Esta
notícia (+
pesquisa ) sobre a invenção do gerador de memes por cientistas da Universidade de Stanford me levou a escrever um artigo. No meu artigo, tentarei mostrar que você não precisa ser um cientista de Stanford para fazer coisas interessantes com redes neurais. No artigo, descrevo como, em 2017, treinamos uma rede neural em um corpo de aproximadamente 30.000 textos e a forçamos a gerar novos memes e memes da Internet (sinais de comunicação) no sentido sociológico da palavra. Descrevemos o algoritmo de aprendizado de máquina que usamos, as dificuldades técnicas e administrativas que encontramos.
Um pouco de fundo sobre como chegamos à ideia de um neuro-escritor e em que consistia exatamente. Em 2017, fizemos um projeto para um site público da Vkontakte, cujo nome e captura de tela os moderadores do Habrahabr proibiram de publicar, considerando sua menção como PR "auto". O público existe desde 2013 e une as postagens com a idéia geral de decompor o humor em uma linha e separar as linhas com o símbolo "@":
@
@
O número de linhas pode variar, o gráfico pode ser qualquer. Na maioria das vezes, isso é humor ou notas sociais afiadas sobre os fatos desenfreados da realidade. Em geral, esse design é chamado de "buhurt".
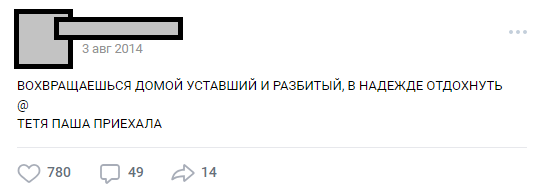 Um dos típicos buhurts
Um dos típicos buhurtsAo longo dos anos, o público se transformou em conhecimento interno (caracteres, tramas, locais) e o número de postagens excedeu 30.000.No momento de analisar as necessidades do projeto, o número de linhas de origem do texto excedia meio milhão.
Parte 0. O surgimento de idéias e equipes
Após a popularidade em massa das redes neurais, a idéia de treinar a RNA em nossos textos ficou no ar por cerca de seis meses, mas foi finalmente formulada com o E7su em dezembro de 2016. Ao mesmo tempo, o nome foi inventado ("Neurobugurt"). Naquela época, a equipe interessada no projeto era composta por apenas três pessoas. Todos éramos estudantes sem experiência prática em algoritmos e redes neurais. Pior, nem sequer tínhamos uma GPU adequada para treinamento. Tudo o que tínhamos era entusiasmo e confiança de que essa história poderia ser interessante.
Parte 1. A formulação da hipótese e tarefas
Nossa hipótese acabou sendo a suposição de que, se você misturar todos os textos publicados em três anos e meio e treinar a rede neural nesse edifício, poderá obter:
a) mais criativo que as pessoas
b) engraçado
Mesmo que as palavras ou letras no buhurt pareçam confundidas e dispostas aleatoriamente à máquina - acreditávamos que isso poderia funcionar como um serviço de fãs e ainda agradaria aos leitores.
A tarefa foi bastante simplificada pelo fato de o formato dos buhurts ser essencialmente textual. Portanto, não precisamos mergulhar na visão de máquina e em outras coisas complexas. Outra boa notícia foi que todo o corpo de textos é muito semelhante. Isso tornou possível não usar o aprendizado reforçado - pelo menos nos estágios iniciais. Ao mesmo tempo, entendemos claramente que criar um gravador de rede neural com saída legível mais de uma vez não é tão fácil. O risco de dar à luz um monstro que jogaria cartas aleatoriamente era muito grande.
Parte 2. Preparação do corpo dos textos
Acredita-se que a fase de preparação possa demorar muito tempo, pois está associada à coleta e limpeza de dados. No nosso caso, acabou por ser bastante curto: um pequeno
analisador foi escrito que extraiu cerca de 30k posts da parede da comunidade e os colocou em um
arquivo txt .
