Algum tempo atrás, um dos meus colegas disse que o local no controlador de domínio está se esgotando, não há lugar para colocar o servidor e a carga está aumentando e não está claro o que fazer, e você provavelmente precisará alterar todos os servidores disponíveis para os mais poderosos.
Naquela época, eu estava envolvido na tarefa de compilar agendas ideais e pensei - mas e se aplicarmos algoritmos de otimização para aumentar a utilização do servidor no controlador de domínio? A partir daqui, nasceu o projeto sobre o qual quero escrever.
Para usuários avançados, direi imediatamente que neste artigo falaremos sobre empacotamento de lixeira e, para os demais, que desejam aprender como economizar até 30% dos recursos do servidor usando cálculos relativamente simples, bem-vindo ao gato.
Portanto, temos um controlador de domínio com aproximadamente 100 servidores, que hospedam aproximadamente 7.000 máquinas virtuais. O que há dentro das máquinas virtuais - não sabemos e não devemos saber. É necessário colocar máquinas virtuais nos servidores para executar o SLA e, ao mesmo tempo, usar o número mínimo de servidores.
Nós sabemos:
- lista de servidores
- quantidade de recursos em cada servidor (tempo da CPU, núcleos da CPU, RAM, disco, disco io, rede io).
- lista de máquinas virtuais (VM)
- a quantidade de recursos consumidos por cada máquina virtual (tempo da CPU, núcleos da CPU, RAM, disco, disco io, rede io).
- consumo de recursos pelo sistema host nos servidores.
Precisamos distribuir máquinas virtuais entre os servidores para que cada um dos recursos em cada servidor não exceda a quantidade disponível do recurso e, ao mesmo tempo, use o número mínimo de servidores.
Essa tarefa na literatura científica é chamada de problema de empacotamento em lixeira (como será em russo?). Em termos simples, esta é uma tarefa sobre como colocar caixas pequenas de tamanhos arbitrários em caixas grandes e, ao mesmo tempo, usar o número mínimo de caixas grandes. O conhecido problema em matemática, NP-complete, é resolvido com precisão apenas por pesquisas exaustivas, cujo custo está crescendo combinatoriamente.
A figura abaixo ilustra a essência do algoritmo de embalagem de contêineres para o caso unidimensional:
 Fig. 1. Ilustração do problema da embalagem do compartimento, posicionamento não ideal
Fig. 1. Ilustração do problema da embalagem do compartimento, posicionamento não idealNa primeira figura, os itens são de alguma forma distribuídos entre as cestas e 3 cestas são usadas para colocá-las.
 Fig. 2. Ilustração do problema da embalagem do compartimento, posicionamento ideal
Fig. 2. Ilustração do problema da embalagem do compartimento, posicionamento idealA segunda imagem mostra a distribuição ideal, para a qual você precisa de apenas 2 cestas.
A formulação padrão do algoritmo de empacotamento de lixeira também pressupõe que todos os cestos sejam iguais. Nossos servidores não são os mesmos, pois foram comprados em momentos diferentes e sua configuração é diferente - número diferente de núcleos, memória, disco e potência do processador.
Uma solução abaixo do ideal pode ser obtida usando heurísticas, algoritmos genéticos, pesquisa em árvores monte-carlo e redes neurais profundas. Decidimos o algoritmo heurístico BestFit, que converge para uma solução não mais que 1,7 vezes pior que a ideal, bem como em algumas variações do algoritmo genético. Abaixo darei os resultados de sua aplicação.
Mas primeiro, vamos discutir o que fazer com métricas variáveis no tempo, como uso da CPU, disco io, rede io. A maneira mais fácil é substituir a métrica variável por uma constante. Mas como escolher o valor dessa constante? Pegamos o valor máximo da métrica por algum período de característica (anteriormente suavizando valores extremos dos valores). A semana acabou sendo um período característico no nosso caso, uma vez que a principal sazonalidade da carga estava associada a dias úteis e folgas.
Nesse modelo, cada máquina virtual recebe uma faixa de recursos do tamanho do valor máximo consumido, e cada VM é descrita pelas constantes uso máximo da CPU, RAM, disco, disco máximo io, rede máxima io.
Em seguida, usamos o algoritmo para calcular o empacotamento ideal e obter um mapa da localização da VM em servidores físicos.
A prática mostra que, se você não deixar uma certa margem para cada um dos recursos no servidor, quando a VM for alocada densamente, o servidor ficará sobrecarregado. Portanto, para uso da CPU, deixamos uma margem de 30%, para RAM 20%, para disco io - 20%, para rede io - 20%, esses limites são selecionados empiricamente.
