necessário adicionar o ponto de extremidade a todos os aplicativos, dos quais serão obtidas métricas. Cernan é o link de transmissão, deve funcionar em qualquer lugar. Existem duas possibilidades: você pode executar o Kubernetes em cada instância, usando o conceito Sidecar, quando outro contêiner trabalha no seu campo de dados que envia dados. Fazemos isso e aquilo.

No momento, todos os logs são enviados para stdout / stderr. Todas as aplicações são projetadas para isso, portanto, um dos requisitos críticos é que não deixemos este sistema. O Cernan envia dados para o ElasticSearch, eventos de todo o sistema Kubernetes são enviados para lá usando o Heapster. Este é um sistema muito bom, eu recomendo.
Depois disso, você pode ver todos os logs em um único local, por exemplo, no console. Nós usamos Kibana. Há um maravilhoso produto Stern, apenas para os registros. Ele permite que você assista, pinte diferentes vagens em cores diferentes, saiba como ver quando uma delas morreu e a outra foi reiniciada. Recolhe automaticamente todos os logs. Um projeto ideal, eu recomendo, é um Kubernetes mais gordo, está tudo bem aqui.


Segredos Usamos S3 e KMS. Estamos pensando em mudar para o Vault ou segredos no próprio Kubernetes. Eles estavam em 1,7 no estado alfa, mas algo precisa ser feito com isso.

Chegamos à parte interessante. O desenvolvimento do Kubernetes geralmente não é muito considerado.
Diz basicamente: "O Kubernetes é um sistema ideal, está tudo bem, vamos seguir em frente".Mas, de fato, o queijo grátis é apenas uma ratoeira, e para desenvolvedores em Kubernetes é um inferno. Não do ponto de vista de que tudo está ruim, mas do fato de que você precisa encarar as coisas de maneira um pouco diferente. Eu comparo o desenvolvimento no Kubernetes com a programação funcional: até você tocá-lo, você pensa em seu estilo imperativo, está tudo bem. Para se desenvolver no funcionalismo, você precisa virar ligeiramente a cabeça para o outro lado - a mesma coisa aqui.Você pode desenvolvê-lo, pode fazê-lo bem, mas precisa encará-lo de maneira diferente. Primeiro, lide com o conceito Docker Way. Isso não é tão difícil, mas é bastante problemático compreendê-lo completamente. A maioria dos desenvolvedores está acostumada a acessar sua máquina local, remota ou virtual via SSH, dizendo: "Deixe-me consertar algo aqui, podshaman".Você diz a ele que Kubernetes não fará isso porque você leu apenas a infraestrutura. Quando você quiser atualizar o aplicativo, faça uma nova imagem que funcione, e a antiga, por favor, não toque, ela simplesmente morrerá. Eu, pessoalmente, trabalhei na introdução do Kubernetes em diferentes equipes e vejo horror aos olhos das pessoas quando elas entendem que terão que abandonar completamente todos os velhos hábitos, criar novos, algum novo sistema, o que é muito difícil.Além disso, você terá que fazer muitas escolhas: digamos, quando você faz algumas alterações, se o desenvolvimento for local, você precisa comprometê-lo com o repositório de alguma forma, então o repositório de pipeline executa os testes e diz: "Oh, há um erro de digitação em uma palavra", você precisa de tudo faça localmente. Monte a pasta de alguma forma, entre, atualize o sistema, pelo menos compile-a. Se a execução local de testes for inconveniente, ele poderá confirmar no IC pelo menos para verificar algumas ações locais e enviá-las ao CI para verificação. Essas escolhas são bastante complicadas.É especialmente difícil quando você tem um aplicativo ramificado que consiste em cem serviços e, para que um deles funcione, você precisa garantir que todos os outros trabalhem lado a lado. Você precisa emular o ambiente ou, de alguma forma, executar localmente. Toda essa escolha não é trivial, o desenvolvedor precisa pensar muito sobre isso. Isso cria uma atitude negativa em relação ao Kubernetes. É claro que ele é bom - mas é ruim, porque você precisa pensar muito e mudar seus hábitos.Portanto, aqui três gatos gordos correram pela estrada.