Não limpamos os dados antes do primeiro treinamento. No futuro, isso representou uma piada cruel conosco, porque, devido ao erro que surgiu nesta fase, não conseguimos trazer os resultados de forma legível por um longo tempo. Mas mais sobre isso mais tarde.
 Arquivo de tela com hambúrgueres
Arquivo de tela com hambúrgueresParte 3. Anúncio, refinamento da hipótese, escolha do algoritmo
Usamos um recurso acessível - um grande número de assinantes públicos. A suposição era que entre 300.000 leitores existem vários entusiastas que possuem redes neurais em um nível suficiente para preencher as lacunas no conhecimento de nossa equipe. Partimos da idéia de anunciar amplamente a competição e atrair entusiastas de aprendizado de máquina, até a discussão do problema formulado. Depois de escrever os textos, contamos às pessoas sobre a nossa ideia e esperamos uma resposta.
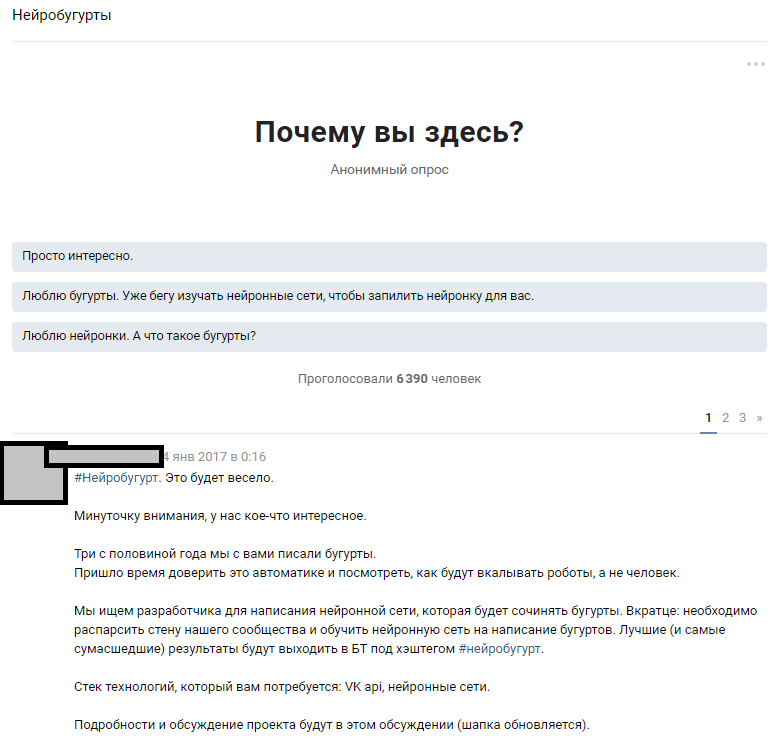 Anúncio de discussão temática
Anúncio de discussão temáticaA reação das pessoas excedeu nossas expectativas mais loucas. A discussão do fato de que vamos treinar uma rede neural espalhou o holivar por quase 1000 comentários. A maioria dos leitores simplesmente desapareceu e tentou imaginar como seria o resultado. Cerca de 6.000 pessoas analisaram a discussão temática e mais de 50 amadores interessados deixaram comentários para os quais testamos
814 linhas de buhurt para a realização de testes e treinamento iniciais. Cada pessoa interessada pode pegar um conjunto de dados e aprender o algoritmo mais interessante para ele, e depois discutir conosco e com outros entusiastas. Anunciamos antecipadamente que continuaremos a trabalhar com os participantes cujos resultados serão mais legíveis.
O trabalho começou: alguém montou silenciosamente um gerador nas cadeias de Markov, alguém tentou várias implementações com um github e a maioria ficou louca na discussão e nos convenceu com espuma na boca de que nada resultaria disso. Isso iniciou a parte técnica do projeto.
