Deixe-me adicionar as linhas "aprendizado de máquina" e "redes neurais" ao seu currículo em 5 a 10 minutos de leitura e compreensão de um pequeno artigo? Para aqueles que estão longe de programar, vou dissipar todos os mitos sobre a complexidade da IA e mostrar que a maioria de todos os projetos de aprendizado de máquina são baseados em princípios extremamente simples. Vamos lá - só temos cinco minutos.
Considere o exemplo mais básico de redes neurais - perceptrons; Eu mesmo depois desse exemplo, percebi completamente como as redes neurais funcionam, por isso, se eu não bagunçar, e você pode entender. Lembre-se: não há mágica aqui, matemática simples no quinto ano do ensino médio.
Suponha que tenhamos três condições binárias diferentes (sim ou não) e uma solução binária na saída (sim ou não):

Um modelo simples com três entradas e uma saída. Esse modelo pode funcionar perfeitamente para pessoas diferentes e gerar resultados diferentes, dependendo de como eles treinaram a rede neural. Mas o que é uma rede neural? Estes são apenas blocos separados - neurônios conectados entre si. Vamos criar um neurônio simples a partir de três neurônios:

O que você vê entre entrada e saída são neurônios. Até agora, eles não estão conectados a nada, mas isso também reflete sua principal característica, que todos esquecem de dizer: eles são um shnyag completamente abstrato. Ou seja, os próprios neurônios não resolvem nada, decidem exatamente o que desenharemos a seguir. Enquanto isso, lembre-se: os neurônios não fazem absolutamente nada, exceto para otimizar e simplificar o conceito para humanos. Vamos desenhar a parte mais importante do neurônio - a conexão:
Uau, isso soa como algo super legal. Agora vamos adicionar um pouco de magia, de alguma forma treinar o neurônio com o calcanhar esquerdo, torcer no lugar, rir, jogar pimenta no ombro direito do vizinho e tudo vai dar certo, certo? Acontece que ainda é mais fácil.
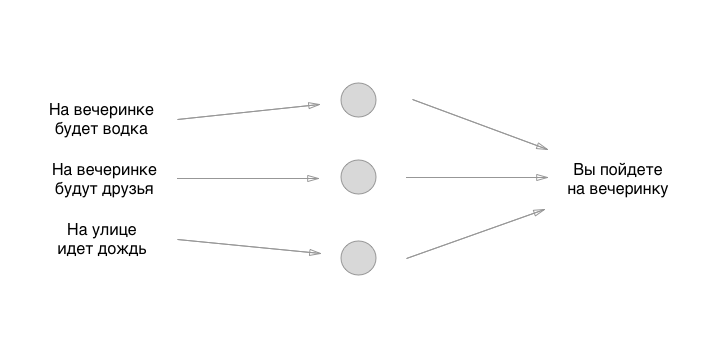
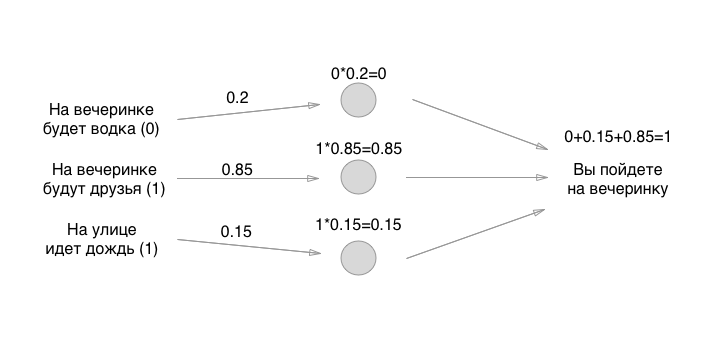
Cada entrada à esquerda possui um valor: 0 ou 1, sim ou não. Vamos adicionar esses valores à entrada, suponha que não haverá vodka na festa, haverá amigos, deixe chover:
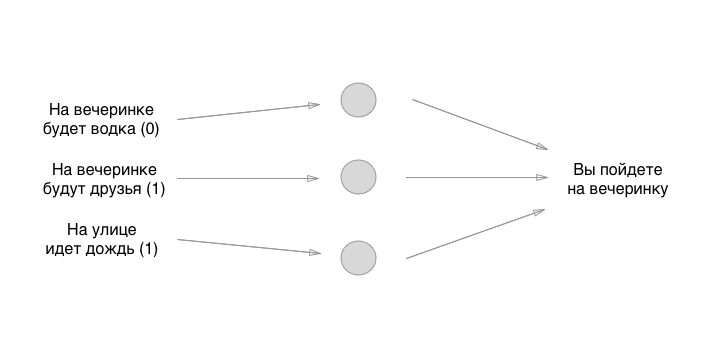
Então, nós descobrimos isso. O que faremos a seguir? E aqui está divertido: vamos usar a maneira mais antiga de definir o estado inicial dos neurônios - o grande acaso:
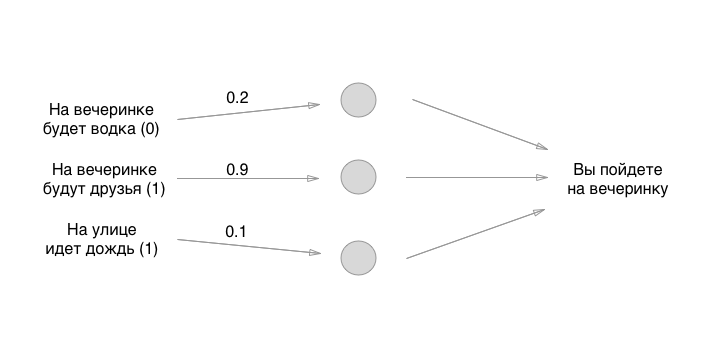