Não do ponto de vista de que tudo está ruim, mas do fato de que você precisa encarar as coisas de maneira um pouco diferente. Eu comparo o desenvolvimento no Kubernetes com a programação funcional: até você tocá-lo, você pensa em seu estilo imperativo, está tudo bem. Para se desenvolver no funcionalismo, você precisa virar ligeiramente a cabeça para o outro lado - a mesma coisa aqui.Você pode desenvolvê-lo, pode fazê-lo bem, mas precisa encará-lo de maneira diferente. Primeiro, lide com o conceito Docker Way. Isso não é tão difícil, mas é bastante problemático compreendê-lo completamente. A maioria dos desenvolvedores está acostumada a acessar sua máquina local, remota ou virtual via SSH, dizendo: "Deixe-me consertar algo aqui, podshaman".Você diz a ele que Kubernetes não fará isso porque você leu apenas a infraestrutura. Quando você quiser atualizar o aplicativo, faça uma nova imagem que funcione, e a antiga, por favor, não toque, ela simplesmente morrerá. Eu, pessoalmente, trabalhei na introdução do Kubernetes em diferentes equipes e vejo horror aos olhos das pessoas quando elas entendem que terão que abandonar completamente todos os velhos hábitos, criar novos, algum novo sistema, o que é muito difícil.Além disso, você terá que fazer muitas escolhas: digamos, quando você faz algumas alterações, se o desenvolvimento for local, você precisa comprometê-lo com o repositório de alguma forma, então o repositório de pipeline executa os testes e diz: "Oh, há um erro de digitação em uma palavra", você precisa de tudo faça localmente. Monte a pasta de alguma forma, entre, atualize o sistema, pelo menos compile-a. Se a execução local de testes for inconveniente, ele poderá confirmar no IC pelo menos para verificar algumas ações locais e enviá-las ao CI para verificação. Essas escolhas são bastante complicadas.É especialmente difícil quando você tem um aplicativo ramificado que consiste em cem serviços e, para que um deles funcione, você precisa garantir que todos os outros trabalhem lado a lado. Você precisa emular o ambiente ou, de alguma forma, executar localmente. Toda essa escolha não é trivial, o desenvolvedor precisa pensar muito sobre isso. Isso cria uma atitude negativa em relação ao Kubernetes. É claro que ele é bom - mas é ruim, porque você precisa pensar muito e mudar seus hábitos.Portanto, aqui três gatos gordos correram pela estrada.
 Quando olhamos para o Kubernetes, tentamos entender, talvez existam alguns sistemas convenientes para o desenvolvimento. Em particular, existe o Deis, com certeza você já ouviu tudo sobre isso. É muito fácil de usar e verificamos, de fato, que todos os projetos simples mudam muito facilmente para o Deis. Mas o problema é que projetos mais complexos podem não mudar para o Deis.Como eu disse, mudamos para Helm Charts. Mas o único problema que estamos vendo agora é que é necessária muita documentação boa. Precisamos de algumas instruções, algumas perguntas frequentes, para que uma pessoa possa iniciar rapidamente, copiar as configurações atuais, colar suas próprias, alterar os nomes para que tudo esteja correto. Também é importante entender isso com antecedência, e você precisa fazer tudo. Listei kits de ferramentas comuns para desenvolvimento aqui. Não vou falar sobre tudo isso, exceto o minicube.