Também temos vários tipos de discos (SSDs rápidos e HDDs lentos e baratos), para cada tipo de disco tomamos as métricas de disco e disco io separadamente, para que o modelo final se torne um pouco mais complicado e tenha mais dimensões.
O resultado da otimização do posicionamento da VM é mostrado no diagrama:
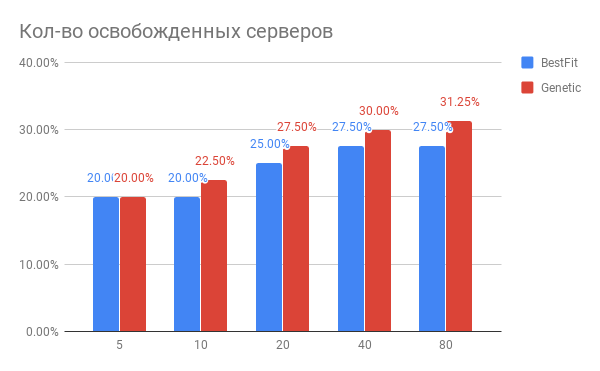 Fig. 3. O resultado da otimização do posicionamento das VMs nos servidores
Fig. 3. O resultado da otimização do posicionamento das VMs nos servidoresHorizontal - o número de servidores que foram otimizados, na vertical - o número de servidores liberados para as heurísticas do BestFit e para o algoritmo genético.
Que conclusões podem ser tiradas do diagrama?
- Para tarefas atuais, você pode usar 20 a 30% menos servidores.
- Quanto mais servidores você otimizar por vez, mais você ganha em%, com o número de servidores 40 e acima, ocorre saturação.
- O algoritmo genético é ligeiramente superior ao BestFit heurístico. Se quisermos melhorar ainda mais nossos resultados, vamos cavar nessa direção.
Que outros problemas surgiram na prática?
- Se você deseja agitar cerca de 100 servidores com 7.000 máquinas virtuais, o volume de migrações será muito significativo, de modo que toda a idéia será irrealizável. Mas se você trabalhar com grupos de 20 a 40 servidores em sequência, o efeito será quase o mesmo, mas o número de migrações será muitas vezes menor. E você pode otimizar seu DC em partes.
- Se você precisar fazer migrações ativas, poderá encontrar uma situação em que a migração não possa terminar. Isso significa que dentro da VM há uma gravação intensa no disco e / ou o estado da memória é alterado, e os estados da VM entre as réplicas antigas e as novas não têm tempo para sincronizar até que o estado da réplica antiga seja alterado. Nesse caso, você precisa predefinir essas máquinas VM e marcá-las como não móveis. Por sua vez, isso requer modificação dos algoritmos de otimização. O que agrada é que o ganho total seja praticamente independente do número dessas máquinas, se não houver mais de 10 a 15% do número total de VMs.
Como a carga do servidor muda depois de otimizar o posicionamento da VM?
Ok, otimizamos o posicionamento da VM. Talvez o novo estado resultante seja muito frágil em relação ao aumento de carga? Talvez os servidores estejam funcionando ao limite e qualquer aumento na carga os matará?
Comparamos a utilização de recursos do servidor antes da otimização e depois por um período de 1 semana. O que aconteceu é mostrado na Figura 2:
 Fig. 4. Alteração na carga da CPU após otimizar a alocação da VM
Fig. 4. Alteração na carga da CPU após otimizar a alocação da VMDe acordo com o uso da CPU: o uso médio da CPU aumentou de 10% para apenas 18%. I.e. temos uma margem tripla de desempenho da CPU, enquanto os servidores permanecerão na chamada zona "verde".
Como isso foi feito no software?
Coletamos as métricas necessárias no Yandex.ClickHouse (tentamos o InfluxDB, mas em nossos volumes de dados as consultas com agregação são realizadas muito lentamente) com uma frequência de 30 segundos. A partir daí, a tarefa de calcular o estado ideal lê as métricas, calcula o consumo máximo delas e gera uma tarefa de cálculo que é colocada na fila. Assim que a tarefa de cálculo é concluída, são executados testes para verificar se o resultado não excede os limites especificados.
Alguém já fez isso?
Do nosso conhecimento, algoritmos semelhantes estão dentro do VMware vSphere e Nutanix e aparecem no OpenStack (projeto OpenStack Watcher).
É possível fazer ainda melhor?
Sim você pode. No próximo artigo, mostrarei como compactar máquinas virtuais ainda mais densas sem violar o SLA e por que os neurônios são necessários para isso.