
No campo do reconhecimento emocional, a voz é a segunda fonte mais importante de dados emocionais após o rosto. A voz pode ser caracterizada por vários parâmetros. O tom da voz é uma das principais características, no entanto, no campo da tecnologia acústica, é mais correto chamar esse parâmetro de frequência fundamental.
A frequência do tom fundamental está diretamente relacionada ao que chamamos de entonação. E a entonação, por exemplo, está associada às características emocionalmente expressivas da voz.
Não obstante, determinar a frequência do tom fundamental não é uma tarefa completamente trivial, com nuances interessantes. Neste artigo, discutiremos os recursos dos algoritmos para sua determinação e comparamos as soluções existentes com exemplos de gravações de áudio específicas.
1. IntroduçãoPara começar, lembremos qual é, em essência, a frequência do tom fundamental e em quais tarefas ele pode ser necessário.
A frequência fundamental , também chamada de CHOT, Frequência fundamental ou F0, é a frequência das cordas vocais quando elas pronunciam sons sonoros. Ao pronunciar sons sem tom (não sonoros), por exemplo, falando em um sussurro ou emitindo assobios e assobios, os ligamentos não hesitam, o que significa que essa característica não é relevante para eles.
* Observe que a divisão em sons tonais e não tonais não é equivalente à divisão em vogais e consoantes.
A variação de frequência do tom fundamental é bastante grande e pode variar bastante não apenas entre as pessoas (para vozes masculinas médias mais baixas, a frequência é de 70 a 200 Hz e, para vozes femininas, pode chegar a 400 Hz), mas também para uma pessoa, especialmente na fala emocional. .
A determinação da frequência do tom fundamental é usada para resolver uma ampla gama de problemas:
- Reconhecimento de emoções, como dissemos acima;
- Determinação de sexo;
- Ao resolver o problema de segmentar áudio com várias vozes ou dividir o discurso em frases;
- Na medicina, para determinar as características patológicas da voz (por exemplo, usando os parâmetros acústicos Jitter e Shimmer). Por exemplo, a identificação de sinais da doença de Parkinson [ 1 ]. Jitter e Shimmer também podem ser usados para reconhecer emoções [ 2 ].
No entanto, existem várias dificuldades na determinação de F0. Por exemplo, muitas vezes é possível confundir F0 com harmônicos, o que pode levar aos chamados efeitos de duplicação de pitch / metade do pitch [
3 ]. E em gravações de áudio de baixa qualidade, F0 é bastante difícil de calcular, pois o pico desejado em baixas frequências quase desaparece.
A propósito, lembra-se da história de
Laurel e Yanny ? As diferenças nas palavras que as pessoas ouvem ao ouvir a mesma gravação de áudio surgiram precisamente devido à diferença na percepção F0, que é influenciada por muitos fatores: idade do ouvinte, grau de fadiga e dispositivo de reprodução. Portanto, ao ouvir gravações em alto-falantes com reprodução de alta qualidade de baixas frequências, você ouvirá Laurel e em sistemas de áudio onde as baixas frequências são mal reproduzidas, Yanny. O efeito de transição pode ser visto em um dispositivo, por exemplo
aqui . E neste
artigo , a rede neural atua como um ouvinte. Em outro
artigo, você pode ler como o fenômeno Yanny / Laurel é explicado em termos de formação da fala.
Como uma análise detalhada de todos os métodos para determinar F0 seria muito volumosa, o artigo é de natureza geral e pode ajudar a navegar no tópico.
Métodos para determinar F0Os métodos para determinar F0 podem ser divididos em três categorias: com base na dinâmica do tempo do sinal ou no domínio do tempo; com base na estrutura de frequência ou no domínio da frequência, bem como em métodos combinados. Sugerimos que você se familiarize com o
artigo de revisão sobre o tópico, onde os métodos indicados para extrair F0 são analisados em detalhes.
Observe que qualquer um dos algoritmos discutidos consiste em 3 etapas principais:
Pré-processamento (filtrando o sinal, dividindo-o em quadros)
Procure por possíveis valores de F0 (candidatos)
O rastreamento é a escolha da trajetória mais provável F0 (já que para cada momento em que temos vários candidatos concorrentes, precisamos encontrar o caminho mais provável entre eles)
Domínio do tempoDelineamos alguns pontos gerais. Antes de aplicar os métodos no domínio do tempo, o sinal é pré-filtrado, deixando apenas frequências baixas. Os limites são definidos - as frequências mínima e máxima, por exemplo, de 75 a 500 Hz. A determinação de F0 é feita apenas para áreas com fala harmônica, pois para pausas ou sons de ruído isso não é apenas sem sentido, mas também pode introduzir erros em quadros adjacentes quando a interpolação e / ou suavização é aplicada. O comprimento do quadro é selecionado para conter pelo menos três períodos.