Quando olhamos para o Kubernetes, tentamos entender, talvez existam alguns sistemas convenientes para o desenvolvimento. Em particular, existe o Deis, com certeza você já ouviu tudo sobre isso. É muito fácil de usar e verificamos, de fato, que todos os projetos simples mudam muito facilmente para o Deis. Mas o problema é que projetos mais complexos podem não mudar para o Deis.Como eu disse, mudamos para Helm Charts. Mas o único problema que estamos vendo agora é que é necessária muita documentação boa. Precisamos de algumas instruções, algumas perguntas frequentes, para que uma pessoa possa iniciar rapidamente, copiar as configurações atuais, colar suas próprias, alterar os nomes para que tudo esteja correto. Também é importante entender isso com antecedência, e você precisa fazer tudo. Listei kits de ferramentas comuns para desenvolvimento aqui. Não vou falar sobre tudo isso, exceto o minicube. O Minikube é um sistema muito bom, no sentido de que é bom, mas é ruim. Ele permite que você execute o Kubernetes localmente, permite ver tudo no seu laptop, não precisa ir a lugar nenhum no SSH e assim por diante.Eu trabalho no MacOS, tenho um Mac, respectivamente, para executar um aplicativo local, preciso executar a janela de encaixe localmente. Isso não pode ser feito. No final, você precisa executar o virtualbox ou o xhyve. As duas coisas são, de fato, emulações no topo do meu sistema operacional. Usamos o xhyve, mas recomendamos o uso do VirtualBox, já que existem muitos bugs, eles precisam ser contornados.Mas a idéia de que existe virtualização e, dentro da virtualização, outro nível de abstração para virtualização é lançada, é algum tipo de ridículo, ilusório. Em geral, é bom que de alguma forma funcione, mas seria melhor se fosse concluído.
O Minikube é um sistema muito bom, no sentido de que é bom, mas é ruim. Ele permite que você execute o Kubernetes localmente, permite ver tudo no seu laptop, não precisa ir a lugar nenhum no SSH e assim por diante.Eu trabalho no MacOS, tenho um Mac, respectivamente, para executar um aplicativo local, preciso executar a janela de encaixe localmente. Isso não pode ser feito. No final, você precisa executar o virtualbox ou o xhyve. As duas coisas são, de fato, emulações no topo do meu sistema operacional. Usamos o xhyve, mas recomendamos o uso do VirtualBox, já que existem muitos bugs, eles precisam ser contornados.Mas a idéia de que existe virtualização e, dentro da virtualização, outro nível de abstração para virtualização é lançada, é algum tipo de ridículo, ilusório. Em geral, é bom que de alguma forma funcione, mas seria melhor se fosse concluído.
 O IC não está diretamente relacionado ao Kubernetes, mas é um sistema muito importante, especialmente se você tiver o Kubernetes, se o integrar, poderá obter resultados muito bons. Usamos o Concourse for CI, com uma funcionalidade muito rica, você pode criar gráficos assustadores, do que, onde, como começa, do que depende. Mas os desenvolvedores do Concourse são muito estranhos sobre o seu produto. Por exemplo, ao mudar de uma versão para outra, eles quebraram a compatibilidade com versões anteriores e não reescreveram a maioria dos plugins. Além disso, a documentação não foi concluída e, quando tentamos fazer algo, nada funcionou.Em geral, existe pouca documentação em todos os ICs, você precisa ler o código e, em geral, abandonamos o Concourse. Mudamos para o Drone.io - é pequeno, muito leve, ágil, a funcionalidade é muito menor, mas com mais frequência é suficiente. Sim, seria conveniente ter gráficos de dependência grandes e pesados, mas você também pode trabalhar em pequenos. Também um pouco de documentação, lemos o código, mas está tudo bem.Cada estágio do pipeline funciona em seu próprio contêiner de docker, o que facilita muito a mudança para o Kubernetes. Se você possui um aplicativo que é executado em uma máquina real, para adicioná-lo ao CI, use o contêiner de docker e, depois disso, a mudança para o Kubernetes é simples.Configuramos a liberação automática do cluster admin / stage, enquanto temos medo de adicionar a configuração ao cluster de produção. Além disso, existe um sistema de plugins.Este é um exemplo de uma configuração simples do Drone. Retirado do sistema de trabalho finalizado, neste caso, existem cinco etapas no pipeline, cada etapa faz algo: coleta, testes e assim por diante. Com esse conjunto de recursos que está no Drone, acho que é uma coisa boa.