Os números que estabelecemos são os pesos dos títulos. Lembra que os neurônios estão vazios? Portanto, as comunicações são exatamente o que consiste em uma rede neural. Mas quais são os pesos dos títulos? Essas são as coisas pelas quais multiplicamos os valores de entrada e os armazenamos temporariamente em neurônios vazios. Na verdade, não o armazenamos, mas por conveniência, imaginaremos que algo pode ser colocado nos neurônios:
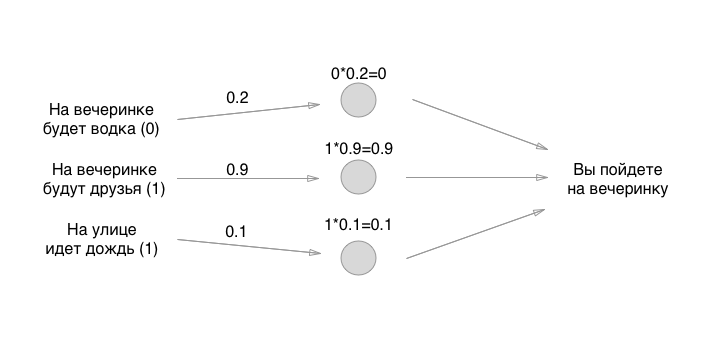
Como você gosta de matemática? Poderia multiplicar? Espere, a parte mais difícil está apenas começando! Em seguida, adicionamos os valores (em uma das implementações do perceptron):

Bem, é isso! O neurônio é criado e você pode usá-lo para qualquer necessidade. Se o valor for maior que 0,5, você precisará ir à festa. Se for menor ou igual, você não precisa ir à festa. Obrigado pela atenção!
Claro, o modelo acima tem pouco benefício prático, precisamos treiná-lo. A frase assustadora "neurônios de trem" não é? Não é assim. Tudo é desajeitado e o mais simples possível: você pega dados de entrada aleatórios (como fizemos), executa a entrada através desses três neurônios, olha a resposta - seja positiva (vá para a festa) - e verifica se o neurônio previu a resposta corretamente ou não . Se estiver certo, não faça nada. Se estiver errado, você muda levemente os pesos dos neurônios (um de cada vez ou todos de uma vez) em qualquer direção. Por exemplo, assim:
E, novamente, você confere: oh, bem, novamente ele diz para ir à festa, quando eu não quero ir lá! E você novamente muda levemente os pesos (na mesma direção, provavelmente) um pouco e passa esses dados de entrada pelos neurônios e depois compara o resultado - e deixa os pesos em paz ou os move novamente. E então trilhões, quadrilhões de vezes e com todos os tipos de dados de entrada diferentes. Aqui, é claro, temos apenas 8 combinações de entradas, mas existem tarefas diferentes (mais sobre elas abaixo).
Esse é o princípio principal do trabalho das redes neurais - a multiplicação é necessária para a diferenciação, e a compreensão do trabalho do perceptron é necessária para criar redes convolucionais, neurônios recursivos e até algum jogo exótico.
Como resultado, tendo treinado um neurônio nas decisões tomadas por uma pessoa, passando por cima dele bilhões de vezes, passando por todos os pesos possíveis dos neurônios, você finalmente chegará a um meio ideal e dourado para que a pessoa insira três valores iniciais - e a máquina o execute já estável e funcionando fórmula com três neurônios e dá uma resposta.
As únicas três incógnitas em nossa eram os pesos das conexões dos neurônios, e foram precisamente eles que repassamos. Portanto, digo que os neurônios são manequins que não resolvem nada, e os reis de um banquete são os pesos das conexões.