O método principal, com base no qual toda uma família de algoritmos apareceu posteriormente, é a autocorrelação. A abordagem é bastante simples - é necessário calcular a função de autocorrelação e obter o seu primeiro máximo. Ele exibirá o componente de frequência mais pronunciado no sinal. Qual poderia ser a dificuldade no uso de autocorrelação e por que nem sempre o primeiro máximo corresponde à frequência desejada? Mesmo em condições próximas às ideais em gravações de alta qualidade, o método pode estar errado devido à estrutura complexa do sinal. Em condições próximas do real, onde, entre outras coisas, podemos encontrar o desaparecimento do pico desejado em gravações ruidosas ou gravações de baixa qualidade inicialmente, o número de erros aumenta acentuadamente.
Apesar dos erros, o método de autocorrelação é bastante conveniente e atraente devido à sua simplicidade e lógica básicas, razão pela qual é tomado como base em muitos algoritmos, incluindo o YIN. Até o nome do algoritmo nos remete a um equilíbrio entre a conveniência e a imprecisão do método de autocorrelação: “O nome YIN de '' yin '' e '' yang '' da filosofia oriental alude à interação entre autocorrelação e cancelamento que envolve.” [
4 ]
Os criadores do YIN tentaram corrigir os pontos fracos da abordagem de autocorrelação. A primeira mudança é o uso da função Diferença Normalizada Média Cumulativa, que deve reduzir a sensibilidade às modulações de amplitude, tornando os picos mais pronunciados:
\ begin {equation}
d'_t (\ tau) =
\ begin {cases}
1, & \ tau = 0 \\
d_t (\ tau) \ bigg / \ bigg [\ frac {1} {\ tau} \ sum \ limits_ {j = 1} ^ {\ tau} d_t (j) \ bigg] e \ text {caso contrário}
\ end {cases}
\ end {equação}
O YIN também tenta evitar erros que ocorrem nos casos em que o comprimento da função da janela não é completamente dividido pelo período de oscilação. Para isso, é utilizada interpolação mínima parabólica. Na última etapa do processamento do sinal de áudio, a função Melhor estimativa local é executada para evitar saltos acentuados nos valores (bons ou ruins - este é um ponto discutível).
Domínio de frequênciaSe falamos sobre o domínio da frequência, a estrutura harmônica do sinal vem à tona, ou seja, a presença de picos espectrais em frequências que são múltiplos de F0. Você pode "colapsar" esse padrão periódico em um pico claro usando a análise cepstral. Cepstrum - transformada de Fourier do logaritmo do espectro de potência; o pico cepstral corresponde ao componente mais periódico do espectro (pode-se ler
aqui e
aqui ).
Métodos híbridos para determinar F0O próximo algoritmo, que vale a pena explorar com mais detalhes, tem o nome falante YAAPT - mais um algoritmo de rastreamento de afinação - e, na verdade, é híbrido, porque usa informações de frequência e tempo. Uma descrição completa está no
artigo , aqui descrevemos apenas os estágios principais.
 Figura 1. Diagrama do algoritmo YAAPTalgo ( link )
Figura 1. Diagrama do algoritmo YAAPTalgo ( link ) .
O YAAPT consiste em várias etapas principais, a primeira das quais é o pré-processamento. Nesse estágio, os valores do sinal original são elevados ao quadrado e uma segunda versão do sinal é obtida. Esta etapa persegue o mesmo objetivo que a Função de Diferença Normalizada Média Acumulada no YIN - amplificação e restauração de picos "congestionados" de autocorrelação. Ambas as versões do sinal são filtradas - geralmente elas variam de 50 a 1500 Hz, às vezes de 50 a 900 Hz.
Então, a trajetória de base F0 é calculada a partir do espectro do sinal convertido. Os candidatos a F0 são determinados usando o recurso Correlação de Harmônicas Espectrais (SHC).