O IC não está diretamente relacionado ao Kubernetes, mas é um sistema muito importante, especialmente se você tiver o Kubernetes, se o integrar, poderá obter resultados muito bons. Usamos o Concourse for CI, com uma funcionalidade muito rica, você pode criar gráficos assustadores, do que, onde, como começa, do que depende. Mas os desenvolvedores do Concourse são muito estranhos sobre o seu produto. Por exemplo, ao mudar de uma versão para outra, eles quebraram a compatibilidade com versões anteriores e não reescreveram a maioria dos plugins. Além disso, a documentação não foi concluída e, quando tentamos fazer algo, nada funcionou.Em geral, existe pouca documentação em todos os ICs, você precisa ler o código e, em geral, abandonamos o Concourse. Mudamos para o Drone.io - é pequeno, muito leve, ágil, a funcionalidade é muito menor, mas com mais frequência é suficiente. Sim, seria conveniente ter gráficos de dependência grandes e pesados, mas você também pode trabalhar em pequenos. Também um pouco de documentação, lemos o código, mas está tudo bem.Cada estágio do pipeline funciona em seu próprio contêiner de docker, o que facilita muito a mudança para o Kubernetes. Se você possui um aplicativo que é executado em uma máquina real, para adicioná-lo ao CI, use o contêiner de docker e, depois disso, a mudança para o Kubernetes é simples.Configuramos a liberação automática do cluster admin / stage, enquanto temos medo de adicionar a configuração ao cluster de produção. Além disso, existe um sistema de plugins.Este é um exemplo de uma configuração simples do Drone. Retirado do sistema de trabalho finalizado, neste caso, existem cinco etapas no pipeline, cada etapa faz algo: coleta, testes e assim por diante. Com esse conjunto de recursos que está no Drone, acho que é uma coisa boa.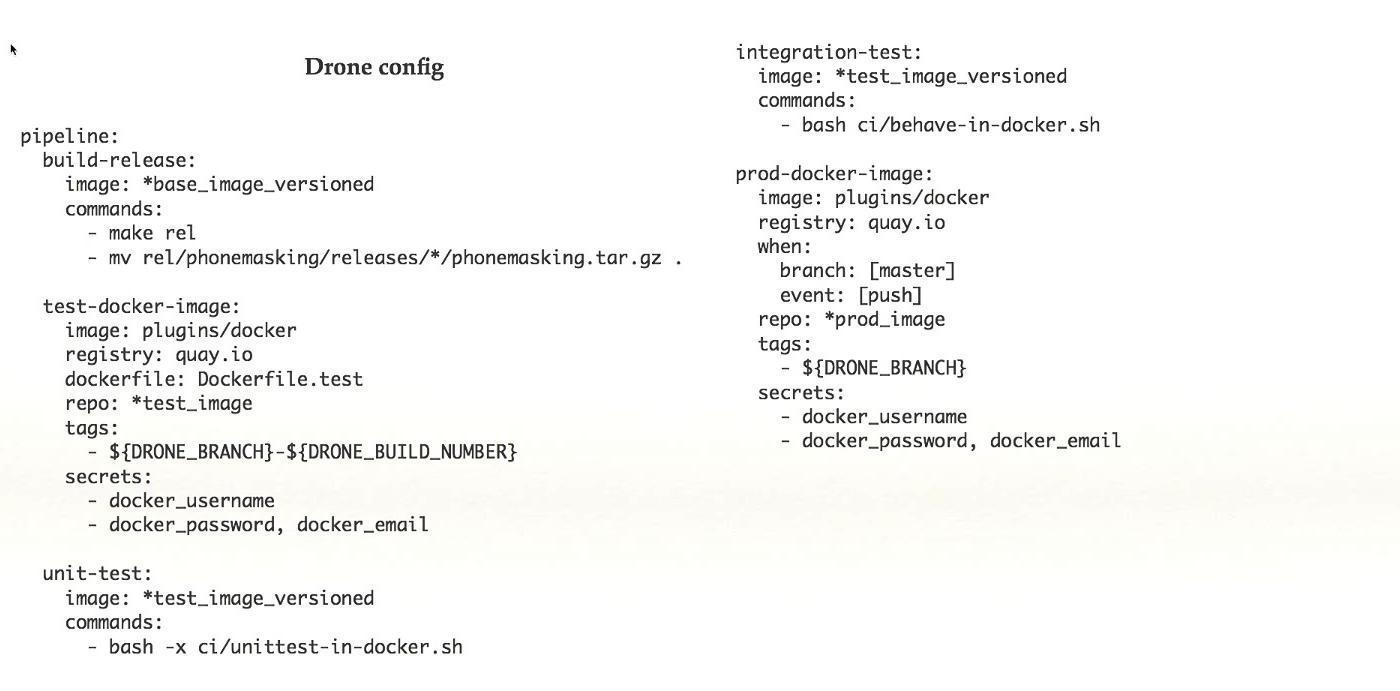