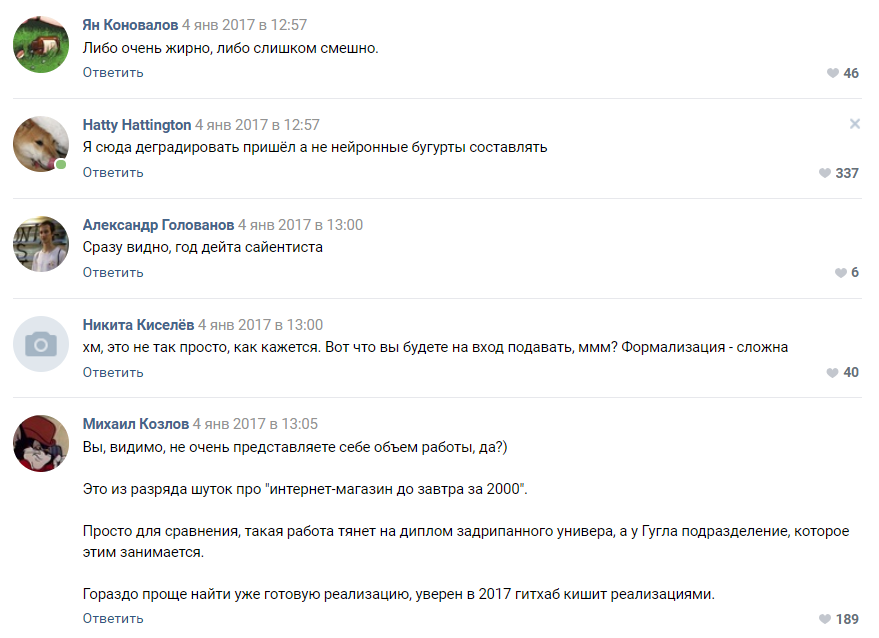
Algumas sugestões de entusiastas
As pessoas ofereceram dezenas de opções para implementação:
- Cadeias de Markov.
- Encontre uma implementação pronta de algo semelhante ao GitHub e treine-a.
- Um gerador de frases aleatórias escrito em Pascal.
- Consiga um negro literário que escreverá bobagens aleatórias, e passaremos isso como uma saída de rede neural.
 Avaliação da complexidade do projeto de um dos assinantes
Avaliação da complexidade do projeto de um dos assinantesA maioria dos comentaristas concordou que nosso projeto está fadado ao fracasso e nem chegaremos ao estágio de protótipo. Como entendemos mais adiante, as pessoas ainda tendem a perceber as redes neurais como algum tipo de magia negra que acontece na “cabeça de Zuckerberg” e nas divisões secretas do Google.
Parte 4. Seleção de algoritmos, treinamento e expansão da equipe
Depois de algum tempo, a campanha que lançamos para idéias de crowdsourcing para o algoritmo começou a dar seus primeiros frutos. Temos cerca de 30 protótipos em funcionamento, a maioria dos quais deu um absurdo completamente ilegível.
Nesta fase, encontramos pela primeira vez uma desmotivação da equipe. Todos os resultados foram muito semelhantes aos buhurts e, na maioria das vezes, representavam abracadabra de letras e símbolos. O trabalho de dezenas de entusiastas foi ao pó e isso desmotivou a eles e a nós.
O algoritmo baseado em pyTorch mostrou-se melhor que outros. Foi decidido tomar essa implementação e o algoritmo LSTM como base. Reconhecemos o assinante que o propôs como vencedor e começamos a trabalhar para melhorar o algoritmo junto com ele. Nossa equipe distribuída cresceu para quatro pessoas. O fato engraçado aqui é que o
vencedor do concurso , como se viu, tinha apenas 16 anos de idade. A vitória foi seu primeiro prêmio real no campo da ciência de dados.
Para o primeiro treinamento, um conjunto de 8 placas gráficas GXT1080 foi alugado.