\ begin {equation}
SHC (t, f) = \ sum \ limits_ {f '= - WL / 2} ^ {WL / 2} \ prod \ limits_ {r = 1} ^ {NH + 1} S (t, rf + f')
\ end {equação}
onde S (t, f) é o espectro de magnitude para o quadro te a frequência f, WL é o comprimento da janela em Hz, NH é o número de harmônicos (os autores recomendam o uso dos três primeiros harmônicos). A potência espectral também é usada para determinar os quadros sonoros e não sonoros, após os quais a trajetória mais ideal é pesquisada e a possibilidade de duplicação / metade do tom é levada em consideração [
3 , Seção II, C].
Além disso, os candidatos a F0 são determinados para o sinal inicial e o convertido e, em vez da função de autocorrelação, a Correlação Cruzada Normalizada (NCCF) é usada aqui.
\ begin {equation}
NCCF (m) = \ frac {\ sum \ limits_ {n = 0} ^ {Nm-1} x (n) * x (n + m)} {\ sqrt {\ sum \ limits_ {n = 0} ^ { Nm-1} x ^ 2 (n) * \ sum \ limits_ {n = 0} ^ {Nm-1} x ^ 2 (n + m)}} \ text {,} \ espaço {0,3cm} 0 <m <M_ {0}
\ end {equação}
O próximo passo é avaliar todos os possíveis candidatos e calcular sua significância ou peso (mérito). O peso dos candidatos obtidos a partir do sinal de áudio depende não apenas da amplitude do pico da NCCF, mas também da proximidade da trajetória F0 determinada a partir do espectro. Ou seja, o domínio da frequência é considerado grosseiro em termos de precisão, mas estável [
3 , Seção II, D].
Então, para todos os pares de candidatos restantes, é calculada a matriz de Custo de Transição - o preço de transição, no qual eles finalmente encontram a trajetória ideal [
3 , Seção II, E].
ExemplosAgora, aplicamos todos os algoritmos acima a gravações de áudio específicas. Como ponto de partida, usaremos o
Praat , uma ferramenta fundamental para muitos estudiosos da fala. E então, em Python, examinaremos a implementação do YIN e YAAPT e compararemos os resultados recebidos.
Como material de áudio, você pode usar qualquer áudio disponível. Tiramos vários trechos de nosso banco de dados
RAMAS - um
conjunto de dados multimodal criado com a participação de atores do VGIK. Você também pode usar material de outros bancos de dados abertos, como
LibriSpeech ou
RAVDESS .
Para um exemplo ilustrativo, extraímos trechos de várias gravações com vozes masculinas e femininas, tanto neutras quanto emocionalmente coloridas, e para maior clareza, as combinamos em uma
gravação . Vejamos nosso sinal, seu espectrograma, intensidade (cor laranja) e F0 (cor azul). No Praat, isso pode ser feito usando Ctrl + O (Abrir - Ler do arquivo) e, em seguida, o botão Exibir e Editar.
 Figura 2. Espectrograma, intensidade (cor laranja), F0 (cor azul) em Praat.
Figura 2. Espectrograma, intensidade (cor laranja), F0 (cor azul) em Praat.O áudio mostra claramente que, na fala emocional, o tom aumenta em homens e mulheres. Ao mesmo tempo, F0 para a fala emocional do homem pode muito bem ser comparado com o F0 de uma voz feminina.
RastreamentoSelecione a guia Analisar periodicidade - para Inclinar (ac) no menu Praat, ou seja, a definição de F0 usando a correlação automática. Aparecerá uma janela para definir parâmetros, na qual é possível definir 3 parâmetros para determinar candidatos para F0 e mais 6 parâmetros para o algoritmo de busca de caminhos, que cria o caminho F0 mais provável entre todos os candidatos.
Muitos parâmetros (no Praat, sua descrição também está no botão Ajuda)- Limiar de silêncio - o limiar da amplitude relativa do sinal para determinar o silêncio, o valor padrão é 0,03.
- Limiar de sonoridade - o peso do candidato não sonoro, o valor máximo é 1. Quanto maior esse parâmetro, mais quadros serão definidos como sonoros, ou seja, sem sons de tom. Nesses quadros, F0 não será determinado. O valor deste parâmetro é o limite para picos da função de autocorrelação. O valor padrão é 0,45.