 Discutimos muito sobre quantos clusters ter: um ou mais. Quando surgiu a ideia de vários clusters, começamos a trabalhar mais nessa direção, criamos alguns scripts, configuramos vários outros cubos para os nossos Kubernetes. Depois disso, eles acessaram o Google e pediram conselhos, todos fizeram isso, talvez algo precise ser corrigido.O Google concordou que a ideia de um único cluster não é aplicável no Kubernetes. Existem muitas imperfeições, em particular, que trabalham com geolocalizações. Acontece que a idéia é verdadeira, mas é muito cedo para falar sobre isso. Talvez mais tarde. Enquanto o Service Mesh pode ajudar.
Discutimos muito sobre quantos clusters ter: um ou mais. Quando surgiu a ideia de vários clusters, começamos a trabalhar mais nessa direção, criamos alguns scripts, configuramos vários outros cubos para os nossos Kubernetes. Depois disso, eles acessaram o Google e pediram conselhos, todos fizeram isso, talvez algo precise ser corrigido.O Google concordou que a ideia de um único cluster não é aplicável no Kubernetes. Existem muitas imperfeições, em particular, que trabalham com geolocalizações. Acontece que a idéia é verdadeira, mas é muito cedo para falar sobre isso. Talvez mais tarde. Enquanto o Service Mesh pode ajudar. Em geral, se você quiser ver como nosso sistema funciona, preste atenção na Geodésica. Este é um produto semelhante ao que fazemos. É de código aberto, uma escolha muito semelhante de conceito de design. Estamos pensando em nos unir e possivelmente usá-los.
Em geral, se você quiser ver como nosso sistema funciona, preste atenção na Geodésica. Este é um produto semelhante ao que fazemos. É de código aberto, uma escolha muito semelhante de conceito de design. Estamos pensando em nos unir e possivelmente usá-los. Sim, em nossa prática de trabalhar com o Kubernetes também existem problemas.Há um problema com nomes locais, com certificados. Há um problema com o download de imagens grandes e seu trabalho, possivelmente relacionado ao sistema de arquivos, ainda não cavamos lá. Já existem três maneiras diferentes de instalar as extensões do Kubernetes. Trabalhamos nesse projeto há menos de um ano e já temos três maneiras diferentes: os anéis anuais estão crescendo.