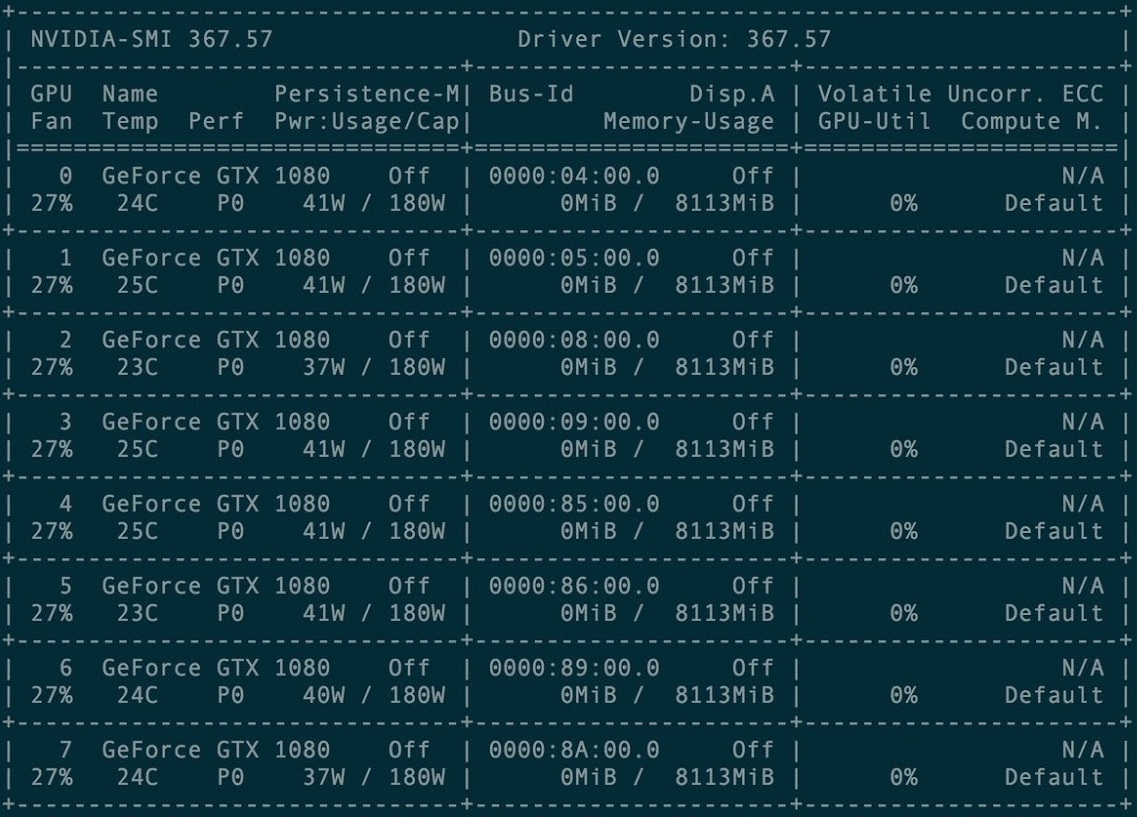 Console de gerenciamento de cluster de cartões
Console de gerenciamento de cluster de cartõesO repositório original e todos os manuais do projeto Torch-rnn estão aqui:
github.com/jcjohnson/torch-rnn . Posteriormente, com base nisso, publicamos
nosso repositório , no qual existem nossas fontes, o Leia-me para instalação, bem como os próprios neurobugurts concluídos.
Nas primeiras vezes em que treinamos usando uma configuração pré-configurada em um cluster de GPU pago. A configuração acabou não sendo tão difícil - basta apenas as instruções do desenvolvedor do Torch e a ajuda da administração de hospedagem, incluída no pagamento.
No entanto, rapidamente encontramos dificuldades: cada treinamento custava o tempo de aluguel da GPU - o que significa que simplesmente não havia dinheiro no projeto. Por isso, em janeiro-fevereiro de 2017, realizamos treinamentos nas instalações adquiridas e tentamos lançar a geração em nossas máquinas locais.