- Custo de oitava - determina quanto mais peso os candidatos de alta frequência têm em relação aos de baixa frequência. Quanto maior o valor, mais preferência é dada ao candidato de alta frequência. O valor padrão é 0,01 por oitava.
- Custo de salto de oitava - com um aumento nesse coeficiente, o número de transições nítidas de salto entre valores sucessivos de F0 diminui. O valor padrão é 0,35.
- Custo expresso / não expresso - aumentar esse coeficiente diminui o número de transições sonoras / não expressas. O valor padrão é 0,14.
- Teto de inclinação (Hz) - candidatos acima dessa frequência não são considerados. O valor padrão é 600 Hz.
Uma descrição detalhada do algoritmo pode ser encontrada em
um artigo de 1993.
A aparência do resultado do rastreador (localizador de caminho) pode ser vista clicando em OK e depois visualizando (Exibir e editar) o arquivo Pitch resultante. Pode-se observar que, além da trajetória selecionada, ainda havia candidatos bastante significativos com frequência mais baixa.
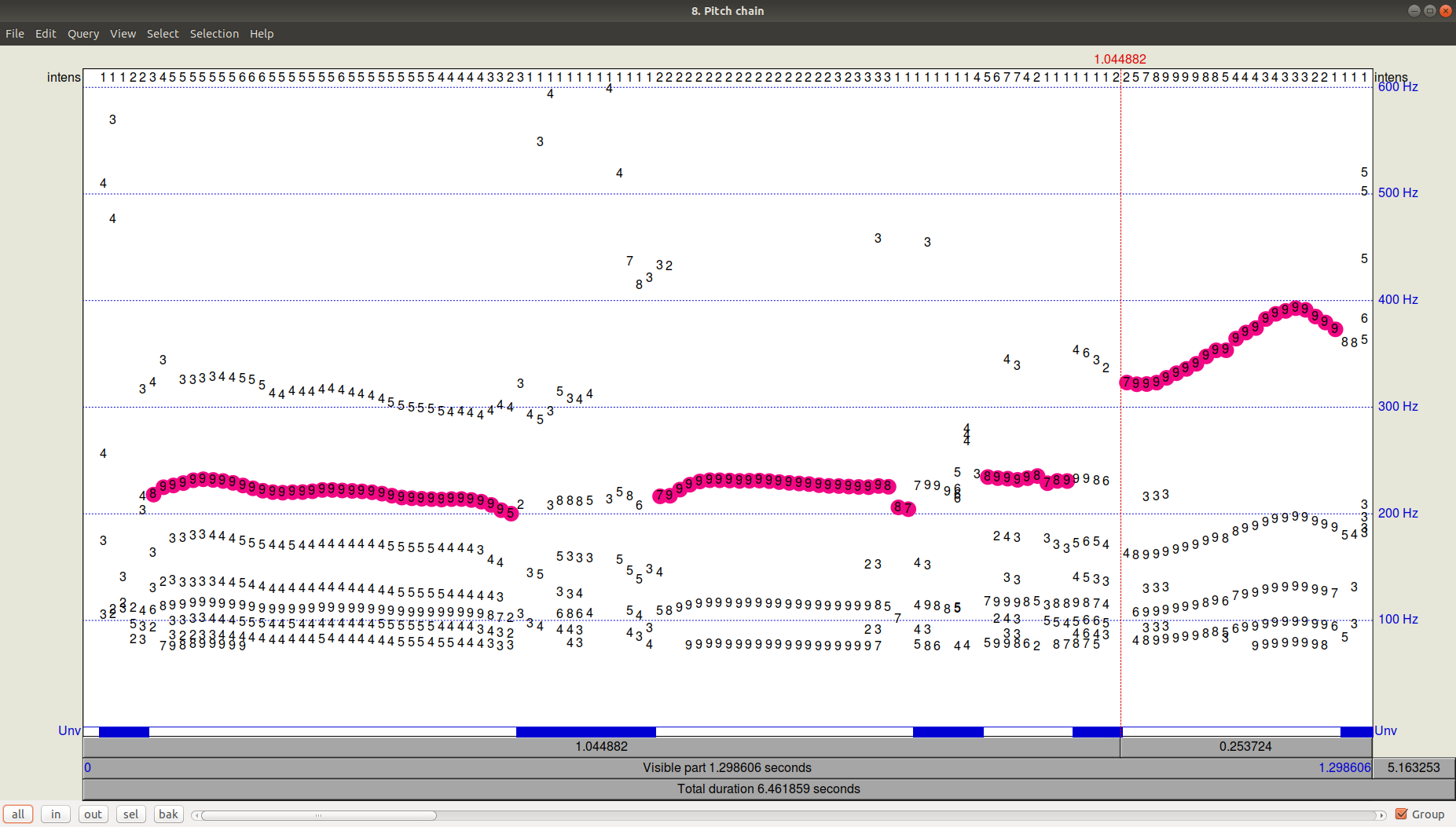 Figura 3. PitchPath pelos primeiros 1,3 segundos de gravação de áudio.Mas e o Python?