Então tudo é simples: em vez de uma camada de neurônios, fazemos duas e novamente classificamos tudo de acordo com exatamente os mesmos princípios, apenas todos os neurônios já atribuem valores a outros neurônios. Se a princípio tivéssemos apenas 3 conexões, agora 3 + 9 conexões com pesos. E então três camadas, quatro camadas recursivas, fixadas em si mesmas e em jogos similares:
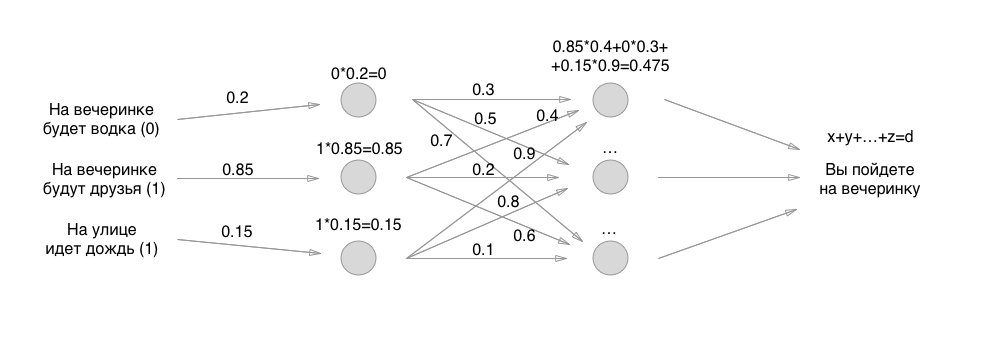
Mas, pergunte-me, eles dizem, qual é o resultado de algo complicado nos neurônios? Por que os especialistas em aprendizado de máquina são pagos tanto? E o problema é exatamente como implementar os perceptrons acima: existem tantas nuances diferentes que você é atormentado a listar.
E se na entrada você tiver uma foto e precisar categorizar todas as fotos dos cães e gatos? As imagens têm tamanhos de 512x512, cada pixel é uma entrada - então, quantos valores perseguiremos ao longo dos neurônios? Existem neurônios convolucionais para isso! Esse é um shnyaga que leva 9 pixels um ao lado do outro, por exemplo, e calcula a média de seus valores RGB. Acontece que comprime a imagem para um processamento mais rápido. Ou, por exemplo, elimina completamente a cor vermelha da imagem, pois não é importante (estamos procurando, por exemplo, apenas vestidos verde-azulados). Essas são redes convolucionais - uma camada adicional de "neurônios" na entrada que processa a entrada para uma visão clara e simplificada para a rede.
Você também precisa entender quanto e em qual direção mudar pesos - existem todos os tipos de algoritmos simples para entender que consideram o erro do final - da direita (do resultado) para a esquerda (para a primeira camada de neurônios) - um dos algoritmos é chamado Propagação Traseira.
Existem todo tipo de algoritmos simples para normalizar valores - para que você obtenha números não de 0 a 500 000, mas de 0 a 1 na saída ou no meio ao adicionar - isso simplifica muito os cálculos e a matemática computacional.
Como você já pode entender, especialistas realmente legais em aprendizado de máquina não apenas conhecem a maioria dos métodos existentes na construção de redes neurais otimizadas, mas também apresentam suas próprias abordagens, começando pela compreensão mais simples, mas profunda, das relações de causa e efeito entre como construir um perceptron e por que funciona, em termos de matemática. Eles não apenas podem fazer o neurônio funcionar, mas também podem alterar o algoritmo ou usar outro algoritmo para continuar executando de maneira rápida e otimizada.
Bem, isso é tudo - eu lhe dei a base para entender o que são redes neurais. Também espero que eu mostrei a você que o diabo não é tão terrível quanto ele é pintado - tudo acabou incrivelmente simples, no nível de multiplicação e adição. Aconselho você a começar a assistir aos tutoriais no YouTube ou na Udemy - os caras são incríveis para explicar tudo de bom.
Da próxima vez, quando eles pedirem dinheiro para um projeto de aprendizado de máquina, sacuda os mendigos dos mendigos com o esboço do trabalho das redes neurais - quais camadas, como elas estão organizadas, por que e por que, aqui está e não está. Tudo isso no nível de no máximo 11 classes será (trata-se de integrais e diferenciais) - e ocorrerá na descrição uma vez, talvez duas. Embora o projeto não possua esse modelo (quais camadas e como estão localizadas) - o projeto não possui um produto, porque essa estrutura são as primeiras 2-4 semanas de um especialista em aprendizado de máquina.
PS, um exemplo de explicação, retirei com desprezo
um magnífico vídeo sobre redes neurais. Eu recomendo fortemente que você olhe - obrigado pessoal! os assinantes ajudaram a restaurar o link para o vídeo original, um exemplo do qual tentei recuperar a memória. Se alguém estiver interessado em codificar a tarefa acima, convido você a assistir este vídeo aqui. Muito obrigado aos autores!