Prefácio
A implementação de trie do PHP descrita aqui torna o dicionário muito gordo até agora, o que leva um bom tempo para carregar na memória, o que uniformiza a velocidade muito boa de seu trabalho. A velocidade da pesquisa é de ~ 80 mil palavras por segundo. O dicionário é feito da lista de lemas do dicionário opencorpora.org e inclui 389844 palavras. Na forma não compactada, o dicionário pesa ~ 150mb e gzip compactado ~ 6mb. No entanto, bons resultados de desempenho provam que, em PHP puro, você pode criar uma árvore de prefixos totalmente funcional.
Peço aos programadores com a ajuda de críticos literários que não escrevam comentários maliciosos. Este artigo deve ser interessante para iniciantes, como eu. Com preguiça de ler, você pode ver imediatamente o código no
github .
Como tudo começou
Há já algum tempo que estou desenvolvendo a ideia de escrever um analisador morfológico para meus projetos PHP, que poderão conduzir rapidamente análises morfológicas de determinadas palavras, além de transformar as palavras na forma morfológica desejada.
O PHP já possui uma biblioteca semelhante chamada phpmorhy. Funciona muito rapidamente e eu o usaria e não inventaria nada, mas o compilador de dicionário é feito como um aplicativo não PHP separado, o que torna impossível o uso dessa biblioteca. A própria biblioteca é construída com base no tão esperado dicionário AOT, que reduz ainda mais sua utilidade.
Semanas e meses se passaram, eu li
um artigo de Khabrovchanin, depois
um artigo de I. Segalovich sobre um algoritmo morfológico rápido para um mecanismo de pesquisa, depois vários artigos diferentes.
Pouco a pouco, amadureci ao escrever meu próprio
lunapark com blackjack e os ossos de um analisador morfológico. Penso: "
Bem, o progresso avançou, em PHP você já pode analisar o genoma humano! "
Peguei o dicionário opencorpora.org, coloquei no mysql e obtive uma velocidade de pesquisa de 2 mil palavras por segundo. É necessário carregar o dicionário na memória, eu acho. E aqui acontece que, para ter estruturas de dados regulares disponíveis no PHP, como uma matriz ou um objeto, você precisa armazenar cerca de 3 GB de RAM para um dicionário de 3 milhões. Todas as implementações de php trie que apareceram para mim foram adequadas apenas como um tutorial para demonstrar a lógica do trabalho, uma vez que elas próprias foram construídas em estruturas nativas de armazenamento de dados PHP.
Dispositivo de armazenamento de dicionário e princípio de operação
Onde quer que eu tenha conseguido ler, ouvir ou examinar a árvore de prefixos, ela não explica como os dados serão armazenados na memória. Aqui temos o nó, e aqui estão seus herdeiros, e aqui está a bandeira do fim da palavra, que não é mostrada sob o capô. Portanto, eu tive que inventar um método de armazenamento.
Como você sabe, a árvore de prefixos trie consiste em nós. Um nó armazena um prefixo, links para nós subsequentes (descendentes) e um ponteiro para o fato de que esse prefixo é o último da cadeia. O indiano diz de maneira bastante inteligível sobre isso
aqui .
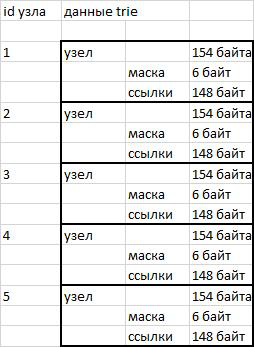
Os nós na minha implementação trie são blocos de dados de comprimento fixo de 154 bytes. Os primeiros 6 bytes (48 bits) contêm a máscara de bits dos herdeiros. Os primeiros 46 bits são o alfabeto russo, números, aspas, hífen e apóstrofo. O apóstrofo foi adicionado porque no dicionário opencorpora.org há a palavra "costa do marfim", que usa o sinal de apóstrofo. O 47º bit é usado para armazenar a palavra flag end. Os seguintes 148 bytes após a máscara de bits são usados para armazenar referências aos herdeiros do nó. 3 bytes por caractere (46 * 3 = 148).
Os nós são armazenados como dados binários em uma sequência. O acesso à seção desejada é realizado usando a função substr () e a subsequente descompactação () da descompactação.
O uso de nós de comprimento fixo simplifica o processo de endereçamento. Para alternar para o nó desejado, basta saber o número de série (id) e o comprimento do nó. Multiplicamos o número de série pelo comprimento e descobrimos o deslocamento em relação ao início da linha - tudo é muito simples.
fig. 1 Esquema de armazenamento
Desvantagens
O esquema de armazenamento usado simplifica o endereçamento, mas consome espaço. O armazenamento de 380 mil palavras requer pouco mais de um milhão de nós. 154 bytes * 1.000.000 de nós = 146,86 megabytes. I.e. aproximadamente 400 bytes por palavra. Se você escrever palavras em um arquivo de texto simples codificado em utf8, essas mesmas 380 mil palavras poderão caber em 16 megabytes.
Planos
Para usar a memória de maneira mais racional, desejo alternar para um comprimento variável de nós e, como um link, terei que registrar não o ID do nó, mas sua localização em bytes. A localização do link para o nó desejado será determinada da seguinte maneira. No exemplo da palavra "abv".
A letra "a" é a primeira do alfabeto; portanto, seu nó também é o primeiro, respectivamente, o deslocamento 0. Leia 6 bytes, começando em 0.
$str = substr($dic, 0, 6);
Desembale a linha:
$mask = (ord($str[5]) << 40) + (ord($str[4]) << 32) + (ord($str[3]) << 24) + (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Olhamos para a máscara do segundo bit (letra "b")
bit_get($mask, 2);
O bit está definido, agora contamos o número de bits elevados na máscara como 2. Digamos que o bit "a" do nosso nó também seja aumentado, portanto, o nosso bit da letra "b" será o segundo bit aumentado. Deslocamento de contagem para ler o link
$offset = 6 + 3;
Máscara de 6 bytes + 3 bytes, que o primeiro link ocupa, resulta em 9 bytes. Lemos o pedaço de fio desejado.
$str = substr($dic, $offset, 3);
Descompacte o link:
$ref = (ord($str[2]) << 16) + (ord($str[1]) << 8) + ord($str[0]);
Vá para o próximo nó e repita tudo novamente. Na última letra, verificamos a presença de 47 bits na máscara, se estiver definida, há uma palavra de pesquisa em nosso teste.
Espero que seja possível manter uma velocidade de pelo menos 50 mil palavras por segundo.
Agradecimentos
Quero agradecer aos participantes do fórum nulled.cc e php.ru por sua ajuda nas funções bit a bit.