Figura 3. PitchPath pelos primeiros 1,3 segundos de gravação de áudio.Mas e o Python?Vamos pegar duas bibliotecas que oferecem rastreamento de pitch -
aubio , no qual o algoritmo padrão é YIN, e a biblioteca
AMFM_decompsition , que possui uma implementação do algoritmo YAAPT. No arquivo separado (arquivo
PraatPitch.txt ),
insira os valores F0 do Praat (isso pode ser feito manualmente: selecione o arquivo de som, clique em Exibir e editar, selecione o arquivo inteiro e selecione a listagem de afinação no menu superior).
Agora compare os resultados para todos os três algoritmos (YIN, YAAPT, Praat).
Muito códigoimport amfm_decompy.basic_tools as basic import amfm_decompy.pYAAPT as pYAAPT import matplotlib.pyplot as plt import numpy as np import sys from aubio import source, pitch
 Figura 4. Comparação da operação dos algoritmos YIN, YAAPT e Praat.
Figura 4. Comparação da operação dos algoritmos YIN, YAAPT e Praat.Vemos que, com os parâmetros padrão, o YIN é bastante nocauteado, obtendo uma trajetória bastante plana com valores inferiores a Praat e perdendo completamente as transições entre as vozes masculina e feminina, bem como entre a fala emocional e não emocional.
YAAPT cortou um tom muito alto no discurso emocional feminino, mas no geral conseguiu claramente melhor. Devido às suas características específicas, o YAAPT funciona melhor - é impossível responder imediatamente, é claro, mas pode-se supor que o papel seja desempenhado pela obtenção de candidatos de três fontes e um cálculo mais meticuloso do seu peso do que no YIN.
ConclusãoComo a questão de determinar a frequência do tom fundamental (F0), de uma forma ou de outra, surge antes de quase todo mundo que trabalha com som, há muitas maneiras de resolvê-lo. A questão da precisão e dos recursos necessários do material de áudio em cada caso determina com que cuidado é necessário selecionar parâmetros ou, em outro caso, você pode restringir-se a uma solução básica como o YAAPT. Tomando o Praat como o padrão do algoritmo para processamento de fala (no entanto, um grande número de pesquisadores o utiliza), podemos concluir que o YAAPT é, para uma primeira aproximação, mais confiável e preciso que o YIN, embora nosso exemplo tenha sido complicado para ele.
Postado por
Eva Kazimirova, pesquisadora do Laboratório Neurodata, especialista em processamento de fala.
Offtop : Você gostou do artigo? De fato, temos várias tarefas interessantes em ML, matemática e programação e precisamos de cérebros. Você está curioso? Venha para nós! E-mail: hr@neurodatalab.com
Referências- Rusz, J., Cmejla, R., Ruzickova, H., Ruzicka, E. Medidas acústicas quantitativas para caracterização de distúrbios da fala e da voz na doença de Parkinson não tratada precoce. O Jornal da Sociedade Acústica da América, vol. 129, edição 1 (2011), pp. 350-367. Acesso
- Farrús, M., Hernando, J., Ejarque, P. Jitter e Shimmer Measurement para reconhecimento de alto-falante. Anais da Conferência Anual da International Speech Communication Association, INTERSPEECH, vol. 2 (2007), pp. 1153-1156. Acesso
- Zahorian, S., Hu, HA. Método espectral / temporal para rastreamento de frequência fundamental robusto. O Jornal da Sociedade Acústica da América, vol. 123, edição 6 (2008), pp. 4559-4571. Acesso
- De Cheveigné, A., Kawahara, H. YIN, um estimador de frequência fundamental para fala e música. O Jornal da Sociedade Acústica da América, vol. 111, edição 4 (2002), pp. 1917-1930. Acesso