Qualquer texto é adequado para o treinamento do modelo. Antes do treinamento, é necessário pré-processá-lo, para o qual o Torch possui um algoritmo preprocess.py especial que converte seu my_data.txt em dois arquivos: HDF5 e JSON:
O script de pré-processamento é executado assim:
python scripts/preprocess.py \ --input_txt my_data.txt \ --output_h5 my_data.h5 \ --output_json my_data.json
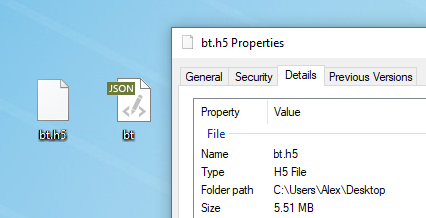 Após o pré-processamento, dois arquivos aparecem nos quais a rede neural será treinada no futuro
Após o pré-processamento, dois arquivos aparecem nos quais a rede neural será treinada no futuroOs vários sinalizadores que podem ser alterados no estágio de pré-processamento são descritos
aqui . Também é possível executar o
Torch no Docker , mas o autor do artigo não o verificou.
Treinamento em redes neurais
Após o pré-processamento, você pode prosseguir para o treinamento do modelo. Na pasta HDF5 e JSON, é necessário executar o utilitário th, que apareceu com você, se você instalou o Torch corretamente:
th train.lua -input_h5 my_data.h5 -input_json my_data.json
O treinamento leva uma quantidade enorme de tempo e gera arquivos no formato cv / checkpoint_1000.t7, que são os "pesos" da nossa rede neural. Esses arquivos pesam uma quantidade impressionante de megabytes e contêm a força dos links entre letras específicas no seu conjunto de dados original.
 Uma rede neural é frequentemente comparada com o cérebro humano, mas me parece uma analogia muito mais clara com uma função matemática que pega parâmetros na entrada (seu conjunto de dados) e fornece o resultado (novos dados) na saída.
Uma rede neural é frequentemente comparada com o cérebro humano, mas me parece uma analogia muito mais clara com uma função matemática que pega parâmetros na entrada (seu conjunto de dados) e fornece o resultado (novos dados) na saída.No nosso caso, cada treinamento em um cluster de 8 GTX 1080 em um conjunto de dados de 500.000 linhas levou cerca de uma hora ou duas, e um treinamento semelhante em um tipo de CPU i3-2120 levou cerca de 80 a 100 horas. No caso de treinamento mais longo, a rede neural começou a se treinar rigidamente - os símbolos se repetiam com muita frequência, caindo em longos ciclos de preposições, conjunções e palavras introdutórias.
É conveniente escolher a frequência dos pontos de verificação e, durante um treinamento, você receberá imediatamente muitos modelos: do menos treinado (ponto de verificação_1000) ao reciclado (ponto de verificação_1000000). Apenas espaço suficiente seria suficiente.
Nova geração de texto
Depois de receber pelo menos um arquivo pronto com pesos (ponto de verificação _ *******), você pode prosseguir para a próxima e mais interessante etapa: começar a gerar textos. Para nós, foi um verdadeiro momento de verdade, porque pela primeira vez obtivemos algum resultado tangível - um bugurt escrito por uma máquina.
Nesse ponto, finalmente paramos de usar o cluster e todas as gerações foram realizadas em nossas máquinas de baixa potência. No entanto, ao tentar iniciar localmente, simplesmente não conseguimos seguir as instruções e instalar o Torch. A primeira barreira foi o uso de máquinas virtuais. No Ubuntu 16 virtual, o stick não decola - esqueça. O StackOverflow costumava ser útil, mas alguns erros eram tão pouco triviais que a resposta só podia ser encontrada com grande dificuldade.