Sim, em nossa prática de trabalhar com o Kubernetes também existem problemas.Há um problema com nomes locais, com certificados. Há um problema com o download de imagens grandes e seu trabalho, possivelmente relacionado ao sistema de arquivos, ainda não cavamos lá. Já existem três maneiras diferentes de instalar as extensões do Kubernetes. Trabalhamos nesse projeto há menos de um ano e já temos três maneiras diferentes: os anéis anuais estão crescendo. Vamos ser como todos os contras.Então, acho que uma das principais desvantagens é a grande quantidade de informações a serem estudadas, não apenas novas tecnologias, mas também novos conceitos e hábitos. É como aprender um novo idioma: em princípio, não é difícil, mas é difícil virar a cabeça um pouco para todos os usuários. Se você não trabalhou com conceitos semelhantes antes, é difícil mudar para o Kubernetes.O Kubernetes será apenas uma pequena parte do seu sistema. Todo mundo pensa que instalará o Kubernetes e tudo funcionará imediatamente. Não, este é um pequeno cubo e haverá muitos desses cubos.Geralmente, alguns aplicativos são difíceis de executar no Kubernetes - e é melhor não executá-los. Também arquivos de configuração muito pesados e grandes e, nos conceitos sobre o Kubernetes, eles são ainda mais complicados. Todas as soluções atuais são brutas.Todos esses contras são, obviamente, nojentos.Compromissos e uma transição difícil criam uma imagem negativa do Kubernetes, e eu não sei como lidar com isso. Não conseguimos vencer muito, há pessoas que odeiam todo o movimento, não querem e não entendem suas vantagens.Para executar o Minikube, seu sistema precisará trabalhar duro para que tudo funcione. Como você pode ver, existem muitas desvantagens, e aqueles que não querem trabalhar com o Kubernetes têm seus próprios motivos. Se você não quiser ouvir sobre os profissionais, feche os olhos e os ouvidos, pois eles irão além.
Vamos ser como todos os contras.Então, acho que uma das principais desvantagens é a grande quantidade de informações a serem estudadas, não apenas novas tecnologias, mas também novos conceitos e hábitos. É como aprender um novo idioma: em princípio, não é difícil, mas é difícil virar a cabeça um pouco para todos os usuários. Se você não trabalhou com conceitos semelhantes antes, é difícil mudar para o Kubernetes.O Kubernetes será apenas uma pequena parte do seu sistema. Todo mundo pensa que instalará o Kubernetes e tudo funcionará imediatamente. Não, este é um pequeno cubo e haverá muitos desses cubos.Geralmente, alguns aplicativos são difíceis de executar no Kubernetes - e é melhor não executá-los. Também arquivos de configuração muito pesados e grandes e, nos conceitos sobre o Kubernetes, eles são ainda mais complicados. Todas as soluções atuais são brutas.Todos esses contras são, obviamente, nojentos.Compromissos e uma transição difícil criam uma imagem negativa do Kubernetes, e eu não sei como lidar com isso. Não conseguimos vencer muito, há pessoas que odeiam todo o movimento, não querem e não entendem suas vantagens.Para executar o Minikube, seu sistema precisará trabalhar duro para que tudo funcione. Como você pode ver, existem muitas desvantagens, e aqueles que não querem trabalhar com o Kubernetes têm seus próprios motivos. Se você não quiser ouvir sobre os profissionais, feche os olhos e os ouvidos, pois eles irão além. A primeira vantagem é que, com o tempo, os iniciantes terão que aprender menos. Muitas vezes acontece que quando um recém-chegado entra no sistema, ele começa a arrancar todo o cabelo, porque nos primeiros 1-2 meses ele tenta descobrir como liberar tudo, se o sistema é grande e dura muito, muitos anéis anuais crescem. Kubernetes facilita as coisas.Em segundo lugar, o Kubernetes não faz isso sozinho, mas permite que você faça um curto ciclo de liberação. Um CI criado de consolidação, o CI criou uma imagem, aumentou automaticamente, você pressionou um botão e tudo entrou em produção. Isso reduz bastante o tempo de liberação.A seguir está a divisão do código. Nosso sistema e a maioria de seus sistemas coletam configurações de diferentes níveis em um único local, ou seja, você possui um código de infraestrutura, um código comercial e todas as lógicas são misturadas em um único local. No Kubernetes, isso não estará pronto para uso, escolher o conceito certo ajuda a evitar isso com antecedência.Uma comunidade grande e muito ativa, o que significa um grande número de mudanças. A maior parte do que mencionei nos últimos dois anos se tornou tão estável que pode ser liberada na produção. Talvez alguns deles tenham aparecido antes, mas não eram muito estáveis.Considero uma grande vantagem que, em um lugar, você possa ver os logs do aplicativo e do Kubernetes trabalhando com seu aplicativo, o que é inestimável. E não há acesso aos nós. Quando removemos o acesso aos nós dos usuários, isso imediatamente eliminou uma grande classe de problemas.