A instalação do Torch em uma máquina local interrompeu o projeto por algumas semanas: encontramos todos os tipos de erros ao instalar vários pacotes necessários, também enfrentamos problemas de virtualização (virtualenv .env) e, por fim, não o usamos. Várias vezes o suporte foi demolido para o nível sudo rm -rf e foi simplesmente instalado novamente.
Usando o arquivo resultante com pesos, pudemos começar a gerar textos em nossa máquina local:
 Uma das primeiras conclusões
Uma das primeiras conclusõesParte 5. Limpando textos
Outra dificuldade óbvia foi que o tópico das postagens é muito diferente, e nosso algoritmo não envolve nenhuma divisão e considera todas as 500.000 linhas como um texto único. Consideramos opções diferentes para agrupar o conjunto de dados e até estávamos prontos para quebrar manualmente o corpo dos textos por tópico ou colocar tags em vários milhares de buhurts (havia um recurso humano necessário para isso), mas constantemente enfrentávamos dificuldades técnicas ao enviar clusters ao aprender LSTM. Mudar o algoritmo e conduzir a competição novamente não parecia ser a idéia mais sensata em termos de tempo do projeto e motivação dos participantes.
Parecia que estávamos em um impasse - não podíamos agrupar buhurts, e o treinamento em um único conjunto de dados enorme produzia resultados duvidosos. Eu não queria dar um passo atrás e mudar o algoritmo e a implementação quase elevados - o projeto poderia simplesmente entrar em coma. A equipe desesperadamente não tinha conhecimento suficiente para resolver a situação normalmente, mas o bom e velho SME-KAL-OCHK-A veio em socorro. A solução final para a
muleta acabou sendo genialmente simples: no conjunto de dados original, separe os buhurts existentes um do outro com linhas vazias e treine LSTM novamente.
Organizamos as batidas em 10 espaços verticais após cada buhurt, repetimos o treinamento e, durante a geração, estabelecemos um limite no volume de saída de 500 caracteres (o comprimento médio de uma buhurt de “plotagem” no conjunto de dados original).
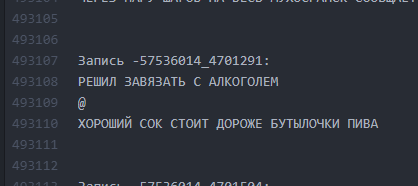 Como era. Intervalos entre textos são mínimos.
Como era. Intervalos entre textos são mínimos.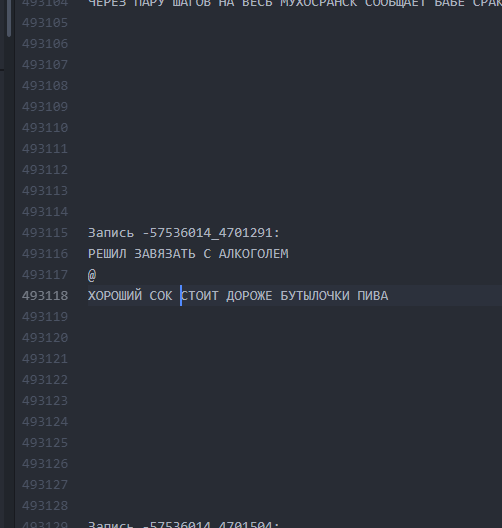 Como isso se tornou. Intervalos de 10 linhas permitem que o LSTM “entenda” que um bogurt acabou e outro começou.
Como isso se tornou. Intervalos de 10 linhas permitem que o LSTM “entenda” que um bogurt acabou e outro começou.Assim, foi possível alcançar que cerca de 60% de todos os buhurts gerados começaram a ter um gráfico legível (embora muitas vezes muito ilusório) ao longo de toda a extensão do buhurt, do começo ao fim. O comprimento de um gráfico era, em média, de 9 a 13 linhas.
Parte 6. Reciclagem
Tendo estimado a economia do projeto, decidimos não gastar mais com o aluguel de um cluster, mas investir na compra de nossos próprios cartões. O tempo de aprendizado aumentaria, mas, tendo comprado um cartão uma vez, poderíamos gerar novos buhurts constantemente. Ao mesmo tempo, frequentemente não era mais necessário realizar treinamento.
 Configurações de combate na máquina local
Configurações de combate na máquina localParte 7. Balanceando Resultados
Na virada de março a abril de 2017, treinamos novamente a rede neural, especificando os parâmetros de temperatura e o número de eras de treinamento. Como resultado, a qualidade da saída aumentou ligeiramente.
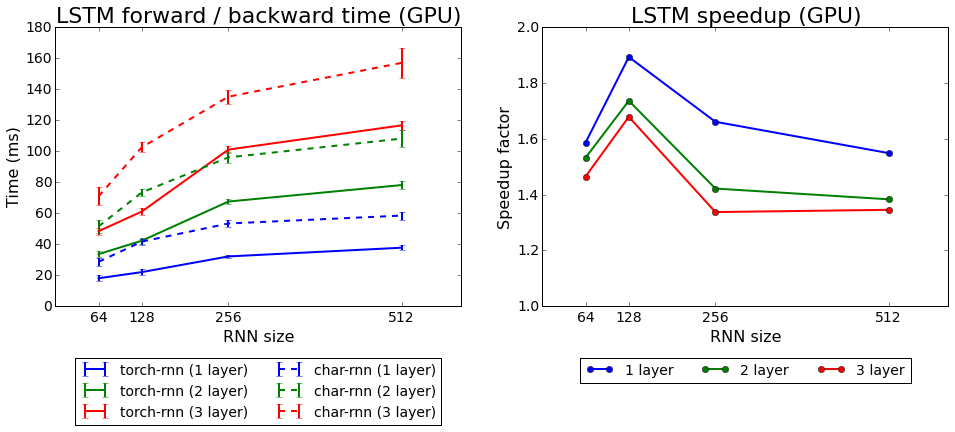 Velocidade de aprendizado da tocha-rnn em comparação com o char-rnn
Velocidade de aprendizado da tocha-rnn em comparação com o char-rnnTestamos os dois algoritmos que acompanham o Torch: rnn e LSTM. O segundo provou ser melhor.
Parte 8. O que alcançamos?
O primeiro neurobugurt foi publicado em 17 de janeiro de 2017 - imediatamente após o treinamento no cluster - e no primeiro dia foram coletados mais de 1000 comentários.
 Um dos primeiros neurobugurts
Um dos primeiros neurobugurtsOs neurobuguristas chegaram tão bem ao público que se tornaram uma seção separada, que ao longo do ano foi publicada com a hashtag # neurobugurt e divertidos assinantes. No total, em 2017 e início de 2018, geramos mais de
18.000 neurobugurtos , com uma média de 500 caracteres cada. Além disso, todo um movimento de paródias públicas apareceu, cujos participantes representavam neurobugures, reorganizando aleatoriamente frases em alguns lugares.

Parte 9. Em vez de uma conclusão
Com este artigo, eu queria mostrar que, mesmo que você não tenha experiência em redes neurais, esse sofrimento não é um problema. Você não precisa trabalhar em Stanford para fazer coisas simples, mas interessantes, com redes neurais. Todos os participantes do nosso projeto eram estudantes comuns, com suas tarefas, diplomas, trabalhos atuais, mas a causa comum nos permitiu levar o projeto à final. Graças à ideia cuidadosa, planejamento e energia dos participantes, conseguimos obter os primeiros resultados sensatos em menos de um mês após a formulação final da ideia (a maior parte do trabalho técnico e organizacional ocorreu nas férias de inverno de 2017).
 Mais de 18.000 buhurts gerados por máquina
Mais de 18.000 buhurts gerados por máquinaEspero que este artigo ajude alguém a planejar seu próprio projeto ambicioso com redes neurais. Peço para não julgar rigorosamente, já que este é meu primeiro artigo sobre Habré. Se você, como eu, um entusiasta do ML,
sejamos amigos .