A primeira vantagem é que, com o tempo, os iniciantes terão que aprender menos. Muitas vezes acontece que quando um recém-chegado entra no sistema, ele começa a arrancar todo o cabelo, porque nos primeiros 1-2 meses ele tenta descobrir como liberar tudo, se o sistema é grande e dura muito, muitos anéis anuais crescem. Kubernetes facilita as coisas.Em segundo lugar, o Kubernetes não faz isso sozinho, mas permite que você faça um curto ciclo de liberação. Um CI criado de consolidação, o CI criou uma imagem, aumentou automaticamente, você pressionou um botão e tudo entrou em produção. Isso reduz bastante o tempo de liberação.A seguir está a divisão do código. Nosso sistema e a maioria de seus sistemas coletam configurações de diferentes níveis em um único local, ou seja, você possui um código de infraestrutura, um código comercial e todas as lógicas são misturadas em um único local. No Kubernetes, isso não estará pronto para uso, escolher o conceito certo ajuda a evitar isso com antecedência.Uma comunidade grande e muito ativa, o que significa um grande número de mudanças. A maior parte do que mencionei nos últimos dois anos se tornou tão estável que pode ser liberada na produção. Talvez alguns deles tenham aparecido antes, mas não eram muito estáveis.Considero uma grande vantagem que, em um lugar, você possa ver os logs do aplicativo e do Kubernetes trabalhando com seu aplicativo, o que é inestimável. E não há acesso aos nós. Quando removemos o acesso aos nós dos usuários, isso imediatamente eliminou uma grande classe de problemas. A segunda parte das vantagens é um pouco mais conceitual. A maioria da comunidade Kubernetes vê a parte da tecnologia. Mas vimos a parte do gerenciamento conceitual. Depois de mudar para o Kubernetes, e se estiver configurado corretamente, o infracommand (ou back-end - não sei como você o chama corretamente) não será mais necessário para liberar aplicativos.O usuário deseja descarregar o aplicativo, ele não virá solicitá-lo, mas basta iniciar um novo pod, existe um comando para isso. A equipe de infraestrutura não é necessária para investigar problemas. Basta olhar para os logs, nosso conjunto de designs não é tão grande, existe uma lista pela qual é muito fácil encontrar o problema. Sim, às vezes é necessário suporte se o problema estiver no Kubernetes, por exemplo, mas com mais freqüência o problema está nos aplicativos.Adicionamos orçamento de erro. Este é o seguinte conceito: cada equipe possui estatísticas sobre quantos problemas estão ocorrendo na produção. Se houver muitos problemas, a equipe corta os lançamentos até levar algum tempo. Isso é bom porque a equipe monitorará seriamente que seus lançamentos são muito estáveis. Precisa de novas funcionalidades - libere. Deseja liberar às duas da manhã - por favor. Se após os lançamentos você tiver apenas “nove” no SLA - faça o que quiser, tudo estará estável, você poderá fazer qualquer coisa. No entanto, se a situação for pior, provavelmente não teremos permissão para liberar nada além de correções.Isso é conveniente tanto para a estabilidade do sistema quanto para o clima dentro da equipe. Deixamos de ser a "Polícia Moral", impedindo-nos de liberá-la tarde da noite. Faça o que quiser enquanto tiver um bom orçamento de erros. Isso reduz muito o estresse dentro da empresa.Você pode usar o e - mail ou o tweet para entrar em contato comigo : @gliush .E no final, existem muitos links para você, você pode baixar e ver tudo:
A segunda parte das vantagens é um pouco mais conceitual. A maioria da comunidade Kubernetes vê a parte da tecnologia. Mas vimos a parte do gerenciamento conceitual. Depois de mudar para o Kubernetes, e se estiver configurado corretamente, o infracommand (ou back-end - não sei como você o chama corretamente) não será mais necessário para liberar aplicativos.O usuário deseja descarregar o aplicativo, ele não virá solicitá-lo, mas basta iniciar um novo pod, existe um comando para isso. A equipe de infraestrutura não é necessária para investigar problemas. Basta olhar para os logs, nosso conjunto de designs não é tão grande, existe uma lista pela qual é muito fácil encontrar o problema. Sim, às vezes é necessário suporte se o problema estiver no Kubernetes, por exemplo, mas com mais freqüência o problema está nos aplicativos.Adicionamos orçamento de erro. Este é o seguinte conceito: cada equipe possui estatísticas sobre quantos problemas estão ocorrendo na produção. Se houver muitos problemas, a equipe corta os lançamentos até levar algum tempo. Isso é bom porque a equipe monitorará seriamente que seus lançamentos são muito estáveis. Precisa de novas funcionalidades - libere. Deseja liberar às duas da manhã - por favor. Se após os lançamentos você tiver apenas “nove” no SLA - faça o que quiser, tudo estará estável, você poderá fazer qualquer coisa. No entanto, se a situação for pior, provavelmente não teremos permissão para liberar nada além de correções.Isso é conveniente tanto para a estabilidade do sistema quanto para o clima dentro da equipe. Deixamos de ser a "Polícia Moral", impedindo-nos de liberá-la tarde da noite. Faça o que quiser enquanto tiver um bom orçamento de erros. Isso reduz muito o estresse dentro da empresa.Você pode usar o e - mail ou o tweet para entrar em contato comigo : @gliush .E no final, existem muitos links para você, você pode baixar e ver tudo:- Rede nativa de contêiner - Comparação
- Entrega contínua por Jez Humble, David Farley.
- Contêineres não são VMs
- Distribuição do Docker (registro de imagem)
- Quay - Registro de imagens como serviço
- etcd-operator - Gerente do cluster etcd no topo do Kubernetes
- Dex - OIDC (OpenID Connect Identity) e o provedor OAuth 2.0 com conectores conectáveis
- awsudo - utilitário sudo-like para gerenciar credenciais da AWS
- Autoscaling-related components for Kubernetes
- Simon's cat
- Helm: Kubernetes package manager
- Geodesic: framework to create your own cloud platform
- Calico: Configuring IP-in-IP
- Sensu: Open-core monitoring system
- InfluxDB: Scalable datastore for metrics, events, and real-time analytics
- Cernan: Telemetry and logging aggregation server
- Prometheus: Open Source monitoring solution
- Heapster: Compute Resource Usage Analysis and Monitoring of Container Clusters
- Stern: Multi pod and container log tailing for Kubernetes
- Minikube: tool to run Kubernetes locally
- Docker machine driver fox xhyve native OS X Hypervisor
- Drone: Continuous Delivery platform built on Docker, written in Go
- Borg, Omega and Kubernetes
- Container-Native Networking — Comparison
- Bug in minikube when working with xhyve driver.
Minuto de publicidade. Se você gostou deste relatório da conferência DevOops - observe que em 14 de outubro o novo DevOops 2018 será realizado em São Petersburgo, haverá muitas coisas interessantes em seu programa. O site já tem os primeiros oradores e relatórios.